[spark] branch branch-3.2 updated: [SPARK-39183][BUILD] Upgrade Apache Xerces Java to 2.12.2
This is an automated email from the ASF dual-hosted git repository. srowen pushed a commit to branch branch-3.2 in repository https://gitbox.apache.org/repos/asf/spark.git The following commit(s) were added to refs/heads/branch-3.2 by this push: new e7060b79752 [SPARK-39183][BUILD] Upgrade Apache Xerces Java to 2.12.2 e7060b79752 is described below commit e7060b79752522881042ff4d4c39a8e72d6b5f1a Author: bjornjorgensen AuthorDate: Mon May 16 18:10:08 2022 -0500 [SPARK-39183][BUILD] Upgrade Apache Xerces Java to 2.12.2 ### What changes were proposed in this pull request? Upgrade Apache Xerces Java to 2.12.2 [Release notes](https://xerces.apache.org/xerces2-j/releases.html) ### Why are the changes needed? [Infinite Loop in Apache Xerces Java](https://github.com/advisories/GHSA-h65f-jvqw-m9fj) There's a vulnerability within the Apache Xerces Java (XercesJ) XML parser when handling specially crafted XML document payloads. This causes, the XercesJ XML parser to wait in an infinite loop, which may sometimes consume system resources for prolonged duration. This vulnerability is present within XercesJ version 2.12.1 and the previous versions. References https://nvd.nist.gov/vuln/detail/CVE-2022-23437 https://lists.apache.org/thread/6pjwm10bb69kq955fzr1n0nflnjd27dl http://www.openwall.com/lists/oss-security/2022/01/24/3 https://www.oracle.com/security-alerts/cpuapr2022.html ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? Pass GA. Closes #36544 from bjornjorgensen/Upgrade-xerces-to-2.12.2. Authored-by: bjornjorgensen Signed-off-by: Sean Owen (cherry picked from commit 181436bd990d3bdf178a33fa6489ad416f3e7f94) Signed-off-by: Sean Owen --- dev/deps/spark-deps-hadoop-2.7-hive-2.3 | 2 +- pom.xml | 2 +- 2 files changed, 2 insertions(+), 2 deletions(-) diff --git a/dev/deps/spark-deps-hadoop-2.7-hive-2.3 b/dev/deps/spark-deps-hadoop-2.7-hive-2.3 index f586797d9e6..ac2a7b2f3f9 100644 --- a/dev/deps/spark-deps-hadoop-2.7-hive-2.3 +++ b/dev/deps/spark-deps-hadoop-2.7-hive-2.3 @@ -236,7 +236,7 @@ transaction-api/1.1//transaction-api-1.1.jar univocity-parsers/2.9.1//univocity-parsers-2.9.1.jar velocity/1.5//velocity-1.5.jar xbean-asm9-shaded/4.20//xbean-asm9-shaded-4.20.jar -xercesImpl/2.12.0//xercesImpl-2.12.0.jar +xercesImpl/2.12.2//xercesImpl-2.12.2.jar xml-apis/1.4.01//xml-apis-1.4.01.jar xmlenc/0.52//xmlenc-0.52.jar xz/1.8//xz-1.8.jar diff --git a/pom.xml b/pom.xml index ae9b881793f..b94ac3ce7d3 100644 --- a/pom.xml +++ b/pom.xml @@ -1237,7 +1237,7 @@ xerces xercesImpl -2.12.0 +2.12.2 org.apache.avro - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated (d9129205a01 -> 181436bd990)
This is an automated email from the ASF dual-hosted git repository. srowen pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git from d9129205a01 [SPARK-39180][SQL] Simplify the planning of limit and offset add 181436bd990 [SPARK-39183][BUILD] Upgrade Apache Xerces Java to 2.12.2 No new revisions were added by this update. Summary of changes: dev/deps/spark-deps-hadoop-2-hive-2.3 | 2 +- pom.xml | 2 +- 2 files changed, 2 insertions(+), 2 deletions(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch branch-3.3 updated: [SPARK-39183][BUILD] Upgrade Apache Xerces Java to 2.12.2
This is an automated email from the ASF dual-hosted git repository. srowen pushed a commit to branch branch-3.3 in repository https://gitbox.apache.org/repos/asf/spark.git The following commit(s) were added to refs/heads/branch-3.3 by this push: new 30bb19e23d2 [SPARK-39183][BUILD] Upgrade Apache Xerces Java to 2.12.2 30bb19e23d2 is described below commit 30bb19e23d28f454e35c96d20db70db5650bd160 Author: bjornjorgensen AuthorDate: Mon May 16 18:10:08 2022 -0500 [SPARK-39183][BUILD] Upgrade Apache Xerces Java to 2.12.2 ### What changes were proposed in this pull request? Upgrade Apache Xerces Java to 2.12.2 [Release notes](https://xerces.apache.org/xerces2-j/releases.html) ### Why are the changes needed? [Infinite Loop in Apache Xerces Java](https://github.com/advisories/GHSA-h65f-jvqw-m9fj) There's a vulnerability within the Apache Xerces Java (XercesJ) XML parser when handling specially crafted XML document payloads. This causes, the XercesJ XML parser to wait in an infinite loop, which may sometimes consume system resources for prolonged duration. This vulnerability is present within XercesJ version 2.12.1 and the previous versions. References https://nvd.nist.gov/vuln/detail/CVE-2022-23437 https://lists.apache.org/thread/6pjwm10bb69kq955fzr1n0nflnjd27dl http://www.openwall.com/lists/oss-security/2022/01/24/3 https://www.oracle.com/security-alerts/cpuapr2022.html ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? Pass GA. Closes #36544 from bjornjorgensen/Upgrade-xerces-to-2.12.2. Authored-by: bjornjorgensen Signed-off-by: Sean Owen (cherry picked from commit 181436bd990d3bdf178a33fa6489ad416f3e7f94) Signed-off-by: Sean Owen --- dev/deps/spark-deps-hadoop-2-hive-2.3 | 2 +- pom.xml | 2 +- 2 files changed, 2 insertions(+), 2 deletions(-) diff --git a/dev/deps/spark-deps-hadoop-2-hive-2.3 b/dev/deps/spark-deps-hadoop-2-hive-2.3 index 7499a9b94c0..ab00ad568cb 100644 --- a/dev/deps/spark-deps-hadoop-2-hive-2.3 +++ b/dev/deps/spark-deps-hadoop-2-hive-2.3 @@ -260,7 +260,7 @@ transaction-api/1.1//transaction-api-1.1.jar univocity-parsers/2.9.1//univocity-parsers-2.9.1.jar velocity/1.5//velocity-1.5.jar xbean-asm9-shaded/4.20//xbean-asm9-shaded-4.20.jar -xercesImpl/2.12.0//xercesImpl-2.12.0.jar +xercesImpl/2.12.2//xercesImpl-2.12.2.jar xml-apis/1.4.01//xml-apis-1.4.01.jar xmlenc/0.52//xmlenc-0.52.jar xz/1.8//xz-1.8.jar diff --git a/pom.xml b/pom.xml index 34c8354a3d4..0d296febbd8 100644 --- a/pom.xml +++ b/pom.xml @@ -1389,7 +1389,7 @@ xerces xercesImpl -2.12.0 +2.12.2 org.apache.avro - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated: [SPARK-39147][SQL] Code simplification, use count() instead of filter().size, etc
This is an automated email from the ASF dual-hosted git repository.
srowen pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new 09564df8485 [SPARK-39147][SQL] Code simplification, use count()
instead of filter().size, etc
09564df8485 is described below
commit 09564df8485d4ba27ba6d77b18a4635038ab2a1e
Author: morvenhuang
AuthorDate: Wed May 11 18:27:29 2022 -0500
[SPARK-39147][SQL] Code simplification, use count() instead of
filter().size, etc
### What changes were proposed in this pull request?
Use count() instead of filter().size, use df.count() instead of
df.collect().size.
### Why are the changes needed?
Code simplification.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Pass GA.
Closes #36507 from morvenhuang/SPARK-39147.
Authored-by: morvenhuang
Signed-off-by: Sean Owen
---
core/src/test/scala/org/apache/spark/scheduler/MapStatusSuite.scala | 2 +-
.../org/apache/spark/sql/catalyst/analysis/StreamingJoinHelper.scala | 4 ++--
.../scala/org/apache/spark/sql/catalyst/optimizer/expressions.scala | 2 +-
3 files changed, 4 insertions(+), 4 deletions(-)
diff --git
a/core/src/test/scala/org/apache/spark/scheduler/MapStatusSuite.scala
b/core/src/test/scala/org/apache/spark/scheduler/MapStatusSuite.scala
index fe76b1bc322..cf2240a0511 100644
--- a/core/src/test/scala/org/apache/spark/scheduler/MapStatusSuite.scala
+++ b/core/src/test/scala/org/apache/spark/scheduler/MapStatusSuite.scala
@@ -263,7 +263,7 @@ class MapStatusSuite extends SparkFunSuite {
val allBlocks = emptyBlocks ++: nonEmptyBlocks
val skewThreshold = Utils.median(allBlocks, false) *
accurateBlockSkewedFactor
-assert(nonEmptyBlocks.filter(_ > skewThreshold).size ==
+assert(nonEmptyBlocks.count(_ > skewThreshold) ==
untrackedSkewedBlocksLength + trackedSkewedBlocksLength,
"number of skewed block sizes")
diff --git
a/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/analysis/StreamingJoinHelper.scala
b/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/analysis/StreamingJoinHelper.scala
index 3c5ab55a8a7..737d30a41d3 100644
---
a/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/analysis/StreamingJoinHelper.scala
+++
b/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/analysis/StreamingJoinHelper.scala
@@ -132,8 +132,8 @@ object StreamingJoinHelper extends PredicateHelper with
Logging {
leftExpr.collect { case a: AttributeReference => a } ++
rightExpr.collect { case a: AttributeReference => a }
)
-if (attributesInCondition.filter {
attributesToFindStateWatermarkFor.contains(_) }.size > 1 ||
-attributesInCondition.filter {
attributesWithEventWatermark.contains(_) }.size > 1) {
+if
(attributesInCondition.count(attributesToFindStateWatermarkFor.contains) > 1 ||
+attributesInCondition.count(attributesWithEventWatermark.contains) >
1) {
// If more than attributes present in condition from one side, then it
cannot be solved
return None
}
diff --git
a/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/optimizer/expressions.scala
b/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/optimizer/expressions.scala
index 8971f0c70af..d8081f4525a 100644
---
a/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/optimizer/expressions.scala
+++
b/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/optimizer/expressions.scala
@@ -622,7 +622,7 @@ object PushFoldableIntoBranches extends Rule[LogicalPlan]
with PredicateHelper {
// To be conservative here: it's only a guaranteed win if all but at most
only one branch
// end up being not foldable.
private def atMostOneUnfoldable(exprs: Seq[Expression]): Boolean = {
-exprs.filterNot(_.foldable).size < 2
+exprs.count(!_.foldable) < 2
}
// Not all UnaryExpression can be pushed into (if / case) branches, e.g.
Alias.
-
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated: [SPARK-39137][SQL] Use `slice` instead of `take and drop`
This is an automated email from the ASF dual-hosted git repository.
srowen pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new 11320f38897 [SPARK-39137][SQL] Use `slice` instead of `take and drop`
11320f38897 is described below
commit 11320f38897be05ff31d0e2d0c2943112b0df24b
Author: yangjie01
AuthorDate: Tue May 10 22:07:37 2022 -0500
[SPARK-39137][SQL] Use `slice` instead of `take and drop`
### What changes were proposed in this pull request?
This pr is minor code simplification:
- `seq.drop(n).take(m)` -> `seq.slice(n, n + m)`
- `seq.take(m).drop(n)` -> `seq.slice(n, m)`
### Why are the changes needed?
Code simplification
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Pass GA
Closes #36494 from LuciferYang/droptake-2-slice.
Authored-by: yangjie01
Signed-off-by: Sean Owen
---
sql/core/src/main/scala/org/apache/spark/sql/execution/limit.scala | 4 ++--
1 file changed, 2 insertions(+), 2 deletions(-)
diff --git a/sql/core/src/main/scala/org/apache/spark/sql/execution/limit.scala
b/sql/core/src/main/scala/org/apache/spark/sql/execution/limit.scala
index f79361ff1c5..caffe3ff855 100644
--- a/sql/core/src/main/scala/org/apache/spark/sql/execution/limit.scala
+++ b/sql/core/src/main/scala/org/apache/spark/sql/execution/limit.scala
@@ -98,7 +98,7 @@ case class CollectLimitExec(limit: Int = -1, child:
SparkPlan, offset: Int = 0)
}
if (limit >= 0) {
if (offset > 0) {
- singlePartitionRDD.mapPartitionsInternal(_.drop(offset).take(limit))
+ singlePartitionRDD.mapPartitionsInternal(_.slice(offset, offset +
limit))
} else {
singlePartitionRDD.mapPartitionsInternal(_.take(limit))
}
@@ -238,7 +238,7 @@ case class GlobalLimitAndOffsetExec(
override def requiredChildDistribution: List[Distribution] = AllTuples :: Nil
override def doExecute(): RDD[InternalRow] = if (limit >= 0) {
-child.execute().mapPartitionsInternal(iter => iter.take(limit +
offset).drop(offset))
+child.execute().mapPartitionsInternal(iter => iter.slice(offset, limit +
offset))
} else {
child.execute().mapPartitionsInternal(iter => iter.drop(offset))
}
-
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch branch-3.3 updated (c759151838b -> 7838a140e3b)
This is an automated email from the ASF dual-hosted git repository. srowen pushed a change to branch branch-3.3 in repository https://gitbox.apache.org/repos/asf/spark.git from c759151838b [SPARK-39107][SQL] Account for empty string input in regex replace add 7838a140e3b [MINOR][INFRA][3.3] Add ANTLR generated files to .gitignore No new revisions were added by this update. Summary of changes: .gitignore | 5 + 1 file changed, 5 insertions(+) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch branch-3.1 updated: [SPARK-39107][SQL] Account for empty string input in regex replace
This is an automated email from the ASF dual-hosted git repository.
srowen pushed a commit to branch branch-3.1
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/branch-3.1 by this push:
new d557a56b956 [SPARK-39107][SQL] Account for empty string input in regex
replace
d557a56b956 is described below
commit d557a56b956545806019ee7f13f41955d8cb107f
Author: Lorenzo Martini
AuthorDate: Mon May 9 19:44:19 2022 -0500
[SPARK-39107][SQL] Account for empty string input in regex replace
### What changes were proposed in this pull request?
When trying to perform a regex replace, account for the possibility of
having empty strings as input.
### Why are the changes needed?
https://github.com/apache/spark/pull/29891 was merged to address
https://issues.apache.org/jira/browse/SPARK-30796 and introduced a bug that
would not allow regex matching on empty strings, as it would account for
position within substring but not consider the case where input string has
length 0 (empty string)
From https://issues.apache.org/jira/browse/SPARK-39107 there is a change in
behavior between spark versions.
3.0.2
```
scala> val df = spark.sql("SELECT '' AS col")
df: org.apache.spark.sql.DataFrame = [col: string]
scala> df.withColumn("replaced", regexp_replace(col("col"), "^$",
"")).show
+---++
|col|replaced|
+---++
| | |
+---++
```
3.1.2
```
scala> val df = spark.sql("SELECT '' AS col")
df: org.apache.spark.sql.DataFrame = [col: string]
scala> df.withColumn("replaced", regexp_replace(col("col"), "^$",
"")).show
+---++
|col|replaced|
+---++
| ||
+---++
```
The 3.0.2 outcome is the expected and correct one
### Does this PR introduce _any_ user-facing change?
Yes compared to spark 3.2.1, as it brings back the correct behavior when
trying to regex match empty strings, as shown in the example above.
### How was this patch tested?
Added special casing test in `RegexpExpressionsSuite.RegexReplace` with
empty string replacement.
Closes #36457 from LorenzoMartini/lmartini/fix-empty-string-replace.
Authored-by: Lorenzo Martini
Signed-off-by: Sean Owen
(cherry picked from commit 731aa2cdf8a78835621fbf3de2d3492b27711d1a)
Signed-off-by: Sean Owen
---
.../org/apache/spark/sql/catalyst/expressions/regexpExpressions.scala | 4 ++--
.../spark/sql/catalyst/expressions/RegexpExpressionsSuite.scala | 3 +++
2 files changed, 5 insertions(+), 2 deletions(-)
diff --git
a/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/regexpExpressions.scala
b/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/regexpExpressions.scala
index 6c0de3fc7ef..27013e26bdd 100644
---
a/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/regexpExpressions.scala
+++
b/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/regexpExpressions.scala
@@ -537,7 +537,7 @@ case class RegExpReplace(subject: Expression, regexp:
Expression, rep: Expressio
}
val source = s.toString()
val position = i.asInstanceOf[Int] - 1
-if (position < source.length) {
+if (position == 0 || position < source.length) {
val m = pattern.matcher(source)
m.region(position, source.length)
result.delete(0, result.length())
@@ -592,7 +592,7 @@ case class RegExpReplace(subject: Expression, regexp:
Expression, rep: Expressio
}
String $source = $subject.toString();
int $position = $pos - 1;
- if ($position < $source.length()) {
+ if ($position == 0 || $position < $source.length()) {
$classNameStringBuffer $termResult = new $classNameStringBuffer();
java.util.regex.Matcher $matcher = $termPattern.matcher($source);
$matcher.region($position, $source.length());
diff --git
a/sql/catalyst/src/test/scala/org/apache/spark/sql/catalyst/expressions/RegexpExpressionsSuite.scala
b/sql/catalyst/src/test/scala/org/apache/spark/sql/catalyst/expressions/RegexpExpressionsSuite.scala
index 019857580d0..2ca9ede7742 100644
---
a/sql/catalyst/src/test/scala/org/apache/spark/sql/catalyst/expressions/RegexpExpressionsSuite.scala
+++
b/sql/catalyst/src/test/scala/org/apache/spark/sql/catalyst/expressions/RegexpExpressionsSuite.scala
@@ -293,6 +293,7 @@ class RegexpExpressionsSuite extends SparkFunSuite with
ExpressionEvalHelper {
val row4 = create_row(null, "(\\d+)", "###")
val row5 = create_row("100-200", null, "###")
val row6 = create_row("100-200", "(-)", null)
+val row7 = create_row("&quo
[spark] branch branch-3.2 updated: [SPARK-39107][SQL] Account for empty string input in regex replace
This is an automated email from the ASF dual-hosted git repository.
srowen pushed a commit to branch branch-3.2
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/branch-3.2 by this push:
new 69df6ec5127 [SPARK-39107][SQL] Account for empty string input in regex
replace
69df6ec5127 is described below
commit 69df6ec5127233652cdeb804bad75169d87ecdc0
Author: Lorenzo Martini
AuthorDate: Mon May 9 19:44:19 2022 -0500
[SPARK-39107][SQL] Account for empty string input in regex replace
### What changes were proposed in this pull request?
When trying to perform a regex replace, account for the possibility of
having empty strings as input.
### Why are the changes needed?
https://github.com/apache/spark/pull/29891 was merged to address
https://issues.apache.org/jira/browse/SPARK-30796 and introduced a bug that
would not allow regex matching on empty strings, as it would account for
position within substring but not consider the case where input string has
length 0 (empty string)
From https://issues.apache.org/jira/browse/SPARK-39107 there is a change in
behavior between spark versions.
3.0.2
```
scala> val df = spark.sql("SELECT '' AS col")
df: org.apache.spark.sql.DataFrame = [col: string]
scala> df.withColumn("replaced", regexp_replace(col("col"), "^$",
"")).show
+---++
|col|replaced|
+---++
| | |
+---++
```
3.1.2
```
scala> val df = spark.sql("SELECT '' AS col")
df: org.apache.spark.sql.DataFrame = [col: string]
scala> df.withColumn("replaced", regexp_replace(col("col"), "^$",
"")).show
+---++
|col|replaced|
+---++
| ||
+---++
```
The 3.0.2 outcome is the expected and correct one
### Does this PR introduce _any_ user-facing change?
Yes compared to spark 3.2.1, as it brings back the correct behavior when
trying to regex match empty strings, as shown in the example above.
### How was this patch tested?
Added special casing test in `RegexpExpressionsSuite.RegexReplace` with
empty string replacement.
Closes #36457 from LorenzoMartini/lmartini/fix-empty-string-replace.
Authored-by: Lorenzo Martini
Signed-off-by: Sean Owen
(cherry picked from commit 731aa2cdf8a78835621fbf3de2d3492b27711d1a)
Signed-off-by: Sean Owen
---
.../org/apache/spark/sql/catalyst/expressions/regexpExpressions.scala | 4 ++--
.../spark/sql/catalyst/expressions/RegexpExpressionsSuite.scala | 3 +++
2 files changed, 5 insertions(+), 2 deletions(-)
diff --git
a/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/regexpExpressions.scala
b/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/regexpExpressions.scala
index 57d7d762687..93820d30006 100644
---
a/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/regexpExpressions.scala
+++
b/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/regexpExpressions.scala
@@ -568,7 +568,7 @@ case class RegExpReplace(subject: Expression, regexp:
Expression, rep: Expressio
}
val source = s.toString()
val position = i.asInstanceOf[Int] - 1
-if (position < source.length) {
+if (position == 0 || position < source.length) {
val m = pattern.matcher(source)
m.region(position, source.length)
result.delete(0, result.length())
@@ -622,7 +622,7 @@ case class RegExpReplace(subject: Expression, regexp:
Expression, rep: Expressio
}
String $source = $subject.toString();
int $position = $pos - 1;
- if ($position < $source.length()) {
+ if ($position == 0 || $position < $source.length()) {
$classNameStringBuffer $termResult = new $classNameStringBuffer();
java.util.regex.Matcher $matcher = $termPattern.matcher($source);
$matcher.region($position, $source.length());
diff --git
a/sql/catalyst/src/test/scala/org/apache/spark/sql/catalyst/expressions/RegexpExpressionsSuite.scala
b/sql/catalyst/src/test/scala/org/apache/spark/sql/catalyst/expressions/RegexpExpressionsSuite.scala
index 019857580d0..2ca9ede7742 100644
---
a/sql/catalyst/src/test/scala/org/apache/spark/sql/catalyst/expressions/RegexpExpressionsSuite.scala
+++
b/sql/catalyst/src/test/scala/org/apache/spark/sql/catalyst/expressions/RegexpExpressionsSuite.scala
@@ -293,6 +293,7 @@ class RegexpExpressionsSuite extends SparkFunSuite with
ExpressionEvalHelper {
val row4 = create_row(null, "(\\d+)", "###")
val row5 = create_row("100-200", null, "###")
val row6 = create_row("100-200", "(-)", null)
+val row7 = create_row("&quo
[spark] branch branch-3.3 updated: [SPARK-39107][SQL] Account for empty string input in regex replace
This is an automated email from the ASF dual-hosted git repository.
srowen pushed a commit to branch branch-3.3
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/branch-3.3 by this push:
new c759151838b [SPARK-39107][SQL] Account for empty string input in regex
replace
c759151838b is described below
commit c759151838b7515a3d5fc5abb33d0d93e067cd75
Author: Lorenzo Martini
AuthorDate: Mon May 9 19:44:19 2022 -0500
[SPARK-39107][SQL] Account for empty string input in regex replace
### What changes were proposed in this pull request?
When trying to perform a regex replace, account for the possibility of
having empty strings as input.
### Why are the changes needed?
https://github.com/apache/spark/pull/29891 was merged to address
https://issues.apache.org/jira/browse/SPARK-30796 and introduced a bug that
would not allow regex matching on empty strings, as it would account for
position within substring but not consider the case where input string has
length 0 (empty string)
From https://issues.apache.org/jira/browse/SPARK-39107 there is a change in
behavior between spark versions.
3.0.2
```
scala> val df = spark.sql("SELECT '' AS col")
df: org.apache.spark.sql.DataFrame = [col: string]
scala> df.withColumn("replaced", regexp_replace(col("col"), "^$",
"")).show
+---++
|col|replaced|
+---++
| | |
+---++
```
3.1.2
```
scala> val df = spark.sql("SELECT '' AS col")
df: org.apache.spark.sql.DataFrame = [col: string]
scala> df.withColumn("replaced", regexp_replace(col("col"), "^$",
"")).show
+---++
|col|replaced|
+---++
| ||
+---++
```
The 3.0.2 outcome is the expected and correct one
### Does this PR introduce _any_ user-facing change?
Yes compared to spark 3.2.1, as it brings back the correct behavior when
trying to regex match empty strings, as shown in the example above.
### How was this patch tested?
Added special casing test in `RegexpExpressionsSuite.RegexReplace` with
empty string replacement.
Closes #36457 from LorenzoMartini/lmartini/fix-empty-string-replace.
