GitHub user shshahpk opened a pull request:
https://github.com/apache/spark/pull/21726
Branch 2.3
## What changes were proposed in this pull request?
(Please fill in changes proposed in this fix)
## How was this patch tested?
(Please explain how this patch was tested. E.g. unit tests, integration
tests, manual tests)
(If this patch involves UI changes, please attach a screenshot; otherwise,
remove this)
Please review http://spark.apache.org/contributing.html before opening a
pull request.
You can merge this pull request into a Git repository by running:
$ git pull https://github.com/apache/spark branch-2.3
Alternatively you can review and apply these changes as the patch at:
https://github.com/apache/spark/pull/21726.patch
To close this pull request, make a commit to your master/trunk branch
with (at least) the following in the commit message:
This closes #21726
----
commit dfb16147791ff87342ff852105420a5eac5c553b
Author: Dongjoon Hyun <dongjoon@...>
Date: 2018-02-09T04:54:57Z
[SPARK-23186][SQL] Initialize DriverManager first before loading JDBC
Drivers
## What changes were proposed in this pull request?
Since some JDBC Drivers have class initialization code to call
`DriverManager`, we need to initialize `DriverManager` first in order to avoid
potential executor-side **deadlock** situations like the following (or
[STORM-2527](https://issues.apache.org/jira/browse/STORM-2527)).
```
Thread 9587: (state = BLOCKED)
-
sun.reflect.NativeConstructorAccessorImpl.newInstance0(java.lang.reflect.Constructor,
java.lang.Object[]) bci=0 (Compiled frame; information may be imprecise)
-
sun.reflect.NativeConstructorAccessorImpl.newInstance(java.lang.Object[])
bci=85, line=62 (Compiled frame)
-
sun.reflect.DelegatingConstructorAccessorImpl.newInstance(java.lang.Object[])
bci=5, line=45 (Compiled frame)
- java.lang.reflect.Constructor.newInstance(java.lang.Object[]) bci=79,
line=423 (Compiled frame)
- java.lang.Class.newInstance() bci=138, line=442 (Compiled frame)
- java.util.ServiceLoader$LazyIterator.nextService() bci=119, line=380
(Interpreted frame)
- java.util.ServiceLoader$LazyIterator.next() bci=11, line=404
(Interpreted frame)
- java.util.ServiceLoader$1.next() bci=37, line=480 (Interpreted frame)
- java.sql.DriverManager$2.run() bci=21, line=603 (Interpreted frame)
- java.sql.DriverManager$2.run() bci=1, line=583 (Interpreted frame)
-
java.security.AccessController.doPrivileged(java.security.PrivilegedAction)
bci=0 (Compiled frame)
- java.sql.DriverManager.loadInitialDrivers() bci=27, line=583
(Interpreted frame)
- java.sql.DriverManager.<clinit>() bci=32, line=101 (Interpreted frame)
-
org.apache.phoenix.mapreduce.util.ConnectionUtil.getConnection(java.lang.String,
java.lang.Integer, java.lang.String, java.util.Properties) bci=12, line=98
(Interpreted frame)
-
org.apache.phoenix.mapreduce.util.ConnectionUtil.getInputConnection(org.apache.hadoop.conf.Configuration,
java.util.Properties) bci=22, line=57 (Interpreted frame)
-
org.apache.phoenix.mapreduce.PhoenixInputFormat.getQueryPlan(org.apache.hadoop.mapreduce.JobContext,
org.apache.hadoop.conf.Configuration) bci=61, line=116 (Interpreted frame)
-
org.apache.phoenix.mapreduce.PhoenixInputFormat.createRecordReader(org.apache.hadoop.mapreduce.InputSplit,
org.apache.hadoop.mapreduce.TaskAttemptContext) bci=10, line=71 (Interpreted
frame)
-
org.apache.spark.rdd.NewHadoopRDD$$anon$1.<init>(org.apache.spark.rdd.NewHadoopRDD,
org.apache.spark.Partition, org.apache.spark.TaskContext) bci=233, line=156
(Interpreted frame)
Thread 9170: (state = BLOCKED)
- org.apache.phoenix.jdbc.PhoenixDriver.<clinit>() bci=35, line=125
(Interpreted frame)
-
sun.reflect.NativeConstructorAccessorImpl.newInstance0(java.lang.reflect.Constructor,
java.lang.Object[]) bci=0 (Compiled frame)
-
sun.reflect.NativeConstructorAccessorImpl.newInstance(java.lang.Object[])
bci=85, line=62 (Compiled frame)
-
sun.reflect.DelegatingConstructorAccessorImpl.newInstance(java.lang.Object[])
bci=5, line=45 (Compiled frame)
- java.lang.reflect.Constructor.newInstance(java.lang.Object[]) bci=79,
line=423 (Compiled frame)
- java.lang.Class.newInstance() bci=138, line=442 (Compiled frame)
-
org.apache.spark.sql.execution.datasources.jdbc.DriverRegistry$.register(java.lang.String)
bci=89, line=46 (Interpreted frame)
-
org.apache.spark.sql.execution.datasources.jdbc.JdbcUtils$$anonfun$createConnectionFactory$2.apply()
bci=7, line=53 (Interpreted frame)
-
org.apache.spark.sql.execution.datasources.jdbc.JdbcUtils$$anonfun$createConnectionFactory$2.apply()
bci=1, line=52 (Interpreted frame)
-
org.apache.spark.sql.execution.datasources.jdbc.JDBCRDD$$anon$1.<init>(org.apache.spark.sql.execution.datasources.jdbc.JDBCRDD,
org.apache.spark.Partition, org.apache.spark.TaskContext) bci=81, line=347
(Interpreted frame)
-
org.apache.spark.sql.execution.datasources.jdbc.JDBCRDD.compute(org.apache.spark.Partition,
org.apache.spark.TaskContext) bci=7, line=339 (Interpreted frame)
