Re: [PR] [SPARK-48143][SQL] Use lightweight exceptions for control-flow between UnivocityParser and FailureSafeParser [spark]
cloud-fan closed pull request #46500: [SPARK-48143][SQL] Use lightweight exceptions for control-flow between UnivocityParser and FailureSafeParser URL: https://github.com/apache/spark/pull/46500 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
Re: [PR] [SPARK-48143][SQL] Use lightweight exceptions for control-flow between UnivocityParser and FailureSafeParser [spark]
cloud-fan commented on PR #46500: URL: https://github.com/apache/spark/pull/46500#issuecomment-2104909079 thanks, merging to master! -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
Re: [PR] [SPARK-48143][SQL] Use lightweight exceptions for control-flow between UnivocityParser and FailureSafeParser [spark]
vladimirg-db commented on code in PR #46500:
URL: https://github.com/apache/spark/pull/46500#discussion_r1596925973
##
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/util/BadRecordException.scala:
##
@@ -67,16 +67,30 @@ case class PartialResultArrayException(
extends Exception(cause)
/**
- * Exception thrown when the underlying parser meet a bad record and can't
parse it.
+ * Exception thrown when the underlying parser met a bad record and can't
parse it.
* @param record a function to return the record that cause the parser to fail
* @param partialResults a function that returns an row array, which is the
partial results of
* parsing this bad record.
- * @param cause the actual exception about why the record is bad and can't be
parsed.
+ * @param cause the actual exception about why the record is bad and can't be
parsed. It's better
+ * to use `LazyBadRecordCauseWrapper` here to delay heavy
cause construction
+ * until it's needed.
*/
case class BadRecordException(
@transient record: () => UTF8String,
@transient partialResults: () => Array[InternalRow] = () =>
Array.empty[InternalRow],
-cause: Throwable) extends Exception(cause)
+cause: Throwable) extends Exception(cause) {
+ override def getStackTrace(): Array[StackTraceElement] = new
Array[StackTraceElement](0)
Review Comment:
Added a doc for that
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
Re: [PR] [SPARK-48143][SQL] Use lightweight exceptions for control-flow between UnivocityParser and FailureSafeParser [spark]
vladimirg-db commented on code in PR #46500:
URL: https://github.com/apache/spark/pull/46500#discussion_r1596767877
##
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/util/BadRecordException.scala:
##
@@ -67,16 +67,30 @@ case class PartialResultArrayException(
extends Exception(cause)
/**
- * Exception thrown when the underlying parser meet a bad record and can't
parse it.
+ * Exception thrown when the underlying parser met a bad record and can't
parse it.
* @param record a function to return the record that cause the parser to fail
* @param partialResults a function that returns an row array, which is the
partial results of
* parsing this bad record.
- * @param cause the actual exception about why the record is bad and can't be
parsed.
+ * @param cause the actual exception about why the record is bad and can't be
parsed. It's better
+ * to use `LazyBadRecordCauseWrapper` here to delay heavy
cause construction
+ * until it's needed.
*/
case class BadRecordException(
@transient record: () => UTF8String,
@transient partialResults: () => Array[InternalRow] = () =>
Array.empty[InternalRow],
-cause: Throwable) extends Exception(cause)
+cause: Throwable) extends Exception(cause) {
+ override def getStackTrace(): Array[StackTraceElement] = new
Array[StackTraceElement](0)
Review Comment:
If the cause is other than `LazyBadRecordExceptionCauseWrapper`, the
stacktrace from the cause itself will be enough.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
Re: [PR] [SPARK-48143][SQL] Use lightweight exceptions for control-flow between UnivocityParser and FailureSafeParser [spark]
vladimirg-db commented on code in PR #46500:
URL: https://github.com/apache/spark/pull/46500#discussion_r1596767877
##
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/util/BadRecordException.scala:
##
@@ -67,16 +67,30 @@ case class PartialResultArrayException(
extends Exception(cause)
/**
- * Exception thrown when the underlying parser meet a bad record and can't
parse it.
+ * Exception thrown when the underlying parser met a bad record and can't
parse it.
* @param record a function to return the record that cause the parser to fail
* @param partialResults a function that returns an row array, which is the
partial results of
* parsing this bad record.
- * @param cause the actual exception about why the record is bad and can't be
parsed.
+ * @param cause the actual exception about why the record is bad and can't be
parsed. It's better
+ * to use `LazyBadRecordCauseWrapper` here to delay heavy
cause construction
+ * until it's needed.