Authored-by: Lorenzo Martini
Signed-off-by: Sean Owen
(cherry picked from commit 731aa2cdf8a78835621fbf3de2d3492b27711d1a)
Signed-off-by: Sean Owen
---
.../org/apache/spark/sql/catalyst/expressions/regexpExpressions.scala | 4 ++--
.../spark/sql/catalyst/expressions/RegexpExpressionsSuite.scala | 3 +++
2 files changed, 5 insertions(+), 2 deletions(-)
diff --git
a/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/regexpExpressions.scala
b/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/regexpExpressions.scala
index bfaaba51446..01763f082d6 100644
---
a/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/regexpExpressions.scala
+++
b/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/regexpExpressions.scala
@@ -642,7 +642,7 @@ case class RegExpReplace(subject: Expression, regexp:
Expression, rep: Expressio
}
val source = s.toString()
val position = i.asInstanceOf[Int] - 1
-if (position < source.length) {
+if (position == 0 || position < source.length) {
val m = pattern.matcher(source)
m.region(position, source.length)
result.delete(0, result.length())
@@ -696,7 +696,7 @@ case class RegExpReplace(subject: Expression, regexp:
Expression, rep: Expressio
}
String $source = $subject.toString();
int $position = $pos - 1;
- if ($position < $source.length()) {
+ if ($position == 0 || $position < $source.length()) {
$classNameStringBuffer $termResult = new $classNameStringBuffer();
java.util.regex.Matcher $matcher = $termPattern.matcher($source);
$matcher.region($position, $source.length());
diff --git
a/sql/catalyst/src/test/scala/org/apache/spark/sql/catalyst/expressions/RegexpExpressionsSuite.scala
b/sql/catalyst/src/test/scala/org/apache/spark/sql/catalyst/expressions/RegexpExpressionsSuite.scala
index 019857580d0..2ca9ede7742 100644
---
a/sql/catalyst/src/test/scala/org/apache/spark/sql/catalyst/expressions/RegexpExpressionsSuite.scala
+++
b/sql/catalyst/src/test/scala/org/apache/spark/sql/catalyst/expressions/RegexpExpressionsSuite.scala
@@ -293,6 +293,7 @@ class RegexpExpressionsSuite extends SparkFunSuite with
ExpressionEvalHelper {
val row4 = create_row(null, "(\\d+)", "###")
val row5 = create_row("100-200", null, "###")
val row6 = create_row("100-200", "(-)", null)
+val row7 = create_row("&quo
[spark] branch master updated: [SPARK-39107][SQL] Account for empty string input in regex replace
This is an automated email from the ASF dual-hosted git repository.
srowen pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new 731aa2cdf8a [SPARK-39107][SQL] Account for empty string input in regex
replace
731aa2cdf8a is described below
commit 731aa2cdf8a78835621fbf3de2d3492b27711d1a
Author: Lorenzo Martini
AuthorDate: Mon May 9 19:44:19 2022 -0500
[SPARK-39107][SQL] Account for empty string input in regex replace
### What changes were proposed in this pull request?
When trying to perform a regex replace, account for the possibility of
having empty strings as input.
### Why are the changes needed?
https://github.com/apache/spark/pull/29891 was merged to address
https://issues.apache.org/jira/browse/SPARK-30796 and introduced a bug that
would not allow regex matching on empty strings, as it would account for
position within substring but not consider the case where input string has
length 0 (empty string)
From https://issues.apache.org/jira/browse/SPARK-39107 there is a change in
behavior between spark versions.
3.0.2
```
scala> val df = spark.sql("SELECT '' AS col")
df: org.apache.spark.sql.DataFrame = [col: string]
scala> df.withColumn("replaced", regexp_replace(col("col"), "^$",
"")).show
+---++
|col|replaced|
+---++
| | |
+---++
```
3.1.2
```
scala> val df = spark.sql("SELECT '' AS col")
df: org.apache.spark.sql.DataFrame = [col: string]
scala> df.withColumn("replaced", regexp_replace(col("col"), "^$",
"")).show
+---++
|col|replaced|
+---++
| ||
+---++
```
The 3.0.2 outcome is the expected and correct one
### Does this PR introduce _any_ user-facing change?
Yes compared to spark 3.2.1, as it brings back the correct behavior when
trying to regex match empty strings, as shown in the example above.
### How was this patch tested?
Added special casing test in `RegexpExpressionsSuite.RegexReplace` with
empty string replacement.
Closes #36457 from LorenzoMartini/lmartini/fix-empty-string-replace.
Authored-by: Lorenzo Martini
Signed-off-by: Sean Owen
---
.../org/apache/spark/sql/catalyst/expressions/regexpExpressions.scala | 4 ++--
.../spark/sql/catalyst/expressions/RegexpExpressionsSuite.scala | 3 +++
2 files changed, 5 insertions(+), 2 deletions(-)
diff --git
a/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/regexpExpressions.scala
b/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/regexpExpressions.scala
index bfaaba51446..01763f082d6 100644
---
a/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/regexpExpressions.scala
+++
b/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/regexpExpressions.scala
@@ -642,7 +642,7 @@ case class RegExpReplace(subject: Expression, regexp:
Expression, rep: Expressio
}
val source = s.toString()
val position = i.asInstanceOf[Int] - 1
-if (position < source.length) {
+if (position == 0 || position < source.length) {
val m = pattern.matcher(source)
m.region(position, source.length)
result.delete(0, result.length())
@@ -696,7 +696,7 @@ case class RegExpReplace(subject: Expression, regexp:
Expression, rep: Expressio
}
String $source = $subject.toString();
int $position = $pos - 1;
- if ($position < $source.length()) {
+ if ($position == 0 || $position < $source.length()) {
$classNameStringBuffer $termResult = new $classNameStringBuffer();
java.util.regex.Matcher $matcher = $termPattern.matcher($source);
$matcher.region($position, $source.length());
diff --git
a/sql/catalyst/src/test/scala/org/apache/spark/sql/catalyst/expressions/RegexpExpressionsSuite.scala
b/sql/catalyst/src/test/scala/org/apache/spark/sql/catalyst/expressions/RegexpExpressionsSuite.scala
index 082e6e4194c..5b007b87915 100644
---
a/sql/catalyst/src/test/scala/org/apache/spark/sql/catalyst/expressions/RegexpExpressionsSuite.scala
+++
b/sql/catalyst/src/test/scala/org/apache/spark/sql/catalyst/expressions/RegexpExpressionsSuite.scala
@@ -293,6 +293,7 @@ class RegexpExpressionsSuite extends SparkFunSuite with
ExpressionEvalHelper {
val row4 = create_row(null, "(\\d+)", "###")
val row5 = create_row("100-200", null, "###")
val row6 = create_row("100-200", "(-)", null)
+val row7 = create_row("", "^$", "")
val s = $"s".string.at(0)
val p = $"p&
[spark] branch master updated: [SPARK-39110][WEBUI] Add metrics properties to environment tab
This is an automated email from the ASF dual-hosted git repository.
srowen pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new 1ebf3e50024 [SPARK-39110][WEBUI] Add metrics properties to environment
tab
1ebf3e50024 is described below
commit 1ebf3e500243003b584d21ff024fba2c11ac7dac
Author: Angerszh
AuthorDate: Sun May 8 08:13:03 2022 -0500
[SPARK-39110][WEBUI] Add metrics properties to environment tab
### What changes were proposed in this pull request?
There are three ways to define metrics properties:
1. Default metrics properties
2. metrics.properties file under $SPARK_CONF_DIR
3. spark.metrics.conf to include a metrics properties file
4. spark.metrics.conf.xx.xx
Many new users always confused when test with metrics system, i think we
can add final metrics properties in the environment tab, to let user can
directly know which metrics are working.
https://user-images.githubusercontent.com/46485123/167062876-c0c98a69-13c7-4a25-bb31-74f1ada88153.png;>
https://user-images.githubusercontent.com/46485123/167062893-f297eeda-b08f-4c9d-a2a2-a74add97493f.png;>
### Why are the changes needed?
Make user clear about which metrics properties are working
### Does this PR introduce _any_ user-facing change?
user can see working metrics properties in UI environment tag
### How was this patch tested?
MT
Closes #36462 from AngersZh/SPARK-39110.
Authored-by: Angerszh
Signed-off-by: Sean Owen
---
.../src/main/resources/org/apache/spark/ui/static/webui.js | 1 +
core/src/main/scala/org/apache/spark/SparkContext.scala| 3 ++-
core/src/main/scala/org/apache/spark/SparkEnv.scala| 9 +
.../scala/org/apache/spark/metrics/MetricsSystem.scala | 2 ++
.../scala/org/apache/spark/status/AppStatusListener.scala | 1 +
.../spark/status/api/v1/OneApplicationResource.scala | 1 +
.../main/scala/org/apache/spark/status/api/v1/api.scala| 1 +
.../scala/org/apache/spark/ui/env/EnvironmentPage.scala| 14 ++
.../main/scala/org/apache/spark/util/JsonProtocol.scala| 5 +
.../app_environment_expectation.json | 6 ++
.../multiple_resource_profiles_expectation.json| 1 +
.../test/resources/spark-events/app-20161116163331-| 2 +-
.../spark/deploy/history/FsHistoryProviderSuite.scala | 3 +++
.../apache/spark/scheduler/EventLoggingListenerSuite.scala | 2 +-
.../scala/org/apache/spark/util/JsonProtocolSuite.scala| 5 +
project/MimaExcludes.scala | 5 -
16 files changed, 53 insertions(+), 8 deletions(-)
diff --git a/core/src/main/resources/org/apache/spark/ui/static/webui.js
b/core/src/main/resources/org/apache/spark/ui/static/webui.js
index c149f2d8433..b365082c1e1 100644
--- a/core/src/main/resources/org/apache/spark/ui/static/webui.js
+++ b/core/src/main/resources/org/apache/spark/ui/static/webui.js
@@ -73,6 +73,7 @@ $(function() {
collapseTablePageLoad('collapse-aggregated-sparkProperties','aggregated-sparkProperties');
collapseTablePageLoad('collapse-aggregated-hadoopProperties','aggregated-hadoopProperties');
collapseTablePageLoad('collapse-aggregated-systemProperties','aggregated-systemProperties');
+
collapseTablePageLoad('collapse-aggregated-metricsProperties','aggregated-metricsProperties');
collapseTablePageLoad('collapse-aggregated-classpathEntries','aggregated-classpathEntries');
collapseTablePageLoad('collapse-aggregated-activeJobs','aggregated-activeJobs');
collapseTablePageLoad('collapse-aggregated-completedJobs','aggregated-completedJobs');
diff --git a/core/src/main/scala/org/apache/spark/SparkContext.scala
b/core/src/main/scala/org/apache/spark/SparkContext.scala
index c6cb5cb5e19..a106d5bacc5 100644
--- a/core/src/main/scala/org/apache/spark/SparkContext.scala
+++ b/core/src/main/scala/org/apache/spark/SparkContext.scala
@@ -2590,7 +2590,8 @@ class SparkContext(config: SparkConf) extends Logging {
val addedFilePaths = addedFiles.keys.toSeq
val addedArchivePaths = addedArchives.keys.toSeq
val environmentDetails = SparkEnv.environmentDetails(conf,
hadoopConfiguration,
-schedulingMode, addedJarPaths, addedFilePaths, addedArchivePaths)
+schedulingMode, addedJarPaths, addedFilePaths, addedArchivePaths,
+env.metricsSystem.metricsProperties.asScala.toMap)
val environmentUpdate =
SparkListenerEnvironmentUpdate(environmentDetails)
listenerBus.post(environmentUpdate)
}
diff --git a/core/src/main/scala/org/apache/spark/SparkEnv.scala
b/core/src/main/scala/org/apache/spark/SparkEnv.scala
index 19467e7eca1..66ee959dbd8 100644
--- a/core/src/main/scala/org/apache/spark/SparkEnv.scala
+++ b/core/src/main/scala/org/
[spark] branch branch-3.3 updated: [SPARK-37618][CORE][FOLLOWUP] Support cleaning up shuffle blocks from external shuffle service
This is an automated email from the ASF dual-hosted git repository.
srowen pushed a commit to branch branch-3.3
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/branch-3.3 by this push:
new e9ee2c8787a [SPARK-37618][CORE][FOLLOWUP] Support cleaning up shuffle
blocks from external shuffle service
e9ee2c8787a is described below
commit e9ee2c8787adfc07a7d1882b7749dd41c2990048
Author: Mridul Muralidharan
AuthorDate: Sun May 8 08:11:19 2022 -0500
[SPARK-37618][CORE][FOLLOWUP] Support cleaning up shuffle blocks from
external shuffle service
### What changes were proposed in this pull request?
Fix test failure in build.
Depending on the umask of the process running tests (which is typically
inherited from the user's default umask), the group writable bit for the
files/directories could be set or unset. The test was assuming that by default
the umask will be restrictive (and so files/directories wont be group
writable). Since this is not a valid assumption, we use jnr to change the umask
of the process to be more restrictive - so that the test can validate the
behavior change - and reset it back once [...]
### Why are the changes needed?
Fix test failure in build
### Does this PR introduce _any_ user-facing change?
No
Adds jnr as a test scoped dependency, which does not bring in any other new
dependency (asm is already a dep in spark).
```
[INFO] +- com.github.jnr:jnr-posix:jar:3.0.9:test
[INFO] | +- com.github.jnr:jnr-ffi:jar:2.0.1:test
[INFO] | | +- com.github.jnr:jffi:jar:1.2.7:test
[INFO] | | +- com.github.jnr:jffi:jar:native:1.2.7:test
[INFO] | | +- org.ow2.asm:asm:jar:5.0.3:test
[INFO] | | +- org.ow2.asm:asm-commons:jar:5.0.3:test
[INFO] | | +- org.ow2.asm:asm-analysis:jar:5.0.3:test
[INFO] | | +- org.ow2.asm:asm-tree:jar:5.0.3:test
[INFO] | | +- org.ow2.asm:asm-util:jar:5.0.3:test
[INFO] | | \- com.github.jnr:jnr-x86asm:jar:1.0.2:test
[INFO] | \- com.github.jnr:jnr-constants:jar:0.8.6:test
```
### How was this patch tested?
Modification to existing test.
Tested on Linux, skips test when native posix env is not found.
Closes #36473 from mridulm/fix-SPARK-37618-test.
Authored-by: Mridul Muralidharan
Signed-off-by: Sean Owen
(cherry picked from commit 317407171cb36439c371153cfd45c1482bf5e425)
Signed-off-by: Sean Owen
---
LICENSE-binary | 1 +
core/pom.xml | 5 ++
.../spark/storage/DiskBlockManagerSuite.scala | 53 +++---
pom.xml| 6 +++
4 files changed, 48 insertions(+), 17 deletions(-)
diff --git a/LICENSE-binary b/LICENSE-binary
index 8bbc913262c..40e2e389b22 100644
--- a/LICENSE-binary
+++ b/LICENSE-binary
@@ -546,6 +546,7 @@ jakarta.annotation:jakarta-annotation-api
https://projects.eclipse.org/projects/
jakarta.servlet:jakarta.servlet-api
https://projects.eclipse.org/projects/ee4j.servlet
jakarta.ws.rs:jakarta.ws.rs-api https://github.com/eclipse-ee4j/jaxrs-api
org.glassfish.hk2.external:jakarta.inject
+com.github.jnr:jnr-posix
Public Domain
diff --git a/core/pom.xml b/core/pom.xml
index 68d1089e34c..ac644130a61 100644
--- a/core/pom.xml
+++ b/core/pom.xml
@@ -61,6 +61,11 @@
com.twitter
chill-java
+
+ com.github.jnr
+ jnr-posix
+ test
+
org.apache.xbean
xbean-asm9-shaded
diff --git
a/core/src/test/scala/org/apache/spark/storage/DiskBlockManagerSuite.scala
b/core/src/test/scala/org/apache/spark/storage/DiskBlockManagerSuite.scala
index 58fe40f9ade..3e4002614ca 100644
--- a/core/src/test/scala/org/apache/spark/storage/DiskBlockManagerSuite.scala
+++ b/core/src/test/scala/org/apache/spark/storage/DiskBlockManagerSuite.scala
@@ -24,6 +24,7 @@ import java.util.HashMap
import com.fasterxml.jackson.core.`type`.TypeReference
import com.fasterxml.jackson.databind.ObjectMapper
+import jnr.posix.{POSIX, POSIXFactory}
import org.apache.commons.io.FileUtils
import org.scalatest.{BeforeAndAfterAll, BeforeAndAfterEach}
@@ -141,28 +142,46 @@ class DiskBlockManagerSuite extends SparkFunSuite with
BeforeAndAfterEach with B
assert(attemptId.equals("1"))
}
+ // Use jnr to get and override the current process umask.
+ // Expects the input mask to be an octal number
+ private def getAndSetUmask(posix: POSIX, mask: String): String = {
+val prev = posix.umask(BigInt(mask, 8).toInt)
+"0" + "%o".format(prev)
+ }
+
test("SPARK-37618: Sub dirs are group writable when removing from shuffle
service enabled") {
val conf = testConf.clone
conf.set("spark.local.dir", rootDirs)
conf.set("spark.shuffle.service.enabled", "true")
conf.set(&qu
[spark] branch master updated: [SPARK-37618][CORE][FOLLOWUP] Support cleaning up shuffle blocks from external shuffle service
This is an automated email from the ASF dual-hosted git repository.
srowen pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new 317407171cb [SPARK-37618][CORE][FOLLOWUP] Support cleaning up shuffle
blocks from external shuffle service
317407171cb is described below
commit 317407171cb36439c371153cfd45c1482bf5e425
Author: Mridul Muralidharan
AuthorDate: Sun May 8 08:11:19 2022 -0500
[SPARK-37618][CORE][FOLLOWUP] Support cleaning up shuffle blocks from
external shuffle service
### What changes were proposed in this pull request?
Fix test failure in build.
Depending on the umask of the process running tests (which is typically
inherited from the user's default umask), the group writable bit for the
files/directories could be set or unset. The test was assuming that by default
the umask will be restrictive (and so files/directories wont be group
writable). Since this is not a valid assumption, we use jnr to change the umask
of the process to be more restrictive - so that the test can validate the
behavior change - and reset it back once [...]
### Why are the changes needed?
Fix test failure in build
### Does this PR introduce _any_ user-facing change?
No
Adds jnr as a test scoped dependency, which does not bring in any other new
dependency (asm is already a dep in spark).
```
[INFO] +- com.github.jnr:jnr-posix:jar:3.0.9:test
[INFO] | +- com.github.jnr:jnr-ffi:jar:2.0.1:test
[INFO] | | +- com.github.jnr:jffi:jar:1.2.7:test
[INFO] | | +- com.github.jnr:jffi:jar:native:1.2.7:test
[INFO] | | +- org.ow2.asm:asm:jar:5.0.3:test
[INFO] | | +- org.ow2.asm:asm-commons:jar:5.0.3:test
[INFO] | | +- org.ow2.asm:asm-analysis:jar:5.0.3:test
[INFO] | | +- org.ow2.asm:asm-tree:jar:5.0.3:test
[INFO] | | +- org.ow2.asm:asm-util:jar:5.0.3:test
[INFO] | | \- com.github.jnr:jnr-x86asm:jar:1.0.2:test
[INFO] | \- com.github.jnr:jnr-constants:jar:0.8.6:test
```
### How was this patch tested?
Modification to existing test.
Tested on Linux, skips test when native posix env is not found.
Closes #36473 from mridulm/fix-SPARK-37618-test.
Authored-by: Mridul Muralidharan
Signed-off-by: Sean Owen
---
LICENSE-binary | 1 +
core/pom.xml | 5 ++
.../spark/storage/DiskBlockManagerSuite.scala | 53 +++---
pom.xml| 6 +++
4 files changed, 48 insertions(+), 17 deletions(-)
diff --git a/LICENSE-binary b/LICENSE-binary
index a090e5205cc..e8ad55c9354 100644
--- a/LICENSE-binary
+++ b/LICENSE-binary
@@ -546,6 +546,7 @@ jakarta.annotation:jakarta-annotation-api
https://projects.eclipse.org/projects/
jakarta.servlet:jakarta.servlet-api
https://projects.eclipse.org/projects/ee4j.servlet
jakarta.ws.rs:jakarta.ws.rs-api https://github.com/eclipse-ee4j/jaxrs-api
org.glassfish.hk2.external:jakarta.inject
+com.github.jnr:jnr-posix
Public Domain
diff --git a/core/pom.xml b/core/pom.xml
index 7d4bab55659..80578417b05 100644
--- a/core/pom.xml
+++ b/core/pom.xml
@@ -61,6 +61,11 @@
com.twitter
chill-java
+
+ com.github.jnr
+ jnr-posix
+ test
+
org.apache.xbean
xbean-asm9-shaded
diff --git
a/core/src/test/scala/org/apache/spark/storage/DiskBlockManagerSuite.scala
b/core/src/test/scala/org/apache/spark/storage/DiskBlockManagerSuite.scala
index 58fe40f9ade..3e4002614ca 100644
--- a/core/src/test/scala/org/apache/spark/storage/DiskBlockManagerSuite.scala
+++ b/core/src/test/scala/org/apache/spark/storage/DiskBlockManagerSuite.scala
@@ -24,6 +24,7 @@ import java.util.HashMap
import com.fasterxml.jackson.core.`type`.TypeReference
import com.fasterxml.jackson.databind.ObjectMapper
+import jnr.posix.{POSIX, POSIXFactory}
import org.apache.commons.io.FileUtils
import org.scalatest.{BeforeAndAfterAll, BeforeAndAfterEach}
@@ -141,28 +142,46 @@ class DiskBlockManagerSuite extends SparkFunSuite with
BeforeAndAfterEach with B
assert(attemptId.equals("1"))
}
+ // Use jnr to get and override the current process umask.