```
## How was this patch tested?
N/A
Author: Dongjoon Hyun <dongj...@apache.org>
Closes #20359 from dongjoon-hyun/SPARK-23186.
(cherry picked from commit 8cbcc33876c773722163b2259644037bbb259bd1)
Signed-off-by: Wenchen Fan <wenc...@databricks.com>
commit 196304a3a8ed15fd018e9c7b441954d17bd60124
Author: hyukjinkwon <gurwls223@...>
Date: 2018-02-09T06:21:10Z
[SPARK-23328][PYTHON] Disallow default value None in na.replace/replace
when 'to_replace' is not a dictionary
## What changes were proposed in this pull request?
This PR proposes to disallow default value None when 'to_replace' is not a
dictionary.
It seems weird we set the default value of `value` to `None` and we ended
up allowing the case as below:
```python
>>> df.show()
```
```
+----+------+-----+
| age|height| name|
+----+------+-----+
| 10| 80|Alice|
...
```
```python
>>> df.na.replace('Alice').show()
```
```
+----+------+----+
| age|height|name|
+----+------+----+
| 10| 80|null|
...
```
**After**
This PR targets to disallow the case above:
```python
>>> df.na.replace('Alice').show()
```
```
...
TypeError: value is required when to_replace is not a dictionary.
```
while we still allow when `to_replace` is a dictionary:
```python
>>> df.na.replace({'Alice': None}).show()
```
```
+----+------+----+
| age|height|name|
+----+------+----+
| 10| 80|null|
...
```
## How was this patch tested?
Manually tested, tests were added in `python/pyspark/sql/tests.py` and
doctests were fixed.
Author: hyukjinkwon <gurwls...@gmail.com>
Closes #20499 from HyukjinKwon/SPARK-19454-followup.
(cherry picked from commit 4b4ee2601079f12f8f410a38d2081793cbdedc14)
Signed-off-by: Wenchen Fan <wenc...@databricks.com>
commit 08eb95f609f5d356c89dedcefa768b12a7a8b96c
Author: liuxian <liu.xian3@...>
Date: 2018-02-09T14:45:06Z
[SPARK-23358][CORE] When the number of partitions is greater than 2^28, it
will result in an error result
## What changes were proposed in this pull request?
In the `checkIndexAndDataFile`,the `blocks` is the ` Int` type, when it is
greater than 2^28, `blocks*8` will overflow, and this will result in an error
result.
In fact, `blocks` is actually the number of partitions.
## How was this patch tested?
Manual test
Author: liuxian <liu.xi...@zte.com.cn>
Closes #20544 from 10110346/overflow.
(cherry picked from commit f77270b8811bbd8956d0c08fa556265d2c5ee20e)
Signed-off-by: Sean Owen <so...@cloudera.com>
commit 49771ac8da8e68e8412d9f5d181953eaf0de7973
Author: Jacek Laskowski <jacek@...>
Date: 2018-02-10T00:18:30Z
[MINOR][HIVE] Typo fixes
## What changes were proposed in this pull request?
Typo fixes (with expanding a Hive property)
## How was this patch tested?
local build. Awaiting Jenkins
Author: Jacek Laskowski <ja...@japila.pl>
Closes #20550 from jaceklaskowski/hiveutils-typos.
(cherry picked from commit 557938e2839afce26a10a849a2a4be8fc4580427)
Signed-off-by: Sean Owen <so...@cloudera.com>
commit f3a9a7f6b6eac4421bd74ff73a74105982604ce6
Author: Feng Liu <fengliu@...>
Date: 2018-02-10T00:21:47Z
[SPARK-23275][SQL] fix the thread leaking in hive/tests
## What changes were proposed in this pull request?
This is a follow up of https://github.com/apache/spark/pull/20441.
