Github user marmbrus commented on a diff in the pull request:
https://github.com/apache/spark/pull/20647#discussion_r169799465
--- Diff:
sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/v2/DataSourceV2Relation.scala
---
@@ -107,17 +106,24 @@ case class DataSourceV2Relation(
}
/**
- * A specialization of DataSourceV2Relation with the streaming bit set to
true. Otherwise identical
- * to the non-streaming relation.
+ * A specialization of [[DataSourceV2Relation]] with the streaming bit set
to true.
+ *
+ * Note that, this plan has a mutable reader, so Spark won't apply
operator push-down for this plan,
+ * to avoid making the plan mutable. We should consolidate this plan and
[[DataSourceV2Relation]]
+ * after we figure out how to apply operator push-down for streaming data
sources.
--- End diff --
@rdblue as well.
I agree that we really need to define the contract here, and personally I
would really benefit from seeing a life cycle diagram for all of the different
pieces of the API. @tdas and @jose-torres made one for just the write side of
streaming and it was super useful for me as someone at a distance that wants to
understand what was going on.
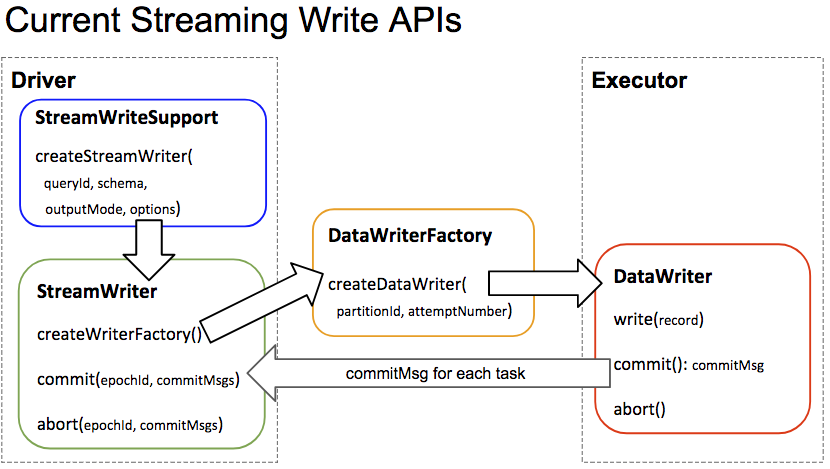
Something like this diagram that also covered when things are resolved,
when pushdown happens, and that shows the differences between read/write,
microbatch, batch and continuous would be awesome.
Regarding the actual question, I'm not a huge fan of option 2 as it still
seems like an implicit contract with this mutable object (assuming I understand
the proposal correctly). Option 1 at least means that we could say, "whenever
its time to do pushdown: call `reset()`, do pushdown in some defined order,
then call `createX()`. It is invalid to do more pushdown after createX has
been called".
Even better than a `reset()` might be a `cleanClone()` method that gives
you a fresh copy. As I said above, I don't really understand the lifecycle of
the API, but given how we reuse query plan fragments I'm really nervous about
mutable objects that are embedded in operators.
I also agree with @jose-torres point that this mechanism looks like action
at a distance, but the `reset()` contract at least localizes it to some degree,
and I don't have a better suggestion for a way to support evolvable pushdown.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
{kind=link}