+ // Expects the input mask to be an octal number
+ private def getAndSetUmask(posix: POSIX, mask: String): String = {
+val prev = posix.umask(BigInt(mask, 8).toInt)
+"0" + "%o".format(prev)
+ }
+
test("SPARK-37618: Sub dirs are group writable when removing from shuffle
service enabled") {
val conf = testConf.clone
conf.set("spark.local.dir", rootDirs)
conf.set("spark.shuffle.service.enabled", "true")
conf.set("spark.shuffle.service.removeShuffle", "false")
-val diskBlockManager = new DiskBlockMan
[spark] branch branch-3.2 updated: [SPARK-39083][CORE] Fix race condition between update and clean app data
This is an automated email from the ASF dual-hosted git repository. srowen pushed a commit to branch branch-3.2 in repository https://gitbox.apache.org/repos/asf/spark.git The following commit(s) were added to refs/heads/branch-3.2 by this push: new 599adc851b2 [SPARK-39083][CORE] Fix race condition between update and clean app data 599adc851b2 is described below commit 599adc851b290c0e9d867d183fe5d030250c28f8 Author: tan.vu AuthorDate: Sun May 8 08:09:20 2022 -0500 [SPARK-39083][CORE] Fix race condition between update and clean app data ### What changes were proposed in this pull request? make `cleanAppData` atomic to prevent race condition between update and clean app data. When the race condition happens, it could lead to a scenario when `cleanAppData` delete the entry of ApplicationInfoWrapper for an application right after it has been updated by `mergeApplicationListing`. So there will be cases when the HS Web UI displays `Application not found` for applications whose logs does exist. Error message ``` 22/04/29 17:16:21 DEBUG FsHistoryProvider: New/updated attempts found: 1 ArrayBuffer(viewfs://iu/log/spark3/application_1651119726430_138107_1) 22/04/29 17:16:21 INFO FsHistoryProvider: Parsing viewfs://iu/log/spark3/application_1651119726430_138107_1 for listing data... 22/04/29 17:16:21 INFO FsHistoryProvider: Looking for end event; skipping 10805037 bytes from viewfs://iu/log/spark3/application_1651119726430_138107_1... 22/04/29 17:16:21 INFO FsHistoryProvider: Finished parsing viewfs://iu/log/spark3/application_1651119726430_138107_1 22/04/29 17:16:21 ERROR Utils: Uncaught exception in thread log-replay-executor-7 java.util.NoSuchElementException at org.apache.spark.util.kvstore.InMemoryStore.read(InMemoryStore.java:85) at org.apache.spark.deploy.history.FsHistoryProvider.$anonfun$checkAndCleanLog$3(FsHistoryProvider.scala:927) at scala.Option.foreach(Option.scala:407) at org.apache.spark.deploy.history.FsHistoryProvider.$anonfun$checkAndCleanLog$1(FsHistoryProvider.scala:926) at scala.runtime.java8.JFunction0$mcV$sp.apply(JFunction0$mcV$sp.java:23) at org.apache.spark.util.Utils$.tryLog(Utils.scala:2032) at org.apache.spark.deploy.history.FsHistoryProvider.checkAndCleanLog(FsHistoryProvider.scala:916) at org.apache.spark.deploy.history.FsHistoryProvider.mergeApplicationListing(FsHistoryProvider.scala:712) at org.apache.spark.deploy.history.FsHistoryProvider.$anonfun$checkForLogs$15(FsHistoryProvider.scala:576) at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511) at java.util.concurrent.FutureTask.run(FutureTask.java:266) at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149) at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) at java.lang.Thread.run(Thread.java:748) ``` Background Currently, the HS runs the `checkForLogs` to build the application list based on the current contents of the log directory for every 10 seconds by default. - https://github.com/apache/spark/blob/v3.2.1/core/src/main/scala/org/apache/spark/deploy/history/FsHistoryProvider.scala#L296-L299 - https://github.com/apache/spark/blob/v3.2.1/core/src/main/scala/org/apache/spark/deploy/history/FsHistoryProvider.scala#L472 In each turn of execution, this method scans the specified logDir and parse the log files to update its KVStore: - detect new updated/added files to process : https://github.com/apache/spark/blob/v3.2.1/core/src/main/scala/org/apache/spark/deploy/history/FsHistoryProvider.scala#L574-L578 - detect stale data to remove: https://github.com/apache/spark/blob/v3.2.1/core/src/main/scala/org/apache/spark/deploy/history/FsHistoryProvider.scala#L586-L600 These 2 operations are executed in different threads as `submitLogProcessTask` uses `replayExecutor` to submit tasks. https://github.com/apache/spark/blob/v3.2.1/core/src/main/scala/org/apache/spark/deploy/history/FsHistoryProvider.scala#L1389-L1401 ### When does the bug happen? `Application not found` error happens in the following scenario: In the first run of `checkForLogs`, it detected a newly-added log `viewfs://iu/log/spark3/AAA_1.inprogress` (log of an in-progress application named AAA). So it will add 2 entries to the KVStore - one entry of key-value as the key is the logPath (`viewfs://iu/log/spark3/AAA_1.inprogress`) and the value is an instance of LogInfo represented the log - https://github.com/apache/spark/blob/v3.2.1/core/src/main/scala/org/apache/spark/deploy/history/FsHistoryProvider.scala#L495-L505 - https://github.com/apache/spark/blob/v3.2.1/core/src/main/scala/org/apache/spark/deploy/history
[spark] branch branch-3.3 updated: [SPARK-39083][CORE] Fix race condition between update and clean app data
This is an automated email from the ASF dual-hosted git repository. srowen pushed a commit to branch branch-3.3 in repository https://gitbox.apache.org/repos/asf/spark.git The following commit(s) were added to refs/heads/branch-3.3 by this push: new feba33585c6 [SPARK-39083][CORE] Fix race condition between update and clean app data feba33585c6 is described below commit feba33585c61fb06bbe801b86228301f2a143d9c Author: tan.vu AuthorDate: Sun May 8 08:09:20 2022 -0500 [SPARK-39083][CORE] Fix race condition between update and clean app data ### What changes were proposed in this pull request? make `cleanAppData` atomic to prevent race condition between update and clean app data. When the race condition happens, it could lead to a scenario when `cleanAppData` delete the entry of ApplicationInfoWrapper for an application right after it has been updated by `mergeApplicationListing`. So there will be cases when the HS Web UI displays `Application not found` for applications whose logs does exist. Error message ``` 22/04/29 17:16:21 DEBUG FsHistoryProvider: New/updated attempts found: 1 ArrayBuffer(viewfs://iu/log/spark3/application_1651119726430_138107_1) 22/04/29 17:16:21 INFO FsHistoryProvider: Parsing viewfs://iu/log/spark3/application_1651119726430_138107_1 for listing data... 22/04/29 17:16:21 INFO FsHistoryProvider: Looking for end event; skipping 10805037 bytes from viewfs://iu/log/spark3/application_1651119726430_138107_1... 22/04/29 17:16:21 INFO FsHistoryProvider: Finished parsing viewfs://iu/log/spark3/application_1651119726430_138107_1 22/04/29 17:16:21 ERROR Utils: Uncaught exception in thread log-replay-executor-7 java.util.NoSuchElementException at org.apache.spark.util.kvstore.InMemoryStore.read(InMemoryStore.java:85) at org.apache.spark.deploy.history.FsHistoryProvider.$anonfun$checkAndCleanLog$3(FsHistoryProvider.scala:927) at scala.Option.foreach(Option.scala:407) at org.apache.spark.deploy.history.FsHistoryProvider.$anonfun$checkAndCleanLog$1(FsHistoryProvider.scala:926) at scala.runtime.java8.JFunction0$mcV$sp.apply(JFunction0$mcV$sp.java:23) at org.apache.spark.util.Utils$.tryLog(Utils.scala:2032) at org.apache.spark.deploy.history.FsHistoryProvider.checkAndCleanLog(FsHistoryProvider.scala:916) at org.apache.spark.deploy.history.FsHistoryProvider.mergeApplicationListing(FsHistoryProvider.scala:712) at org.apache.spark.deploy.history.FsHistoryProvider.$anonfun$checkForLogs$15(FsHistoryProvider.scala:576) at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511) at java.util.concurrent.FutureTask.run(FutureTask.java:266) at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149) at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) at java.lang.Thread.run(Thread.java:748) ``` Background Currently, the HS runs the `checkForLogs` to build the application list based on the current contents of the log directory for every 10 seconds by default. - https://github.com/apache/spark/blob/v3.2.1/core/src/main/scala/org/apache/spark/deploy/history/FsHistoryProvider.scala#L296-L299 - https://github.com/apache/spark/blob/v3.2.1/core/src/main/scala/org/apache/spark/deploy/history/FsHistoryProvider.scala#L472 In each turn of execution, this method scans the specified logDir and parse the log files to update its KVStore: - detect new updated/added files to process : https://github.com/apache/spark/blob/v3.2.1/core/src/main/scala/org/apache/spark/deploy/history/FsHistoryProvider.scala#L574-L578 - detect stale data to remove: https://github.com/apache/spark/blob/v3.2.1/core/src/main/scala/org/apache/spark/deploy/history/FsHistoryProvider.scala#L586-L600 These 2 operations are executed in different threads as `submitLogProcessTask` uses `replayExecutor` to submit tasks. https://github.com/apache/spark/blob/v3.2.1/core/src/main/scala/org/apache/spark/deploy/history/FsHistoryProvider.scala#L1389-L1401 ### When does the bug happen? `Application not found` error happens in the following scenario: In the first run of `checkForLogs`, it detected a newly-added log `viewfs://iu/log/spark3/AAA_1.inprogress` (log of an in-progress application named AAA). So it will add 2 entries to the KVStore - one entry of key-value as the key is the logPath (`viewfs://iu/log/spark3/AAA_1.inprogress`) and the value is an instance of LogInfo represented the log - https://github.com/apache/spark/blob/v3.2.1/core/src/main/scala/org/apache/spark/deploy/history/FsHistoryProvider.scala#L495-L505 - https://github.com/apache/spark/blob/v3.2.1/core/src/main/scala/org/apache/spark/deploy/history
[spark] branch master updated: [SPARK-39083][CORE] Fix race condition between update and clean app data
This is an automated email from the ASF dual-hosted git repository. srowen pushed a commit to branch master in repository https://gitbox.apache.org/repos/asf/spark.git The following commit(s) were added to refs/heads/master by this push: new 29643265a9f [SPARK-39083][CORE] Fix race condition between update and clean app data 29643265a9f is described below commit 29643265a9f5e8142d20add5350c614a55161451 Author: tan.vu AuthorDate: Sun May 8 08:09:20 2022 -0500 [SPARK-39083][CORE] Fix race condition between update and clean app data ### What changes were proposed in this pull request? make `cleanAppData` atomic to prevent race condition between update and clean app data. When the race condition happens, it could lead to a scenario when `cleanAppData` delete the entry of ApplicationInfoWrapper for an application right after it has been updated by `mergeApplicationListing`. So there will be cases when the HS Web UI displays `Application not found` for applications whose logs does exist. Error message ``` 22/04/29 17:16:21 DEBUG FsHistoryProvider: New/updated attempts found: 1 ArrayBuffer(viewfs://iu/log/spark3/application_1651119726430_138107_1) 22/04/29 17:16:21 INFO FsHistoryProvider: Parsing viewfs://iu/log/spark3/application_1651119726430_138107_1 for listing data... 22/04/29 17:16:21 INFO FsHistoryProvider: Looking for end event; skipping 10805037 bytes from viewfs://iu/log/spark3/application_1651119726430_138107_1... 22/04/29 17:16:21 INFO FsHistoryProvider: Finished parsing viewfs://iu/log/spark3/application_1651119726430_138107_1 22/04/29 17:16:21 ERROR Utils: Uncaught exception in thread log-replay-executor-7 java.util.NoSuchElementException at org.apache.spark.util.kvstore.InMemoryStore.read(InMemoryStore.java:85) at org.apache.spark.deploy.history.FsHistoryProvider.$anonfun$checkAndCleanLog$3(FsHistoryProvider.scala:927) at scala.Option.foreach(Option.scala:407) at org.apache.spark.deploy.history.FsHistoryProvider.$anonfun$checkAndCleanLog$1(FsHistoryProvider.scala:926) at scala.runtime.java8.JFunction0$mcV$sp.apply(JFunction0$mcV$sp.java:23) at org.apache.spark.util.Utils$.tryLog(Utils.scala:2032) at org.apache.spark.deploy.history.FsHistoryProvider.checkAndCleanLog(FsHistoryProvider.scala:916) at org.apache.spark.deploy.history.FsHistoryProvider.mergeApplicationListing(FsHistoryProvider.scala:712) at org.apache.spark.deploy.history.FsHistoryProvider.$anonfun$checkForLogs$15(FsHistoryProvider.scala:576) at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511) at java.util.concurrent.FutureTask.run(FutureTask.java:266) at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149) at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) at java.lang.Thread.run(Thread.java:748) ``` Background Currently, the HS runs the `checkForLogs` to build the application list based on the current contents of the log directory for every 10 seconds by default. - https://github.com/apache/spark/blob/v3.2.1/core/src/main/scala/org/apache/spark/deploy/history/FsHistoryProvider.scala#L296-L299 - https://github.com/apache/spark/blob/v3.2.1/core/src/main/scala/org/apache/spark/deploy/history/FsHistoryProvider.scala#L472 In each turn of execution, this method scans the specified logDir and parse the log files to update its KVStore: - detect new updated/added files to process : https://github.com/apache/spark/blob/v3.2.1/core/src/main/scala/org/apache/spark/deploy/history/FsHistoryProvider.scala#L574-L578 - detect stale data to remove: https://github.com/apache/spark/blob/v3.2.1/core/src/main/scala/org/apache/spark/deploy/history/FsHistoryProvider.scala#L586-L600 These 2 operations are executed in different threads as `submitLogProcessTask` uses `replayExecutor` to submit tasks. https://github.com/apache/spark/blob/v3.2.1/core/src/main/scala/org/apache/spark/deploy/history/FsHistoryProvider.scala#L1389-L1401 ### When does the bug happen? `Application not found` error happens in the following scenario: In the first run of `checkForLogs`, it detected a newly-added log `viewfs://iu/log/spark3/AAA_1.inprogress` (log of an in-progress application named AAA). So it will add 2 entries to the KVStore - one entry of key-value as the key is the logPath (`viewfs://iu/log/spark3/AAA_1.inprogress`) and the value is an instance of LogInfo represented the log - https://github.com/apache/spark/blob/v3.2.1/core/src/main/scala/org/apache/spark/deploy/history/FsHistoryProvider.scala#L495-L505 - https://github.com/apache/spark/blob/v3.2.1/core/src/main/scala/org/apache/spark/deploy/history
[spark] branch master updated: [SPARK-39113][CORE][MLLIB][PYTHON] Rename `self` to `cls`
This is an automated email from the ASF dual-hosted git repository. srowen pushed a commit to branch master in repository https://gitbox.apache.org/repos/asf/spark.git The following commit(s) were added to refs/heads/master by this push: new 7ac27514f64 [SPARK-39113][CORE][MLLIB][PYTHON] Rename `self` to `cls` 7ac27514f64 is described below commit 7ac27514f64a42d5e934332065c03c65d0d657cd Author: bjornjorgensen AuthorDate: Sun May 8 08:07:19 2022 -0500 [SPARK-39113][CORE][MLLIB][PYTHON] Rename `self` to `cls` ### What changes were proposed in this pull request? Rename `self` to `cls` ### Why are the changes needed? Function def train(self) is decorated as a classmethod ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? Pass existed tests. Closes #36465 from bjornjorgensen/rename-self-to-cls. Authored-by: bjornjorgensen Signed-off-by: Sean Owen --- python/pyspark/mllib/clustering.py | 2 +- python/pyspark/testing/sqlutils.py | 4 ++-- 2 files changed, 3 insertions(+), 3 deletions(-) diff --git a/python/pyspark/mllib/clustering.py b/python/pyspark/mllib/clustering.py index fd33887fd9e..bf8073c2a2e 100644 --- a/python/pyspark/mllib/clustering.py +++ b/python/pyspark/mllib/clustering.py @@ -176,7 +176,7 @@ class BisectingKMeans: @classmethod def train( -self, +cls, rdd: RDD["VectorLike"], k: int = 4, maxIterations: int = 20, diff --git a/python/pyspark/testing/sqlutils.py b/python/pyspark/testing/sqlutils.py index 3eb58ffee87..92fcd08091c 100644 --- a/python/pyspark/testing/sqlutils.py +++ b/python/pyspark/testing/sqlutils.py @@ -79,7 +79,7 @@ class ExamplePointUDT(UserDefinedType): """ @classmethod -def sqlType(self): +def sqlType(cls): return ArrayType(DoubleType(), False) @classmethod @@ -124,7 +124,7 @@ class PythonOnlyUDT(UserDefinedType): """ @classmethod -def sqlType(self): +def sqlType(cls): return ArrayType(DoubleType(), False) @classmethod - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated: [SPARK-39111][CORE][SQL] Mark overridden methods with `@Override` annotation
This is an automated email from the ASF dual-hosted git repository.
srowen pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new 94de3ca2942 [SPARK-39111][CORE][SQL] Mark overridden methods with
`@Override` annotation
94de3ca2942 is described below
commit 94de3ca2942bb04852510abccf06df1fa8b2dab3
Author: Qian.Sun
AuthorDate: Fri May 6 18:14:27 2022 -0500
[SPARK-39111][CORE][SQL] Mark overridden methods with `@Override` annotation
### What changes were proposed in this pull request?
This PR marks overridden methods with `Override` annotation.
### Why are the changes needed?
An overridden method from an interface or abstract class must be marked
with `Override` annotation. To accurately determine whether the overriding is
successful, an `Override` annotation is necessary. Meanwhile, once the method
signature in the abstract class is changed, the implementation class will
report a compile-time error immediately.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Pass the unit test.
Closes #36461 from dcoliversun/SPARK-39111.
Authored-by: Qian.Sun
Signed-off-by: Sean Owen
---
.../src/main/java/org/apache/spark/network/TransportContext.java | 1 +
.../java/org/apache/spark/network/crypto/AuthServerBootstrap.java | 1 +
.../java/org/apache/spark/network/protocol/StreamChunkId.java | 1 +
.../java/org/apache/spark/network/sasl/SaslServerBootstrap.java | 1 +
.../src/main/java/org/apache/spark/network/util/NettyLogger.java | 1 +
.../spark/network/shuffle/ExternalShuffleBlockResolver.java | 1 +
.../org/apache/spark/network/shuffle/RemoteBlockPushResolver.java | 1 +
.../src/main/java/org/apache/spark/unsafe/types/UTF8String.java | 2 ++
.../java/org/apache/spark/sql/avro/SparkAvroKeyOutputFormat.java | 4
core/src/main/java/org/apache/spark/SparkFirehoseListener.java| 2 ++
.../main/java/org/apache/spark/memory/SparkOutOfMemoryError.java | 1 +
.../spark/util/collection/unsafe/sort/PrefixComparators.java | 8
.../spark/util/collection/unsafe/sort/UnsafeInMemorySorter.java | 1 +
.../src/main/java/org/apache/spark/examples/JavaLogQuery.java | 1 +
.../spark/examples/sql/JavaUserDefinedTypedAggregation.java | 6 ++
.../spark/examples/sql/JavaUserDefinedUntypedAggregation.java | 6 ++
.../src/main/java/org/apache/spark/launcher/AbstractLauncher.java | 1 +
.../spark/sql/catalyst/expressions/RowBasedKeyValueBatch.java | 2 ++
.../apache/spark/sql/catalyst/expressions/UnsafeArrayData.java| 1 +
.../spark/sql/connector/catalog/DelegatingCatalogExtension.java | 1 +
.../java/org/apache/spark/sql/connector/catalog/TableChange.java | 1 +
.../spark/sql/connector/expressions/GeneralScalarExpression.java | 1 +
.../spark/sql/connector/expressions/filter/AlwaysFalse.java | 3 +++
.../apache/spark/sql/connector/expressions/filter/AlwaysTrue.java | 3 +++
.../src/main/java/org/apache/spark/sql/util/NumericHistogram.java | 1 +
.../datasources/parquet/VectorizedDeltaByteArrayReader.java | 1 +
.../spark/sql/execution/vectorized/OffHeapColumnVector.java | 1 +
.../apache/spark/sql/execution/vectorized/OnHeapColumnVector.java | 1 +
28 files changed, 55 insertions(+)
diff --git
a/common/network-common/src/main/java/org/apache/spark/network/TransportContext.java
b/common/network-common/src/main/java/org/apache/spark/network/TransportContext.java
index 6948e595b54..b885bee7032 100644
---
a/common/network-common/src/main/java/org/apache/spark/network/TransportContext.java
+++
b/common/network-common/src/main/java/org/apache/spark/network/TransportContext.java
@@ -243,6 +243,7 @@ public class TransportContext implements Closeable {
return registeredConnections;
}
+ @Override
public void close() {
if (chunkFetchWorkers != null) {
chunkFetchWorkers.shutdownGracefully();
diff --git
a/common/network-common/src/main/java/org/apache/spark/network/crypto/AuthServerBootstrap.java
b/common/network-common/src/main/java/org/apache/spark/network/crypto/AuthServerBootstrap.java
index 77a2a6af4d1..f4c98fad292 100644
---
a/common/network-common/src/main/java/org/apache/spark/network/crypto/AuthServerBootstrap.java
+++
b/common/network-common/src/main/java/org/apache/spark/network/crypto/AuthServerBootstrap.java
@@ -43,6 +43,7 @@ public class AuthServerBootstrap implements
TransportServerBootstrap {
this.secretKeyHolder = secretKeyHolder;
}
+ @Override
public RpcHandler doBootstrap(Channel channel, RpcHandler rpcHandler) {
if (!conf.encryptionEnabled()) {
TransportServerBootstrap sasl = new SaslServerBootstrap(conf,
secretKeyHolder);
diff --git
a/common/network-common/src/main/java/org/apache/spark/network/protocol
[spark] branch master updated (ba499b1dcc1 -> 215b1b9e518)
This is an automated email from the ASF dual-hosted git repository. srowen pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git from ba499b1dcc1 [SPARK-39068][SQL] Make thriftserver and sparksql-cli support in-memory catalog add 215b1b9e518 [SPARK-30661][ML][PYTHON] KMeans blockify input vectors No new revisions were added by this update. Summary of changes: .../scala/org/apache/spark/ml/linalg/BLAS.scala| 83 +++- .../org/apache/spark/ml/linalg/Matrices.scala | 72 ++-- .../scala/org/apache/spark/ml/linalg/Vectors.scala | 7 + .../org/apache/spark/ml/clustering/KMeans.scala| 428 +++-- .../org/apache/spark/mllib/clustering/KMeans.scala | 16 + .../apache/spark/ml/clustering/KMeansSuite.scala | 373 +- python/pyspark/ml/clustering.py| 48 ++- 7 files changed, 787 insertions(+), 240 deletions(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark-website] branch asf-site updated: Add link to ASF events in rest of templates
This is an automated email from the ASF dual-hosted git repository. srowen pushed a commit to branch asf-site in repository https://gitbox.apache.org/repos/asf/spark-website.git The following commit(s) were added to refs/heads/asf-site by this push: new cbf031539 Add link to ASF events in rest of templates cbf031539 is described below commit cbf03153968d0f311bf5517ef5f55ce41f0f2874 Author: Sean Owen AuthorDate: Mon May 2 09:21:14 2022 -0500 Add link to ASF events in rest of templates Required links to ASF events were added to the site in https://github.com/apache/spark-website/commit/b899a8353467b9a27c90509daa19f07dba450b38 but we missed one template that controls the home page. Author: Sean Owen Closes #386 from srowen/Events2. --- _layouts/home.html | 1 + site/index.html| 1 + 2 files changed, 2 insertions(+) diff --git a/_layouts/home.html b/_layouts/home.html index 1b4c20a44..7cf1ee258 100644 --- a/_layouts/home.html +++ b/_layouts/home.html @@ -123,6 +123,7 @@ href="https://www.apache.org/foundation/sponsorship.html;>Sponsorship https://www.apache.org/foundation/thanks.html;>Thanks https://www.apache.org/security/;>Security + https://www.apache.org/events/current-event;>Event diff --git a/site/index.html b/site/index.html index 1b02ea829..d95cc1583 100644 --- a/site/index.html +++ b/site/index.html @@ -119,6 +119,7 @@ href="https://www.apache.org/foundation/sponsorship.html;>Sponsorship https://www.apache.org/foundation/thanks.html;>Thanks https://www.apache.org/security/;>Security + https://www.apache.org/events/current-event;>Event - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated: [SPARK-39067][BUILD] Upgrade scala-maven-plugin to 4.6.1
This is an automated email from the ASF dual-hosted git repository. srowen pushed a commit to branch master in repository https://gitbox.apache.org/repos/asf/spark.git The following commit(s) were added to refs/heads/master by this push: new 6d819622dde [SPARK-39067][BUILD] Upgrade scala-maven-plugin to 4.6.1 6d819622dde is described below commit 6d819622ddeabe022fb2f0aaccfa0cb00db22528 Author: yangjie01 AuthorDate: Sun May 1 15:20:07 2022 -0500 [SPARK-39067][BUILD] Upgrade scala-maven-plugin to 4.6.1 ### What changes were proposed in this pull request? This pr aims to upgrade scala-maven-plugin to 4.6.1 ### Why are the changes needed? `scala-maven-plugin` 4.6.1 upgrades `zinc` from 1.5.8 to 1.6.1, it also adds some other new features at the same time, for example, [Add maven.main.skip support](https://github.com/davidB/scala-maven-plugin/commit/67f11faa477bc0e5e8cf673a8753b478fe008a09) and [Patch target to match Scala 2.11/2.12 scalac option syntax](https://github.com/davidB/scala-maven-plugin/commit/36453a1b6b00e90c5e0877568a086c97f799ba12) Other between 4.5.6 and 4.6.1 as follows: - https://github.com/davidB/scala-maven-plugin/compare/4.5.6...4.6.1 ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? Pass GA Closes #36406 from LuciferYang/SPARK-39067. Authored-by: yangjie01 Signed-off-by: Sean Owen --- pom.xml | 2 +- 1 file changed, 1 insertion(+), 1 deletion(-) diff --git a/pom.xml b/pom.xml index ad3a382f503..6081f700b62 100644 --- a/pom.xml +++ b/pom.xml @@ -166,7 +166,7 @@ See: SPARK-36547, SPARK-38394. --> -4.5.6 +4.6.1 true 1.9.13 - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated: [SPARK-35739][SQL] Add Java-compatible Dataset.join overloads
This is an automated email from the ASF dual-hosted git repository.
srowen pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new 973283c33ad [SPARK-35739][SQL] Add Java-compatible Dataset.join
overloads
973283c33ad is described below
commit 973283c33ad908d071550e9be92a4fca76a8a9df
Author: Brandon Dahler
AuthorDate: Thu Apr 28 18:52:26 2022 -0500
[SPARK-35739][SQL] Add Java-compatible Dataset.join overloads
### What changes were proposed in this pull request?
Adds 3 new syntactic sugar overloads to Dataset's join method as proposed
in [SPARK-35739](https://issues.apache.org/jira/browse/SPARK-35739).
### Why are the changes needed?
Improved development experience for developers using Spark SQL,
specifically when coding in Java.
Prior to changes the Seq overloads required developers to use less-known
Java-to-Scala converter methods that made code less readable. The overloads
internalize those converter calls for two of the new methods and the third
method adds a single-item overload that is useful for both Java and Scala.
### Does this PR introduce _any_ user-facing change?
Yes, the three new overloads technically constitute an API change to the
Dataset class. These overloads are net-new and have been commented
appropriately in line with the existing methods.
### How was this patch tested?
Test cases were not added because it is unclear to me where/how syntactic
sugar overloads fit into the testing suites (if at all). Happy to add them if
I can be pointed in the correct direction.
* Changes were tested in Scala via spark-shell.
* Changes were tested in Java by modifying an example:
```
diff --git
a/examples/src/main/java/org/apache/spark/examples/sql/JavaSparkSQLExample.java
b/examples/src/main/java/org/apache/spark/examples/sql/JavaSparkSQLExample.java
index 86a9045d8a..342810c1e6 100644
---
a/examples/src/main/java/org/apache/spark/examples/sql/JavaSparkSQLExample.java
+++
b/examples/src/main/java/org/apache/spark/examples/sql/JavaSparkSQLExample.java
-124,6 +124,10 public class JavaSparkSQLExample {
// |-- age: long (nullable = true)
// |-- name: string (nullable = true)
+df.join(df, new String[] {"age"}).show();
+df.join(df, "age", "left").show();
+df.join(df, new String[] {"age"}, "left").show();
+
// Select only the "name" column
df.select("name").show();
// +---+
```
Notes
Re-opening of #33323 and #34923 with comments addressed.
Closes #36343 from brandondahler/features/JavaCompatibleJoinOverloads.
Authored-by: Brandon Dahler
Signed-off-by: Sean Owen
---
.../main/scala/org/apache/spark/sql/Dataset.scala | 62 +-
.../org/apache/spark/sql/DataFrameJoinSuite.scala | 55 +++
2 files changed, 115 insertions(+), 2 deletions(-)
diff --git a/sql/core/src/main/scala/org/apache/spark/sql/Dataset.scala
b/sql/core/src/main/scala/org/apache/spark/sql/Dataset.scala
index e66bfd87337..36b6d6b470d 100644
--- a/sql/core/src/main/scala/org/apache/spark/sql/Dataset.scala
+++ b/sql/core/src/main/scala/org/apache/spark/sql/Dataset.scala
@@ -946,7 +946,21 @@ class Dataset[T] private[sql](
}
/**
- * Inner equi-join with another `DataFrame` using the given columns.
+ * (Java-specific) Inner equi-join with another `DataFrame` using the given
columns. See the
+ * Scala-specific overload for more details.
+ *
+ * @param right Right side of the join operation.
+ * @param usingColumns Names of the columns to join on. This columns must
exist on both sides.
+ *
+ * @group untypedrel
+ * @since 3.4.0
+ */
+ def join(right: Dataset[_], usingColumns: Array[String]): DataFrame = {
+join(right, usingColumns.toSeq)
+ }
+
+ /**
+ * (Scala-specific) Inner equi-join with another `DataFrame` using the given
columns.
*
* Different from other join functions, the join columns will only appear
once in the output,
* i.e. similar to SQL's `JOIN USING` syntax.
@@ -971,10 +985,54 @@ class Dataset[T] private[sql](
}
/**
- * Equi-join with another `DataFrame` using the given columns. A cross join
with a predicate
+ * Equi-join with another `DataFrame` using the given column. A cross join
with a predicate
* is specified as an inner join. If you would explicitly like to perform a
cross join use the
* `crossJoin` method.
*
+ * Different from other join functions, the join column will only appear
once in the output,
+ * i.e. similar to SQL's `JOIN USING` syntax.
+ *
+ * @param right Right side of the join operation.
+ * @param usingColumn Name of the column to
[spark] branch master updated: [SPARK-38896][CORE][SQL] Use `tryWithResource` release `LevelDB/RocksDBIterator` resources earlier
This is an automated email from the ASF dual-hosted git repository.
srowen pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new fba68e6f20b [SPARK-38896][CORE][SQL] Use `tryWithResource` release
`LevelDB/RocksDBIterator` resources earlier
fba68e6f20b is described below
commit fba68e6f20b88779dc5ca78742958952b3d7acf0
Author: yangjie01
AuthorDate: Thu Apr 28 18:51:28 2022 -0500
[SPARK-38896][CORE][SQL] Use `tryWithResource` release
`LevelDB/RocksDBIterator` resources earlier
### What changes were proposed in this pull request?
Similar to SPARK-38847, this pr aims to release the
`LevelDB/RocksDBIterator` resources earlier by using `tryWithResource`. The
main change of this pr as follows:
1. Use Java `tryWithResource` and Spark `Utils.tryWithResource` to
recycling `KVStoreIterator` opened by `RocksDB.view(Class type).iterator`
and `RocksDB.view(Class type).iterator`
2. Introduce 4 new function for KVUtils(`count|foreach|mapToSeq|size`),
these function will close `KVStoreIterator` in time.