The two lines actually can trigger the hive metastore bug:
https://issues.apache.org/jira/browse/HIVE-16844
The two configs are not in the default `ObjectStore` properties, so any run
hive commands after these two lines will set the `propsChanged` flag in the
`ObjectStore.setConf` and then cause thread leaks.
I don't think the two lines are very useful. They can be removed safely.
## How was this patch tested?
(Please explain how this patch was tested. E.g. unit tests, integration
tests, manual tests)
(If this patch involves UI changes, please attach a screenshot; otherwise,
remove this)
Please review http://spark.apache.org/contributing.html before opening a
pull request.
Author: Feng Liu <feng...@databricks.com>
Closes #20562 from liufengdb/fix-omm.
(cherry picked from commit 6d7c38330e68c7beb10f54eee8b4f607ee3c4136)
Signed-off-by: gatorsmile <gatorsm...@gmail.com>
commit b7571b9bfcced2e08f87e815c2ea9474bfd5fe2a
Author: Takuya UESHIN <ueshin@...>
Date: 2018-02-10T16:08:02Z
[SPARK-23360][SQL][PYTHON] Get local timezone from environment via pytz, or
dateutil.
## What changes were proposed in this pull request?
Currently we use `tzlocal()` to get Python local timezone, but it sometimes
causes unexpected behavior.
I changed the way to get Python local timezone to use pytz if the timezone
is specified in environment variable, or timezone file via dateutil .
## How was this patch tested?
Added a test and existing tests.
Author: Takuya UESHIN <ues...@databricks.com>
Closes #20559 from ueshin/issues/SPARK-23360/master.
(cherry picked from commit 97a224a855c4410b2dfb9c0bcc6aae583bd28e92)
Signed-off-by: hyukjinkwon <gurwls...@gmail.com>
commit 9fa7b0e107c283557648160195ce179077752e4c
Author: Li Jin <ice.xelloss@...>
Date: 2018-02-11T08:31:35Z
[SPARK-23314][PYTHON] Add ambiguous=False when localizing tz-naive
timestamps in Arrow codepath to deal with dst
## What changes were proposed in this pull request?
When tz_localize a tz-naive timetamp, pandas will throw exception if the
timestamp is during daylight saving time period, e.g., `2015-11-01 01:30:00`.
This PR fixes this issue by setting `ambiguous=False` when calling tz_localize,
which is the same default behavior of pytz.
## How was this patch tested?
Add `test_timestamp_dst`
Author: Li Jin <ice.xell...@gmail.com>
Closes #20537 from icexelloss/SPARK-23314.
(cherry picked from commit a34fce19bc0ee5a7e36c6ecba75d2aeb70fdcbc7)
Signed-off-by: hyukjinkwon <gurwls...@gmail.com>
commit 8875e47cec01ae8da4ffb855409b54089e1016fb
Author: Takuya UESHIN <ueshin@...>
Date: 2018-02-11T13:16:47Z
[SPARK-23387][SQL][PYTHON][TEST][BRANCH-2.3] Backport assertPandasEqual to
branch-2.3.
## What changes were proposed in this pull request?
When backporting a pr with tests using `assertPandasEqual` from master to
branch-2.3, the tests fail because `assertPandasEqual` doesn't exist in
branch-2.3.
We should backport `assertPandasEqual` to branch-2.3 to avoid the failures.
## How was this patch tested?
Modified tests.
Author: Takuya UESHIN <ues...@databricks.com>
Closes #20577 from ueshin/issues/SPARK-23387/branch-2.3.
commit 7e2a2b33c0664b3638a1428688b28f68323994c1
Author: Wenchen Fan <wenchen@...>
Date: 2018-02-11T16:03:49Z
[SPARK-23376][SQL] creating UnsafeKVExternalSorter with BytesToBytesMap may
fail
## What changes were proposed in this pull request?
This is a long-standing bug in `UnsafeKVExternalSorter` and was reported in
the dev list multiple times.
When creating `UnsafeKVExternalSorter` with `BytesToBytesMap`, we need to
create a `UnsafeInMemorySorter` to sort the data in `BytesToBytesMap`. The data
format of the sorter and the map is same, so no data movement is required.
However, both the sorter and the map need a point array for some bookkeeping
work.
