GitHub user hehuiyuan opened a pull request:
https://github.com/apache/spark/pull/21812
SPARK UI K8S : this parameter's
illustration(spark.kubernetes.executor.label.[LabelName] )
[é¾æ¥å°åï¼](http://spark.apache.org/docs/2.3.0/running-on-kubernetes.html)
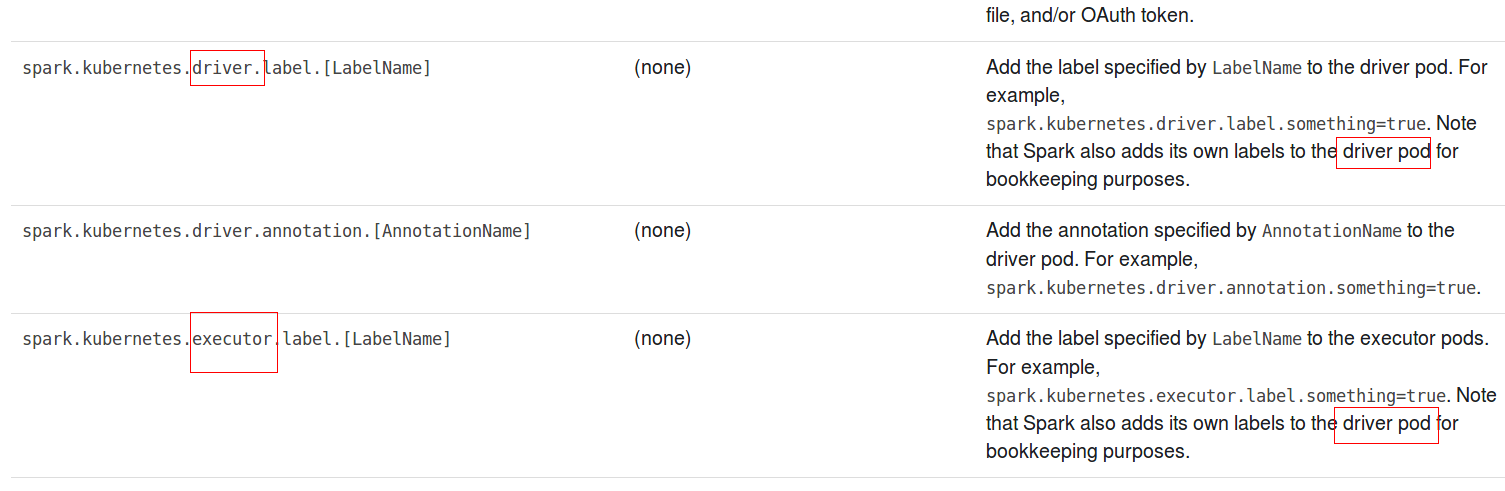
spark.kubernetes.executor.label.[LabelName] ï¼this parameter is for
driver or executor ?
You can merge this pull request into a Git repository by running:
$ git pull https://github.com/apache/spark master
Alternatively you can review and apply these changes as the patch at:
https://github.com/apache/spark/pull/21812.patch
To close this pull request, make a commit to your master/trunk branch
with (at least) the following in the commit message:
This closes #21812
----
commit 8ef167a5f9ba8a79bb7ca98a9844fe9cfcfea060
Author: Xingbo Jiang <xingbo.jiang@...>
Date: 2018-06-01T20:46:05Z
[SPARK-24340][CORE] Clean up non-shuffle disk block manager files following
executor exits on a Standalone cluster
## What changes were proposed in this pull request?
Currently we only clean up the local directories on application removed.
However, when executors die and restart repeatedly, many temp files are left
untouched in the local directories, which is undesired behavior and could cause
disk space used up gradually.
We can detect executor death in the Worker, and clean up the non-shuffle
files (files not ended with ".index" or ".data") in the local directories, we
should not touch the shuffle files since they are expected to be used by the
external shuffle service.
Scope of this PR is limited to only implement the cleanup logic on a
Standalone cluster, we defer to experts familiar with other cluster
managers(YARN/Mesos/K8s) to determine whether it's worth to add similar support.