### Why are the changes needed?
Release the `LevelDB/RocksDBIterator` resources earlier
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Pass GA
Closes #36237 from LuciferYang/Manual-Close-KVStoreIterator.
Authored-by: yangjie01
Signed-off-by: Sean Owen
---
.../org/apache/spark/util/kvstore/LevelDB.java | 12 +++--
.../org/apache/spark/util/kvstore/RocksDB.java | 12 +++--
.../apache/spark/util/kvstore/DBIteratorSuite.java | 6 ++-
.../spark/util/kvstore/LevelDBBenchmark.java | 12 +++--
.../apache/spark/util/kvstore/LevelDBSuite.java| 29 ++-
.../spark/util/kvstore/RocksDBBenchmark.java | 13 +++--
.../apache/spark/util/kvstore/RocksDBSuite.java| 29 ++-
.../spark/deploy/history/FsHistoryProvider.scala | 15 ++
.../apache/spark/status/AppStatusListener.scala| 2 +-
.../org/apache/spark/status/AppStatusStore.scala | 58 --
.../scala/org/apache/spark/status/KVUtils.scala| 37 ++
.../spark/deploy/history/HybridStoreSuite.scala| 18 +--
.../spark/status/AppStatusListenerSuite.scala | 3 +-
.../spark/sql/diagnostic/DiagnosticStore.scala | 10 ++--
.../ui/HiveThriftServer2AppStatusStore.scala | 8 +--
.../ui/HiveThriftServer2Listener.scala | 3 +-
16 files changed, 170 insertions(+), 97 deletions(-)
diff --git
a/common/kvstore/src/main/java/org/apache/spark/util/kvstore/LevelDB.java
b/common/kvstore/src/main/java/org/apache/spark/util/kvstore/LevelDB.java
index 6b28373a480..b50906e2cba 100644
--- a/common/kvstore/src/main/java/org/apache/spark/util/kvstore/LevelDB.java
+++ b/common/kvstore/src/main/java/org/apache/spark/util/kvstore/LevelDB.java
@@ -270,10 +270,14 @@ public class LevelDB implements KVStore {
KVStoreView view = view(klass).index(index);
for (Object indexValue : indexValues) {
- for (T value: view.first(indexValue).last(indexValue)) {
-Object itemKey = naturalIndex.getValue(value);
-delete(klass, itemKey);
-removed = true;
+ try (KVStoreIterator iterator =
+view.first(indexValue).last(indexValue).closeableIterator()) {
+while (iterator.hasNext()) {
+ T value = iterator.next();
+ Object itemKey = naturalIndex.getValue(value);
+ delete(klass, itemKey);
+ removed = true;
+}
}
}
diff --git
a/common/kvstore/src/main/java/org/apache/spark/util/kvstore/RocksDB.java
b/common/kvstore/src/main/java/org/apache/spark/util/kvstore/RocksDB.java
index 7674bc52dc7..d328e5c79d3 100644
--- a/common/kvstore/src/main/java/org/apache/spark/util/kvstore/RocksDB.java
+++ b/common/kvstore/src/main/java/org/apache/spark/util/kvstore/RocksDB.java
@@ -303,10 +303,14 @@ public class RocksDB implements KVStore {
KVStoreView view = view(klass).index(index);
for (Object indexValue : indexValues) {
- for (T value: view.first(indexValue).last(indexValue)) {
-Object itemKey = naturalIndex.getValue(value);
-delete(klass, itemKey);
-removed = true;
+ try (KVStoreIterator iterator =
+view.first(indexValue).last(indexValue).closeableIterator()) {
+while (iterator.hasNext()) {
+ T value = iterator.next();
+ Object itemKey = naturalIndex.getValue(value);
+ delete(klass, itemKey);
+ removed = true;
+}
}
}
diff --git
a/common/kvstore/src/test/java/org/apache/spark/util/kvstore/DBIteratorSuite.java
b/common/kvstore/src/test/java/org/apache/spark/util/kvstore/DBIteratorSuite.java
index ab1e2728585..223f3f93a87 100644
---
a/common/kvstore/src/test/java/org/apache/spark/util/kvstore/DBIteratorSuite.java
+++
b/common/kvstore
[spark] branch master updated: [SPARK-39042][CORE][SQL][SS] Use `Map.values()` instead of `Map.entrySet()` in scene that don't use keys
This is an automated email from the ASF dual-hosted git repository.
srowen pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new fe6f70c6630 [SPARK-39042][CORE][SQL][SS] Use `Map.values()` instead of
`Map.entrySet()` in scene that don't use keys
fe6f70c6630 is described below
commit fe6f70c6630b51ea032dcb68c444f43e1c801f1a
Author: yangjie01
AuthorDate: Thu Apr 28 18:50:32 2022 -0500
[SPARK-39042][CORE][SQL][SS] Use `Map.values()` instead of `Map.entrySet()`
in scene that don't use keys
### What changes were proposed in this pull request?
Some code in Spark use `Map.entrySet()`, but doesn't need a keys, this pr
use `Map.values()` to simplified them.
### Why are the changes needed?
Code simplification
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Pass GA
Closes #36372 from LuciferYang/SPARK-39042.
Authored-by: yangjie01
Signed-off-by: Sean Owen
---
.../org/apache/spark/network/client/TransportResponseHandler.java | 4 ++--
.../org/apache/spark/sql/execution/streaming/state/RocksDB.scala | 2 +-
.../java/org/apache/hive/service/cli/operation/LogDivertAppender.java | 3 +--
3 files changed, 4 insertions(+), 5 deletions(-)
diff --git
a/common/network-common/src/main/java/org/apache/spark/network/client/TransportResponseHandler.java
b/common/network-common/src/main/java/org/apache/spark/network/client/TransportResponseHandler.java
index 261f20540a2..a19767ae201 100644
---
a/common/network-common/src/main/java/org/apache/spark/network/client/TransportResponseHandler.java
+++
b/common/network-common/src/main/java/org/apache/spark/network/client/TransportResponseHandler.java
@@ -113,9 +113,9 @@ public class TransportResponseHandler extends
MessageHandler {
logger.warn("ChunkReceivedCallback.onFailure throws exception", e);
}
}
-for (Map.Entry entry :
outstandingRpcs.entrySet()) {
+for (BaseResponseCallback callback : outstandingRpcs.values()) {
try {
-entry.getValue().onFailure(cause);
+callback.onFailure(cause);
} catch (Exception e) {
logger.warn("RpcResponseCallback.onFailure throws exception", e);
}
diff --git
a/sql/core/src/main/scala/org/apache/spark/sql/execution/streaming/state/RocksDB.scala
b/sql/core/src/main/scala/org/apache/spark/sql/execution/streaming/state/RocksDB.scala
index 048db5b53ff..ae16faa41dc 100644
---
a/sql/core/src/main/scala/org/apache/spark/sql/execution/streaming/state/RocksDB.scala
+++
b/sql/core/src/main/scala/org/apache/spark/sql/execution/streaming/state/RocksDB.scala
@@ -450,7 +450,7 @@ class RocksDB(
}
private def closePrefixScanIterators(): Unit = {
-prefixScanReuseIter.entrySet().asScala.foreach(_.getValue.close())
+prefixScanReuseIter.values().asScala.foreach(_.close())
prefixScanReuseIter.clear()
}
diff --git
a/sql/hive-thriftserver/src/main/java/org/apache/hive/service/cli/operation/LogDivertAppender.java
b/sql/hive-thriftserver/src/main/java/org/apache/hive/service/cli/operation/LogDivertAppender.java
index 64730f39bf3..12d7f407093 100644
---
a/sql/hive-thriftserver/src/main/java/org/apache/hive/service/cli/operation/LogDivertAppender.java
+++
b/sql/hive-thriftserver/src/main/java/org/apache/hive/service/cli/operation/LogDivertAppender.java
@@ -264,8 +264,7 @@ public class LogDivertAppender extends
AbstractWriterAppender {
StringLayout layout = null;
Map appenders = root.getAppenders();
-for (Map.Entry entry : appenders.entrySet()) {
- Appender ap = entry.getValue();
+for (Appender ap : appenders.values()) {
if (ap.getClass().equals(ConsoleAppender.class)) {
Layout l = ap.getLayout();
if (l instanceof StringLayout) {
-
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated: [SPARK-38979][SQL] Improve error log readability in OrcUtils.requestedColumnIds
This is an automated email from the ASF dual-hosted git repository.
srowen pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new 70b4b1d1f69 [SPARK-38979][SQL] Improve error log readability in
OrcUtils.requestedColumnIds
70b4b1d1f69 is described below
commit 70b4b1d1f69be3a15eadb0e798139982c152b7bb
Author: sychen
AuthorDate: Wed Apr 27 08:38:28 2022 -0500
[SPARK-38979][SQL] Improve error log readability in
OrcUtils.requestedColumnIds
### What changes were proposed in this pull request?
Add detailed log in `OrcUtils#requestedColumnIds`.
### Why are the changes needed?
In `OrcUtils#requestedColumnIds` sometimes it fails because
`orcFieldNames.length > dataSchema.length`, the log is not very clear.
```
java.lang.AssertionError: assertion failed: The given data schema
struct has less fields than the actual ORC physical schema, no idea
which columns were dropped, fail to read.
```
after the change
```
java.lang.AssertionError: assertion failed: The given data schema
struct (length:1) has fewer 1 fields than the actual ORC physical
schema struct (length:2), no idea which columns were
dropped, fail to read.
```
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
exist UT / local test
Closes #36296 from cxzl25/SPARK-38979.
Authored-by: sychen
Signed-off-by: Sean Owen
---
.../org/apache/spark/sql/execution/datasources/orc/OrcUtils.scala | 4 +++-
1 file changed, 3 insertions(+), 1 deletion(-)
diff --git
a/sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/orc/OrcUtils.scala
b/sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/orc/OrcUtils.scala
index f07573beae6..1783aadaa78 100644
---
a/sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/orc/OrcUtils.scala
+++
b/sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/orc/OrcUtils.scala
@@ -224,7 +224,9 @@ object OrcUtils extends Logging {
// the physical schema doesn't match the data schema).
// In these cases we map the physical schema to the data schema by
index.
assert(orcFieldNames.length <= dataSchema.length, "The given data
schema " +
- s"${dataSchema.catalogString} has less fields than the actual ORC
physical schema, " +
+ s"${dataSchema.catalogString} (length:${dataSchema.length}) " +
+ s"has fewer ${orcFieldNames.length - dataSchema.length} fields than
" +
+ s"the actual ORC physical schema $orcSchema
(length:${orcFieldNames.length}), " +
"no idea which columns were dropped, fail to read.")
// for ORC file written by Hive, no field names
// in the physical schema, there is a need to send the
-
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated (f1286f324c0 -> f66fde8a4f3)
This is an automated email from the ASF dual-hosted git repository. srowen pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git from f1286f324c0 [SPARK-38944][CORE][SQL] Close `UnsafeSorterSpillReader` before `SpillableArrayIterator` throw `ConcurrentModificationException` add f66fde8a4f3 [SPARK-39016][TESTS] Fix compilation warnings related to "`enum` will become a keyword in Scala 3" No new revisions were added by this update. Summary of changes: .../test/scala/org/apache/spark/sql/avro/AvroSuite.scala | 4 ++-- .../apache/spark/internal/config/ConfigEntrySuite.scala | 15 --- 2 files changed, 10 insertions(+), 9 deletions(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated: [SPARK-38944][CORE][SQL] Close `UnsafeSorterSpillReader` before `SpillableArrayIterator` throw `ConcurrentModificationException`
This is an automated email from the ASF dual-hosted git repository.
srowen pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new f1286f324c0 [SPARK-38944][CORE][SQL] Close `UnsafeSorterSpillReader`
before `SpillableArrayIterator` throw `ConcurrentModificationException`
f1286f324c0 is described below
commit f1286f324c032f9a875167fdbb265b4d495752c9
Author: yangjie01
AuthorDate: Tue Apr 26 08:47:54 2022 -0500
[SPARK-38944][CORE][SQL] Close `UnsafeSorterSpillReader` before
`SpillableArrayIterator` throw `ConcurrentModificationException`
### What changes were proposed in this pull request?
There will be `UnsafeSorterSpillReader` resource leak(`InputStream` hold by
`UnsafeSorterSpillReader` ) when `SpillableArrayIterator` throw
`ConcurrentModificationException`, so this pr add resource cleanup process
before `UnsafeSorterSpillReader` throws `ConcurrentModificationException`.
### Why are the changes needed?
Fix file resource leak.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
- Pass GA
- Add new check in `ExternalAppendOnlyUnsafeRowArraySuite`
run command:
```
mvn clean install -pl sql/core -am -DskipTests
mvn clean test -pl sql/core -Dtest=none
-DwildcardSuites=org.apache.spark.sql.execution.ExternalAppendOnlyUnsafeRowArraySuite
```
**Before**
```
- test iterator invalidation (with spill) *** FAILED ***
org.apache.spark.io.ReadAheadInputStream478b0739 did not equal null
(ExternalAppendOnlyUnsafeRowArraySuite.scala:397)
Run completed in 9 seconds, 652 milliseconds.
Total number of tests run: 14
Suites: completed 2, aborted 0
Tests: succeeded 13, failed 1, canceled 0, ignored 0, pending 0
*** 1 TEST FAILED ***
```
**After**
```
Run completed in 8 seconds, 535 milliseconds.
Total number of tests run: 14
Suites: completed 2, aborted 0
Tests: succeeded 14, failed 0, canceled 0, ignored 0, pending 0
All tests passed.
```
Closes #36262 from LuciferYang/SPARK-38944.
Authored-by: yangjie01
Signed-off-by: Sean Owen
---
.../unsafe/sort/UnsafeExternalSorter.java | 24 --
.../ExternalAppendOnlyUnsafeRowArray.scala | 11 +++
.../ExternalAppendOnlyUnsafeRowArraySuite.scala| 37 ++
3 files changed, 70 insertions(+), 2 deletions(-)
diff --git
a/core/src/main/java/org/apache/spark/util/collection/unsafe/sort/UnsafeExternalSorter.java
b/core/src/main/java/org/apache/spark/util/collection/unsafe/sort/UnsafeExternalSorter.java
index c38327cae8c..d836cf3f0e3 100644
---
a/core/src/main/java/org/apache/spark/util/collection/unsafe/sort/UnsafeExternalSorter.java
+++
b/core/src/main/java/org/apache/spark/util/collection/unsafe/sort/UnsafeExternalSorter.java
@@ -18,6 +18,7 @@
package org.apache.spark.util.collection.unsafe.sort;
import javax.annotation.Nullable;
+import java.io.Closeable;
import java.io.File;
import java.io.IOException;
import java.util.LinkedList;
@@ -25,13 +26,14 @@ import java.util.Queue;
import java.util.function.Supplier;
import com.google.common.annotations.VisibleForTesting;
-import org.apache.spark.memory.SparkOutOfMemoryError;
+import org.apache.commons.io.IOUtils;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.apache.spark.TaskContext;
import org.apache.spark.executor.ShuffleWriteMetrics;
import org.apache.spark.memory.MemoryConsumer;
+import org.apache.spark.memory.SparkOutOfMemoryError;
import org.apache.spark.memory.TaskMemoryManager;
import org.apache.spark.memory.TooLargePageException;
import org.apache.spark.serializer.SerializerManager;
@@ -745,7 +747,7 @@ public final class UnsafeExternalSorter extends
MemoryConsumer {
/**
* Chain multiple UnsafeSorterIterator together as single one.
*/
- static class ChainedIterator extends UnsafeSorterIterator {
+ static class ChainedIterator extends UnsafeSorterIterator implements
Closeable {
private final Queue iterators;
private UnsafeSorterIterator current;
@@ -798,5 +800,23 @@ public final class UnsafeExternalSorter extends
MemoryConsumer {
@Override
public long getKeyPrefix() { return current.getKeyPrefix(); }
+
+@Override
+public void close() throws IOException {
+ if (iterators != null && !iterators.isEmpty()) {
+for (UnsafeSorterIterator iterator : iterators) {
+ closeIfPossible(iterator);
+}
+ }
+ if (current != null) {
+closeIfPossible(current);
+ }
+}
+
+private void closeIfPossible(UnsafeSorterIterator iterator) {
+ if (iterator instanceof Closeable) {
+IOUtils.closeQuietly(((Closeable) iterator));
+ }
+}
}
}
diff --git
a/sql/core/
[spark] branch master updated: [SPARK-38885][BUILD][FOLLOWUP] Fix compile error on `Appleslicon/MacOs` and ensure `./dev/test-dependencies.sh` produce the same results on Linux and `Appleslicon/MacOs`
This is an automated email from the ASF dual-hosted git repository. srowen pushed a commit to branch master in repository https://gitbox.apache.org/repos/asf/spark.git The following commit(s) were added to refs/heads/master by this push: new 7154fb989de [SPARK-38885][BUILD][FOLLOWUP] Fix compile error on `Appleslicon/MacOs` and ensure `./dev/test-dependencies.sh` produce the same results on Linux and `Appleslicon/MacOs` 7154fb989de is described below commit 7154fb989de9b0dfefb5dc8953ee63ab43dc414b Author: yangjie01 AuthorDate: Sun Apr 24 11:02:02 2022 -0500 [SPARK-38885][BUILD][FOLLOWUP] Fix compile error on `Appleslicon/MacOs` and ensure `./dev/test-dependencies.sh` produce the same results on Linux and `Appleslicon/MacOs` ### What changes were proposed in this pull request? After SPARK-38885 upgrading `Netty` to 4.1.76.Final, there are 2 problems: 1. `spark-network-yarn` module compile failed on `Appleslicon/MacOs` 2. The result file generated by `./dev/test-dependencies.sh --replace-manifest ` on Linux is different from that generated on `Appleslicon/MacOS`. This pr add Netty native dependencies explicitly to fix above 2 problems. ### Why are the changes needed? ix compile error on Appleslicon/MacOs and ensure `./dev/test-dependencies.sh --replace-manifest ` produce the same results on Linux and `Appleslicon/MacOS`. ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? - Pass GA - Manual test 1: Run `mvn clean install -DskipTests -Phadoop-3 -Phadoop-cloud -Pmesos -Pyarn -Pkinesis-asl -Phive-thriftserver -Pspark-ganglia-lgpl -Pkubernetes -Phive` **Before** ``` [ERROR] Failed to execute goal org.apache.maven.plugins:maven-antrun-plugin:1.8:run (unpack) on project spark-network-yarn_2.12: An Ant BuildException has occured: Warning: Could not find file /spark-source/common/network-yarn/target/exploded/META-INF/native/libnetty_transport_native_epoll_x86_64.so to copy. [ERROR] around Ant part .. 6:340 in /spark-source/common/network-yarn/target/antrun/build-main.xml [ERROR] -> [Help 1] [ERROR] [ERROR] To see the full stack trace of the errors, re-run Maven with the -e switch. [ERROR] Re-run Maven using the -X switch to enable full debug logging. [ERROR] [ERROR] For more information about the errors and possible solutions, please read the following articles: [ERROR] [Help 1] http://cwiki.apache.org/confluence/display/MAVEN/MojoExecutionException [ERROR] [ERROR] After correcting the problems, you can resume the build with the command [ERROR] mvn -rf :spark-network-yarn_2.12 ``` **After** ``` [INFO] BUILD SUCCESS [INFO] [INFO] Total time: 20:03 min [INFO] Finished at: 2022-04-24T19:31:23+08:00 [INFO] ``` - Manual test 2: Run `./dev/test-dependencies.sh --replace-manifest ` on `Appleslicon/MacOS` **Before** ``` diff --git a/dev/deps/spark-deps-hadoop-2-hive-2.3 b/dev/deps/spark-deps-hadoop-2-hive-2.3 index b6df3ea5ce..acf3d22600 100644 --- a/dev/deps/spark-deps-hadoop-2-hive-2.3 +++ b/dev/deps/spark-deps-hadoop-2-hive-2.3 -137,6 +137,7 javolution/5.5.1//javolution-5.5.1.jar jaxb-api/2.2.11//jaxb-api-2.2.11.jar jaxb-runtime/2.3.2//jaxb-runtime-2.3.2.jar jcl-over-slf4j/1.7.32//jcl-over-slf4j-1.7.32.jar +jctools-core/3.1.0//jctools-core-3.1.0.jar jdo-api/3.0.1//jdo-api-3.0.1.jar jersey-client/2.35//jersey-client-2.35.jar jersey-common/2.35//jersey-common-2.35.jar -209,10 +210,6 netty-resolver/4.1.76.Final//netty-resolver-4.1.76.Final.jar netty-tcnative-classes/2.0.51.Final//netty-tcnative-classes-2.0.51.Final.jar netty-transport-classes-epoll/4.1.76.Final//netty-transport-classes-epoll-4.1.76.Final.jar netty-transport-classes-kqueue/4.1.76.Final//netty-transport-classes-kqueue-4.1.76.Final.jar -netty-transport-native-epoll/4.1.76.Final/linux-aarch_64/netty-transport-native-epoll-4.1.76.Final-linux-aarch_64.jar -netty-transport-native-epoll/4.1.76.Final/linux-x86_64/netty-transport-native-epoll-4.1.76.Final-linux-x86_64.jar -netty-transport-native-kqueue/4.1.76.Final/osx-aarch_64/netty-transport-native-kqueue-4.1.76.Final-osx-aarch_64.jar -netty-transport-native-kqueue/4.1.76.Final/osx-x86_64/netty-transport-native-kqueue-4.1.76.Final-osx-x86_64.jar netty-transport-native-unix-common/4.1.76.Final//netty-transport-native-unix-common-4.1.76.Final.jar netty-transport/4.1.76.Final//netty-transport-4.1.76.Final.jar objenesis/3.2//objenesis-3.2.jar diff --git a/dev/deps/spark-deps-hadoop-3-hive-2.3 b/dev/deps/spark-deps-hadoop-3-hive-
[spark] branch master updated (80929d6b549 -> ffaceac4329)
This is an automated email from the ASF dual-hosted git repository. srowen pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git from 80929d6b549 [SPARK-38832][SQL][FOLLOWUP] Support propagate empty expression set for distinct key add ffaceac4329 [SPARK-38968][K8S] Remove a variable `hadoopConf` from `KerberosConfDriverFeatureStep` No new revisions were added by this update. Summary of changes: .../apache/spark/deploy/k8s/features/KerberosConfDriverFeatureStep.scala | 1 - 1 file changed, 1 deletion(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated: [SPARK-38910][YARN] Clean spark staging before `unregister`
This is an automated email from the ASF dual-hosted git repository.
srowen pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new 87c744b6050 [SPARK-38910][YARN] Clean spark staging before `unregister`
87c744b6050 is described below
commit 87c744b60507f82e1722f1488f1741cb2bb8e8e5
Author: Angerszh
AuthorDate: Mon Apr 18 11:18:48 2022 -0500
[SPARK-38910][YARN] Clean spark staging before `unregister`
### What changes were proposed in this pull request?
`ApplicationMaster`'s shutdown
```
ShutdownHookManager.addShutdownHook(priority) { () =>
try {
val maxAppAttempts = client.getMaxRegAttempts(sparkConf, yarnConf)
val isLastAttempt = appAttemptId.getAttemptId() >= maxAppAttempts
if (!finished) {
// The default state of ApplicationMaster is failed if it is
invoked by shut down hook.
// This behavior is different compared to 1.x version.
// If user application is exited ahead of time by calling
System.exit(N), here mark
// this application as failed with EXIT_EARLY. For a good
shutdown, user shouldn't call
// System.exit(0) to terminate the application.
finish(finalStatus,
ApplicationMaster.EXIT_EARLY,
"Shutdown hook called before final status was reported.")
}
if (!unregistered) {
// we only want to unregister if we don't want the RM to retry
if (finalStatus == FinalApplicationStatus.SUCCEEDED ||
isLastAttempt) {
unregister(finalStatus, finalMsg)
cleanupStagingDir(new
Path(System.getenv("SPARK_YARN_STAGING_DIR")))
}
}
} catch {
case e: Throwable =>
logWarning("Ignoring Exception while stopping ApplicationMaster
from shutdown hook", e)
}
}
```
`unregister` may throw exception, we should clean staging dir first.
### Why are the changes needed?
Clean staging dir
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Closes #36207 from AngersZh/SPARK-38910.
Authored-by: Angerszh
Signed-off-by: Sean Owen
---
.../src/main/scala/org/apache/spark/deploy/yarn/ApplicationMaster.scala | 2 +-
1 file changed, 1 insertion(+), 1 deletion(-)
diff --git
a/resource-managers/yarn/src/main/scala/org/apache/spark/deploy/yarn/ApplicationMaster.scala
b/resource-managers/yarn/src/main/scala/org/apache/spark/deploy/yarn/ApplicationMaster.scala
index 99ad181a542..b15623ceff5 100644
---
a/resource-managers/yarn/src/main/scala/org/apache/spark/deploy/yarn/ApplicationMaster.scala
+++
b/resource-managers/yarn/src/main/scala/org/apache/spark/deploy/yarn/ApplicationMaster.scala
@@ -261,8 +261,8 @@ private[spark] class ApplicationMaster(
if (!unregistered) {
// we only want to unregister if we don't want the RM to retry
if (finalStatus == FinalApplicationStatus.SUCCEEDED ||
isLastAttempt) {
- unregister(finalStatus, finalMsg)
cleanupStagingDir(new
Path(System.getenv("SPARK_YARN_STAGING_DIR")))
+ unregister(finalStatus, finalMsg)
}
}
} catch {
-
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated (dff52d649d1 -> 6d3c1c10c4a)
This is an automated email from the ASF dual-hosted git repository. srowen pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git from dff52d649d1 [SPARK-37015][PYTHON] Inline type hints for python/pyspark/streaming/dstream.py add 6d3c1c10c4a [SPARK-38885][BUILD] Upgrade Netty to 4.1.76 No new revisions were added by this update. Summary of changes: dev/deps/spark-deps-hadoop-2-hive-2.3 | 30 +++--- dev/deps/spark-deps-hadoop-3-hive-2.3 | 30 +++--- pom.xml | 4 ++-- 3 files changed, 32 insertions(+), 32 deletions(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated: [MINOR] Improve to update some mutable hash maps
This is an automated email from the ASF dual-hosted git repository.
srowen pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new 2a667fbff7e [MINOR] Improve to update some mutable hash maps
2a667fbff7e is described below
commit 2a667fbff7e7fd21bf69668ef78b175f60a24dba
Author: weixiuli
AuthorDate: Mon Apr 18 09:22:24 2022 -0500
[MINOR] Improve to update some mutable hash maps
### What changes were proposed in this pull request?
Improve to update some mutable hash maps
### Why are the changes needed?
Reduce some mutable hash maps calls and cleanup code.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Existing unittests.