There is an optimization in `UnsafeKVExternalSorter`: reuse the point array
between the sorter and the map, to avoid an extra memory allocation. This
sounds like a reasonable optimization, the length of the `BytesToBytesMap`
point array is at least 4 times larger than the number of keys(to avoid hash
collision, the hash table size should be at least 2 times larger than the
number of keys, and each key occupies 2 slots). `UnsafeInMemorySorter` needs
the pointer array size to be 4 times of the number of entries, so we are safe
to reuse the point array.
However, the number of keys of the map doesn't equal to the number of
entries in the map, because `BytesToBytesMap` supports duplicated keys. This
breaks the assumption of the above optimization and we may run out of space
when inserting data into the sorter, and hit error
```
java.lang.IllegalStateException: There is no space for new record
at
org.apache.spark.util.collection.unsafe.sort.UnsafeInMemorySorter.insertRecord(UnsafeInMemorySorter.java:239)
at
org.apache.spark.sql.execution.UnsafeKVExternalSorter.<init>(UnsafeKVExternalSorter.java:149)
...
```
This PR fixes this bug by creating a new point array if the existing one is
not big enough.
## How was this patch tested?
a new test
Author: Wenchen Fan <wenc...@databricks.com>
Closes #20561 from cloud-fan/bug.
(cherry picked from commit 4bbd7443ebb005f81ed6bc39849940ac8db3b3cc)
Signed-off-by: Wenchen Fan <wenc...@databricks.com>
commit 79e8650cccb00c7886efba6dd691d9733084cb81
Author: Wenchen Fan <wenchen@...>
Date: 2018-02-12T07:46:23Z
[SPARK-23390][SQL] Flaky Test Suite: FileBasedDataSourceSuite in Spark
2.3/hadoop 2.7
## What changes were proposed in this pull request?
This test only fails with sbt on Hadoop 2.7, I can't reproduce it locally,
but here is my speculation by looking at the code:
1. FileSystem.delete doesn't delete the directory entirely, somehow we can
still open the file as a 0-length empty file.(just speculation)
2. ORC intentionally allow empty files, and the reader fails during reading
without closing the file stream.
This PR improves the test to make sure all files are deleted and can't be
opened.
## How was this patch tested?
N/A
Author: Wenchen Fan <wenc...@databricks.com>
Closes #20584 from cloud-fan/flaky-test.
(cherry picked from commit 6efd5d117e98074d1b16a5c991fbd38df9aa196e)
Signed-off-by: Sameer Agarwal <samee...@apache.org>
commit 1e3118c2ee0fe7d2c59cb3e2055709bb2809a6db
Author: Wenchen Fan <wenchen@...>
Date: 2018-02-12T14:07:59Z
[SPARK-22977][SQL] fix web UI SQL tab for CTAS
## What changes were proposed in this pull request?
This is a regression in Spark 2.3.
In Spark 2.2, we have a fragile UI support for SQL data writing commands.
We only track the input query plan of `FileFormatWriter` and display its
metrics. This is not ideal because we don't know who triggered the writing(can
be table insertion, CTAS, etc.), but it's still useful to see the metrics of
the input query.
In Spark 2.3, we introduced a new mechanism: `DataWritigCommand`, to fix
the UI issue entirely. Now these writing commands have real children, and we
don't need to hack into the `FileFormatWriter` for the UI. This also helps with
`explain`, now `explain` can show the physical plan of the input query, while
in 2.2 the physical writing plan is simply `ExecutedCommandExec` and it has no
child.
However there is a regression in CTAS. CTAS commands don't extend
`DataWritigCommand`, and we don't have the UI hack in `FileFormatWriter`
anymore, so the UI for CTAS is just an empty node. See
https://issues.apache.org/jira/browse/SPARK-22977 for more information about
this UI issue.
To fix it, we should apply the `DataWritigCommand` mechanism to CTAS
commands.
TODO: In the future, we should refactor this part and create some physical
layer code pieces for data writing, and reuse them in different writing
commands. We should have different logical nodes for different operators, even
some of them share some same logic, e.g. CTAS, CREATE TABLE, INSERT TABLE.
Internally we can share the same physical logic.
## How was this patch tested?
manually tested.
For data source table
<img width="644" alt="1"
src="https://user-images.githubusercontent.com/3182036/35874155-bdffab28-0ba6-11e8-94a8-e32e106ba069.png";>
For hive table
<img width="666" alt="2"
src="https://user-images.githubusercontent.com/3182036/35874161-c437e2a8-0ba6-11e8-98ed-7930f01432c5.png";>
Author: Wenchen Fan <wenc...@databricks.com>
Closes #20521 from cloud-fan/UI.