*/
case class BadRecordException(
@transient record: () => UTF8String,
@transient partialResults: () => Array[InternalRow] = () =>
Array.empty[InternalRow],
-cause: Throwable) extends Exception(cause)
+cause: Throwable) extends Exception(cause) {
+ override def getStackTrace(): Array[StackTraceElement] = new
Array[StackTraceElement](0)
Review Comment:
If the cause is other than `LazyBadRecordExceptionCauseWrapper`, the
stacktrace from the cause will be enough.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
Re: [PR] [SPARK-48143][SQL] Use lightweight exceptions for control-flow between UnivocityParser and FailureSafeParser [spark]
cloud-fan commented on code in PR #46500:
URL: https://github.com/apache/spark/pull/46500#discussion_r1596740941
##
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/util/BadRecordException.scala:
##
@@ -67,16 +67,30 @@ case class PartialResultArrayException(
extends Exception(cause)
/**
- * Exception thrown when the underlying parser meet a bad record and can't
parse it.
+ * Exception thrown when the underlying parser met a bad record and can't
parse it.
* @param record a function to return the record that cause the parser to fail
* @param partialResults a function that returns an row array, which is the
partial results of
* parsing this bad record.
- * @param cause the actual exception about why the record is bad and can't be
parsed.
+ * @param cause the actual exception about why the record is bad and can't be
parsed. It's better
+ * to use `LazyBadRecordCauseWrapper` here to delay heavy
cause construction
+ * until it's needed.
*/
case class BadRecordException(
@transient record: () => UTF8String,
@transient partialResults: () => Array[InternalRow] = () =>
Array.empty[InternalRow],
-cause: Throwable) extends Exception(cause)
+cause: Throwable) extends Exception(cause) {
+ override def getStackTrace(): Array[StackTraceElement] = new
Array[StackTraceElement](0)
Review Comment:
If `BadRecordException` can be a user-facing exception, doesn't this change
degrade the error message?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
Re: [PR] [SPARK-48143][SQL] Use lightweight exceptions for control-flow between UnivocityParser and FailureSafeParser [spark]
vladimirg-db commented on code in PR #46500:
URL: https://github.com/apache/spark/pull/46500#discussion_r1595606748
##
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/csv/UnivocityParser.scala:
##
@@ -316,7 +316,7 @@ class UnivocityParser(
throw BadRecordException(
() => getCurrentInput,
() => Array.empty,
-QueryExecutionErrors.malformedCSVRecordError(""))
+MalformedCSVRecordException(""))
Review Comment:
Do you mean, to use some other exception _in place_ of `BadRecordException`
between the `UnivocityParser` and `FailureSafeParser`? Looks like a cleaner
idea! But it seems that in that case we're gonna end up with two similar
mechanisms for the same thing. And eventual refactoring for this issue does not
seem easy, considering how extensively the parsers and `BadRecordException` are
used in the codebase...
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
Re: [PR] [SPARK-48143][SQL] Use lightweight exceptions for control-flow between UnivocityParser and FailureSafeParser [spark]
cloud-fan commented on code in PR #46500:
URL: https://github.com/apache/spark/pull/46500#discussion_r1595576046
##
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/csv/UnivocityParser.scala:
##
@@ -316,7 +316,7 @@ class UnivocityParser(
throw BadRecordException(
() => getCurrentInput,
() => Array.empty,
-QueryExecutionErrors.malformedCSVRecordError(""))
+MalformedCSVRecordException(""))
Review Comment:
This approach is like using a placeholder exception first and then replacing
it with the actual error at a later phase. The current implementation needs a
dedicate placeholder exception for each real error.
Shall we make it more general? We can have a special wrapper exception,
which does not have the cause field and can lazily produce the actual error.
Just like the updated `BadRecordException` in the previous attempt.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
Re: [PR] [SPARK-48143][SQL] Use lightweight exceptions for control-flow between UnivocityParser and FailureSafeParser [spark]
cloud-fan commented on code in PR #46500:
URL: https://github.com/apache/spark/pull/46500#discussion_r1595576046
##
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/csv/UnivocityParser.scala:
##
@@ -316,7 +316,7 @@ class UnivocityParser(
throw BadRecordException(
() => getCurrentInput,
() => Array.empty,
-QueryExecutionErrors.malformedCSVRecordError(""))
+MalformedCSVRecordException(""))
Review Comment:
This approach is like using a placeholder exception first and then replacing
it with the actual error at a later phase. The current implementation needs a
dedicate placeholder exception for each real error.
Shall we make it more general? We can have a special wrapper exception,
which does not have the cause field and can lazily produce the actual error?