Closes #36179 from weixiuli/update-numBlocksInFlightPerAddress.
Authored-by: weixiuli
Signed-off-by: Sean Owen
---
.../main/scala/org/apache/spark/deploy/worker/Worker.scala| 4 ++--
.../scala/org/apache/spark/resource/ResourceAllocator.scala | 4 ++--
.../scala/org/apache/spark/shuffle/ShuffleBlockPusher.scala | 2 +-
.../apache/spark/storage/ShuffleBlockFetcherIterator.scala| 11 +--
.../scala/org/apache/spark/ml/classification/NaiveBayes.scala | 2 +-
.../src/main/scala/org/apache/spark/ml/stat/Summarizer.scala | 2 +-
6 files changed, 12 insertions(+), 13 deletions(-)
diff --git a/core/src/main/scala/org/apache/spark/deploy/worker/Worker.scala
b/core/src/main/scala/org/apache/spark/deploy/worker/Worker.scala
index 2c7021bdcb9..b26a0f82d69 100755
--- a/core/src/main/scala/org/apache/spark/deploy/worker/Worker.scala
+++ b/core/src/main/scala/org/apache/spark/deploy/worker/Worker.scala
@@ -264,13 +264,13 @@ private[deploy] class Worker(
private def addResourcesUsed(deltaInfo: Map[String, ResourceInformation]):
Unit = {
deltaInfo.foreach { case (rName, rInfo) =>
- resourcesUsed(rName) = resourcesUsed(rName) + rInfo
+ resourcesUsed(rName) += rInfo
}
}
private def removeResourcesUsed(deltaInfo: Map[String,
ResourceInformation]): Unit = {
deltaInfo.foreach { case (rName, rInfo) =>
- resourcesUsed(rName) = resourcesUsed(rName) - rInfo
+ resourcesUsed(rName) -= rInfo
}
}
diff --git
a/core/src/main/scala/org/apache/spark/resource/ResourceAllocator.scala
b/core/src/main/scala/org/apache/spark/resource/ResourceAllocator.scala
index 7605e8c44b9..10cf0402d5f 100644
--- a/core/src/main/scala/org/apache/spark/resource/ResourceAllocator.scala
+++ b/core/src/main/scala/org/apache/spark/resource/ResourceAllocator.scala
@@ -82,7 +82,7 @@ private[spark] trait ResourceAllocator {
}
val isAvailable = addressAvailabilityMap(address)
if (isAvailable > 0) {
-addressAvailabilityMap(address) = addressAvailabilityMap(address) - 1
+addressAvailabilityMap(address) -= 1
} else {
throw new SparkException("Try to acquire an address that is not
available. " +
s"$resourceName address $address is not available.")
@@ -103,7 +103,7 @@ private[spark] trait ResourceAllocator {
}
val isAvailable = addressAvailabilityMap(address)
if (isAvailable < slotsPerAddress) {
-addressAvailabilityMap(address) = addressAvailabilityMap(address) + 1
+addressAvailabilityMap(address) += 1
} else {
throw new SparkException(s"Try to release an address that is not
assigned. $resourceName " +
s"address $address is not assigned.")
diff --git
a/core/src/main/scala/org/apache/spark/shuffle/ShuffleBlockPusher.scala
b/core/src/main/scala/org/apache/spark/shuffle/ShuffleBlockPusher.scala
index 230ec7efdb1..15a9ddd40e6 100644
--- a/core/src/main/scala/org/apache/spark/shuffle/ShuffleBlockPusher.scala
+++ b/core/src/main/scala/org/apache/spark/shuffle/ShuffleBlockPusher.scala
@@ -317,7 +317,7 @@ private[spark] class ShuffleBlockPusher(conf: SparkConf)
extends Logging {
pushResult: PushResult): Boolean = synchronized {
remainingBlocks -= pushResult.blockId
bytesInFlight -= bytesPushed
-numBlocksInFlightPerAddress(address) =
numBlocksInFlightPerAddress(address) - 1
+numBlocksInFlightPerAddress(address) -= 1
if (remainingBlocks.isEmpty) {
reqsInFlight -= 1
}
diff --git
a/core/src/main/scala/org/apache/spark/storage/ShuffleBlockFetcherIterator.scala
b/core/src/main/scala/org/apache/spark/storage/ShuffleBlockFetcherIterator.scala
index e2fc5389091..c91aaa8ddb7 100644
---
a/core/src/main/scala/org/apache/spark/storage/ShuffleBlockFetcherIterator.scala
+++
b/core/src/main/scala/org/apache/spark/storage/ShuffleBlockFetcherIterator.scala
@@ -763,7 +763,7 @@ final class ShuffleBlockFetcherIterator(
shuffleMetrics.incLocalBlocksFetched(1)
shuffleMet
[spark] branch master updated: [SPARK-38826][SQL][DOCS] dropFieldIfAllNull option does not work for empty JSON struct
This is an automated email from the ASF dual-hosted git repository. srowen pushed a commit to branch master in repository https://gitbox.apache.org/repos/asf/spark.git The following commit(s) were added to refs/heads/master by this push: new 078f50b16f0 [SPARK-38826][SQL][DOCS] dropFieldIfAllNull option does not work for empty JSON struct 078f50b16f0 is described below commit 078f50b16f07db6df169254fac36f8c41201ca61 Author: morvenhuang AuthorDate: Sun Apr 17 08:51:20 2022 -0500 [SPARK-38826][SQL][DOCS] dropFieldIfAllNull option does not work for empty JSON struct ### What changes were proposed in this pull request? Make a minor correction for the documentation of json option `dropFieldIfAllNull` ### Why are the changes needed? The `dropFieldIfAllNull` option actually does not work for empty json struct due to [SPARK-8093](https://issues.apache.org/jira/browse/SPARK-8093), the empty struct will be dropped anyway. We should update the doc, otherwise it would be confusing. ### Does this PR introduce _any_ user-facing change? Yes ### How was this patch tested? I've built the documentation locally and tested my change. Closes #36111 from morvenhuang/SPARK-38826. Authored-by: morvenhuang Signed-off-by: Sean Owen --- docs/sql-data-sources-json.md | 2 +- 1 file changed, 1 insertion(+), 1 deletion(-) diff --git a/docs/sql-data-sources-json.md b/docs/sql-data-sources-json.md index b5f27aacf41..f75efd1108a 100644 --- a/docs/sql-data-sources-json.md +++ b/docs/sql-data-sources-json.md @@ -235,7 +235,7 @@ Data source options of JSON can be set via: dropFieldIfAllNull false -Whether to ignore column of all null values or empty array/struct during schema inference. +Whether to ignore column of all null values or empty array during schema inference. read - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch branch-3.3 updated: [SPARK-38640][CORE] Fix NPE with memory-only cache blocks and RDD fetching
This is an automated email from the ASF dual-hosted git repository.
srowen pushed a commit to branch branch-3.3
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/branch-3.3 by this push:
new c10160b4163 [SPARK-38640][CORE] Fix NPE with memory-only cache blocks
and RDD fetching
c10160b4163 is described below
commit c10160b4163be00b8009cb462b1e33704b0ff3d6
Author: Adam Binford
AuthorDate: Sun Apr 17 08:39:27 2022 -0500
[SPARK-38640][CORE] Fix NPE with memory-only cache blocks and RDD fetching
### What changes were proposed in this pull request?
Fixes a bug where if `spark.shuffle.service.fetch.rdd.enabled=true`,
memory-only cached blocks will fail to unpersist.
### Why are the changes needed?
In https://github.com/apache/spark/pull/33020, when all RDD blocks are
removed from `externalShuffleServiceBlockStatus`, the underlying Map is nulled
to reduce memory. When persisting blocks we check if it's using disk before
adding it to `externalShuffleServiceBlockStatus`, but when removing them there
is no check, so a memory-only cache block will keep
`externalShuffleServiceBlockStatus` null, and when unpersisting it throw an NPE
because it tries to remove from the null Map. This a [...]
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
New and updated UT
Closes #35959 from Kimahriman/fetch-rdd-memory-only-unpersist.
Authored-by: Adam Binford
Signed-off-by: Sean Owen
(cherry picked from commit e0939f0f7c3d3bd4baa89e720038dbd3c7363a72)
Signed-off-by: Sean Owen
---
.../spark/storage/BlockManagerMasterEndpoint.scala | 8 +---
.../apache/spark/ExternalShuffleServiceSuite.scala | 22 ++
.../spark/storage/BlockManagerInfoSuite.scala | 2 ++
3 files changed, 29 insertions(+), 3 deletions(-)
diff --git
a/core/src/main/scala/org/apache/spark/storage/BlockManagerMasterEndpoint.scala
b/core/src/main/scala/org/apache/spark/storage/BlockManagerMasterEndpoint.scala
index 4d8ba9b3e4e..adeb507941c 100644
---
a/core/src/main/scala/org/apache/spark/storage/BlockManagerMasterEndpoint.scala
+++
b/core/src/main/scala/org/apache/spark/storage/BlockManagerMasterEndpoint.scala
@@ -838,9 +838,11 @@ private[spark] class BlockStatusPerBlockId {
}
def remove(blockId: BlockId): Unit = {
-blocks.remove(blockId)
-if (blocks.isEmpty) {
- blocks = null
+if (blocks != null) {
+ blocks.remove(blockId)
+ if (blocks.isEmpty) {
+blocks = null
+ }
}
}
diff --git
a/core/src/test/scala/org/apache/spark/ExternalShuffleServiceSuite.scala
b/core/src/test/scala/org/apache/spark/ExternalShuffleServiceSuite.scala
index dd3d90f3124..1ca78d572c7 100644
--- a/core/src/test/scala/org/apache/spark/ExternalShuffleServiceSuite.scala
+++ b/core/src/test/scala/org/apache/spark/ExternalShuffleServiceSuite.scala
@@ -255,4 +255,26 @@ class ExternalShuffleServiceSuite extends ShuffleSuite
with BeforeAndAfterAll wi
}
}
}
+
+ test("SPARK-38640: memory only blocks can unpersist using shuffle service
cache fetching") {
+for (enabled <- Seq(true, false)) {
+ val confWithRddFetch =
+conf.clone.set(config.SHUFFLE_SERVICE_FETCH_RDD_ENABLED, enabled)
+ sc = new SparkContext("local-cluster[1,1,1024]", "test",
confWithRddFetch)
+ sc.env.blockManager.externalShuffleServiceEnabled should equal(true)
+ sc.env.blockManager.blockStoreClient.getClass should
equal(classOf[ExternalBlockStoreClient])
+ try {
+val rdd = sc.parallelize(0 until 100, 2)
+ .map { i => (i, 1) }
+ .persist(StorageLevel.MEMORY_ONLY)
+
+rdd.count()
+rdd.unpersist(true)
+assert(sc.persistentRdds.isEmpty)
+ } finally {
+rpcHandler.applicationRemoved(sc.conf.getAppId, true)
+sc.stop()
+ }
+}
+ }
}
diff --git
a/core/src/test/scala/org/apache/spark/storage/BlockManagerInfoSuite.scala
b/core/src/test/scala/org/apache/spark/storage/BlockManagerInfoSuite.scala
index f0c19c5ccce..85f012aece3 100644
--- a/core/src/test/scala/org/apache/spark/storage/BlockManagerInfoSuite.scala
+++ b/core/src/test/scala/org/apache/spark/storage/BlockManagerInfoSuite.scala
@@ -63,6 +63,8 @@ class BlockManagerInfoSuite extends SparkFunSuite {
if (svcEnabled) {
assert(getEssBlockStatus(bmInfo, rddId).isEmpty)
}
+bmInfo.updateBlockInfo(rddId, StorageLevel.NONE, memSize = 0, diskSize = 0)
+assert(bmInfo.remainingMem === 3)
}
testWithShuffleServiceOnOff("RDD block with MEMORY_AND_DISK") { (svcEnabled,
bmInfo) =>
-
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated: [SPARK-38640][CORE] Fix NPE with memory-only cache blocks and RDD fetching
This is an automated email from the ASF dual-hosted git repository.
srowen pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new e0939f0f7c3 [SPARK-38640][CORE] Fix NPE with memory-only cache blocks
and RDD fetching
e0939f0f7c3 is described below
commit e0939f0f7c3d3bd4baa89e720038dbd3c7363a72
Author: Adam Binford
AuthorDate: Sun Apr 17 08:39:27 2022 -0500
[SPARK-38640][CORE] Fix NPE with memory-only cache blocks and RDD fetching
### What changes were proposed in this pull request?
Fixes a bug where if `spark.shuffle.service.fetch.rdd.enabled=true`,
memory-only cached blocks will fail to unpersist.
### Why are the changes needed?
In https://github.com/apache/spark/pull/33020, when all RDD blocks are
removed from `externalShuffleServiceBlockStatus`, the underlying Map is nulled
to reduce memory. When persisting blocks we check if it's using disk before
adding it to `externalShuffleServiceBlockStatus`, but when removing them there
is no check, so a memory-only cache block will keep
`externalShuffleServiceBlockStatus` null, and when unpersisting it throw an NPE
because it tries to remove from the null Map. This a [...]
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
New and updated UT
Closes #35959 from Kimahriman/fetch-rdd-memory-only-unpersist.
Authored-by: Adam Binford
Signed-off-by: Sean Owen
---
.../spark/storage/BlockManagerMasterEndpoint.scala | 8 +---
.../apache/spark/ExternalShuffleServiceSuite.scala | 22 ++
.../spark/storage/BlockManagerInfoSuite.scala | 2 ++
3 files changed, 29 insertions(+), 3 deletions(-)
diff --git
a/core/src/main/scala/org/apache/spark/storage/BlockManagerMasterEndpoint.scala
b/core/src/main/scala/org/apache/spark/storage/BlockManagerMasterEndpoint.scala
index 4d8ba9b3e4e..adeb507941c 100644
---
a/core/src/main/scala/org/apache/spark/storage/BlockManagerMasterEndpoint.scala
+++
b/core/src/main/scala/org/apache/spark/storage/BlockManagerMasterEndpoint.scala
@@ -838,9 +838,11 @@ private[spark] class BlockStatusPerBlockId {
}
def remove(blockId: BlockId): Unit = {
-blocks.remove(blockId)
-if (blocks.isEmpty) {
- blocks = null
+if (blocks != null) {
+ blocks.remove(blockId)
+ if (blocks.isEmpty) {
+blocks = null
+ }
}
}
diff --git
a/core/src/test/scala/org/apache/spark/ExternalShuffleServiceSuite.scala
b/core/src/test/scala/org/apache/spark/ExternalShuffleServiceSuite.scala
index dd3d90f3124..1ca78d572c7 100644
--- a/core/src/test/scala/org/apache/spark/ExternalShuffleServiceSuite.scala
+++ b/core/src/test/scala/org/apache/spark/ExternalShuffleServiceSuite.scala
@@ -255,4 +255,26 @@ class ExternalShuffleServiceSuite extends ShuffleSuite
with BeforeAndAfterAll wi
}
}
}
+
+ test("SPARK-38640: memory only blocks can unpersist using shuffle service
cache fetching") {
+for (enabled <- Seq(true, false)) {
+ val confWithRddFetch =
+conf.clone.set(config.SHUFFLE_SERVICE_FETCH_RDD_ENABLED, enabled)
+ sc = new SparkContext("local-cluster[1,1,1024]", "test",
confWithRddFetch)
+ sc.env.blockManager.externalShuffleServiceEnabled should equal(true)
+ sc.env.blockManager.blockStoreClient.getClass should
equal(classOf[ExternalBlockStoreClient])
+ try {
+val rdd = sc.parallelize(0 until 100, 2)
+ .map { i => (i, 1) }
+ .persist(StorageLevel.MEMORY_ONLY)
+
+rdd.count()
+rdd.unpersist(true)
+assert(sc.persistentRdds.isEmpty)
+ } finally {
+rpcHandler.applicationRemoved(sc.conf.getAppId, true)
+sc.stop()
+ }
+}
+ }
}
diff --git
a/core/src/test/scala/org/apache/spark/storage/BlockManagerInfoSuite.scala
b/core/src/test/scala/org/apache/spark/storage/BlockManagerInfoSuite.scala
index f0c19c5ccce..85f012aece3 100644
--- a/core/src/test/scala/org/apache/spark/storage/BlockManagerInfoSuite.scala
+++ b/core/src/test/scala/org/apache/spark/storage/BlockManagerInfoSuite.scala
@@ -63,6 +63,8 @@ class BlockManagerInfoSuite extends SparkFunSuite {
if (svcEnabled) {
assert(getEssBlockStatus(bmInfo, rddId).isEmpty)
}
+bmInfo.updateBlockInfo(rddId, StorageLevel.NONE, memSize = 0, diskSize = 0)
+assert(bmInfo.remainingMem === 3)
}
testWithShuffleServiceOnOff("RDD block with MEMORY_AND_DISK") { (svcEnabled,
bmInfo) =>
-
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated: [SPARK-38881][DSTREAMS][KINESIS][PYSPARK] Added Support for CloudWatch MetricsLevel Config
This is an automated email from the ASF dual-hosted git repository.
srowen pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new 907074bafad [SPARK-38881][DSTREAMS][KINESIS][PYSPARK] Added Support
for CloudWatch MetricsLevel Config
907074bafad is described below
commit 907074bafad0da3d1c802a4389589658ecf93432
Author: Mark Khaitman
AuthorDate: Sat Apr 16 21:30:15 2022 -0500
[SPARK-38881][DSTREAMS][KINESIS][PYSPARK] Added Support for CloudWatch
MetricsLevel Config
JIRA: https://issues.apache.org/jira/browse/SPARK-38881
### What changes were proposed in this pull request?
Exposing a configuration option (metricsLevel) used for CloudWatch metrics
reporting when consuming from an AWS Kinesis Stream, which is already available
in Scala/Java Spark APIs
This relates to https://issues.apache.org/jira/browse/SPARK-27420 which was
merged as part of Spark 3.0.0
### Why are the changes needed?
This change is desirable as it further exposes the metricsLevel config
parameter that was added for the Scala/Java Spark APIs when working with the
Kinesis Streaming integration, and makes it available to the PySpark API as
well.
### Does this PR introduce _any_ user-facing change?
No. Default behavior of MetricsLevel.DETAILED is maintained.
### How was this patch tested?
This change passes all tests, and local testing was done with a development
Kinesis stream in AWS, in order to confirm that metrics were no longer being
reported to CloudWatch after specifying MetricsLevel.NONE in the PySpark
Kinesis streaming context creation, and also worked as it does today when
leaving the MetricsLevel parameter out, which would result in a default of
DETAILED, with CloudWatch metrics appearing again.
Built with:
```
# ./build/mvn -pl :spark-streaming-kinesis-asl_2.12 -DskipTests
-Pkinesis-asl clean install
```
Tested with small pyspark kinesis streaming context + AWS kinesis stream,
using updated streaming kinesis asl jar:
```
# spark-submit --packages
org.apache.spark:spark-streaming-kinesis-asl_2.12:3.2.1 --jars
spark/connector/kinesis-asl/target/spark-streaming-kinesis-asl_2.12-3.4.0-SNAPSHOT.jar
metricsLevelTesting.py
```
Closes #36201 from mkman84/metricsLevel-pyspark.
Authored-by: Mark Khaitman
Signed-off-by: Sean Owen
---
.../kinesis/KinesisUtilsPythonHelper.scala | 10 ++
docs/streaming-kinesis-integration.md | 10 ++
python/pyspark/streaming/kinesis.py| 22 +-
python/pyspark/streaming/tests/test_kinesis.py | 5 -
4 files changed, 37 insertions(+), 10 deletions(-)
diff --git
a/connector/kinesis-asl/src/main/scala/org/apache/spark/streaming/kinesis/KinesisUtilsPythonHelper.scala
b/connector/kinesis-asl/src/main/scala/org/apache/spark/streaming/kinesis/KinesisUtilsPythonHelper.scala
index 0056438c4ee..8abaef6b834 100644
---
a/connector/kinesis-asl/src/main/scala/org/apache/spark/streaming/kinesis/KinesisUtilsPythonHelper.scala
+++
b/connector/kinesis-asl/src/main/scala/org/apache/spark/streaming/kinesis/KinesisUtilsPythonHelper.scala
@@ -17,6 +17,7 @@
package org.apache.spark.streaming.kinesis
import
com.amazonaws.services.kinesis.clientlibrary.lib.worker.InitialPositionInStream
+import com.amazonaws.services.kinesis.metrics.interfaces.MetricsLevel
import org.apache.spark.storage.StorageLevel
import org.apache.spark.streaming.Duration
@@ -37,6 +38,7 @@ private class KinesisUtilsPythonHelper {
regionName: String,
initialPositionInStream: Int,
checkpointInterval: Duration,
+ metricsLevel: Int,
storageLevel: StorageLevel,
awsAccessKeyId: String,
awsSecretKey: String,
@@ -64,6 +66,13 @@ private class KinesisUtilsPythonHelper {
"InitialPositionInStream.LATEST or
InitialPositionInStream.TRIM_HORIZON")
}
+val cloudWatchMetricsLevel = metricsLevel match {
+ case 0 => MetricsLevel.DETAILED
+ case 1 => MetricsLevel.SUMMARY
+ case 2 => MetricsLevel.NONE
+ case _ => MetricsLevel.DETAILED
+}
+
val builder = KinesisInputDStream.builder.
streamingContext(jssc).
checkpointAppName(kinesisAppName).
@@ -72,6 +81,7 @@ private class KinesisUtilsPythonHelper {
regionName(regionName).
initialPosition(KinesisInitialPositions.fromKinesisInitialPosition(kinesisInitialPosition)).
checkpointInterval(checkpointInterval).
+ metricsLevel(cloudWatchMetricsLevel).
storageLevel(storageLevel)
if (stsAssumeRoleArn != null && stsSessionName != null && stsExternalId !=
null) {
diff --git a/docs/streaming-kinesis-integration.md
b/docs/streaming-kinesis-integration.md
index dc80
[spark] branch master updated (8548a8221cf -> eced406b600)
This is an automated email from the ASF dual-hosted git repository. srowen pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git from 8548a8221cf [SPARK-38738][SQL][TESTS] Test the error class: INVALID_FRACTION_OF_SECOND add eced406b600 [SPARK-38660][PYTHON] PySpark DeprecationWarning: distutils Version classes are deprecated No new revisions were added by this update. Summary of changes: python/pyspark/__init__.py | 5 + 1 file changed, 5 insertions(+) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated: [SPARK-38847][CORE][SQL][SS] Introduce a `viewToSeq` function for `KVUtils` to close `KVStoreIterator` in time
This is an automated email from the ASF dual-hosted git repository.
srowen pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new 61aa65d9f89 [SPARK-38847][CORE][SQL][SS] Introduce a `viewToSeq`
function for `KVUtils` to close `KVStoreIterator` in time
61aa65d9f89 is described below
commit 61aa65d9f897f29813cbbc77b6d0dbad770c8954
Author: yangjie01
AuthorDate: Tue Apr 12 09:25:03 2022 -0500
[SPARK-38847][CORE][SQL][SS] Introduce a `viewToSeq` function for `KVUtils`
to close `KVStoreIterator` in time
### What changes were proposed in this pull request?
There are many codes in spark that convert `KVStoreView` into scala `List`,
and these codes will not close `KVStoreIterator`, these resources are mainly
recycled by `finalize()` method implemented in `LevelDB` and `RockSB`, this
makes `KVStoreIterator` resource recycling unpredictable.
This pr introduce a `viewToSeq` function for `KVUtils`, this function will
convert all data in the `KVStoreView` into scala `List` and close
`KVStoreIterator` in time.
### Why are the changes needed?
Add a general function to convert `KVStoreView` into scala `List` and close
`KVStoreIterator` in time.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Pass GA
Closes #36132 from LuciferYang/kvutils-viewToSeq.