## How was this patch tested?
Add new test suite to cover.
Author: Xingbo Jiang <xingbo.ji...@databricks.com>
Closes #21390 from jiangxb1987/cleanupNonshuffleFiles.
commit a36c1a6bbd1deb119d96316ccbb6dc96ad174796
Author: Yinan Li <ynli@...>
Date: 2018-06-02T06:43:10Z
[SPARK-23668][K8S] Added missing config property in running-on-kubernetes.md
## What changes were proposed in this pull request?
PR https://github.com/apache/spark/pull/20811 introduced a new Spark
configuration property `spark.kubernetes.container.image.pullSecrets` for
specifying image pull secrets. However, the documentation wasn't updated
accordingly. This PR adds the property introduced into running-on-kubernetes.md.
## How was this patch tested?
N/A.
foxish mccheah please help merge this. Thanks!
Author: Yinan Li <y...@google.com>
Closes #21480 from liyinan926/master.
commit de4feae3cd2fef9e83cac749b04ea9395bdd805e
Author: Misha Dmitriev <misha@...>
Date: 2018-06-03T04:07:39Z
[SPARK-24356][CORE] Duplicate strings in File.path managed by
FileSegmentManagedBuffer
This patch eliminates duplicate strings that come from the 'path' field of
java.io.File objects created by FileSegmentManagedBuffer. That is, we want
to avoid the situation when multiple File instances for the same pathname
"foo/bar" are created, each with a separate copy of the "foo/bar" String
instance. In some scenarios such duplicate strings may waste a lot of memory
(~ 10% of the heap). To avoid that, we intern the pathname with
String.intern(), and before that we make sure that it's in a normalized
form (contains no "//", "///" etc.) Otherwise, the code in java.io.File
would normalize it later, creating a new "foo/bar" String copy.
Unfortunately, the normalization code that java.io.File uses internally
is in the package-private class java.io.FileSystem, so we cannot call it
here directly.
## What changes were proposed in this pull request?
Added code to ExternalShuffleBlockResolver.getFile(), that normalizes and
then interns the pathname string before passing it to the File() constructor.
## How was this patch tested?
Added unit test
Author: Misha Dmitriev <mi...@cloudera.com>
Closes #21456 from countmdm/misha/spark-24356.
commit a2166ecddaec030f78acaa66ce660d979a35079c
Author: xueyu <xueyu@...>
Date: 2018-06-04T01:10:49Z
[SPARK-24455][CORE] fix typo in TaskSchedulerImpl comment
change runTasks to submitTasks in the TaskSchedulerImpl.scala 's comment
Author: xueyu <xu...@yidian-inc.com>
Author: Xue Yu <278006...@qq.com>
Closes #21485 from xueyumusic/fixtypo1.
commit 416cd1fd96c0db9194e32ba877b1396b6dc13c8e
Author: Wenchen Fan <wenchen@...>
Date: 2018-06-04T04:57:42Z
[SPARK-24369][SQL] Correct handling for multiple distinct aggregations
having the same argument set
## What changes were proposed in this pull request?
bring back https://github.com/apache/spark/pull/21443
This is a different approach: just change the check to count distinct
columns with `toSet`
## How was this patch tested?
a new test to verify the planner behavior.
Author: Wenchen Fan <wenc...@databricks.com>
Author: Takeshi Yamamuro <yamam...@apache.org>
Closes #21487 from cloud-fan/back.
