Repository: spark Updated Branches: refs/heads/branch-2.3 9632c461e -> 2b80571e2
[SPARK-23313][DOC] Add a migration guide for ORC ## What changes were proposed in this pull request? This PR adds a migration guide documentation for ORC. 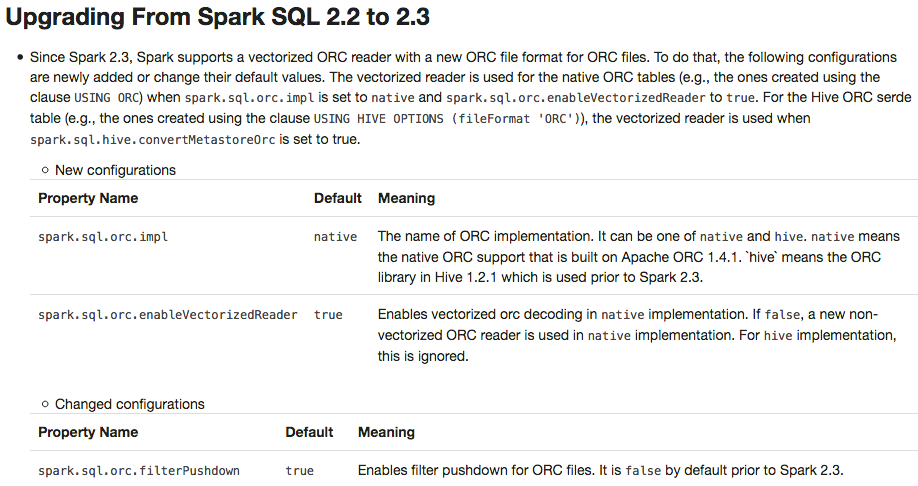 ## How was this patch tested? N/A. Author: Dongjoon Hyun <dongj...@apache.org> Closes #20484 from dongjoon-hyun/SPARK-23313. (cherry picked from commit 6cb59708c70c03696c772fbb5d158eed57fe67d4) Signed-off-by: gatorsmile <gatorsm...@gmail.com> Project: http://git-wip-us.apache.org/repos/asf/spark/repo Commit: http://git-wip-us.apache.org/repos/asf/spark/commit/2b80571e Tree: http://git-wip-us.apache.org/repos/asf/spark/tree/2b80571e Diff: http://git-wip-us.apache.org/repos/asf/spark/diff/2b80571e Branch: refs/heads/branch-2.3 Commit: 2b80571e215d56d15c59f0fc5db053569a79efae Parents: 9632c46 Author: Dongjoon Hyun <dongj...@apache.org> Authored: Mon Feb 12 15:26:37 2018 -0800 Committer: gatorsmile <gatorsm...@gmail.com> Committed: Mon Feb 12 15:27:00 2018 -0800 ---------------------------------------------------------------------- docs/sql-programming-guide.md | 29 +++++++++++++++++++++++++++++ 1 file changed, 29 insertions(+) ---------------------------------------------------------------------- http://git-wip-us.apache.org/repos/asf/spark/blob/2b80571e/docs/sql-programming-guide.md ---------------------------------------------------------------------- diff --git a/docs/sql-programming-guide.md b/docs/sql-programming-guide.md index eab4030..dcef6e5 100644 --- a/docs/sql-programming-guide.md +++ b/docs/sql-programming-guide.md @@ -1776,6 +1776,35 @@ working with timestamps in `pandas_udf`s to get the best performance, see ## Upgrading From Spark SQL 2.2 to 2.3 + - Since Spark 2.3, Spark supports a vectorized ORC reader with a new ORC file format for ORC files. To do that, the following configurations are newly added or change their default values. The vectorized reader is used for the native ORC tables (e.g., the ones created using the clause `USING ORC`) when `spark.sql.orc.impl` is set to `native` and `spark.sql.orc.enableVectorizedReader` is set to `true`. For the Hive ORC serde table (e.g., the ones created using the clause `USING HIVE OPTIONS (fileFormat 'ORC')`), the vectorized reader is used when `spark.sql.hive.convertMetastoreOrc` is set to `true`. + + - New configurations + + <table class="table"> + <tr><th><b>Property Name</b></th><th><b>Default</b></th><th><b>Meaning</b></th></tr> + <tr> + <td><code>spark.sql.orc.impl</code></td> + <td><code>native</code></td> + <td>The name of ORC implementation. It can be one of <code>native</code> and <code>hive</code>. <code>native</code> means the native ORC support that is built on Apache ORC 1.4.1. `hive` means the ORC library in Hive 1.2.1 which is used prior to Spark 2.3.</td> + </tr> + <tr> + <td><code>spark.sql.orc.enableVectorizedReader</code></td> + <td><code>true</code></td> + <td>Enables vectorized orc decoding in <code>native</code> implementation. If <code>false</code>, a new non-vectorized ORC reader is used in <code>native</code> implementation. For <code>hive</code> implementation, this is ignored.</td> + </tr> + </table> + + - Changed configurations + + <table class="table"> + <tr><th><b>Property Name</b></th><th><b>Default</b></th><th><b>Meaning</b></th></tr> + <tr> + <td><code>spark.sql.orc.filterPushdown</code></td> + <td><code>true</code></td> + <td>Enables filter pushdown for ORC files. It is <code>false</code> by default prior to Spark 2.3.</td> + </tr> + </table> + - Since Spark 2.3, the queries from raw JSON/CSV files are disallowed when the referenced columns only include the internal corrupt record column (named `_corrupt_record` by default). For example, `spark.read.schema(schema).json(file).filter($"_corrupt_record".isNotNull).count()` and `spark.read.schema(schema).json(file).select("_corrupt_record").show()`. Instead, you can cache or save the parsed results and then send the same query. For example, `val df = spark.read.schema(schema).json(file).cache()` and then `df.filter($"_corrupt_record".isNotNull).count()`. - The `percentile_approx` function previously accepted numeric type input and output double type results. Now it supports date type, timestamp type and numeric types as input types. The result type is also changed to be the same as the input type, which is more reasonable for percentiles. - Since Spark 2.3, the Join/Filter's deterministic predicates that are after the first non-deterministic predicates are also pushed down/through the child operators, if possible. In prior Spark versions, these filters are not eligible for predicate pushdown. --------------------------------------------------------------------- To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
{kind=link}