Authored-by: yangjie01
Signed-off-by: Sean Owen
---
.../spark/deploy/history/FsHistoryProvider.scala | 26 +++---
.../deploy/history/HistoryServerDiskManager.scala | 8 +++
.../apache/spark/status/AppStatusListener.scala| 10 -
.../org/apache/spark/status/AppStatusStore.scala | 2 +-
.../scala/org/apache/spark/status/KVUtils.scala| 8 +++
.../deploy/history/FsHistoryProviderSuite.scala| 10 -
.../spark/status/AppStatusListenerSuite.scala | 23 +--
.../spark/sql/execution/ui/SQLAppStatusStore.scala | 6 ++---
.../execution/ui/StreamingQueryStatusStore.scala | 6 ++---
.../ui/StreamingQueryStatusListener.scala | 2 +-
.../ui/HiveThriftServer2AppStatusStore.scala | 5 +++--
11 files changed, 50 insertions(+), 56 deletions(-)
diff --git
a/core/src/main/scala/org/apache/spark/deploy/history/FsHistoryProvider.scala
b/core/src/main/scala/org/apache/spark/deploy/history/FsHistoryProvider.scala
index a9adaed374a..dddb7da617f 100644
---
a/core/src/main/scala/org/apache/spark/deploy/history/FsHistoryProvider.scala
+++
b/core/src/main/scala/org/apache/spark/deploy/history/FsHistoryProvider.scala
@@ -592,11 +592,9 @@ private[history] class FsHistoryProvider(conf: SparkConf,
clock: Clock)
// Only entries with valid applications are cleaned up here. Cleaning up
invalid log
// files is done by the periodic cleaner task.
val stale = listing.synchronized {
-listing.view(classOf[LogInfo])
+KVUtils.viewToSeq(listing.view(classOf[LogInfo])
.index("lastProcessed")
- .last(newLastScanTime - 1)
- .asScala
- .toList
+ .last(newLastScanTime - 1))
}
stale.filterNot(isProcessing)
.filterNot(info => notStale.contains(info.logPath))
@@ -957,12 +955,10 @@ private[history] class FsHistoryProvider(conf: SparkConf,
clock: Clock)
val maxTime = clock.getTimeMillis() - conf.get(MAX_LOG_AGE_S) * 1000
val maxNum = conf.get(MAX_LOG_NUM)
-val expired = listing.view(classOf[ApplicationInfoWrapper])
+val expired =
KVUtils.viewToSeq(listing.view(classOf[ApplicationInfoWrapper])
.index("oldestAttempt")
.reverse()
- .first(maxTime)
- .asScala
- .toList
+ .first(maxTime))
expired.foreach { app =>
// Applications may have multiple attempts, some of which may not need
to be deleted yet.
val (remaining, toDelete) = app.attempts.partition { attempt =>
@@ -972,13 +968,10 @@ private[history] class FsHistoryProvider(conf: SparkConf,
clock: Clock)
}
// Delete log files that don't have a valid application and exceed the
configured max age.
-val stale = listing.view(classOf[LogInfo])
+val stale = KVUtils.viewToSeq(listing.view(classOf[LogInfo])
.index("lastProcessed")
.reverse()
- .first(maxTime)
- .asScala
- .filter { l => l.logType == null || l.logType == LogType.EventLogs }
- .toList
+ .first(maxTime), Int.MaxValue) { l => l.logType == null || l.logType ==
LogType.EventLogs }
stale.filterNot(isProcessing).foreach { log =>
if (log.appId.isEmpty) {
logInfo(s"Deleting invalid / corrupt event log ${log.logPath}")
@@ -1080,13 +1073,10 @@ private[history] class FsHistoryProvider(conf:
SparkConf, clock: Clock)
// Delete driver log file entries th
[spark] branch master updated: [SPARK-38848][TESTS] Replcace all `@Test(expected = XXException)` with `assertThrows`
This is an automated email from the ASF dual-hosted git repository.
srowen pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new 29b9537e00d [SPARK-38848][TESTS] Replcace all `@Test(expected =
XXException)` with `assertThrows`
29b9537e00d is described below
commit 29b9537e00d857c92378648ca7163ba0dc63da39
Author: yangjie01
AuthorDate: Tue Apr 12 09:24:10 2022 -0500
[SPARK-38848][TESTS] Replcace all `@Test(expected = XXException)` with
`assertThrows`
### What changes were proposed in this pull request?
`Test` no longer has `expected` parameters in Junit 5, this pr replace them
with `assertThrows` to reduce the workload of future migration from Junit 4 to
Junit 5.
### Why are the changes needed?
Reduce Api usage that JUnit 5 no longer supports.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Pass GA
Closes #36133 from LuciferYang/assert-throws-2.
Lead-authored-by: yangjie01
Co-authored-by: YangJie
Signed-off-by: Sean Owen
---
.../spark/util/kvstore/LevelDBTypeInfoSuite.java | 42 --
.../spark/util/kvstore/RocksDBTypeInfoSuite.java | 42 --
.../client/TransportClientFactorySuite.java| 7 ++--
.../spark/network/crypto/AuthEngineSuite.java | 33 +
.../network/util/TransportFrameDecoderSuite.java | 12 +++
.../shuffle/RemoteBlockPushResolverSuite.java | 5 +--
.../org/apache/spark/unsafe/PlatformUtilSuite.java | 8 ++---
.../org/apache/spark/api/java/OptionalSuite.java | 15
.../spark/memory/TaskMemoryManagerSuite.java | 8 ++---
.../shuffle/sort/UnsafeShuffleWriterSuite.java | 8 ++---
.../spark/launcher/ChildProcAppHandleSuite.java| 28 ---
.../launcher/SparkSubmitCommandBuilderSuite.java | 11 +++---
.../launcher/SparkSubmitOptionParserSuite.java | 6 ++--
.../org/apache/spark/sql/JavaDataFrameSuite.java | 5 +--
.../org/apache/spark/sql/JavaDatasetSuite.java | 30 +---
.../test/org/apache/spark/sql/JavaUDFSuite.java| 5 +--
16 files changed, 149 insertions(+), 116 deletions(-)
diff --git
a/common/kvstore/src/test/java/org/apache/spark/util/kvstore/LevelDBTypeInfoSuite.java
b/common/kvstore/src/test/java/org/apache/spark/util/kvstore/LevelDBTypeInfoSuite.java
index 38db3bedaef..0359e11404c 100644
---
a/common/kvstore/src/test/java/org/apache/spark/util/kvstore/LevelDBTypeInfoSuite.java
+++
b/common/kvstore/src/test/java/org/apache/spark/util/kvstore/LevelDBTypeInfoSuite.java
@@ -43,34 +43,40 @@ public class LevelDBTypeInfoSuite {
assertEquals(t1.child, ti.getIndexValue("child", t1));
}
- @Test(expected = IllegalArgumentException.class)
- public void testNoNaturalIndex() throws Exception {
-newTypeInfo(NoNaturalIndex.class);
+ @Test
+ public void testNoNaturalIndex() {
+assertThrows(IllegalArgumentException.class,
+ () -> newTypeInfo(NoNaturalIndex.class));
}
- @Test(expected = IllegalArgumentException.class)
- public void testNoNaturalIndex2() throws Exception {
-newTypeInfo(NoNaturalIndex2.class);
+ @Test
+ public void testNoNaturalIndex2() {
+assertThrows(IllegalArgumentException.class,
+ () -> newTypeInfo(NoNaturalIndex2.class));
}
- @Test(expected = IllegalArgumentException.class)
- public void testDuplicateIndex() throws Exception {
-newTypeInfo(DuplicateIndex.class);
+ @Test
+ public void testDuplicateIndex() {
+assertThrows(IllegalArgumentException.class,
+ () -> newTypeInfo(DuplicateIndex.class));
}
- @Test(expected = IllegalArgumentException.class)
- public void testEmptyIndexName() throws Exception {
-newTypeInfo(EmptyIndexName.class);
+ @Test
+ public void testEmptyIndexName() {
+assertThrows(IllegalArgumentException.class,
+ () -> newTypeInfo(EmptyIndexName.class));
}
- @Test(expected = IllegalArgumentException.class)
- public void testIllegalIndexName() throws Exception {
-newTypeInfo(IllegalIndexName.class);
+ @Test
+ public void testIllegalIndexName() {
+assertThrows(IllegalArgumentException.class,
+ () -> newTypeInfo(IllegalIndexName.class));
}
- @Test(expected = IllegalArgumentException.class)
- public void testIllegalIndexMethod() throws Exception {
-newTypeInfo(IllegalIndexMethod.class);
+ @Test
+ public void testIllegalIndexMethod() {
+assertThrows(IllegalArgumentException.class,
+ () -> newTypeInfo(IllegalIndexMethod.class));
}
@Test
diff --git
a/common/kvstore/src/test/java/org/apache/spark/util/kvstore/RocksDBTypeInfoSuite.java
b/common/kvstore/src/test/java/org/apache/spark/util/kvstore/RocksDBTypeInfoSuite.java
index a51fd1a7fea..f694fd36b68 100644
---
a/common/kvstore/src/test/java/o
[spark] branch master updated: [SPARK-38799][INFRA] Replace BSD 3-clause with ASF License v2 for scala binaries
This is an automated email from the ASF dual-hosted git repository. srowen pushed a commit to branch master in repository https://gitbox.apache.org/repos/asf/spark.git The following commit(s) were added to refs/heads/master by this push: new 62cc198cc0f [SPARK-38799][INFRA] Replace BSD 3-clause with ASF License v2 for scala binaries 62cc198cc0f is described below commit 62cc198cc0f26e6f01276ff3338a6b21ae2663a8 Author: Kent Yao AuthorDate: Wed Apr 6 07:28:17 2022 -0500 [SPARK-38799][INFRA] Replace BSD 3-clause with ASF License v2 for scala binaries ### What changes were proposed in this pull request? Replace BSD 3-clause with ASF License v2 for scala binaries ### Why are the changes needed? Scala distribution is released under the ASF License v2 since 2.12.x, while 2.11.x is BSD 3-clause, see https://www.scala-lang.org/news/license-change.html https://www.scala-lang.org/download/2.11.12.html https://www.scala-lang.org/download/2.13.8.html https://www.scala-lang.org/download/2.12.15.html ### Does this PR introduce _any_ user-facing change? yes, people who use the binary distribution of spark shall be aware of the licenses from upstream. ### How was this patch tested? pass GHA Closes #36081 from yaooqinn/SPARK-38799. Authored-by: Kent Yao Signed-off-by: Sean Owen --- LICENSE-binary| 8 licenses-binary/LICENSE-scala.txt | 30 -- 2 files changed, 4 insertions(+), 34 deletions(-) diff --git a/LICENSE-binary b/LICENSE-binary index 8bbc913262c..a090e5205cc 100644 --- a/LICENSE-binary +++ b/LICENSE-binary @@ -382,6 +382,10 @@ org.eclipse.jetty:jetty-servlets org.eclipse.jetty:jetty-util org.eclipse.jetty:jetty-webapp org.eclipse.jetty:jetty-xml +org.scala-lang:scala-compiler +org.scala-lang:scala-library +org.scala-lang:scala-reflect +org.scala-lang.modules:scala-parser-combinators_2.12 org.scala-lang.modules:scala-xml_2.12 com.github.joshelser:dropwizard-metrics-hadoop-metrics2-reporter com.zaxxer.HikariCP @@ -445,10 +449,6 @@ org.antlr:stringtemplate org.antlr:antlr4-runtime antlr:antlr com.thoughtworks.paranamer:paranamer -org.scala-lang:scala-compiler -org.scala-lang:scala-library -org.scala-lang:scala-reflect -org.scala-lang.modules:scala-parser-combinators_2.12 org.fusesource.leveldbjni:leveldbjni-all net.sourceforge.f2j:arpack_combined_all xmlenc:xmlenc diff --git a/licenses-binary/LICENSE-scala.txt b/licenses-binary/LICENSE-scala.txt deleted file mode 100644 index 4846076aba2..000 --- a/licenses-binary/LICENSE-scala.txt +++ /dev/null @@ -1,30 +0,0 @@ -Copyright (c) 2002-2013 EPFL -Copyright (c) 2011-2013 Typesafe, Inc. - -All rights reserved. - -Redistribution and use in source and binary forms, with or without -modification, are permitted provided that the following conditions are met: - -- Redistributions of source code must retain the above copyright notice, - this list of conditions and the following disclaimer. - -- Redistributions in binary form must reproduce the above copyright notice, - this list of conditions and the following disclaimer in the documentation - and/or other materials provided with the distribution. - -- Neither the name of the EPFL nor the names of its contributors may be - used to endorse or promote products derived from this software without - specific prior written permission. - -THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS" -AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE -IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE -ARE DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT OWNER OR CONTRIBUTORS BE -LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR -CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF -SUBSTITUTE GOODS OR SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS -INTERRUPTION) HOWEVER CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN -CONTRACT, STRICT LIABILITY, OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) -ARISING IN ANY WAY OUT OF THE USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE -POSSIBILITY OF SUCH DAMAGE. - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated (a46abbc -> a139ede)
This is an automated email from the ASF dual-hosted git repository. srowen pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git. from a46abbc [SPARK-38756][CORE][DOCS] Clean up unused security configuration items in `TransportConf` add a139ede [SPARK-38661][TESTS][FOLLOWUP] Replace Symbol usage with $"" in unit tests No new revisions were added by this update. Summary of changes: .../apache/spark/sql/avro/AvroFunctionsSuite.scala | 42 +- .../spark/sql/avro/AvroLogicalTypeSuite.scala | 17 +- .../sql/avro/DeprecatedAvroFunctionsSuite.scala| 12 +- .../sql/kafka010/KafkaMicroBatchSourceSuite.scala | 6 +- .../apache/spark/sql/kafka010/KafkaSinkSuite.scala | 2 +- .../metrics/sink/PrometheusServletSuite.scala | 2 +- .../sql/streaming/StructuredSessionization.scala | 2 +- .../scala/org/apache/spark/ml/FunctionsSuite.scala | 6 +- .../apache/spark/sql/catalyst/dsl/package.scala| 2 +- .../sql/catalyst/analysis/AnalysisErrorSuite.scala | 10 +- .../sql/catalyst/analysis/AnalysisSuite.scala | 30 +- .../spark/sql/catalyst/analysis/DSLHintSuite.scala | 6 +- .../analysis/ExpressionTypeCheckingSuite.scala | 184 +++--- .../analysis/PullOutNondeterministicSuite.scala| 6 +- .../analysis/ResolveGroupingAnalyticsSuite.scala | 10 +- .../sql/catalyst/analysis/ResolveHintsSuite.scala | 17 +- .../analysis/ResolveLambdaVariablesSuite.scala | 16 +- .../analysis/ResolveNaturalJoinSuite.scala | 8 +- .../catalyst/analysis/ResolveSubquerySuite.scala | 34 +- .../analysis/ResolvedUuidExpressionsSuite.scala| 8 +- .../SubstituteUnresolvedOrdinalsSuite.scala| 6 +- .../catalyst/analysis/V2WriteAnalysisSuite.scala | 30 +- .../catalyst/catalog/ExternalCatalogSuite.scala| 18 +- .../catalyst/encoders/EncoderResolutionSuite.scala | 47 +- .../expressions/ArithmeticExpressionSuite.scala| 20 +- .../expressions/BitwiseExpressionsSuite.scala | 10 +- .../catalyst/expressions/CanonicalizeSuite.scala | 24 +- .../catalyst/expressions/ComplexTypeSuite.scala| 15 +- .../expressions/ConditionalExpressionSuite.scala | 30 +- .../expressions/ExpressionSQLBuilderSuite.scala| 67 +- .../expressions/MathExpressionsSuite.scala | 10 +- .../expressions/ObjectExpressionsSuite.scala | 2 +- .../expressions/RegexpExpressionsSuite.scala | 26 +- .../expressions/StringExpressionsSuite.scala | 58 +- .../aggregate/ApproximatePercentileSuite.scala | 2 +- .../aggregate/HistogramNumericSuite.scala | 12 +- .../optimizer/AggregateOptimizeSuite.scala | 45 +- .../BinaryComparisonSimplificationSuite.scala | 74 +-- .../optimizer/BooleanSimplificationSuite.scala | 210 +++--- .../optimizer/CheckCartesianProductsSuite.scala| 8 +- .../catalyst/optimizer/CollapseProjectSuite.scala | 85 +-- .../optimizer/CollapseRepartitionSuite.scala | 49 +- .../catalyst/optimizer/CollapseWindowSuite.scala | 32 +- .../catalyst/optimizer/ColumnPruningSuite.scala| 242 +++ .../catalyst/optimizer/CombiningLimitsSuite.scala | 16 +- .../catalyst/optimizer/ConstantFoldingSuite.scala | 143 ++-- .../optimizer/ConstantPropagationSuite.scala | 10 +- .../optimizer/ConvertToLocalRelationSuite.scala| 12 +- .../optimizer/DecimalAggregatesSuite.scala | 51 +- .../optimizer/DecorrelateInnerQuerySuite.scala | 8 +- .../optimizer/EliminateAggregateFilterSuite.scala | 25 +- .../optimizer/EliminateDistinctSuite.scala | 12 +- .../optimizer/EliminateMapObjectsSuite.scala | 4 +- .../optimizer/EliminateSerializationSuite.scala| 10 +- .../EliminateSortsBeforeRepartitionSuite.scala | 86 +-- .../catalyst/optimizer/EliminateSortsSuite.scala | 192 +++--- .../optimizer/EliminateSubqueryAliasesSuite.scala | 10 +- .../ExtractPythonUDFFromJoinConditionSuite.scala | 22 +- .../optimizer/FilterPushdownOnePassSuite.scala | 84 +-- .../catalyst/optimizer/FilterPushdownSuite.scala | 716 +++-- .../optimizer/FoldablePropagationSuite.scala | 130 ++-- .../optimizer/GenerateOptimizationSuite.scala | 20 +- .../InferFiltersFromConstraintsSuite.scala | 206 +++--- .../optimizer/InferFiltersFromGenerateSuite.scala | 20 +- .../catalyst/optimizer/JoinOptimizationSuite.scala | 16 +- .../optimizer/JoinSelectionHelperSuite.scala | 4 +- .../optimizer/LeftSemiAntiJoinPushDownSuite.scala | 208 +++--- .../optimizer/LikeSimplificationSuite.scala| 92 +-- .../catalyst/optimizer/LimitPushdownSuite.scala| 24 +- .../optimizer/NestedColumnAliasingSuite.scala | 223 +++ .../NormalizeFloatingPointNumbersSuite.scala | 4 +- .../optimizer/NullDownPropagationSuite.scala | 12 +- .../optimizer/ObjectSerializerPruningSuite.scala | 9 +- .../catalyst
[spark] branch master updated: [SPARK-38756][CORE][DOCS] Clean up unused security configuration items in `TransportConf`
This is an automated email from the ASF dual-hosted git repository.
srowen pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new a46abbc [SPARK-38756][CORE][DOCS] Clean up unused security
configuration items in `TransportConf`
a46abbc is described below
commit a46abbc18d1874148f97b3035c553ffee8494811
Author: yangjie01
AuthorDate: Sat Apr 2 11:40:39 2022 -0500
[SPARK-38756][CORE][DOCS] Clean up unused security configuration items in
`TransportConf`
### What changes were proposed in this pull request?
There are some configuration items in `TransportConf` already unused after
[Update Spark key negotiation
protocol](https://github.com/apache/spark/commit/3b0dd14f1c5dd033ad0a6295baa288eda9dfe10a)
- `spark.network.crypto.keyFactoryAlgorithm`
- `spark.network.crypto.keyLength`
- `spark.network.crypto.ivLength`
- `spark.network.crypto.keyAlgorithm`
so this pr clean up these configuration items from `TransportConf`, `
security.md` and relevant UT `AuthEngineSuite`
### Why are the changes needed?
Clean up unused security configuration items.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Pass GA
Closes #36035 from LuciferYang/unused-security-config.
Authored-by: yangjie01
Signed-off-by: Sean Owen
---
.../apache/spark/network/util/TransportConf.java | 41 --
.../spark/network/crypto/AuthEngineSuite.java | 15
docs/security.md | 17 -
3 files changed, 73 deletions(-)
diff --git
a/common/network-common/src/main/java/org/apache/spark/network/util/TransportConf.java
b/common/network-common/src/main/java/org/apache/spark/network/util/TransportConf.java
index f73e3ce..57bd494 100644
---
a/common/network-common/src/main/java/org/apache/spark/network/util/TransportConf.java
+++
b/common/network-common/src/main/java/org/apache/spark/network/util/TransportConf.java
@@ -220,47 +220,6 @@ public class TransportConf {
}
/**
- * The key generation algorithm. This should be an algorithm that accepts a
"PBEKeySpec"
- * as input. The default value (PBKDF2WithHmacSHA1) is available in Java 7.
- */
- public String keyFactoryAlgorithm() {
-return conf.get("spark.network.crypto.keyFactoryAlgorithm",
"PBKDF2WithHmacSHA1");
- }
-
- /**
- * How many iterations to run when generating keys.
- *
- * See some discussion about this at:
http://security.stackexchange.com/q/3959
- * The default value was picked for speed, since it assumes that the secret
has good entropy
- * (128 bits by default), which is not generally the case with user
passwords.
- */
- public int keyFactoryIterations() {
-return conf.getInt("spark.network.crypto.keyFactoryIterations", 1024);
- }
-
- /**
- * Encryption key length, in bits.
- */
- public int encryptionKeyLength() {
-return conf.getInt("spark.network.crypto.keyLength", 128);
- }
-
- /**
- * Initial vector length, in bytes.
- */
- public int ivLength() {
-return conf.getInt("spark.network.crypto.ivLength", 16);
- }
-
- /**
- * The algorithm for generated secret keys. Nobody should really need to
change this,
- * but configurable just in case.
- */
- public String keyAlgorithm() {
-return conf.get("spark.network.crypto.keyAlgorithm", "AES");
- }
-
- /**
* Whether to fall back to SASL if the new auth protocol fails. Enabled by
default for
* backwards compatibility.
*/
diff --git
a/common/network-common/src/test/java/org/apache/spark/network/crypto/AuthEngineSuite.java
b/common/network-common/src/test/java/org/apache/spark/network/crypto/AuthEngineSuite.java
index 33a8ce2..22dbdc7 100644
---
a/common/network-common/src/test/java/org/apache/spark/network/crypto/AuthEngineSuite.java
+++
b/common/network-common/src/test/java/org/apache/spark/network/crypto/AuthEngineSuite.java
@@ -20,10 +20,8 @@ package org.apache.spark.network.crypto;
import java.nio.ByteBuffer;
import java.nio.channels.WritableByteChannel;
import java.security.GeneralSecurityException;
-import java.util.Map;
import java.util.Random;
-import com.google.common.collect.ImmutableMap;
import com.google.crypto.tink.subtle.Hex;
import io.netty.buffer.ByteBuf;
import io.netty.buffer.Unpooled;
@@ -188,19 +186,6 @@ public class AuthEngineSuite {
}
}
- @Test(expected = AssertionError.class)
- public void testBadKeySize() throws Exception {
-Map mconf =
ImmutableMap.of("spark.network.crypto.keyLength", "42");
-TransportConf conf = new TransportConf("rpc", new
MapConfigProvider(mconf));
-
-try (AuthEngine engine = new AuthEngine("appId", "secr
[spark] branch master updated (af942d7 -> 6522141)
This is an automated email from the ASF dual-hosted git repository. srowen pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git. from af942d7 [SPARK-38669][ML] Validate input dataset of ml.clustering and ml.recommendation add 6522141 [SPARK-38561][K8S][DOCS][FOLLOWUP] Add note for specific scheduler configuration and fix typos No new revisions were added by this update. Summary of changes: docs/running-on-kubernetes.md | 4 ++-- 1 file changed, 2 insertions(+), 2 deletions(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated (7b3f544 -> af942d7)
This is an automated email from the ASF dual-hosted git repository. srowen pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git. from 7b3f544 [SPARK-38757][BUILD][TEST] Update oracle-xe version from 18.4.0 to 21.3.0 add af942d7 [SPARK-38669][ML] Validate input dataset of ml.clustering and ml.recommendation No new revisions were added by this update. Summary of changes: .../spark/ml/clustering/BisectingKMeans.scala | 20 ++-- .../spark/ml/clustering/GaussianMixture.scala | 20 ++-- .../org/apache/spark/ml/clustering/KMeans.scala| 18 ++- .../scala/org/apache/spark/ml/clustering/LDA.scala | 15 ++- .../ml/clustering/PowerIterationClustering.scala | 28 ++--- .../org/apache/spark/ml/recommendation/ALS.scala | 57 + .../org/apache/spark/ml/util/DatasetUtils.scala| 15 ++- .../spark/ml/clustering/BisectingKMeansSuite.scala | 5 + .../spark/ml/clustering/GaussianMixtureSuite.scala | 5 + .../apache/spark/ml/clustering/KMeansSuite.scala | 5 + .../org/apache/spark/ml/clustering/LDASuite.scala | 4 + .../clustering/PowerIterationClusteringSuite.scala | 8 +- .../apache/spark/ml/recommendation/ALSSuite.scala | 130 ++--- project/MimaExcludes.scala | 2 + 14 files changed, 200 insertions(+), 132 deletions(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated (2f8613f -> 0b6ea01)
This is an automated email from the ASF dual-hosted git repository. srowen pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git. from 2f8613f [SPARK-38684][SS] Fix correctness issue on stream-stream outer join with RocksDB state store provider add 0b6ea01 [SPARK-38620][WEBUI] Replace `value.formatted(formatString)` with `formatString.format(value)` to clean up compilation warning No new revisions were added by this update. Summary of changes: .../scala/org/apache/spark/sql/streaming/ui/StreamingQueryPage.scala | 4 ++-- .../src/main/scala/org/apache/spark/streaming/ui/StreamingPage.scala | 2 +- 2 files changed, 3 insertions(+), 3 deletions(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated: [SPARK-38694][TESTS] Simplify Java UT code with Junit `assertThrows` Api
This is an automated email from the ASF dual-hosted git repository.
srowen pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new ef8fb9b [SPARK-38694][TESTS] Simplify Java UT code with Junit
`assertThrows` Api
ef8fb9b is described below
commit ef8fb9b9d84b6adfe5a4e03b6e775e709d624144
Author: yangjie01
AuthorDate: Wed Mar 30 18:32:37 2022 -0500
[SPARK-38694][TESTS] Simplify Java UT code with Junit `assertThrows` Api
### What changes were proposed in this pull request?
There are some code patterns in Spark Java UTs:
```java
Test
public void testAuthReplay() throws Exception {
try {
doSomeOperation();
fail("Should have failed");
} catch (Exception e) {
assertTrue(doExceptionCheck(e));
}
}
```
or
```java
Test(expected = SomeException.class)
public void testAuthReplay() throws Exception {
try {
doSomeOperation();
fail("Should have failed");
} catch (Exception e) {
assertTrue(doExceptionCheck(e));
throw e;
}
}
```
This pr use Junit `assertThrows` Api to simplify the similar patterns.
### Why are the changes needed?
Simplify code.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Pass GA
Closes #36008 from LuciferYang/SPARK-38694.