Just like the updated `BadRecordException` in the previous attempt.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
Re: [PR] [SPARK-48143][SQL] Use lightweight exceptions for control-flow between UnivocityParser and FailureSafeParser [spark]
vladimirg-db commented on PR #46500: URL: https://github.com/apache/spark/pull/46500#issuecomment-2102304041 Checked the benchmark, the perf is the same as it was on the reverted version -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
Re: [PR] [SPARK-48143][SQL] Use lightweight exceptions for control-flow between UnivocityParser and FailureSafeParser [spark]
vladimirg-db commented on PR #46500: URL: https://github.com/apache/spark/pull/46500#issuecomment-2102192074 @HyukjinKwon @cloud-fan @dongjoon-hyun hi! New implementation for the reverted https://github.com/apache/spark/pull/46478 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[PR] [SPARK-48143][SQL] Use lightweight exceptions for control-flow between UnivocityParser and FailureSafeParser [spark]
vladimirg-db opened a new pull request, #46500: URL: https://github.com/apache/spark/pull/46500 # What changes were proposed in this pull request? New lightweight exception for control-flow between UnivocityParser and FalureSafeParser to speed-up malformed CSV parsing. This is a different way to implement these reverted changes: https://github.com/apache/spark/pull/46478 The previous implementation was more invasive - removing `cause` from `BadRecordException` could break upper code, which unwraps errors and checks the types of the causes. This implementation only touches `FailureSafeParser` and `UnivocityParser` since in the codebase they are always used together, unlike `JacksonParser` and `StaxXmlParser`. Removing stacktrace from `BadRecordException` is safe, since the cause itself has an adequate stacktrace (except pure control-flow cases). ### Why are the changes needed? Parsing in `PermissiveMode` is slow due to heavy exception construction (stacktrace filling + string template substitution in `SparkRuntimeException`) ### Does this PR introduce _any_ user-facing change? No, since `FailureSafeParser` unwraps `BadRecordException` and correctly rethrows user-facing exceptions in `FailFastMode` ### How was this patch tested? - `testOnly org.apache.spark.sql.catalyst.csv.UnivocityParserSuite` - Manually run csv benchmark - Manually checked correct and malformed csv in sherk-shell (org.apache.spark.SparkException is thrown with the stacktrace) ### Was this patch authored or co-authored using generative AI tooling? No -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
Re: [PR] [SPARK-48143][SQL] Use lightweight exceptions for control-flow between UnivocityParser and FailureSafeParser [spark]
cloud-fan closed pull request #46400: [SPARK-48143][SQL] Use lightweight exceptions for control-flow between UnivocityParser and FailureSafeParser URL: https://github.com/apache/spark/pull/46400 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
Re: [PR] [SPARK-48143][SQL] Use lightweight exceptions for control-flow between UnivocityParser and FailureSafeParser [spark]
cloud-fan commented on PR #46400: URL: https://github.com/apache/spark/pull/46400#issuecomment-2098291491 thanks, merging to master! -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
Re: [PR] [SPARK-48143][SQL] Use lightweight exceptions for control-flow between UnivocityParser and FailureSafeParser [spark]
vladimirg-db commented on code in PR #46400:
URL: https://github.com/apache/spark/pull/46400#discussion_r1591891672
##
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/util/BadRecordException.scala:
##
@@ -67,16 +67,23 @@ case class PartialResultArrayException(
extends Exception(cause)
/**
- * Exception thrown when the underlying parser meet a bad record and can't
parse it.
+ * Exception thrown when the underlying parser meets a bad record and can't
parse it. Used for
+ * control flow between wrapper and underlying parser without overhead of
creating a full exception.
* @param record a function to return the record that cause the parser to fail
* @param partialResults a function that returns an row array, which is the
partial results of
* parsing this bad record.
- * @param cause the actual exception about why the record is bad and can't be
parsed.
+ * @param cause the actual exception about why the record is bad and can't be
parsed. It's better
+ * to use lightweight exception here (e.g. without
stacktrace), and throw an
+ * adequate (user-facing) exception only in case it's
necessary after
+ * unwrapping `BadRecordException`
*/
case class BadRecordException(
@transient record: () => UTF8String,
@transient partialResults: () => Array[InternalRow] = () =>
Array.empty[InternalRow],
-cause: Throwable) extends Exception(cause)
+cause: Throwable) extends Exception(cause) {
Review Comment:
Made a PR right away, since it's a trivial change:
https://github.com/apache/spark/pull/46428
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
Re: [PR] [SPARK-48143][SQL] Use lightweight exceptions for control-flow between UnivocityParser and FailureSafeParser [spark]
vladimirg-db commented on code in PR #46400:
URL: https://github.com/apache/spark/pull/46400#discussion_r1591891672
##
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/util/BadRecordException.scala:
##
@@ -67,16 +67,23 @@ case class PartialResultArrayException(
extends Exception(cause)
/**
- * Exception thrown when the underlying parser meet a bad record and can't
parse it.