(cherry picked from commit 0e2c266de7189473177f45aa68ea6a45c7e47ec3)
Signed-off-by: Wenchen Fan <wenc...@databricks.com>
commit d31c4ae7ba734356c849347b9a7b448da9a5a9a1
Author: liuxian <liu.xian3@...>
Date: 2018-02-12T14:49:45Z
[SPARK-23391][CORE] It may lead to overflow for some integer multiplication
## What changes were proposed in this pull request?
In the `getBlockData`,`blockId.reduceId` is the `Int` type, when it is
greater than 2^28, `blockId.reduceId*8` will overflow
In the `decompress0`, `len` and `unitSize` are Int type, so `len *
unitSize` may lead to overflow
## How was this patch tested?
N/A
Author: liuxian <liu.xi...@zte.com.cn>
Closes #20581 from 10110346/overflow2.
(cherry picked from commit 4a4dd4f36f65410ef5c87f7b61a960373f044e61)
Signed-off-by: Sean Owen <so...@cloudera.com>
commit 89f6fcbafcfb0a7aeb897fba6036cb085bd35121
Author: Sameer Agarwal <sameerag@...>
Date: 2018-02-12T19:08:28Z
Preparing Spark release v2.3.0-rc3
commit 70be6038df38d5e80af8565120eedd8242c5a7c5
Author: Sameer Agarwal <sameerag@...>
Date: 2018-02-12T19:08:34Z
Preparing development version 2.3.1-SNAPSHOT
commit 4e138207ebb11a08393c15e5e39f46a5dc1e7c66
Author: James Thompson <jamesthomp@...>
Date: 2018-02-12T19:34:56Z
[SPARK-23388][SQL] Support for Parquet Binary DecimalType in
VectorizedColumnReader
## What changes were proposed in this pull request?
Re-add support for parquet binary DecimalType in VectorizedColumnReader
## How was this patch tested?
Existing test suite
Author: James Thompson <jamesth...@users.noreply.github.com>
Closes #20580 from jamesthomp/jt/add-back-binary-decimal.
(cherry picked from commit 5bb11411aec18b8d623e54caba5397d7cb8e89f0)
Signed-off-by: gatorsmile <gatorsm...@gmail.com>
commit 9632c461e6931a1a4d05684d0f62ee36f9e90b77
Author: Takuya UESHIN <ueshin@...>
Date: 2018-02-12T20:20:29Z
[SPARK-22002][SQL][FOLLOWUP][TEST] Add a test to check if the original
schema doesn't have metadata.
## What changes were proposed in this pull request?
This is a follow-up pr of #19231 which modified the behavior to remove
metadata from JDBC table schema.
This pr adds a test to check if the schema doesn't have metadata.
## How was this patch tested?
Added a test and existing tests.
Author: Takuya UESHIN <ues...@databricks.com>
Closes #20585 from ueshin/issues/SPARK-22002/fup1.
(cherry picked from commit 0c66fe4f22f8af4932893134bb0fd56f00fabeae)
Signed-off-by: gatorsmile <gatorsm...@gmail.com>
commit 2b80571e215d56d15c59f0fc5db053569a79efae
Author: Dongjoon Hyun <dongjoon@...>
Date: 2018-02-12T23:26:37Z
[SPARK-23313][DOC] Add a migration guide for ORC
## What changes were proposed in this pull request?
This PR adds a migration guide documentation for ORC.
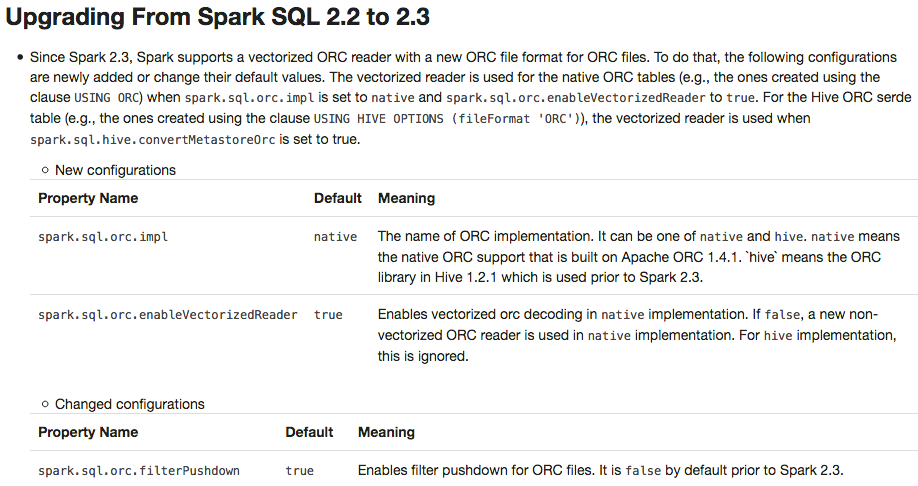
## How was this patch tested?
N/A.
Author: Dongjoon Hyun <dongj...@apache.org>
Closes #20484 from dongjoon-hyun/SPARK-23313.