Authored-by: yangjie01
Signed-off-by: Sean Owen
---
.../spark/util/kvstore/InMemoryStoreSuite.java | 21 +-
.../apache/spark/util/kvstore/LevelDBSuite.java| 21 +-
.../apache/spark/util/kvstore/RocksDBSuite.java| 21 +-
.../spark/network/crypto/AuthIntegrationSuite.java | 39 +-
.../spark/network/crypto/TransportCipherSuite.java | 21 +-
.../apache/spark/network/sasl/SparkSaslSuite.java | 41 +-
.../server/OneForOneStreamManagerSuite.java| 23 +-
.../spark/network/sasl/SaslIntegrationSuite.java | 37 +-
.../network/shuffle/ExternalBlockHandlerSuite.java | 14 +-
.../shuffle/ExternalShuffleBlockResolverSuite.java | 17 +-
.../shuffle/ExternalShuffleSecuritySuite.java | 16 +-
.../shuffle/OneForOneBlockFetcherSuite.java| 14 +-
.../shuffle/RemoteBlockPushResolverSuite.java | 464 +
.../apache/spark/unsafe/types/UTF8StringSuite.java | 8 +-
.../apache/spark/launcher/SparkLauncherSuite.java | 15 +-
.../shuffle/sort/PackedRecordPointerSuite.java | 14 +-
.../unsafe/map/AbstractBytesToBytesMapSuite.java | 40 +-
.../java/test/org/apache/spark/JavaAPISuite.java | 16 +-
.../spark/launcher/CommandBuilderUtilsSuite.java | 7 +-
.../apache/spark/launcher/LauncherServerSuite.java | 14 +-
.../JavaRandomForestClassifierSuite.java | 8 +-
.../regression/JavaRandomForestRegressorSuite.java | 8 +-
.../spark/ml/util/JavaDefaultReadWriteSuite.java | 8 +-
.../expressions/RowBasedKeyValueBatchSuite.java| 60 +--
.../spark/sql/JavaBeanDeserializationSuite.java| 15 +-
.../spark/sql/JavaColumnExpressionSuite.java | 16 +-
26 files changed, 317 insertions(+), 661 deletions(-)
diff --git
a/common/kvstore/src/test/java/org/apache/spark/util/kvstore/InMemoryStoreSuite.java
b/common/kvstore/src/test/java/org/apache/spark/util/kvstore/InMemoryStoreSuite.java
index 198b6e8..b2acd1a 100644
---
a/common/kvstore/src/test/java/org/apache/spark/util/kvstore/InMemoryStoreSuite.java
+++
b/common/kvstore/src/test/java/org/apache/spark/util/kvstore/InMemoryStoreSuite.java
@@ -34,24 +34,14 @@ public class InMemoryStoreSuite {
t.id = "id";
t.name = "name";
-try {
- store.read(CustomType1.class, t.key);
- fail("Expected exception for non-existent object.");
-} catch (NoSuchElementException nsee) {
- // Expected.
-}
+assertThrows(NoSuchElementException.class, () ->
store.read(CustomType1.class, t.key));
store.write(t);
assertEquals(t, store.read(t.getClass(), t.key));
assertEquals(1L, store.count(t.getClass()));
store.delete(t.getClass(), t.key);
-try {
- store.read(t.getClass(), t.key);
- fail("Expected exception for deleted object.");
-} catch (NoSuchElementException nsee) {
- // Expected.
-}
+assertThrows(NoSuchElementException.class, () -> store.read(t.getClass(),
t.key));
}
@Test
@@ -78,12 +68,7 @@ public class InMemoryStoreSuite {
store.delete(t1.getClass(), t1.key);
assertEquals(t2, store.read(t2.getClass(), t2.key));
store.delete(t2.getClass(), t2.key);
-try {
- store.read(t2.getClass(), t2.key);
- fail("Expected exception for deleted object.");
-} catch (NoSuchElementException nsee) {
- // Expected.
-}
+assertThrows(NoSuchElementException.
[spark] branch branch-3.3 updated: [SPARK-37853][CORE][SQL][FOLLOWUP] Clean up log4j2 deprecation api usage
This is an automated email from the ASF dual-hosted git repository.
srowen pushed a commit to branch branch-3.3
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/branch-3.3 by this push:
new 8e52fd3 [SPARK-37853][CORE][SQL][FOLLOWUP] Clean up log4j2
deprecation api usage
8e52fd3 is described below
commit 8e52fd308430b0d723e5d04b3f88d093b02058b0
Author: yangjie01
AuthorDate: Mon Mar 28 18:23:12 2022 -0500
[SPARK-37853][CORE][SQL][FOLLOWUP] Clean up log4j2 deprecation api usage
### What changes were proposed in this pull request?
This pr just fix a previously unnoticed deprecation api usage related to
log4j2.
### Why are the changes needed?
Clean up log4j2 deprecation api usage
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Pass GA
Closes #35796 from LuciferYang/SPARK-37853-FOLLOWUP.
Authored-by: yangjie01
Signed-off-by: Sean Owen
(cherry picked from commit 84bc452bb59d2b4067b617f8dd32d35f875b1e72)
Signed-off-by: Sean Owen
---
.../test/java/org/apache/spark/launcher/ChildProcAppHandleSuite.java | 3 ++-
.../java/org/apache/hive/service/cli/operation/LogDivertAppender.java | 3 ++-
2 files changed, 4 insertions(+), 2 deletions(-)
diff --git
a/launcher/src/test/java/org/apache/spark/launcher/ChildProcAppHandleSuite.java
b/launcher/src/test/java/org/apache/spark/launcher/ChildProcAppHandleSuite.java
index b0525a6..6a0c584 100644
---
a/launcher/src/test/java/org/apache/spark/launcher/ChildProcAppHandleSuite.java
+++
b/launcher/src/test/java/org/apache/spark/launcher/ChildProcAppHandleSuite.java
@@ -28,6 +28,7 @@ import java.util.List;
import java.util.stream.Collectors;
import static java.nio.file.attribute.PosixFilePermission.*;
+import org.apache.logging.log4j.core.config.Property;
import org.apache.logging.log4j.core.config.plugins.*;
import org.apache.logging.log4j.core.Filter;
import org.apache.logging.log4j.core.Layout;
@@ -249,7 +250,7 @@ public class ChildProcAppHandleSuite extends BaseSuite {
Filter filter,
Layout layout,
boolean ignoreExceptions) {
- super(name, filter, layout, ignoreExceptions);
+ super(name, filter, layout, ignoreExceptions, Property.EMPTY_ARRAY);
}
@Override
diff --git
a/sql/hive-thriftserver/src/main/java/org/apache/hive/service/cli/operation/LogDivertAppender.java
b/sql/hive-thriftserver/src/main/java/org/apache/hive/service/cli/operation/LogDivertAppender.java
index ca0fbe7..64730f3 100644
---
a/sql/hive-thriftserver/src/main/java/org/apache/hive/service/cli/operation/LogDivertAppender.java
+++
b/sql/hive-thriftserver/src/main/java/org/apache/hive/service/cli/operation/LogDivertAppender.java
@@ -38,6 +38,7 @@ import org.apache.logging.log4j.core.appender.ConsoleAppender;
import org.apache.logging.log4j.core.appender.AbstractWriterAppender;
import org.apache.logging.log4j.core.appender.WriterManager;
import com.google.common.base.Joiner;
+import org.apache.logging.log4j.core.config.Property;
import org.apache.logging.log4j.message.Message;
/**
@@ -278,7 +279,7 @@ public class LogDivertAppender extends
AbstractWriterAppender {
public LogDivertAppender(OperationManager operationManager,
OperationLog.LoggingLevel loggingMode) {
-super("LogDivertAppender", initLayout(loggingMode), null, false, true,
+super("LogDivertAppender", initLayout(loggingMode), null, false, true,
Property.EMPTY_ARRAY,
new WriterManager(new CharArrayWriter(), "LogDivertAppender",
initLayout(loggingMode), true));
-
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated (0562cac -> 84bc452)
This is an automated email from the ASF dual-hosted git repository. srowen pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git. from 0562cac [SPARK-38673][TESTS] Replace Java assert with Junit API in Java UTs add 84bc452 [SPARK-37853][CORE][SQL][FOLLOWUP] Clean up log4j2 deprecation api usage No new revisions were added by this update. Summary of changes: .../test/java/org/apache/spark/launcher/ChildProcAppHandleSuite.java | 3 ++- .../java/org/apache/hive/service/cli/operation/LogDivertAppender.java | 3 ++- 2 files changed, 4 insertions(+), 2 deletions(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated: [SPARK-38673][TESTS] Replace Java assert with Junit API in Java UTs
This is an automated email from the ASF dual-hosted git repository.
srowen pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new 0562cac [SPARK-38673][TESTS] Replace Java assert with Junit API in
Java UTs
0562cac is described below
commit 0562cacafe8e402683de2898cec65b9327983f84
Author: yangjie01
AuthorDate: Mon Mar 28 18:21:38 2022 -0500
[SPARK-38673][TESTS] Replace Java assert with Junit API in Java UTs
### What changes were proposed in this pull request?
There are some Java UTs use java `assert` for assertion, and these
assertions will strongly depend on JVM start with `-ea` mode, so this pr
replace them with Junit API.
### Why are the changes needed?
Use Junit API in Java UTs.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Pass GA
Closes #35987 from LuciferYang/SPARK-38673.
Authored-by: yangjie01
Signed-off-by: Sean Owen
---
.../spark/util/kvstore/InMemoryStoreSuite.java | 8
.../client/TransportClientFactorySuite.java| 7 ++-
.../apache/spark/unsafe/array/ByteArraySuite.java | 8
.../spark/resource/JavaResourceProfileSuite.java | 6 +++---
.../unsafe/map/AbstractBytesToBytesMapSuite.java | 22 +++---
.../unsafe/sort/UnsafeExternalSorterSuite.java | 4 ++--
.../sql/streaming/JavaGroupStateTimeoutSuite.java | 10 ++
7 files changed, 32 insertions(+), 33 deletions(-)
diff --git
a/common/kvstore/src/test/java/org/apache/spark/util/kvstore/InMemoryStoreSuite.java
b/common/kvstore/src/test/java/org/apache/spark/util/kvstore/InMemoryStoreSuite.java
index 35656fb..198b6e8 100644
---
a/common/kvstore/src/test/java/org/apache/spark/util/kvstore/InMemoryStoreSuite.java
+++
b/common/kvstore/src/test/java/org/apache/spark/util/kvstore/InMemoryStoreSuite.java
@@ -159,25 +159,25 @@ public class InMemoryStoreSuite {
assertEquals(9, store.count(ArrayKeyIndexType.class));
// Try removing non-existing keys
-assert(!store.removeAllByIndexValues(
+assertFalse(store.removeAllByIndexValues(
ArrayKeyIndexType.class,
KVIndex.NATURAL_INDEX_NAME,
ImmutableSet.of(new int[] {10, 10, 10}, new int[] { 3, 3, 3 })));
assertEquals(9, store.count(ArrayKeyIndexType.class));
-assert(store.removeAllByIndexValues(
+assertTrue(store.removeAllByIndexValues(
ArrayKeyIndexType.class,
KVIndex.NATURAL_INDEX_NAME,
ImmutableSet.of(new int[] {0, 0, 0}, new int[] { 2, 2, 2 })));
assertEquals(7, store.count(ArrayKeyIndexType.class));
-assert(store.removeAllByIndexValues(
+assertTrue(store.removeAllByIndexValues(
ArrayKeyIndexType.class,
"id",
ImmutableSet.of(new String [] { "things" })));
assertEquals(4, store.count(ArrayKeyIndexType.class));
-assert(store.removeAllByIndexValues(
+assertTrue(store.removeAllByIndexValues(
ArrayKeyIndexType.class,
"id",
ImmutableSet.of(new String [] { "more things" })));
diff --git
a/common/network-common/src/test/java/org/apache/spark/network/client/TransportClientFactorySuite.java
b/common/network-common/src/test/java/org/apache/spark/network/client/TransportClientFactorySuite.java
index 277ff85..c542f31 100644
---
a/common/network-common/src/test/java/org/apache/spark/network/client/TransportClientFactorySuite.java
+++
b/common/network-common/src/test/java/org/apache/spark/network/client/TransportClientFactorySuite.java
@@ -231,11 +231,8 @@ public class TransportClientFactorySuite {
TransportServer server = context.createServer();
int unreachablePort = server.getPort();
server.close();
-try {
- factory.createClient(TestUtils.getLocalHost(), unreachablePort, true);
-} catch (Exception e) {
- assert(e instanceof IOException);
-}
+Assert.assertThrows(IOException.class,
+ () -> factory.createClient(TestUtils.getLocalHost(), unreachablePort,
true));
Assert.assertThrows("fail this connection directly", IOException.class,
() -> factory.createClient(TestUtils.getLocalHost(), unreachablePort,
true));
}
diff --git
a/common/unsafe/src/test/java/org/apache/spark/unsafe/array/ByteArraySuite.java
b/common/unsafe/src/test/java/org/apache/spark/unsafe/array/ByteArraySuite.java
index 67de435..71cd824 100644
---
a/common/unsafe/src/test/java/org/apache/spark/unsafe/array/ByteArraySuite.java
+++
b/common/unsafe/src/test/java/org/apache/spark/unsafe/array/ByteArraySuite.java
@@ -53,18 +53,18 @@ public class ByteArraySuite {
public void testCompareBinary() {
byte[] x1 = new byte[0];
byte[] y1 = new byte[]{(byte) 1, (byte) 2, (byte) 3};
-assert(ByteArray.compareBinary(x1, y1) < 0);
+Assert.assertTrue(ByteArray.comp
[spark] branch master updated: [SPARK-38641][BUILD] Get rid of invalid configuration elements in mvn_scalafmt in main pom.xml
This is an automated email from the ASF dual-hosted git repository.
srowen pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new de960a5 [SPARK-38641][BUILD] Get rid of invalid configuration
elements in mvn_scalafmt in main pom.xml
de960a5 is described below
commit de960a5d5f892248226a82f2f0f2adc43749db5d
Author: morvenhuang
AuthorDate: Thu Mar 24 18:24:35 2022 -0500
[SPARK-38641][BUILD] Get rid of invalid configuration elements in
mvn_scalafmt in main pom.xml
### What changes were proposed in this pull request?
In main pom.xml, for mvn_scalafmt plugin, I removed 'parameters' since it's
invalid , and replace 'skip' with 'validateOnly' since 'skip' is invalid too.
### Why are the changes needed?
I think we should not leave invalid items there in the pom.xml
I've contacted the author of mvn_scalafmt, Ciaran Kearney, to confirm if
these 2 configuration items are no longer there since v 1.0.0, and he said:
"That's correct. The command line parameters were removed by scalafmt itself a
few versions ago and skip was replaced by validateOnly (which checks formatting
without changing files."
### Does this PR introduce _any_ user-facing change?
Yes
### How was this patch tested?
Run mvn-scalafmt_2.12:format locally via mvn.
Closes #35956 from morvenhuang/SPARK-38641.
Authored-by: morvenhuang
Signed-off-by: Sean Owen
---
pom.xml | 4 +---
1 file changed, 1 insertion(+), 3 deletions(-)
diff --git a/pom.xml b/pom.xml
index aaaf91f..d3deddd 100644
--- a/pom.xml
+++ b/pom.xml
@@ -171,7 +171,6 @@
-->
4.5.6
---test
true
1.9.13
@@ -3350,8 +3349,7 @@
mvn-scalafmt_${scala.binary.version}
1.0.4
- ${scalafmt.parameters}
- ${scalafmt.skip}
+ ${scalafmt.skip}
${scalafmt.skip}
${scalafmt.skip}
dev/.scalafmt.conf
-
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated: [SPARK-38611][TESTS] Replace `intercept` with `assertThrows` in `CatalogLoadingSuite`
This is an automated email from the ASF dual-hosted git repository.
srowen pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new 39fc7ee [SPARK-38611][TESTS] Replace `intercept` with `assertThrows`
in `CatalogLoadingSuite`
39fc7ee is described below
commit 39fc7eec470122d2afc7886a63646111914ffd94
Author: yangjie01
AuthorDate: Wed Mar 23 18:01:31 2022 -0500
[SPARK-38611][TESTS] Replace `intercept` with `assertThrows` in
`CatalogLoadingSuite`
### What changes were proposed in this pull request?
The `intercept` method implemented in `CatalogLoadingSuite` has same
semantics with `Assert.assertThrows`, so this pr replaces the handwritten
implementation with the standard Junit4 Api.
### Why are the changes needed?
Use standard Junit4 Api.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Pass GA
Closes #35919 from LuciferYang/SPARK-38611.
Authored-by: yangjie01
Signed-off-by: Sean Owen
---
.../sql/connector/catalog/CatalogLoadingSuite.java | 35 ++
1 file changed, 9 insertions(+), 26 deletions(-)
diff --git
a/sql/catalyst/src/test/java/org/apache/spark/sql/connector/catalog/CatalogLoadingSuite.java
b/sql/catalyst/src/test/java/org/apache/spark/sql/connector/catalog/CatalogLoadingSuite.java
index 37f6051..369e2fc 100644
---
a/sql/catalyst/src/test/java/org/apache/spark/sql/connector/catalog/CatalogLoadingSuite.java
+++
b/sql/catalyst/src/test/java/org/apache/spark/sql/connector/catalog/CatalogLoadingSuite.java
@@ -23,8 +23,6 @@ import org.apache.spark.sql.util.CaseInsensitiveStringMap;
import org.junit.Assert;
import org.junit.Test;
-import java.util.concurrent.Callable;
-
public class CatalogLoadingSuite {
@Test
public void testLoad() throws SparkException {
@@ -66,7 +64,7 @@ public class CatalogLoadingSuite {
public void testLoadWithoutConfig() {
SQLConf conf = new SQLConf();
-SparkException exc = intercept(CatalogNotFoundException.class,
+SparkException exc = Assert.assertThrows(CatalogNotFoundException.class,
() -> Catalogs.load("missing", conf));
Assert.assertTrue("Should complain that implementation is not configured",
@@ -81,7 +79,8 @@ public class CatalogLoadingSuite {
SQLConf conf = new SQLConf();
conf.setConfString("spark.sql.catalog.missing",
"com.example.NoSuchCatalogPlugin");
-SparkException exc = intercept(SparkException.class, () ->
Catalogs.load("missing", conf));
+SparkException exc =
+ Assert.assertThrows(SparkException.class, () -> Catalogs.load("missing",
conf));
Assert.assertTrue("Should complain that the class is not found",
exc.getMessage().contains("Cannot find catalog plugin class"));
@@ -97,7 +96,8 @@ public class CatalogLoadingSuite {
String invalidClassName = InvalidCatalogPlugin.class.getCanonicalName();
conf.setConfString("spark.sql.catalog.invalid", invalidClassName);
-SparkException exc = intercept(SparkException.class, () ->
Catalogs.load("invalid", conf));
+SparkException exc =
+ Assert.assertThrows(SparkException.class, () -> Catalogs.load("invalid",
conf));
Assert.assertTrue("Should complain that class does not implement
CatalogPlugin",
exc.getMessage().contains("does not implement CatalogPlugin"));
@@ -113,7 +113,8 @@ public class CatalogLoadingSuite {
String invalidClassName =
ConstructorFailureCatalogPlugin.class.getCanonicalName();
conf.setConfString("spark.sql.catalog.invalid", invalidClassName);
-SparkException exc = intercept(SparkException.class, () ->
Catalogs.load("invalid", conf));
+SparkException exc =
+ Assert.assertThrows(SparkException.class, () -> Catalogs.load("invalid",
conf));
Assert.assertTrue("Should identify the constructor error",
exc.getMessage().contains("Failed during instantiating constructor for
catalog"));
@@ -127,7 +128,8 @@ public class CatalogLoadingSuite {
String invalidClassName =
AccessErrorCatalogPlugin.class.getCanonicalName();
conf.setConfString("spark.sql.catalog.invalid", invalidClassName);
-SparkException exc = intercept(SparkException.class, () ->
Catalogs.load("invalid", conf));
+SparkException exc =
+ Assert.assertThrows(SparkException.class, () -> Catalogs.load("invalid",
conf));
Assert.assertTrue("Should complain that no public constructor is provided",
exc.getMessage().contains("Failed to call public no-arg constructor
for catalog"));
@@ -136,25 +138,6 @@ public class CatalogLoadi
[spark] branch master updated: [SPARK-38613][CORE] Change the exception type thrown by `PushBlockStreamCallback#abortIfNecessary` from `RuntimeException` to `IllegalStateException`
This is an automated email from the ASF dual-hosted git repository.
srowen pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new 2eae3db [SPARK-38613][CORE] Change the exception type thrown by
`PushBlockStreamCallback#abortIfNecessary` from `RuntimeException` to
`IllegalStateException`
2eae3db is described below
commit 2eae3dbdab0dbdea09928ab0252f0dfa13a94259
Author: yangjie01
AuthorDate: Wed Mar 23 09:59:02 2022 -0500
[SPARK-38613][CORE] Change the exception type thrown by
`PushBlockStreamCallback#abortIfNecessary` from `RuntimeException` to
`IllegalStateException`
### What changes were proposed in this pull request?
This pr change the exception type thrown by
`PushBlockStreamCallback#abortIfNecessary` from `RuntimeException` to
`IllegalStateException` and fixed the corresponding test case.
In addition, this PR fixes the bug of
`testWritingPendingBufsIsAbortedImmediatelyDuringComplete` in
`RemoteBlockPushResolverSuite`. `RuntimeException` throw by
https://github.com/apache/spark/blob/acb50d95a4952dea1cbbc27d4ddcc0b3432a13cf/common/network-shuffle/src/test/java/org/apache/spark/network/shuffle/RemoteBlockPushResolverSuite.java#L818-L820
before this pr, but the test case expects it to be thrown by
https://github.com/apache/spark/blob/2ca5d1857a551ca4b11bdf8166beb0861cf4e3b6/common/network-shuffle/src/test/java/org/apache/spark/network/shuffle/RemoteBlockPushResolverSuite.java#L834-L840
### Why are the changes needed?
The `RuntimeException` is too broad, it should be specific.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Pass GA and fix related UTs
Closes #35923 from LuciferYang/SPARK-38613.
Authored-by: yangjie01
Signed-off-by: Sean Owen
---
.../spark/network/shuffle/RemoteBlockPushResolver.java | 4 ++--
.../network/shuffle/RemoteBlockPushResolverSuite.java | 14 +++---
2 files changed, 9 insertions(+), 9 deletions(-)
diff --git
a/common/network-shuffle/src/main/java/org/apache/spark/network/shuffle/RemoteBlockPushResolver.java
b/common/network-shuffle/src/main/java/org/apache/spark/network/shuffle/RemoteBlockPushResolver.java
index 62ab340..626a725 100644
---
a/common/network-shuffle/src/main/java/org/apache/spark/network/shuffle/RemoteBlockPushResolver.java
+++
b/common/network-shuffle/src/main/java/org/apache/spark/network/shuffle/RemoteBlockPushResolver.java
@@ -756,12 +756,12 @@ public class RemoteBlockPushResolver implements
MergedShuffleFileManager {
}
/**
- * This throws RuntimeException if the number of IOExceptions have
exceeded threshold.
+ * @throws IllegalStateException if the number of IOExceptions have
exceeded threshold.
*/
private void abortIfNecessary() {
if
(partitionInfo.shouldAbort(mergeManager.ioExceptionsThresholdDuringMerge)) {
deferredBufs = null;
-throw new RuntimeException(String.format("%s when merging %s",
+throw new IllegalStateException(String.format("%s when merging %s",
ErrorHandler.BlockPushErrorHandler.IOEXCEPTIONS_EXCEEDED_THRESHOLD_PREFIX,
streamId));
}
diff --git
a/common/network-shuffle/src/test/java/org/apache/spark/network/shuffle/RemoteBlockPushResolverSuite.java
b/common/network-shuffle/src/test/java/org/apache/spark/network/shuffle/RemoteBlockPushResolverSuite.java
index 603b20c..f76afae 100644
---
a/common/network-shuffle/src/test/java/org/apache/spark/network/shuffle/RemoteBlockPushResolverSuite.java
+++
b/common/network-shuffle/src/test/java/org/apache/spark/network/shuffle/RemoteBlockPushResolverSuite.java
@@ -673,7 +673,7 @@ public class RemoteBlockPushResolverSuite {
validateChunks(TEST_APP, 0, 0, 0, blockMeta, new int[] {4, 5}, new int[][]
{{0}, {1}});
}
- @Test(expected = RuntimeException.class)
+ @Test(expected = IllegalStateException.class)
public void testIOExceptionsExceededThreshold() throws IOException {
RemoteBlockPushResolver.PushBlockStreamCallback callback =
(RemoteBlockPushResolver.PushBlockStreamCallback)
pushResolver.receiveBlockDataAsStream(
@@ -708,7 +708,7 @@ public class RemoteBlockPushResolverSuite {
}
}
- @Test(expected = RuntimeException.class)
+ @Test(expected = IllegalStateException.class)
public void testIOExceptionsDuringMetaUpdateIncreasesExceptionCount() throws
IOException {
useTestFiles(true, false);
RemoteBlockPushResolver.PushBlockStreamCallback callback =
@@ -743,7 +743,7 @@ public class RemoteBlockPushResolverSuite {
}
}
- @Test(expected = RuntimeException.class)
+ @Test(expected = IllegalStateException.class)
public void testRequestForAbortedShufflePartitionThrowsEx
[spark] branch master updated (c5ebdc6 -> 71f1083)
This is an automated email from the ASF dual-hosted git repository. srowen pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git. from c5ebdc6 [SPARK-18621][PYTHON] Make sql type reprs eval-able add 71f1083 [SPARK-38635][YARN] Remove duplicate log No new revisions were added by this update. Summary of changes: .../src/main/scala/org/apache/spark/deploy/yarn/ApplicationMaster.scala | 2 +- 1 file changed, 1 insertion(+), 1 deletion(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch branch-3.3 updated: [SPARK-18621][PYTHON] Make sql type reprs eval-able
This is an automated email from the ASF dual-hosted git repository.
srowen pushed a commit to branch branch-3.3
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/branch-3.3 by this push:
new eb5d8fa [SPARK-18621][PYTHON] Make sql type reprs eval-able
eb5d8fa is described below
commit eb5d8fab5a575ce54e43926e1fa3ec31080934f0
Author: flynn
AuthorDate: Wed Mar 23 08:59:30 2022 -0500
[SPARK-18621][PYTHON] Make sql type reprs eval-able
### What changes were proposed in this pull request?
These changes update the `__repr__` methods of type classes in
`pyspark.sql.types` to print string representations which are `eval`-able. In
other words, any instance of a `DataType` will produce a repr which can be
passed to `eval()` to create an identical instance.