+ * Exception thrown when the underlying parser meets a bad record and can't
parse it. Used for
+ * control flow between wrapper and underlying parser without overhead of
creating a full exception.
* @param record a function to return the record that cause the parser to fail
* @param partialResults a function that returns an row array, which is the
partial results of
* parsing this bad record.
- * @param cause the actual exception about why the record is bad and can't be
parsed.
+ * @param cause the actual exception about why the record is bad and can't be
parsed. It's better
+ * to use lightweight exception here (e.g. without
stacktrace), and throw an
+ * adequate (user-facing) exception only in case it's
necessary after
+ * unwrapping `BadRecordException`
*/
case class BadRecordException(
@transient record: () => UTF8String,
@transient partialResults: () => Array[InternalRow] = () =>
Array.empty[InternalRow],
-cause: Throwable) extends Exception(cause)
+cause: Throwable) extends Exception(cause) {
Review Comment:
Make a PR right away, since it's a trivial change:
https://github.com/apache/spark/pull/46428
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
Re: [PR] [SPARK-48143][SQL] Use lightweight exceptions for control-flow between UnivocityParser and FailureSafeParser [spark]
cloud-fan commented on code in PR #46400:
URL: https://github.com/apache/spark/pull/46400#discussion_r1591871466
##
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/util/BadRecordException.scala:
##
@@ -67,16 +67,23 @@ case class PartialResultArrayException(
extends Exception(cause)
/**
- * Exception thrown when the underlying parser meet a bad record and can't
parse it.
+ * Exception thrown when the underlying parser meets a bad record and can't
parse it. Used for
+ * control flow between wrapper and underlying parser without overhead of
creating a full exception.
* @param record a function to return the record that cause the parser to fail
* @param partialResults a function that returns an row array, which is the
partial results of
* parsing this bad record.
- * @param cause the actual exception about why the record is bad and can't be
parsed.
+ * @param cause the actual exception about why the record is bad and can't be
parsed. It's better
+ * to use lightweight exception here (e.g. without
stacktrace), and throw an
+ * adequate (user-facing) exception only in case it's
necessary after
+ * unwrapping `BadRecordException`
*/
case class BadRecordException(
@transient record: () => UTF8String,
@transient partialResults: () => Array[InternalRow] = () =>
Array.empty[InternalRow],
-cause: Throwable) extends Exception(cause)
+cause: Throwable) extends Exception(cause) {
Review Comment:
In `VariantExpressionEvalUtils.parseJson`, we should not wrap the error with
`BadRecordException`
```
throw
QueryExecutionErrors.malformedRecordsDetectedInRecordParsingError(
input.toString, BadRecordException(() => input, cause = e))
```
should be
```
throw
QueryExecutionErrors.malformedRecordsDetectedInRecordParsingError(
input.toString, e)
```
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
Re: [PR] [SPARK-48143][SQL] Use lightweight exceptions for control-flow between UnivocityParser and FailureSafeParser [spark]
gene-db commented on code in PR #46400:
URL: https://github.com/apache/spark/pull/46400#discussion_r1591776687
##
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/util/BadRecordException.scala:
##
@@ -67,16 +67,23 @@ case class PartialResultArrayException(
extends Exception(cause)
/**
- * Exception thrown when the underlying parser meet a bad record and can't
parse it.
+ * Exception thrown when the underlying parser meets a bad record and can't
parse it. Used for
+ * control flow between wrapper and underlying parser without overhead of
creating a full exception.
* @param record a function to return the record that cause the parser to fail
* @param partialResults a function that returns an row array, which is the
partial results of
* parsing this bad record.
- * @param cause the actual exception about why the record is bad and can't be
parsed.