(cherry picked from commit 6cb59708c70c03696c772fbb5d158eed57fe67d4)
Signed-off-by: gatorsmile <gatorsm...@gmail.com>
commit befb22de81aad41673eec9dba7585b80c6cb2564
Author: sychen <sychen@...>
Date: 2018-02-13T00:00:47Z
[SPARK-23230][SQL] When hive.default.fileformat is other kinds of file
types, create textfile table cause a serde error
When hive.default.fileformat is other kinds of file types, create textfile
table cause a serde error.
We should take the default type of textfile and sequencefile both as
org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe.
```
set hive.default.fileformat=orc;
create table tbl( i string ) stored as textfile;
desc formatted tbl;
Serde Library org.apache.hadoop.hive.ql.io.orc.OrcSerde
InputFormat org.apache.hadoop.mapred.TextInputFormat
OutputFormat org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat
```
Author: sychen <syc...@ctrip.com>
Closes #20406 from cxzl25/default_serde.
(cherry picked from commit 4104b68e958cd13975567a96541dac7cccd8195c)
Signed-off-by: gatorsmile <gatorsm...@gmail.com>
commit 43f5e40679f771326b2ee72f14cf1ab0ed2ad692
Author: hyukjinkwon <gurwls223@...>
Date: 2018-02-13T00:47:28Z
[SPARK-23352][PYTHON][BRANCH-2.3] Explicitly specify supported types in
Pandas UDFs
## What changes were proposed in this pull request?
This PR backports https://github.com/apache/spark/pull/20531:
It explicitly specifies supported types in Pandas UDFs.
The main change here is to add a deduplicated and explicit type checking in
`returnType` ahead with documenting this; however, it happened to fix multiple
things.
1. Currently, we don't support `BinaryType` in Pandas UDFs, for example,
see:
```python
from pyspark.sql.functions import pandas_udf
pudf = pandas_udf(lambda x: x, "binary")
df = spark.createDataFrame([[bytearray(1)]])
df.select(pudf("_1")).show()
```
```
...
TypeError: Unsupported type in conversion to Arrow: BinaryType
```
We can document this behaviour for its guide.
2. Since we can check the return type ahead, we can fail fast before actual
execution.
```python
# we can fail fast at this stage because we know the schema ahead
pandas_udf(lambda x: x, BinaryType())
```
## How was this patch tested?
Manually tested and unit tests for `BinaryType` and `ArrayType(...)` were
added.
Author: hyukjinkwon <gurwls...@gmail.com>
Closes #20588 from HyukjinKwon/PR_TOOL_PICK_PR_20531_BRANCH-2.3.
commit 3737c3d32bb92e73cadaf3b1b9759d9be00b288d
Author: gatorsmile <gatorsmile@...>
Date: 2018-02-13T06:05:13Z
[SPARK-20090][FOLLOW-UP] Revert the deprecation of `names` in PySpark
## What changes were proposed in this pull request?
Deprecating the field `name` in PySpark is not expected. This PR is to
revert the change.
## How was this patch tested?
N/A
Author: gatorsmile <gatorsm...@gmail.com>
Closes #20595 from gatorsmile/removeDeprecate.
(cherry picked from commit 407f67249639709c40c46917700ed6dd736daa7d)
Signed-off-by: hyukjinkwon <gurwls...@gmail.com>
commit 1c81c0c626f115fbfe121ad6f6367b695e9f3b5f
Author: guoxiaolong <guo.xiaolong1@...>
Date: 2018-02-13T12:23:10Z
[SPARK-23384][WEB-UI] When it has no incomplete(completed) applications
found, the last updated time is not formatted and client local time zone is not
show in history server web ui.
## What changes were proposed in this pull request?
When it has no incomplete(completed) applications found, the last updated
time is not formatted and client local time zone is not show in history server
web ui. It is a bug.
fix before:

fix after:

## How was this patch tested?
(Please explain how this patch was tested. E.g. unit tests, integration
tests, manual tests)
(If this patch involves UI changes, please attach a screenshot; otherwise,
remove this)
Please review http://spark.apache.org/contributing.html before opening a
pull request.
Author: guoxiaolong <guo.xiaolo...@zte.com.cn>
Closes #20573 from guoxiaolongzte/SPARK-23384.