commit 1d9338bb10b953daddb23b8879ff99aa5c57dbea
Author: Maxim Gekk <maxim.gekk@...>
Date: 2018-06-04T05:02:21Z
[SPARK-23786][SQL] Checking column names of csv headers
## What changes were proposed in this pull request?
Currently column names of headers in CSV files are not checked against
provided schema of CSV data. It could cause errors like showed in the
[SPARK-23786](https://issues.apache.org/jira/browse/SPARK-23786) and
https://github.com/apache/spark/pull/20894#issuecomment-375957777. I introduced
new CSV option - `enforceSchema`. If it is enabled (by default `true`), Spark
forcibly applies provided or inferred schema to CSV files. In that case, CSV
headers are ignored and not checked against the schema. If `enforceSchema` is
set to `false`, additional checks can be performed. For example, if column in
CSV header and in the schema have different ordering, the following exception
is thrown:
```
java.lang.IllegalArgumentException: CSV file header does not contain the
expected fields
Header: depth, temperature
Schema: temperature, depth
CSV file: marina.csv
```
## How was this patch tested?
The changes were tested by existing tests of CSVSuite and by 2 new tests.
Author: Maxim Gekk <maxim.g...@databricks.com>
Author: Maxim Gekk <max.g...@gmail.com>
Closes #20894 from MaxGekk/check-column-names.
commit 0be5aa27460f87b5627f9de16ec25b09368d205a
Author: Yuming Wang <yumwang@...>
Date: 2018-06-04T17:16:13Z
[SPARK-23903][SQL] Add support for date extract
## What changes were proposed in this pull request?
Add support for date `extract` function:
```sql
spark-sql> SELECT EXTRACT(YEAR FROM TIMESTAMP '2000-12-16 12:21:13');
2000
```
Supported field same as
[Hive](https://github.com/apache/hive/blob/rel/release-2.3.3/ql/src/java/org/apache/hadoop/hive/ql/parse/IdentifiersParser.g#L308-L316):
`YEAR`, `QUARTER`, `MONTH`, `WEEK`, `DAY`, `DAYOFWEEK`, `HOUR`, `MINUTE`,
`SECOND`.
## How was this patch tested?
unit tests
Author: Yuming Wang <yumw...@ebay.com>
Closes #21479 from wangyum/SPARK-23903.
commit 7297ae04d87b6e3d48b747a7c1d53687fcc3971c
Author: aokolnychyi <anton.okolnychyi@...>
Date: 2018-06-04T20:28:16Z
[SPARK-21896][SQL] Fix StackOverflow caused by window functions inside
aggregate functions
## What changes were proposed in this pull request?
This PR explicitly prohibits window functions inside aggregates. Currently,
this will cause StackOverflow during analysis. See PR #19193 for previous
discussion.
## How was this patch tested?
This PR comes with a dedicated unit test.
Author: aokolnychyi <anton.okolnyc...@sap.com>
Closes #21473 from aokolnychyi/fix-stackoverflow-window-funcs.
commit b24d3dba6571fd3c9e2649aceeaadc3f9c6cc90f
Author: Lu WANG <lu.wang@...>
Date: 2018-06-04T21:54:31Z
[SPARK-24290][ML] add support for Array input for
instrumentation.logNamedValue
## What changes were proposed in this pull request?
Extend instrumentation.logNamedValue to support Array input
change the logging for "clusterSizes" to new method
## How was this patch tested?
N/A
Please review http://spark.apache.org/contributing.html before opening a
pull request.
Author: Lu WANG <lu.w...@databricks.com>
Closes #21347 from ludatabricks/SPARK-24290.
commit ff0501b0c27dc8149bd5fb38a19d9b0056698766
Author: Lu WANG <lu.wang@...>
Date: 2018-06-04T23:08:27Z
[SPARK-24300][ML] change the way to set seed in
ml.cluster.LDASuite.generateLDAData
## What changes were proposed in this pull request?
Using different RNG in all different partitions.
## How was this patch tested?
manually
Please review http://spark.apache.org/contributing.html before opening a
pull request.
Author: Lu WANG <lu.w...@databricks.com>
Closes #21492 from ludatabricks/SPARK-24300.
commit dbb4d83829ec4b51d6e6d3a96f7a4e611d8827bc
Author: Yuanjian Li <xyliyuanjian@...>
Date: 2018-06-05T01:23:08Z
[SPARK-24215][PYSPARK] Implement _repr_html_ for dataframes in PySpark
## What changes were proposed in this pull request?
Implement `_repr_html_` for PySpark while in notebook and add config named
"spark.sql.repl.eagerEval.enabled" to control this.