+ * @param cause the actual exception about why the record is bad and can't be
parsed. It's better
+ * to use lightweight exception here (e.g. without
stacktrace), and throw an
+ * adequate (user-facing) exception only in case it's
necessary after
+ * unwrapping `BadRecordException`
*/
case class BadRecordException(
@transient record: () => UTF8String,
@transient partialResults: () => Array[InternalRow] = () =>
Array.empty[InternalRow],
-cause: Throwable) extends Exception(cause)
+cause: Throwable) extends Exception(cause) {
Review Comment:
Yes, we can change `parse_json` exception behavior. What is the desired
behavior?
cc @chenhao-db
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
Re: [PR] [SPARK-48143][SQL] Use lightweight exceptions for control-flow between UnivocityParser and FailureSafeParser [spark]
cloud-fan commented on code in PR #46400:
URL: https://github.com/apache/spark/pull/46400#discussion_r1591749162
##
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/util/BadRecordException.scala:
##
@@ -67,16 +67,23 @@ case class PartialResultArrayException(
extends Exception(cause)
/**
- * Exception thrown when the underlying parser meet a bad record and can't
parse it.
+ * Exception thrown when the underlying parser meets a bad record and can't
parse it. Used for
+ * control flow between wrapper and underlying parser without overhead of
creating a full exception.
* @param record a function to return the record that cause the parser to fail
* @param partialResults a function that returns an row array, which is the
partial results of
* parsing this bad record.
- * @param cause the actual exception about why the record is bad and can't be
parsed.
+ * @param cause the actual exception about why the record is bad and can't be
parsed. It's better
+ * to use lightweight exception here (e.g. without
stacktrace), and throw an
+ * adequate (user-facing) exception only in case it's
necessary after
+ * unwrapping `BadRecordException`
*/
case class BadRecordException(
@transient record: () => UTF8String,
@transient partialResults: () => Array[InternalRow] = () =>
Array.empty[InternalRow],
-cause: Throwable) extends Exception(cause)
+cause: Throwable) extends Exception(cause) {
Review Comment:
`parse_json` is a new function and not release yet, we can still change it.
It looks wrong to throw `BadRecordException` as a user-facing error. cc
@gene-db
##
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/util/BadRecordException.scala:
##
@@ -67,16 +67,23 @@ case class PartialResultArrayException(
extends Exception(cause)
/**
- * Exception thrown when the underlying parser meet a bad record and can't
parse it.
+ * Exception thrown when the underlying parser meets a bad record and can't
parse it. Used for
+ * control flow between wrapper and underlying parser without overhead of
creating a full exception.
* @param record a function to return the record that cause the parser to fail
* @param partialResults a function that returns an row array, which is the
partial results of
* parsing this bad record.
- * @param cause the actual exception about why the record is bad and can't be
parsed.
+ * @param cause the actual exception about why the record is bad and can't be
parsed. It's better
+ * to use lightweight exception here (e.g. without
stacktrace), and throw an
+ * adequate (user-facing) exception only in case it's
necessary after
+ * unwrapping `BadRecordException`
*/
case class BadRecordException(
@transient record: () => UTF8String,
@transient partialResults: () => Array[InternalRow] = () =>
Array.empty[InternalRow],
-cause: Throwable) extends Exception(cause)
+cause: Throwable) extends Exception(cause) {
Review Comment:
`parse_json` is a new function and not released yet, we can still change it.
It looks wrong to throw `BadRecordException` as a user-facing error. cc
@gene-db
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
Re: [PR] [SPARK-48143][SQL] Use lightweight exceptions for control-flow between UnivocityParser and FailureSafeParser [spark]
vladimirg-db commented on code in PR #46400:
URL: https://github.com/apache/spark/pull/46400#discussion_r1591304831
##
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/util/BadRecordException.scala:
##
@@ -67,16 +67,23 @@ case class PartialResultArrayException(
extends Exception(cause)
/**
- * Exception thrown when the underlying parser meet a bad record and can't
parse it.
+ * Exception thrown when the underlying parser meets a bad record and can't
parse it. Used for
+ * control flow between wrapper and underlying parser without overhead of
creating a full exception.
* @param record a function to return the record that cause the parser to fail
* @param partialResults a function that returns an row array, which is the
partial results of
* parsing this bad record.
- * @param cause the actual exception about why the record is bad and can't be
parsed.
