Github user wangyum commented on a diff in the pull request:
https://github.com/apache/spark/pull/18323#discussion_r130526538
--- Diff:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/mathExpressions.scala
---
@@ -1186,3 +1186,124 @@ case class BRound(child: Expression, scale:
Expression)
with Serializable with ImplicitCastInputTypes {
def this(child: Expression) = this(child, Literal(0))
}
+
+/**
+ * Returns the bucket number into which
+ * the value of this expression would fall after being evaluated.
+ *
+ * @param expr is the expression for which the histogram is being created
+ * @param minValue is an expression that resolves
+ * to the minimum end point of the acceptable range for
expr
+ * @param maxValue is an expression that resolves
+ * to the maximum end point of the acceptable range for
expr
+ * @param numBucket is an expression that resolves to
+ * a constant indicating the number of buckets
+ */
+// scalastyle:off line.size.limit
+@ExpressionDescription(
+ usage = "_FUNC_(expr, min_value, max_value, num_bucket) - Returns the
`bucket` to which operand would be assigned in an equidepth histogram with
`num_bucket` buckets, in the range `min_value` to `max_value`.",
+ extended = """
+ Examples:
+ > SELECT _FUNC_(5.35, 0.024, 10.06, 5);
+ 3
+ """)
+// scalastyle:on line.size.limit
+case class WidthBucket(
+ expr: Expression,
+ minValue: Expression,
+ maxValue: Expression,
+ numBucket: Expression) extends QuaternaryExpression with
ImplicitCastInputTypes {
+
+ override def children: Seq[Expression] = Seq(expr, minValue, maxValue,
numBucket)
+ override def inputTypes: Seq[AbstractDataType] = Seq(DoubleType,
DoubleType, DoubleType, LongType)
+ override def dataType: DataType = LongType
+ override def nullable: Boolean = true
+
+ private val isFoldable = minValue.foldable && maxValue.foldable &&
numBucket.foldable
+
+ private lazy val _minValue: Any = minValue.eval(EmptyRow)
+ private lazy val minValueV = _minValue.asInstanceOf[Double]
+
+ private lazy val _maxValue: Any = maxValue.eval(EmptyRow)
+ private lazy val maxValueV = _maxValue.asInstanceOf[Double]
+
+ private lazy val _numBucket: Any = numBucket.eval(EmptyRow)
+ private lazy val numBucketV = _numBucket.asInstanceOf[Long]
+
+ private val errMsg = "The argument [%d] of WIDTH_BUCKET function is NULL
or invalid."
+
+ override def eval(input: InternalRow): Any = {
+
+ if (isFoldable) {
+ if (_minValue == null) {
+ throw new RuntimeException(errMsg.format(2))
+ } else if (_maxValue == null) {
+ throw new RuntimeException(errMsg.format(3))
+ } else if (_numBucket == null || numBucketV <= 0) {
+ throw new RuntimeException(errMsg.format(4))
--- End diff --
To be consistent with oracle:
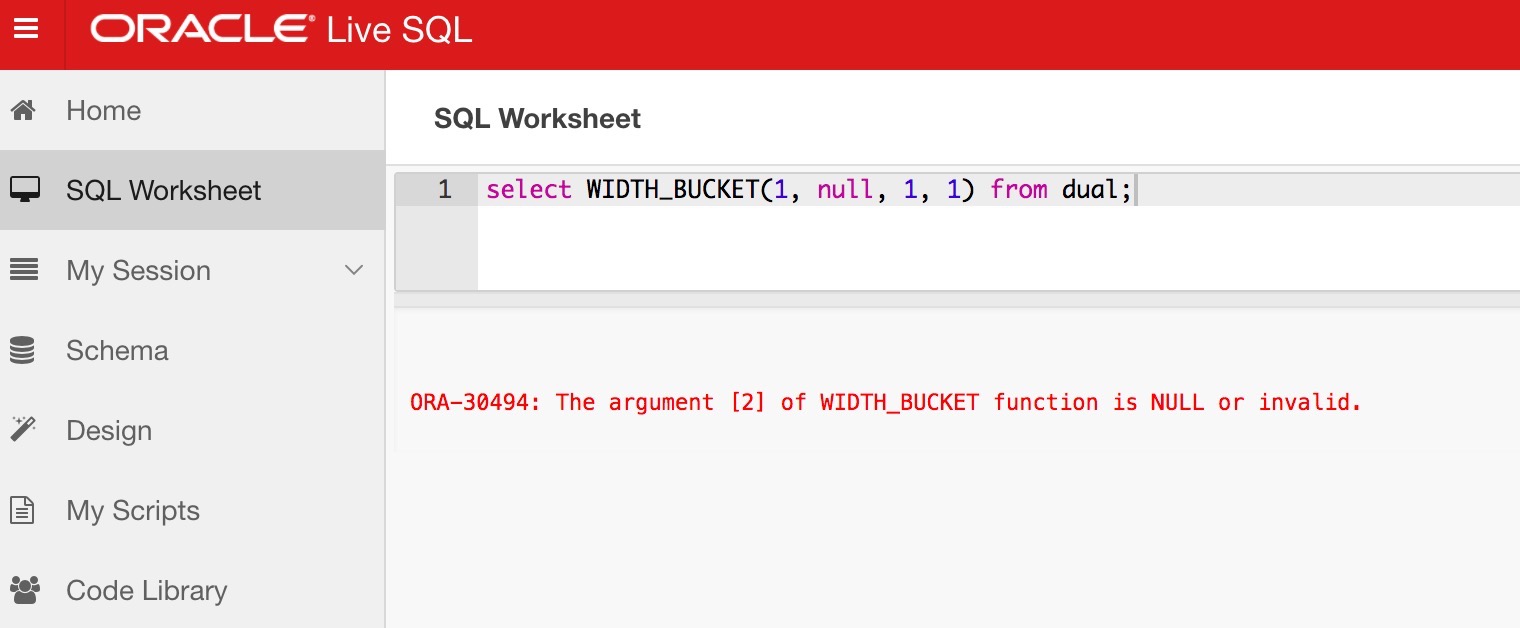
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
{kind=link}