The dev list thread for context:
http://apache-spark-developers-list.1001551.n3.nabble.com/eager-execution-and-debuggability-td23928.html
## How was this patch tested?
New ut in DataFrameSuite and manual test in jupyter. Some screenshot below.
**After:**

**Before:**

Author: Yuanjian Li <xyliyuanj...@gmail.com>
Closes #21370 from xuanyuanking/SPARK-24215.
commit b3417b731d4e323398a0d7ec6e86405f4464f4f9
Author: Marcelo Vanzin <vanzin@...>
Date: 2018-06-05T01:29:29Z
[SPARK-16451][REPL] Fail shell if SparkSession fails to start.
Currently, in spark-shell, if the session fails to start, the
user sees a bunch of unrelated errors which are caused by code
in the shell initialization that references the "spark" variable,
which does not exist in that case. Things like:
```
<console>:14: error: not found: value spark
import spark.sql
```
The user is also left with a non-working shell (unless they want
to just write non-Spark Scala or Python code, that is).
This change fails the whole shell session at the point where the
failure occurs, so that the last error message is the one with
the actual information about the failure.
For the python error handling, I moved the session initialization code
to session.py, so that traceback.print_exc() only shows the last error.
Otherwise, the printed exception would contain all previous exceptions
with a message "During handling of the above exception, another
exception occurred", making the actual error kinda hard to parse.
Tested with spark-shell, pyspark (with 2.7 and 3.5), by forcing an
error during SparkContext initialization.
Author: Marcelo Vanzin <van...@cloudera.com>
Closes #21368 from vanzin/SPARK-16451.
commit e8c1a0c2fdb09a628d9cc925676af870d5a7a946
Author: WeichenXu <weichen.xu@...>
Date: 2018-06-05T04:24:35Z
[SPARK-15784] Add Power Iteration Clustering to spark.ml
## What changes were proposed in this pull request?
According to the discussion on JIRA. I rewrite the Power Iteration
Clustering API in `spark.ml`.
## How was this patch tested?
Unit test.
Please review http://spark.apache.org/contributing.html before opening a
pull request.
Author: WeichenXu <weichen...@databricks.com>
Closes #21493 from WeichenXu123/pic_api.
commit 2c2a86b5d5be6f77ee72d16f990b39ae59f479b9
Author: Tathagata Das <tathagata.das1565@...>
Date: 2018-06-05T08:08:55Z
[SPARK-24453][SS] Fix error recovering from the failure in a no-data batch
## What changes were proposed in this pull request?
The error occurs when we are recovering from a failure in a no-data batch
(say X) that has been planned (i.e. written to offset log) but not executed
(i.e. not written to commit log). Upon recovery the following sequence of
events happen.
1. `MicroBatchExecution.populateStartOffsets` sets `currentBatchId` to X.
Since there was no data in the batch, the `availableOffsets` is same as
`committedOffsets`, so `isNewDataAvailable` is `false`.
2. When `MicroBatchExecution.constructNextBatch` is called, ideally it
should immediately return true because the next batch has already been
constructed. However, the check of whether the batch has been constructed was
`if (isNewDataAvailable) return true`. Since the planned batch is a no-data
batch, it escaped this check and proceeded to plan the same batch X *once
again*.
The solution is to have an explicit flag that signifies whether a batch has
already been constructed or not. `populateStartOffsets` is going to set the
flag appropriately.
## How was this patch tested?
new unit test
Author: Tathagata Das <tathagata.das1...@gmail.com>
Closes #21491 from tdas/SPARK-24453.
commit 93df3cd03503fca7745141fbd2676b8bf70fe92f
Author: jinxing <jinxing6042@...>
Date: 2018-06-05T18:32:42Z
[SPARK-22384][SQL] Refine partition pruning when attribute is wrapped in
Cast
## What changes were proposed in this pull request?
Sql below will get all partitions from metastore, which put much burden on
metastore;
```
CREATE TABLE `partition_test`(`col` int) PARTITIONED BY (`pt` byte)
SELECT * FROM partition_test WHERE CAST(pt AS INT)=1
```
The reason is that the the analyzed attribute `dt` is wrapped in `Cast` and
`HiveShim` fails to generate a proper partition filter.