+ * @param cause the actual exception about why the record is bad and can't be
parsed. It's better
+ * to use lightweight exception here (e.g. without
stacktrace), and throw an
+ * adequate (user-facing) exception only in case it's
necessary after
+ * unwrapping `BadRecordException`
*/
case class BadRecordException(
@transient record: () => UTF8String,
@transient partialResults: () => Array[InternalRow] = () =>
Array.empty[InternalRow],
-cause: Throwable) extends Exception(cause)
+cause: Throwable) extends Exception(cause) {
Review Comment:
In that case I propose the following:
- Merge this PR with the original implementation (with the
`MalformedCSVRecordException`)
- Replace `BadRecordException` in `parseJson` with something more pretty
- Refactor all parsers to pass exception cause in `BadRecordException`
lazily using factory function
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
Re: [PR] [SPARK-48143][SQL] Use lightweight exceptions for control-flow between UnivocityParser and FailureSafeParser [spark]
vladimirg-db commented on code in PR #46400:
URL: https://github.com/apache/spark/pull/46400#discussion_r1591304831
##
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/util/BadRecordException.scala:
##
@@ -67,16 +67,23 @@ case class PartialResultArrayException(
extends Exception(cause)
/**
- * Exception thrown when the underlying parser meet a bad record and can't
parse it.
+ * Exception thrown when the underlying parser meets a bad record and can't
parse it. Used for
+ * control flow between wrapper and underlying parser without overhead of
creating a full exception.
* @param record a function to return the record that cause the parser to fail
* @param partialResults a function that returns an row array, which is the
partial results of
* parsing this bad record.
- * @param cause the actual exception about why the record is bad and can't be
parsed.
+ * @param cause the actual exception about why the record is bad and can't be
parsed. It's better
+ * to use lightweight exception here (e.g. without
stacktrace), and throw an
+ * adequate (user-facing) exception only in case it's
necessary after
+ * unwrapping `BadRecordException`
*/
case class BadRecordException(
@transient record: () => UTF8String,
@transient partialResults: () => Array[InternalRow] = () =>
Array.empty[InternalRow],
-cause: Throwable) extends Exception(cause)
+cause: Throwable) extends Exception(cause) {
Review Comment:
In that case I propose the following:
- Merge this PR with the origjnal implementation (with the
`MalformedCSVRecordException`)
- Replace `BadRecordException` in `parseJson` with something more pretty
- Refactor all parsers to pass exception cause in `BadRecordException`
lazily using factory function
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
Re: [PR] [SPARK-48143][SQL] Use lightweight exceptions for control-flow between UnivocityParser and FailureSafeParser [spark]
vladimirg-db commented on code in PR #46400:
URL: https://github.com/apache/spark/pull/46400#discussion_r1591293044
##
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/util/BadRecordException.scala:
##
@@ -67,16 +67,23 @@ case class PartialResultArrayException(
extends Exception(cause)
/**
- * Exception thrown when the underlying parser meet a bad record and can't
parse it.
+ * Exception thrown when the underlying parser meets a bad record and can't
parse it. Used for
+ * control flow between wrapper and underlying parser without overhead of
creating a full exception.
* @param record a function to return the record that cause the parser to fail
* @param partialResults a function that returns an row array, which is the
partial results of
* parsing this bad record.
- * @param cause the actual exception about why the record is bad and can't be
parsed.
+ * @param cause the actual exception about why the record is bad and can't be
parsed. It's better
+ * to use lightweight exception here (e.g. without
stacktrace), and throw an
+ * adequate (user-facing) exception only in case it's
necessary after
+ * unwrapping `BadRecordException`
*/
case class BadRecordException(
@transient record: () => UTF8String,
@transient partialResults: () => Array[InternalRow] = () =>
Array.empty[InternalRow],
-cause: Throwable) extends Exception(cause)
+cause: Throwable) extends Exception(cause) {
Review Comment:
Yea, it's user-facing there:
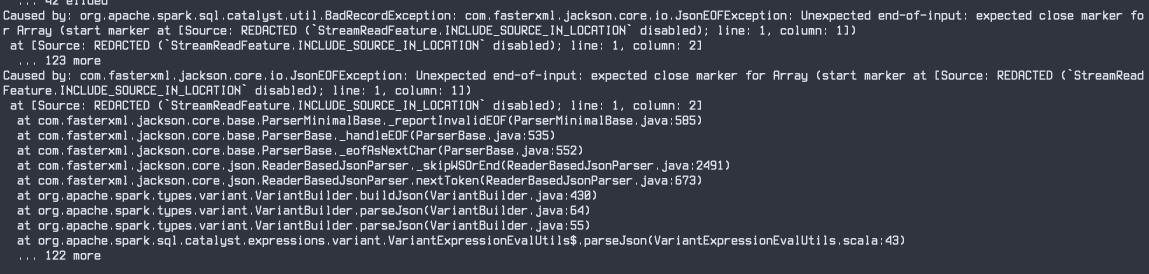
By omitting the cause we would break the user-facing diagnostics for the
`parse_json` sql function. But for me it looks like `BadRecordException` should
not be used there at all
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
Re: [PR] [SPARK-48143][SQL] Use lightweight exceptions for control-flow between UnivocityParser and FailureSafeParser [spark]
vladimirg-db commented on code in PR #46400:
URL: https://github.com/apache/spark/pull/46400#discussion_r1591293044
##
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/util/BadRecordException.scala:
##
@@ -67,16 +67,23 @@ case class PartialResultArrayException(
extends Exception(cause)
/**
- * Exception thrown when the underlying parser meet a bad record and can't
parse it.