(cherry picked from commit 300c40f50ab4258d697f06a814d1491dc875c847)
Signed-off-by: Sean Owen <so...@cloudera.com>
commit dbb1b399b6cf8372a3659c472f380142146b1248
Author: huangtengfei <huangtengfei@...>
Date: 2018-02-13T15:59:21Z
[SPARK-23053][CORE] taskBinarySerialization and task partitions calculate
in DagScheduler.submitMissingTasks should keep the same RDD checkpoint status
## What changes were proposed in this pull request?
When we run concurrent jobs using the same rdd which is marked to do
checkpoint. If one job has finished running the job, and start the process of
RDD.doCheckpoint, while another job is submitted, then submitStage and
submitMissingTasks will be called. In
[submitMissingTasks](https://github.com/apache/spark/blob/master/core/src/main/scala/org/apache/spark/scheduler/DAGScheduler.scala#L961),
will serialize taskBinaryBytes and calculate task partitions which are both
affected by the status of checkpoint, if the former is calculated before
doCheckpoint finished, while the latter is calculated after doCheckpoint
finished, when run task, rdd.compute will be called, for some rdds with
particular partition type such as
[UnionRDD](https://github.com/apache/spark/blob/master/core/src/main/scala/org/apache/spark/rdd/UnionRDD.scala)
who will do partition type cast, will get a ClassCastException because the
part params is actually a CheckpointRDDPartition.
This error occurs because rdd.doCheckpoint occurs in the same thread that
called sc.runJob, while the task serialization occurs in the DAGSchedulers
event loop.
## How was this patch tested?
the exist uts and also add a test case in DAGScheduerSuite to show the
exception case.
Author: huangtengfei <huangtengfei@huangtengfeideMacBook-Pro.local>
Closes #20244 from ivoson/branch-taskpart-mistype.
(cherry picked from commit 091a000d27f324de8c5c527880854ecfcf5de9a4)
Signed-off-by: Imran Rashid <iras...@cloudera.com>
commit ab01ba718c7752b564e801a1ea546aedc2055dc0
Author: Bogdan Raducanu <bogdan@...>
Date: 2018-02-13T17:49:52Z
[SPARK-23316][SQL] AnalysisException after max iteration reached for IN
query
## What changes were proposed in this pull request?
Added flag ignoreNullability to DataType.equalsStructurally.
The previous semantic is for ignoreNullability=false.
When ignoreNullability=true equalsStructurally ignores nullability of
contained types (map key types, value types, array element types, structure
field types).
In.checkInputTypes calls equalsStructurally to check if the children types
match. They should match regardless of nullability (which is just a hint), so
it is now called with ignoreNullability=true.
## How was this patch tested?
New test in SubquerySuite
Author: Bogdan Raducanu <bog...@databricks.com>
Closes #20548 from bogdanrdc/SPARK-23316.
(cherry picked from commit 05d051293fe46938e9cb012342fea6e8a3715cd4)
Signed-off-by: gatorsmile <gatorsm...@gmail.com>
commit 320ffb1309571faedb271f2c769b4ab1ee1cd267
Author: Joseph K. Bradley <joseph@...>
Date: 2018-02-13T19:18:45Z
[SPARK-23154][ML][DOC] Document backwards compatibility guarantees for ML
persistence
## What changes were proposed in this pull request?
Added documentation about what MLlib guarantees in terms of loading ML
models and Pipelines from old Spark versions. Discussed & confirmed on linked
JIRA.
Author: Joseph K. Bradley <jos...@databricks.com>
Closes #20592 from jkbradley/SPARK-23154-backwards-compat-doc.
(cherry picked from commit d58fe28836639e68e262812d911f167cb071007b)
Signed-off-by: Joseph K. Bradley <jos...@databricks.com>
commit 4f6a457d464096d791e13e57c55bcf23c01c418f
Author: gatorsmile <gatorsmile@...>
Date: 2018-02-13T19:56:49Z
[SPARK-23400][SQL] Add a constructors for ScalaUDF
## What changes were proposed in this pull request?
In this upcoming 2.3 release, we changed the interface of `ScalaUDF`.
Unfortunately, some Spark packages (e.g., spark-deep-learning) are using our
internal class `ScalaUDF`. In the release 2.3, we added new parameters into
this class. The users hit the binary compatibility issues and got the exception:
```
> java.lang.NoSuchMethodError:
org.apache.spark.sql.catalyst.expressions.ScalaUDF.<init>(Ljava/lang/Object;Lorg/apache/spark/sql/types/DataType;Lscala/collection/Seq;Lscala/collection/Seq;Lscala/Option;)V
```
This PR is to improve the backward compatibility. However, we definitely
should not encourage the external packages to use our internal classes. This
might make us hard to maintain/develop the codes in Spark.
## How was this patch tested?
N/A
Author: gatorsmile <gatorsm...@gmail.com>
Closes #20591 from gatorsmile/scalaUDF.