This pr proposes to take `Cast` into consideration when generate partition
filter.
## How was this patch tested?
Test added.
This pr proposes to use analyzed expressions in `HiveClientSuite`
Author: jinxing <jinxing6...@126.com>
Closes #19602 from jinxing64/SPARK-22384.
commit e9efb62e0795c8d5233b7e5bfc276d74953942b8
Author: Huaxin Gao <huaxing@...>
Date: 2018-06-06T01:31:35Z
[SPARK-24187][R][SQL] Add array_join function to SparkR
## What changes were proposed in this pull request?
This PR adds array_join function to SparkR
## How was this patch tested?
Add unit test in test_sparkSQL.R
Author: Huaxin Gao <huax...@us.ibm.com>
Closes #21313 from huaxingao/spark-24187.
commit e76b0124fbe463def00b1dffcfd8fd47e04772fe
Author: Asher Saban <asaban@...>
Date: 2018-06-06T14:14:08Z
[SPARK-23803][SQL] Support bucket pruning
## What changes were proposed in this pull request?
support bucket pruning when filtering on a single bucketed column on the
following predicates -
EqualTo, EqualNullSafe, In, And/Or predicates
## How was this patch tested?
refactored unit tests to test the above.
based on gatorsmile work in
https://github.com/apache/spark/commit/e3c75c6398b1241500343ff237e9bcf78b5396f9
Author: Asher Saban <asa...@palantir.com>
Author: asaban <asa...@palantir.com>
Closes #20915 from sabanas/filter-prune-buckets.
commit 1462bba4fd99a264ebc8679db91dfc62d0b9a35f
Author: Bruce Robbins <bersprockets@...>
Date: 2018-06-08T11:27:52Z
[SPARK-24119][SQL] Add interpreted execution to SortPrefix expression
## What changes were proposed in this pull request?
Implemented eval in SortPrefix expression.
## How was this patch tested?
- ran existing sbt SQL tests
- added unit test
- ran existing Python SQL tests
- manual tests: disabling codegen -- patching code to disable beyond what
spark.sql.codegen.wholeStage=false can do -- and running sbt SQL tests
Author: Bruce Robbins <bersprock...@gmail.com>
Closes #21231 from bersprockets/sortprefixeval.
commit 2c100209f0b73e882ab953993b307867d1df7c2f
Author: Shahid <shahidki31@...>
Date: 2018-06-08T13:44:59Z
[SPARK-24224][ML-EXAMPLES] Java example code for Power Iteration Clustering
in spark.ml
## What changes were proposed in this pull request?
Java example code for Power Iteration Clustering in spark.ml
## How was this patch tested?
Locally tested
Author: Shahid <shahidk...@gmail.com>
Closes #21283 from shahidki31/JavaPicExample.
commit a5d775a1f3aad7bef0ac0f93869eaf96b677411b
Author: Shahid <shahidki31@...>
Date: 2018-06-08T13:45:56Z
[SPARK-24191][ML] Scala Example code for Power Iteration Clustering
## What changes were proposed in this pull request?
Added example code for Power Iteration Clustering in Spark ML examples
Author: Shahid <shahidk...@gmail.com>
Closes #21248 from shahidki31/sparkCommit.
commit 173fe450df203b262b58f7e71c6b52a79db95ee0
Author: hyukjinkwon <gurwls223@...>
Date: 2018-06-08T16:32:11Z
[SPARK-24477][SPARK-24454][ML][PYTHON] Imports submodule in ml/__init__.py
and add ImageSchema into __all__
## What changes were proposed in this pull request?
This PR attaches submodules to ml's `__init__.py` module.
Also, adds `ImageSchema` into `image.py` explicitly.