+ * Exception thrown when the underlying parser meets a bad record and can't
parse it. Used for
+ * control flow between wrapper and underlying parser without overhead of
creating a full exception.
* @param record a function to return the record that cause the parser to fail
* @param partialResults a function that returns an row array, which is the
partial results of
* parsing this bad record.
- * @param cause the actual exception about why the record is bad and can't be
parsed.
+ * @param cause the actual exception about why the record is bad and can't be
parsed. It's better
+ * to use lightweight exception here (e.g. without
stacktrace), and throw an
+ * adequate (user-facing) exception only in case it's
necessary after
+ * unwrapping `BadRecordException`
*/
case class BadRecordException(
@transient record: () => UTF8String,
@transient partialResults: () => Array[InternalRow] = () =>
Array.empty[InternalRow],
-cause: Throwable) extends Exception(cause)
+cause: Throwable) extends Exception(cause) {
Review Comment:
Yea, it's user-facing there:

By omitting the cause we would break the user-facing diagnostics for the
`parse_json` sql function. For me it looks like `BadRecordException` should not
be used there at all
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
Re: [PR] [SPARK-48143][SQL] Use lightweight exceptions for control-flow between UnivocityParser and FailureSafeParser [spark]
vladimirg-db commented on code in PR #46400:
URL: https://github.com/apache/spark/pull/46400#discussion_r1591293044
##
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/util/BadRecordException.scala:
##
@@ -67,16 +67,23 @@ case class PartialResultArrayException(
extends Exception(cause)
/**
- * Exception thrown when the underlying parser meet a bad record and can't
parse it.
+ * Exception thrown when the underlying parser meets a bad record and can't
parse it. Used for
+ * control flow between wrapper and underlying parser without overhead of
creating a full exception.
* @param record a function to return the record that cause the parser to fail
* @param partialResults a function that returns an row array, which is the
partial results of
* parsing this bad record.
- * @param cause the actual exception about why the record is bad and can't be
parsed.
+ * @param cause the actual exception about why the record is bad and can't be
parsed. It's better
+ * to use lightweight exception here (e.g. without
stacktrace), and throw an
+ * adequate (user-facing) exception only in case it's
necessary after
+ * unwrapping `BadRecordException`
*/
case class BadRecordException(
@transient record: () => UTF8String,
@transient partialResults: () => Array[InternalRow] = () =>
Array.empty[InternalRow],
-cause: Throwable) extends Exception(cause)
+cause: Throwable) extends Exception(cause) {
Review Comment:
Yea, it's user-facing there:

--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
Re: [PR] [SPARK-48143][SQL] Use lightweight exceptions for control-flow between UnivocityParser and FailureSafeParser [spark]
vladimirg-db commented on code in PR #46400:
URL: https://github.com/apache/spark/pull/46400#discussion_r1591287417
##
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/util/BadRecordException.scala:
##
@@ -67,16 +67,23 @@ case class PartialResultArrayException(
extends Exception(cause)
/**
- * Exception thrown when the underlying parser meet a bad record and can't
parse it.
+ * Exception thrown when the underlying parser meets a bad record and can't
parse it. Used for
+ * control flow between wrapper and underlying parser without overhead of
creating a full exception.
* @param record a function to return the record that cause the parser to fail
* @param partialResults a function that returns an row array, which is the
partial results of
* parsing this bad record.
- * @param cause the actual exception about why the record is bad and can't be
parsed.
+ * @param cause the actual exception about why the record is bad and can't be
parsed. It's better
+ * to use lightweight exception here (e.g. without
stacktrace), and throw an
+ * adequate (user-facing) exception only in case it's
necessary after
+ * unwrapping `BadRecordException`
*/
case class BadRecordException(
@transient record: () => UTF8String,
@transient partialResults: () => Array[InternalRow] = () =>
Array.empty[InternalRow],
-cause: Throwable) extends Exception(cause)
+cause: Throwable) extends Exception(cause) {
Review Comment:
Oh I found one place:
https://github.com/apache/spark/blob/7c728b2c2d6cbe2b8310cd8cf8aa4c2528b489c8/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/jsonExpressions.scala#L720
It throws
`QueryExecutionErrors.malformedRecordsDetectedInRecordParsingError`, but with a
`BadRecordException` cause, which has a real cause embedded inside. I wonder if
we would break this place by omitting the cause...