(cherry picked from commit 2ee76c22b6e48e643694c9475e5f0d37124215e7)
Signed-off-by: Shixiong Zhu <zsxw...@gmail.com>
commit bb26bdb55fdf84c4e36fd66af9a15e325a3982d6
Author: Dongjoon Hyun <dongjoon@...>
Date: 2018-02-14T02:55:24Z
[SPARK-23399][SQL] Register a task completion listener first for
OrcColumnarBatchReader
This PR aims to resolve an open file leakage issue reported at
[SPARK-23390](https://issues.apache.org/jira/browse/SPARK-23390) by moving the
listener registration position. Currently, the sequence is like the following.
1. Create `batchReader`
2. `batchReader.initialize` opens a ORC file.
3. `batchReader.initBatch` may take a long time to alloc memory in some
environment and cause errors.
4. `Option(TaskContext.get()).foreach(_.addTaskCompletionListener(_ =>
iter.close()))`
This PR moves 4 before 2 and 3. To sum up, the new sequence is 1 -> 4 -> 2
-> 3.
Manual. The following test case makes OOM intentionally to cause leaked
filesystem connection in the current code base. With this patch, leakage
doesn't occurs.
```scala
// This should be tested manually because it raises OOM intentionally
// in order to cause `Leaked filesystem connection`.
test("SPARK-23399 Register a task completion listener first for
OrcColumnarBatchReader") {
withSQLConf(SQLConf.ORC_VECTORIZED_READER_BATCH_SIZE.key ->
s"${Int.MaxValue}") {
withTempDir { dir =>
val basePath = dir.getCanonicalPath
Seq(0).toDF("a").write.format("orc").save(new Path(basePath,
"first").toString)
Seq(1).toDF("a").write.format("orc").save(new Path(basePath,
"second").toString)
val df = spark.read.orc(
new Path(basePath, "first").toString,
new Path(basePath, "second").toString)
val e = intercept[SparkException] {
df.collect()
}
assert(e.getCause.isInstanceOf[OutOfMemoryError])
}
}
}
```
Author: Dongjoon Hyun <dongj...@apache.org>
Closes #20590 from dongjoon-hyun/SPARK-23399.
(cherry picked from commit 357babde5a8eb9710de7016d7ae82dee21fa4ef3)
Signed-off-by: Wenchen Fan <wenc...@databricks.com>
commit fd66a3b7b151514a9f626444ef8710f64dab6813
Author: âattilapirosâ <piros.attila.zsolt@...>
Date: 2018-02-14T14:45:54Z
[SPARK-23394][UI] In RDD storage page show the executor addresses instead
of the IDs
## What changes were proposed in this pull request?
Extending RDD storage page to show executor addresses in the block table.
## How was this patch tested?
Manually:

Author: âattilapirosâ <piros.attila.zs...@gmail.com>
Closes #20589 from attilapiros/SPARK-23394.
(cherry picked from commit 140f87533a468b1046504fc3ff01fbe1637e41cd)
Signed-off-by: Marcelo Vanzin <van...@cloudera.com>
commit a5a8a86e213c34d6fb32f0ae52db24d8f1ef0905
Author: gatorsmile <gatorsmile@...>
Date: 2018-02-14T18:59:36Z
Revert "[SPARK-23249][SQL] Improved block merging logic for partitions"
This reverts commit f5f21e8c4261c0dfe8e3e788a30b38b188a18f67.
commit bd83f7ba097d9bca9a0e8c072f7566a645887a96
Author: gatorsmile <gatorsmile@...>
Date: 2018-02-15T07:52:59Z
[SPARK-23421][SPARK-22356][SQL] Document the behavior change in
## What changes were proposed in this pull request?
https://github.com/apache/spark/pull/19579 introduces a behavior change. We
need to document it in the migration guide.
## How was this patch tested?
Also update the HiveExternalCatalogVersionsSuite to verify it.
Author: gatorsmile <gatorsm...@gmail.com>
Closes #20606 from gatorsmile/addMigrationGuide.
(cherry picked from commit a77ebb0921e390cf4fc6279a8c0a92868ad7e69b)
Signed-off-by: gatorsmile <gatorsm...@gmail.com>
commit 129fd45efb418c6afa95aa26e5b96f03a39dcdd0
Author: gatorsmile <gatorsmile@...>
Date: 2018-02-15T07:56:02Z
[SPARK-23094] Revert [] Fix invalid character handling in JsonDataSource
## What changes were proposed in this pull request?
This PR is to revert the PR https://github.com/apache/spark/pull/20302,
because it causes a regression.
## How was this patch tested?
N/A
Author: gatorsmile <gatorsm...@gmail.com>
Closes #20614 from gatorsmile/revertJsonFix.
(cherry picked from commit 95e4b4916065e66a4f8dba57e98e725796f75e04)
Signed-off-by: gatorsmile <gatorsm...@gmail.com>
----
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}