## How was this patch tested?
Before:
```python
>>> from pyspark import ml
>>> ml.image
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
AttributeError: 'module' object has no attribute 'image'
>>> ml.image.ImageSchema
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
AttributeError: 'module' object has no attribute 'image'
```
```python
>>> "image" in globals()
False
>>> from pyspark.ml import *
>>> "image" in globals()
False
>>> image
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
NameError: name 'image' is not defined
```
After:
```python
>>> from pyspark import ml
>>> ml.image
<module 'pyspark.ml.image' from '/.../spark/python/pyspark/ml/image.pyc'>
>>> ml.image.ImageSchema
<pyspark.ml.image._ImageSchema object at 0x10d973b10>
```
```python
>>> "image" in globals()
False
>>> from pyspark.ml import *
>>> "image" in globals()
True
>>> image
<module 'pyspark.ml.image' from #'/.../spark/python/pyspark/ml/image.pyc'>
```
Author: hyukjinkwon <gurwls...@apache.org>
Closes #21483 from HyukjinKwon/SPARK-24454.
commit 1a644afbac35c204f9ad55f86999319a9ab458c6
Author: Ilan Filonenko <if56@...>
Date: 2018-06-08T18:18:34Z
[SPARK-23984][K8S] Initial Python Bindings for PySpark on K8s
## What changes were proposed in this pull request?
Introducing Python Bindings for PySpark.
- [x] Running PySpark Jobs
- [x] Increased Default Memory Overhead value
- [ ] Dependency Management for virtualenv/conda
## How was this patch tested?
This patch was tested with
- [x] Unit Tests
- [x] Integration tests with [this
addition](https://github.com/apache-spark-on-k8s/spark-integration/pull/46)
```
KubernetesSuite:
- Run SparkPi with no resources
- Run SparkPi with a very long application name.
- Run SparkPi with a master URL without a scheme.
- Run SparkPi with an argument.
- Run SparkPi with custom labels, annotations, and environment variables.
- Run SparkPi with a test secret mounted into the driver and executor pods
- Run extraJVMOptions check on driver
- Run SparkRemoteFileTest using a remote data file
- Run PySpark on simple pi.py example
- Run PySpark with Python2 to test a pyfiles example
- Run PySpark with Python3 to test a pyfiles example
Run completed in 4 minutes, 28 seconds.
Total number of tests run: 11
Suites: completed 2, aborted 0
Tests: succeeded 11, failed 0, canceled 0, ignored 0, pending 0
All tests passed.
```
Author: Ilan Filonenko <i...@cornell.edu>
Author: Ilan Filonenko <ifilo...@gmail.com>
Closes #21092 from ifilonenko/master.
commit b070ded2843e88131c90cb9ef1b4f8d533f8361d
Author: hyukjinkwon <gurwls223@...>
Date: 2018-06-08T18:27:51Z
[SPARK-17756][PYTHON][STREAMING] Workaround to avoid return type mismatch
in PythonTransformFunction
## What changes were proposed in this pull request?
This PR proposes to wrap the transformed rdd within `TransformFunction`.
`PythonTransformFunction` looks requiring to return `JavaRDD` in `_jrdd`.
https://github.com/apache/spark/blob/39e2bad6a866d27c3ca594d15e574a1da3ee84cc/python/pyspark/streaming/util.py#L67
https://github.com/apache/spark/blob/6ee28423ad1b2e6089b82af64a31d77d3552bb38/streaming/src/main/scala/org/apache/spark/streaming/api/python/PythonDStream.scala#L43
However, this could be `JavaPairRDD` by some APIs, for example, `zip` in
PySpark's RDD API.
`_jrdd` could be checked as below:
```python
>>> rdd.zip(rdd)._jrdd.getClass().toString()
u'class org.apache.spark.api.java.JavaPairRDD'
```
So, here, I wrapped it with `map` so that it ensures returning `JavaRDD`.