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
Re: [PR] [SPARK-48143][SQL] Use lightweight exceptions for control-flow between UnivocityParser and FailureSafeParser [spark]
vladimirg-db commented on code in PR #46400:
URL: https://github.com/apache/spark/pull/46400#discussion_r1591119148
##
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/util/BadRecordException.scala:
##
@@ -67,16 +67,23 @@ case class PartialResultArrayException(
extends Exception(cause)
/**
- * Exception thrown when the underlying parser meet a bad record and can't
parse it.
+ * Exception thrown when the underlying parser meets a bad record and can't
parse it. Used for
+ * control flow between wrapper and underlying parser without overhead of
creating a full exception.
* @param record a function to return the record that cause the parser to fail
* @param partialResults a function that returns an row array, which is the
partial results of
* parsing this bad record.
- * @param cause the actual exception about why the record is bad and can't be
parsed.
+ * @param cause the actual exception about why the record is bad and can't be
parsed. It's better
+ * to use lightweight exception here (e.g. without
stacktrace), and throw an
+ * adequate (user-facing) exception only in case it's
necessary after
+ * unwrapping `BadRecordException`
*/
case class BadRecordException(
@transient record: () => UTF8String,
@transient partialResults: () => Array[InternalRow] = () =>
Array.empty[InternalRow],
-cause: Throwable) extends Exception(cause)
+cause: Throwable) extends Exception(cause) {
Review Comment:
I wanted to make something like this, but the diff turned out to be quite
large (too large for that performance optimization ticket). But I can propose a
compromise - make 2 constructors (one with the value, and the other one with
the factory function), and proceed with a larger refactoring later.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
Re: [PR] [SPARK-48143][SQL] Use lightweight exceptions for control-flow between UnivocityParser and FailureSafeParser [spark]
cloud-fan commented on code in PR #46400:
URL: https://github.com/apache/spark/pull/46400#discussion_r159106
##
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/util/BadRecordException.scala:
##
@@ -67,16 +67,23 @@ case class PartialResultArrayException(
extends Exception(cause)
/**
- * Exception thrown when the underlying parser meet a bad record and can't
parse it.
+ * Exception thrown when the underlying parser meets a bad record and can't
parse it. Used for
+ * control flow between wrapper and underlying parser without overhead of
creating a full exception.
* @param record a function to return the record that cause the parser to fail
* @param partialResults a function that returns an row array, which is the
partial results of
* parsing this bad record.
- * @param cause the actual exception about why the record is bad and can't be
parsed.
+ * @param cause the actual exception about why the record is bad and can't be
parsed. It's better
+ * to use lightweight exception here (e.g. without
stacktrace), and throw an
+ * adequate (user-facing) exception only in case it's
necessary after
+ * unwrapping `BadRecordException`
*/
case class BadRecordException(
@transient record: () => UTF8String,
@transient partialResults: () => Array[InternalRow] = () =>
Array.empty[InternalRow],
-cause: Throwable) extends Exception(cause)
+cause: Throwable) extends Exception(cause) {
Review Comment:
do we never throw `BadRecordException` directly? then its `cause` doesn't
matter and we can make it take a function to generate the actual error.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[PR] [SPARK-48143][SQL] Use lightweight exceptions for control-flow between UnivocityParser and FailureSafeParser [spark]
vladimirg-db opened a new pull request, #46400: URL: https://github.com/apache/spark/pull/46400 # What changes were proposed in this pull request? New lightweight exception for control-flow between UnivocityParser and FalureSafeParser to speed-up malformed CSV parsing ### Why are the changes needed? Parsing in `PermissiveMode` is slow due to heavy exception construction (stacktrace filling + string template substitution in `SparkRuntimeException`) ### Does this PR introduce _any_ user-facing change? No, since `FailureSafeParser` unwraps `BadRecordException` and correctly rethrows exceptions in `FailFastMode` ### How was this patch tested? - `testOnly org.apache.spark.sql.catalyst.csv.UnivocityParserSuite` - Manually run csv benchmark on DB benchmark workspace - Manually checked correct and malformed csv in sherk-shell (org.apache.spark.SparkException is thrown with the stacktrace) ### Was this patch authored or co-authored using generative AI tooling? No -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org