```python
>>> rdd.zip(rdd).map(lambda x: x)._jrdd.getClass().toString()
u'class org.apache.spark.api.java.JavaRDD'
```
I tried to elaborate some failure cases as below:
```python
from pyspark.streaming import StreamingContext
ssc = StreamingContext(spark.sparkContext, 10)
ssc.queueStream([sc.range(10)]) \
.transform(lambda rdd: rdd.cartesian(rdd)) \
.pprint()
ssc.start()
```
```python
from pyspark.streaming import StreamingContext
ssc = StreamingContext(spark.sparkContext, 10)
ssc.queueStream([sc.range(10)]).foreachRDD(lambda rdd: rdd.cartesian(rdd))
ssc.start()
```
```python
from pyspark.streaming import StreamingContext
ssc = StreamingContext(spark.sparkContext, 10)
ssc.queueStream([sc.range(10)]).foreachRDD(lambda rdd: rdd.zip(rdd))
ssc.start()
```
```python
from pyspark.streaming import StreamingContext
ssc = StreamingContext(spark.sparkContext, 10)
ssc.queueStream([sc.range(10)]).foreachRDD(lambda rdd:
rdd.zip(rdd).union(rdd.zip(rdd)))
ssc.start()
```
```python
from pyspark.streaming import StreamingContext
ssc = StreamingContext(spark.sparkContext, 10)
ssc.queueStream([sc.range(10)]).foreachRDD(lambda rdd:
rdd.zip(rdd).coalesce(1))
ssc.start()
```
## How was this patch tested?
Unit tests were added in `python/pyspark/streaming/tests.py` and manually
tested.
Author: hyukjinkwon <gurwls...@gmail.com>
Closes #19498 from HyukjinKwon/SPARK-17756.
commit f433ef786770e48e3594ad158ce9908f98ef0d9a
Author: Sean Suchter <sean-github@...>
Date: 2018-06-08T22:15:24Z
[SPARK-23010][K8S] Initial checkin of k8s integration tests.
These tests were developed in the
https://github.com/apache-spark-on-k8s/spark-integration repo
by several contributors. This is a copy of the current state into the main
apache spark repo.
The only changes from the current spark-integration repo state are:
* Move the files from the repo root into
resource-managers/kubernetes/integration-tests
* Add a reference to these tests in the root README.md
* Fix a path reference in dev/dev-run-integration-tests.sh
* Add a TODO in include/util.sh
## What changes were proposed in this pull request?
Incorporation of Kubernetes integration tests.
## How was this patch tested?
This code has its own unit tests, but the main purpose is to provide the
integration tests.
I tested this on my laptop by running dev/dev-run-integration-tests.sh
--spark-tgz ~/spark-2.4.0-SNAPSHOT-bin--.tgz
The spark-integration tests have already been running for months in AMPLab,
here is an example:
https://amplab.cs.berkeley.edu/jenkins/job/testing-k8s-scheduled-spark-integration-master/
Please review http://spark.apache.org/contributing.html before opening a
pull request.
Author: Sean Suchter <sean-git...@suchter.com>
Author: Sean Suchter <ssuch...@pepperdata.com>
Closes #20697 from ssuchter/ssuchter-k8s-integration-tests.
commit 36a3409134687d6a2894cd6a77554b8439cacec1
Author: Thiruvasakan Paramasivan <thiru@...>
Date: 2018-06-09T00:17:43Z
[SPARK-24412][SQL] Adding docs about automagical type casting in `isin` and
`isInCollection` APIs
## What changes were proposed in this pull request?
Update documentation for `isInCollection` API to clealy explain the
"auto-casting" of elements if their types are different.
## How was this patch tested?
No-Op
Author: Thiruvasakan Paramasivan <th...@apple.com>
Closes #21519 from trvskn/sql-doc-update.
commit f07c5064a3967cdddf57c2469635ee50a26d864c
Author: Marco Gaido <marcogaido91@...>
Date: 2018-06-09T01:51:56Z
[SPARK-24468][SQL] Handle negative scale when adjusting precision for
decimal operations
## What changes were proposed in this pull request?
In SPARK-22036 we introduced the possibility to allow precision loss in
arithmetic operations (according to the SQL standard). The implementation was
drawn from Hive's one, where Decimals with a negative scale are not allowed in
the operations.
The PR handles the case when the scale is negative, removing the assertion
that it is not.
## How was this patch tested?
added UTs
Author: Marco Gaido <marcogaid...@gmail.com>
Closes #21499 from mgaido91/SPARK-24468.
commit 3e5b4ae63a468858ff8b9f7f3231cc877846a0af
Author: edorigatti <emilio.dorigatti@...>
Date: 2018-06-11T02:15:42Z
[SPARK-23754][PYTHON][FOLLOWUP] Move UDF stop iteration wrapping from
driver to executor
## What changes were proposed in this pull request?
SPARK-23754 was fixed in #21383 by changing the UDF code to wrap the user
function, but this required a hack to save its argspec. This PR reverts this
change and fixes the `StopIteration` bug in the worker
## How does this work?
The root of the problem is that when an user-supplied function raises a
`StopIteration`, pyspark might stop processing data, if this function is used
in a for-loop. The solution is to catch `StopIteration`s exceptions and
re-raise them as `RuntimeError`s, so that the execution fails and the error is
reported to the user. This is done using the `fail_on_stopiteration` wrapper,
in different ways depending on where the function is used:
- In RDDs, the user function is wrapped in the driver, because this
function is also called in the driver itself.
- In SQL UDFs, the function is wrapped in the worker, since all processing
happens there. Moreover, the worker needs the signature of the user function,
which is lost when wrapping it, but passing this signature to the worker
requires a not so nice hack.
## How was this patch tested?
Same tests, plus tests for pandas UDFs
Author: edorigatti <emilio.doriga...@gmail.com>
Closes #21467 from e-dorigatti/fix_udf_hack.
commit a99d284c16cc4e00ce7c83ecdc3db6facd467552
Author: Huaxin Gao <huaxing@...>
Date: 2018-06-11T19:15:14Z
[SPARK-19826][ML][PYTHON] add spark.ml Python API for PIC
## What changes were proposed in this pull request?
add spark.ml Python API for PIC
## How was this patch tested?
add doctest
Author: Huaxin Gao <huax...@us.ibm.com>
Closes #21513 from huaxingao/spark--19826.
commit 9b6f24202f6f8d9d76bbe53f379743318acb19f9
Author: Jonathan Kelly <jonathak@...>
Date: 2018-06-11T21:41:15Z
[MINOR][CORE] Log committer class used by HadoopMapRedCommitProtocol
## What changes were proposed in this pull request?
When HadoopMapRedCommitProtocol is used (e.g., when using saveAsTextFile()
or
saveAsHadoopFile() with RDDs), it's not easy to determine which output
committer
class was used, so this PR simply logs the class that was used, similarly
to what
is done in SQLHadoopMapReduceCommitProtocol.
## How was this patch tested?
Built Spark then manually inspected logging when calling saveAsTextFile():
```scala
scala> sc.setLogLevel("INFO")
scala> sc.textFile("README.md").saveAsTextFile("/tmp/out")
...
18/05/29 10:06:20 INFO HadoopMapRedCommitProtocol: Using output committer
class org.apache.hadoop.mapred.FileOutputCommitter
```
Author: Jonathan Kelly <jonat...@amazon.com>
Closes #21452 from ejono/master.
commit 2dc047a3189290411def92f6d7e9a4e01bdb2c30
Author: Fokko Driesprong <fokkodriesprong@...>
Date: 2018-06-11T22:12:33Z
[SPARK-24520] Double braces in documentations
There are double braces in the markdown, which break the link.
## What changes were proposed in this pull request?
(Please fill in changes proposed in this fix)
## How was this patch tested?
(Please explain how this patch was tested. E.g. unit tests, integration
tests, manual tests)
(If this patch involves UI changes, please attach a screenshot; otherwise,
remove this)
Please review http://spark.apache.org/contributing.html before opening a
pull request.
Author: Fokko Driesprong <fokkodriespr...@godatadriven.com>
Closes #21528 from Fokko/patch-1.
----
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
{kind=link}
{kind=link}
{kind=link}