Similar changes previously submitted:
https://github.com/apache/spark/pull/25495
### Why are the changes needed?
This [bug](https://issues.apache.org/jira/browse/SPARK-18621) has been
around for a while. The current implementation returns a string representation
which is valid in scala rather than python. These changes fix the repr to be
valid with python.
The [motivation](https://docs.python.org/3/library/functions.html#repr) is
"to return a string that would yield an object with the same value when passed
to eval()".
### Does this PR introduce _any_ user-facing change?
Example:
Current implementation:
```python
from pyspark.sql.types import *
struct = StructType([StructField('f1', StringType(), True)])
repr(struct)
# StructType(List(StructField(f1,StringType,true)))
new_struct = eval(repr(struct))
# Traceback (most recent call last):
# File "", line 1, in
# File "", line 1, in
# NameError: name 'List' is not defined
struct_field = StructField('f1', StringType(), True)
repr(struct_field)
# StructField(f1,StringType,true)
new_struct_field = eval(repr(struct_field))
# Traceback (most recent call last):
# File "", line 1, in
# File "", line 1, in
# NameError: name 'f1' is not defined
```
With changes:
```python
from pyspark.sql.types import *
struct = StructType([StructField('f1', StringType(), True)])
repr(struct)
# StructType([StructField('f1', StringType(), True)])
new_struct = eval(repr(struct))
struct == new_struct
# True
struct_field = StructField('f1', StringType(), True)
repr(struct_field)
# StructField('f1', StringType(), True)
new_struct_field = eval(repr(struct_field))
struct_field == new_struct_field
# True
```
### How was this patch tested?
The changes include a test which asserts that an instance of each type is
equal to the `eval` of its `repr`, as in the above example.
Closes #34320 from crflynn/sql-types-repr.
Lead-authored-by: flynn
Co-authored-by: Flynn
Signed-off-by: Sean Owen
(cherry picked from commit c5ebdc6ded0479f557541a08b1312097a9c4244f)
Signed-off-by: Sean Owen
---
.../source/migration_guide/pyspark_3.2_to_3.3.rst | 1 +
python/pyspark/ml/functions.py | 8 +--
python/pyspark/pandas/extensions.py| 8 +--
python/pyspark/pandas/internal.py | 78 --
python/pyspark/pandas/spark/utils.py | 23 ---
python/pyspark/pandas/tests/test_groupby.py| 2 +-
python/pyspark/pandas/tests/test_series.py | 2 +-
python/pyspark/pandas/typedef/typehints.py | 52 +++
python/pyspark/sql/dataframe.py| 3 +-
python/pyspark/sql/tests/test_dataframe.py | 2 +-
python/pyspark/sql/tests/test_types.py | 23 +++
python/pyspark/sql/types.py| 32 -
12 files changed, 135 insertions(+), 99 deletions(-)
diff --git a/python/docs/source/migration_guide/pyspark_3.2_to_3.3.rst
b/python/docs/source/migration_guide/pyspark_3.2_to_3.3.rst
index f2701d4..d81008d 100644
--- a/python/docs/source/migration_guide/pyspark_3.2_to_3.3.rst
+++ b/python/docs/source/migration_guide/pyspark_3.2_to_3.3.rst
@@ -23,3 +23,4 @@ Upgrading from PySpark 3.2 to 3.3
* In Spark 3.3, the ``pyspark.pandas.sql`` method follows [the standard Python
string
formatter](https://docs.python.org/3/library/string.html#format-string-syntax).
To restore the previous behavior, set ``PYSPARK_PANDAS_SQL_LEGACY`` environment
variable to ``1``.
* In Spark 3.3, the ``drop`` method of pandas API on Spark DataFrame supports
dropping rows by ``index``, and sets dropping by index instead of column by
default.
* In Spark 3.3, PySpark upgrades Pandas version, the new minimum required
version changes from 0.23.2 to 1.0.5.
+* In Spark 3.3, the ``repr`` return v
[spark] branch master updated: [SPARK-18621][PYTHON] Make sql type reprs eval-able
This is an automated email from the ASF dual-hosted git repository.
srowen pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new c5ebdc6 [SPARK-18621][PYTHON] Make sql type reprs eval-able
c5ebdc6 is described below
commit c5ebdc6ded0479f557541a08b1312097a9c4244f
Author: flynn
AuthorDate: Wed Mar 23 08:59:30 2022 -0500
[SPARK-18621][PYTHON] Make sql type reprs eval-able
### What changes were proposed in this pull request?
These changes update the `__repr__` methods of type classes in
`pyspark.sql.types` to print string representations which are `eval`-able. In
other words, any instance of a `DataType` will produce a repr which can be
passed to `eval()` to create an identical instance.
Similar changes previously submitted:
https://github.com/apache/spark/pull/25495
### Why are the changes needed?
This [bug](https://issues.apache.org/jira/browse/SPARK-18621) has been
around for a while. The current implementation returns a string representation
which is valid in scala rather than python. These changes fix the repr to be
valid with python.
The [motivation](https://docs.python.org/3/library/functions.html#repr) is
"to return a string that would yield an object with the same value when passed
to eval()".
### Does this PR introduce _any_ user-facing change?
Example:
Current implementation:
```python
from pyspark.sql.types import *
struct = StructType([StructField('f1', StringType(), True)])
repr(struct)
# StructType(List(StructField(f1,StringType,true)))
new_struct = eval(repr(struct))
# Traceback (most recent call last):
# File "", line 1, in
# File "", line 1, in
# NameError: name 'List' is not defined
struct_field = StructField('f1', StringType(), True)
repr(struct_field)
# StructField(f1,StringType,true)
new_struct_field = eval(repr(struct_field))
# Traceback (most recent call last):
# File "", line 1, in
# File "", line 1, in
# NameError: name 'f1' is not defined
```
With changes:
```python
from pyspark.sql.types import *
struct = StructType([StructField('f1', StringType(), True)])
repr(struct)
# StructType([StructField('f1', StringType(), True)])
new_struct = eval(repr(struct))
struct == new_struct
# True
struct_field = StructField('f1', StringType(), True)
repr(struct_field)
# StructField('f1', StringType(), True)
new_struct_field = eval(repr(struct_field))
struct_field == new_struct_field
# True
```
### How was this patch tested?
The changes include a test which asserts that an instance of each type is
equal to the `eval` of its `repr`, as in the above example.
Closes #34320 from crflynn/sql-types-repr.
Lead-authored-by: flynn
Co-authored-by: Flynn
Signed-off-by: Sean Owen
---
.../source/migration_guide/pyspark_3.2_to_3.3.rst | 1 +
python/pyspark/ml/functions.py | 8 +--
python/pyspark/pandas/extensions.py| 8 +--
python/pyspark/pandas/internal.py | 78 --
python/pyspark/pandas/spark/utils.py | 23 ---
python/pyspark/pandas/tests/test_groupby.py| 2 +-
python/pyspark/pandas/tests/test_series.py | 2 +-
python/pyspark/pandas/typedef/typehints.py | 52 +++
python/pyspark/sql/dataframe.py| 3 +-
python/pyspark/sql/tests/test_dataframe.py | 2 +-
python/pyspark/sql/tests/test_types.py | 23 +++
python/pyspark/sql/types.py| 32 -
12 files changed, 135 insertions(+), 99 deletions(-)
diff --git a/python/docs/source/migration_guide/pyspark_3.2_to_3.3.rst
b/python/docs/source/migration_guide/pyspark_3.2_to_3.3.rst
index f2701d4..d81008d 100644
--- a/python/docs/source/migration_guide/pyspark_3.2_to_3.3.rst
+++ b/python/docs/source/migration_guide/pyspark_3.2_to_3.3.rst
@@ -23,3 +23,4 @@ Upgrading from PySpark 3.2 to 3.3
* In Spark 3.3, the ``pyspark.pandas.sql`` method follows [the standard Python
string
formatter](https://docs.python.org/3/library/string.html#format-string-syntax).
To restore the previous behavior, set ``PYSPARK_PANDAS_SQL_LEGACY`` environment
variable to ``1``.
* In Spark 3.3, the ``drop`` method of pandas API on Spark DataFrame supports
dropping rows by ``index``, and sets dropping by index instead of column by
default.
* In Spark 3.3, PySpark upgrades Pandas version, the new minimum required
version changes from 0.23.2 to 1.0.5.
+* In Spark 3.3, the ``repr`` return values of SQL DataTypes have been changed
to yield an object with the same value when passed to ``eval``.
di
[spark] branch branch-3.3 updated: [SPARK-38194][FOLLOWUP] Update executor config description for memoryOverheadFactor
This is an automated email from the ASF dual-hosted git repository.
srowen pushed a commit to branch branch-3.3
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/branch-3.3 by this push:
new 4bb2967 [SPARK-38194][FOLLOWUP] Update executor config description
for memoryOverheadFactor
4bb2967 is described below
commit 4bb2967ea321dd656a28ec685fecc2f97391968e
Author: Adam Binford
AuthorDate: Tue Mar 22 18:10:41 2022 -0500
[SPARK-38194][FOLLOWUP] Update executor config description for
memoryOverheadFactor
Follow up for
https://github.com/apache/spark/pull/35912#pullrequestreview-915755215, update
the executor memoryOverheadFactor to mention the 0.4 default for non-jvm jobs
as well.
### What changes were proposed in this pull request?
Doc update
### Why are the changes needed?
To clarify new configs
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Existing UTs
Closes #35934 from Kimahriman/memory-overhead-executor-docs.
Authored-by: Adam Binford
Signed-off-by: Sean Owen
(cherry picked from commit 768ab55e00cb0ec639db1444250ef40471c4a417)
Signed-off-by: Sean Owen
---
core/src/main/scala/org/apache/spark/internal/config/package.scala | 6 +-
docs/configuration.md | 4
docs/running-on-kubernetes.md | 2 +-
3 files changed, 10 insertions(+), 2 deletions(-)
diff --git a/core/src/main/scala/org/apache/spark/internal/config/package.scala
b/core/src/main/scala/org/apache/spark/internal/config/package.scala
index ffe4501..fa048f5 100644
--- a/core/src/main/scala/org/apache/spark/internal/config/package.scala
+++ b/core/src/main/scala/org/apache/spark/internal/config/package.scala
@@ -336,7 +336,11 @@ package object config {
.doc("Fraction of executor memory to be allocated as additional non-heap
memory per " +
"executor process. This is memory that accounts for things like VM
overheads, " +
"interned strings, other native overheads, etc. This tends to grow
with the container " +
-"size. This value is ignored if spark.executor.memoryOverhead is set
directly.")
+"size. This value defaults to 0.10 except for Kubernetes non-JVM jobs,
which defaults " +
+"to 0.40. This is done as non-JVM tasks need more non-JVM heap space
and such tasks " +
+"commonly fail with \"Memory Overhead Exceeded\" errors. This preempts
this error " +
+"with a higher default. This value is ignored if
spark.executor.memoryOverhead is set " +
+"directly.")
.version("3.3.0")
.doubleConf
.checkValue(factor => factor > 0,
diff --git a/docs/configuration.md b/docs/configuration.md
index a2e6797..a2cf233 100644
--- a/docs/configuration.md
+++ b/docs/configuration.md
@@ -309,6 +309,10 @@ of the most common options to set are:
Fraction of executor memory to be allocated as additional non-heap memory
per executor process.
This is memory that accounts for things like VM overheads, interned
strings,
other native overheads, etc. This tends to grow with the container size.
+This value defaults to 0.10 except for Kubernetes non-JVM jobs, which
defaults to
+0.40. This is done as non-JVM tasks need more non-JVM heap space and such
tasks
+commonly fail with "Memory Overhead Exceeded" errors. This preempts this
error
+with a higher default.
This value is ignored if spark.executor.memoryOverhead is set
directly.
3.3.0
diff --git a/docs/running-on-kubernetes.md b/docs/running-on-kubernetes.md
index de37e22..6fec9ba 100644
--- a/docs/running-on-kubernetes.md
+++ b/docs/running-on-kubernetes.md
@@ -359,7 +359,7 @@ If no volume is set as local storage, Spark uses temporary
scratch space to spil
`emptyDir` volumes use the nodes backing storage for ephemeral storage by
default, this behaviour may not be appropriate for some compute environments.
For example if you have diskless nodes with remote storage mounted over a
network, having lots of executors doing IO to this remote storage may actually
degrade performance.
-In this case it may be desirable to set
`spark.kubernetes.local.dirs.tmpfs=true` in your configuration which will cause
the `emptyDir` volumes to be configured as `tmpfs` i.e. RAM backed volumes.
When configured like this Spark's local storage usage will count towards your
pods memory usage therefore you may wish to increase your memory requests by
increasing the value of `spark.kubernetes.memoryOverheadFactor` as appropriate.
+In this case it may be desirable to set
`spark.kubernetes.local.dirs.tmpfs=true` in your configuration which will cause
the `
[spark] branch master updated (7373cd2 -> 768ab55)
This is an automated email from the ASF dual-hosted git repository. srowen pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git. from 7373cd2 [SPARK-38619][TESTS] Clean up Junit api usage in scalatest add 768ab55 [SPARK-38194][FOLLOWUP] Update executor config description for memoryOverheadFactor No new revisions were added by this update. Summary of changes: core/src/main/scala/org/apache/spark/internal/config/package.scala | 6 +- docs/configuration.md | 4 docs/running-on-kubernetes.md | 2 +- 3 files changed, 10 insertions(+), 2 deletions(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated: [SPARK-38619][TESTS] Clean up Junit api usage in scalatest
This is an automated email from the ASF dual-hosted git repository.
srowen pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new 7373cd2 [SPARK-38619][TESTS] Clean up Junit api usage in scalatest
7373cd2 is described below
commit 7373cd22210ab9ef865740059ba265f781978469
Author: yangjie01
AuthorDate: Tue Mar 22 18:09:40 2022 -0500
[SPARK-38619][TESTS] Clean up Junit api usage in scalatest
### What changes were proposed in this pull request?
This pr clean up Junit api usage in scalatest and replace them with native
scalatest api.
### Why are the changes needed?
Use scalatest api in scalatest and Junit api in Java test
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Pass GA
Closes #35929 from LuciferYang/remove-junit-in-scalatest.
Authored-by: yangjie01
Signed-off-by: Sean Owen
---
.../scala/org/apache/spark/SparkContextSuite.scala | 11 ++--
.../spark/api/python/PythonHadoopUtilSuite.scala | 9 ++-
.../spark/storage/BlockManagerMasterSuite.scala| 6 +-
.../cluster/k8s/ExecutorRollPluginSuite.scala | 71 +++---
.../scala/org/apache/spark/sql/QueryTest.scala | 3 +-
5 files changed, 46 insertions(+), 54 deletions(-)
diff --git a/core/src/test/scala/org/apache/spark/SparkContextSuite.scala
b/core/src/test/scala/org/apache/spark/SparkContextSuite.scala
index 411a3b1..8671180 100644
--- a/core/src/test/scala/org/apache/spark/SparkContextSuite.scala
+++ b/core/src/test/scala/org/apache/spark/SparkContextSuite.scala
@@ -33,7 +33,6 @@ import org.apache.hadoop.mapred.TextInputFormat
import org.apache.hadoop.mapreduce.lib.input.{TextInputFormat =>
NewTextInputFormat}
import org.apache.logging.log4j.{Level, LogManager}
import org.json4s.{DefaultFormats, Extraction}
-import org.junit.Assert.{assertEquals, assertFalse}
import org.scalatest.concurrent.Eventually
import org.scalatest.matchers.must.Matchers._
@@ -1257,12 +1256,12 @@ class SparkContextSuite extends SparkFunSuite with
LocalSparkContext with Eventu
test("SPARK-35383: Fill missing S3A magic committer configs if needed") {
val c1 = new SparkConf().setAppName("s3a-test").setMaster("local")
sc = new SparkContext(c1)
-assertFalse(sc.getConf.contains("spark.hadoop.fs.s3a.committer.name"))
+assert(!sc.getConf.contains("spark.hadoop.fs.s3a.committer.name"))
resetSparkContext()
val c2 =
c1.clone.set("spark.hadoop.fs.s3a.bucket.mybucket.committer.magic.enabled",
"false")
sc = new SparkContext(c2)
-assertFalse(sc.getConf.contains("spark.hadoop.fs.s3a.committer.name"))
+assert(!sc.getConf.contains("spark.hadoop.fs.s3a.committer.name"))
resetSparkContext()
val c3 =
c1.clone.set("spark.hadoop.fs.s3a.bucket.mybucket.committer.magic.enabled",
"true")
@@ -1277,7 +1276,7 @@ class SparkContextSuite extends SparkFunSuite with
LocalSparkContext with Eventu
"spark.sql.sources.commitProtocolClass" ->
"org.apache.spark.internal.io.cloud.PathOutputCommitProtocol"
).foreach { case (k, v) =>
- assertEquals(v, sc.getConf.get(k))
+ assert(v == sc.getConf.get(k))
}
// Respect a user configuration
@@ -1294,9 +1293,9 @@ class SparkContextSuite extends SparkFunSuite with
LocalSparkContext with Eventu
"spark.sql.sources.commitProtocolClass" -> null
).foreach { case (k, v) =>
if (v == null) {
-assertFalse(sc.getConf.contains(k))
+assert(!sc.getConf.contains(k))
} else {
-assertEquals(v, sc.getConf.get(k))
+assert(v == sc.getConf.get(k))
}
}
}
diff --git
a/core/src/test/scala/org/apache/spark/api/python/PythonHadoopUtilSuite.scala
b/core/src/test/scala/org/apache/spark/api/python/PythonHadoopUtilSuite.scala
index 039d49d..b4f7f1d 100644
---
a/core/src/test/scala/org/apache/spark/api/python/PythonHadoopUtilSuite.scala
+++
b/core/src/test/scala/org/apache/spark/api/python/PythonHadoopUtilSuite.scala
@@ -21,7 +21,6 @@ import java.util.HashMap
import org.apache.hadoop.io.{BooleanWritable, BytesWritable, ByteWritable,
DoubleWritable, FloatWritable, IntWritable, LongWritable,
MapWritable, NullWritable, ShortWritable, Text, Writable}
-import org.junit.Assert
import org.mockito.Mockito.mock
import org.apache.spark.SparkFunSuite
@@ -34,13 +33,13 @@ class PythonHadoopUtilSuite extends SparkFunSuite {
val writableToJavaConverter = new WritableToJavaConverter(broadcast)
val result = writableToJavaConverter.convert(input)
expected match {
- case _: Array[Byte] => Assert.assertArrayEquals(
-expected.asInstanceOf[Array[Byte]],
[spark] branch branch-3.2 updated: [SPARK-38606][DOC] Update document to make a good guide of multiple versions of the Spark Shuffle Service
This is an automated email from the ASF dual-hosted git repository. srowen pushed a commit to branch branch-3.2 in repository https://gitbox.apache.org/repos/asf/spark.git The following commit(s) were added to refs/heads/branch-3.2 by this push: new e78038b [SPARK-38606][DOC] Update document to make a good guide of multiple versions of the Spark Shuffle Service e78038b is described below commit e78038b1b1b9f8de75c6cf5df6613cb5fe8ac9cf Author: zhangxudong1 AuthorDate: Mon Mar 21 13:48:20 2022 -0500 [SPARK-38606][DOC] Update document to make a good guide of multiple versions of the Spark Shuffle Service ### What changes were proposed in this pull request? Update document "Running multiple versions of the Spark Shuffle Service" to use colon when writing %s.classpath instead of commas. ### Why are the changes needed? User may be confused when they following the current document to deploy multi-versions Spark Shuffle Service on YARN. We have tried to run multiple versions of the Spark Shuffle Service according https://github.com/apache/spark/blob/master/docs/running-on-yarn.md but, it wont work. Then we solved it by using colon when writing %s.classpath instead of commas. Related discussing is in https://issues.apache.org/jira/browse/YARN-4577?focusedCommentId=17493624=com.atlassian.jira.plugin.system.issuetabpanels%3Acomment-tabpanel#comment-17493624 ### Does this PR introduce _any_ user-facing change? User document changes. ### How was this patch tested? 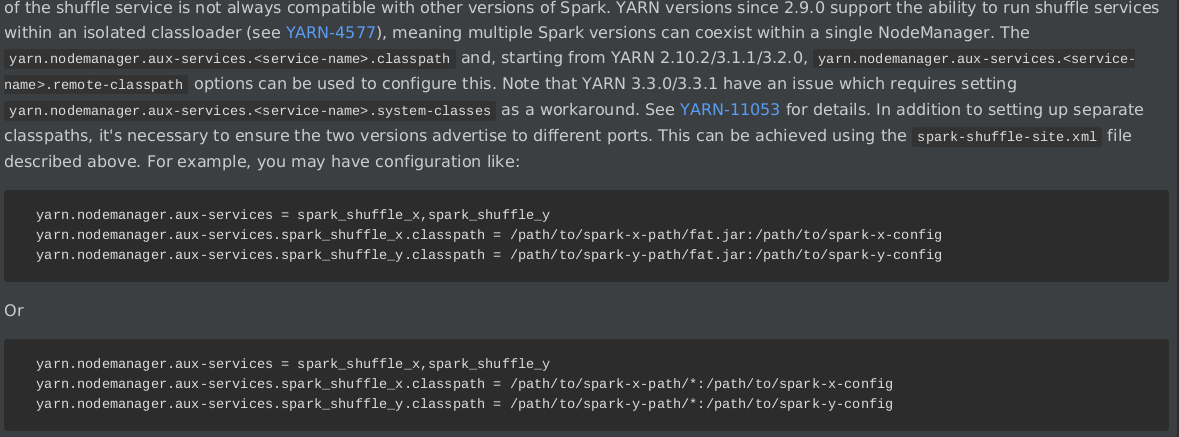 Closes #35914 from TonyDoen/SPARK-38606. Authored-by: zhangxudong1 Signed-off-by: Sean Owen (cherry picked from commit a876f005ecef77d94bb8048fa1ff0841b7f3607a) Signed-off-by: Sean Owen --- docs/running-on-yarn.md | 10 -- 1 file changed, 8 insertions(+), 2 deletions(-) diff --git a/docs/running-on-yarn.md b/docs/running-on-yarn.md index 4a1dddf..77d0ed0 100644 --- a/docs/running-on-yarn.md +++ b/docs/running-on-yarn.md @@ -888,8 +888,14 @@ above. For example, you may have configuration like: ```properties yarn.nodemanager.aux-services = spark_shuffle_x,spark_shuffle_y - yarn.nodemanager.aux-services.spark_shuffle_x.classpath = /path/to/spark-x-yarn-shuffle.jar,/path/to/spark-x-config - yarn.nodemanager.aux-services.spark_shuffle_y.classpath = /path/to/spark-y-yarn-shuffle.jar,/path/to/spark-y-config + yarn.nodemanager.aux-services.spark_shuffle_x.classpath = /path/to/spark-x-path/fat.jar:/path/to/spark-x-config + yarn.nodemanager.aux-services.spark_shuffle_y.classpath = /path/to/spark-y-path/fat.jar:/path/to/spark-y-config +``` +Or +```properties + yarn.nodemanager.aux-services = spark_shuffle_x,spark_shuffle_y + yarn.nodemanager.aux-services.spark_shuffle_x.classpath = /path/to/spark-x-path/*:/path/to/spark-x-config + yarn.nodemanager.aux-services.spark_shuffle_y.classpath = /path/to/spark-y-path/*:/path/to/spark-y-config ``` The two `spark-*-config` directories each contain one file, `spark-shuffle-site.xml`. These are XML - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch branch-3.3 updated (64165ca -> 444bac2)
This is an automated email from the ASF dual-hosted git repository. srowen pushed a change to branch branch-3.3 in repository https://gitbox.apache.org/repos/asf/spark.git. from 64165ca [SPARK-34805][SQL] Propagate metadata from nested columns in Alias add 444bac2 [SPARK-38606][DOC] Update document to make a good guide of multiple versions of the Spark Shuffle Service No new revisions were added by this update. Summary of changes: docs/running-on-yarn.md | 10 -- 1 file changed, 8 insertions(+), 2 deletions(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated: [SPARK-38606][DOC] Update document to make a good guide of multiple versions of the Spark Shuffle Service
This is an automated email from the ASF dual-hosted git repository. srowen pushed a commit to branch master in repository https://gitbox.apache.org/repos/asf/spark.git The following commit(s) were added to refs/heads/master by this push: new a876f00 [SPARK-38606][DOC] Update document to make a good guide of multiple versions of the Spark Shuffle Service a876f00 is described below commit a876f005ecef77d94bb8048fa1ff0841b7f3607a Author: zhangxudong1 AuthorDate: Mon Mar 21 13:48:20 2022 -0500 [SPARK-38606][DOC] Update document to make a good guide of multiple versions of the Spark Shuffle Service ### What changes were proposed in this pull request? Update document "Running multiple versions of the Spark Shuffle Service" to use colon when writing %s.classpath instead of commas. ### Why are the changes needed? User may be confused when they following the current document to deploy multi-versions Spark Shuffle Service on YARN. We have tried to run multiple versions of the Spark Shuffle Service according https://github.com/apache/spark/blob/master/docs/running-on-yarn.md but, it wont work. Then we solved it by using colon when writing %s.classpath instead of commas. Related discussing is in https://issues.apache.org/jira/browse/YARN-4577?focusedCommentId=17493624=com.atlassian.jira.plugin.system.issuetabpanels%3Acomment-tabpanel#comment-17493624 ### Does this PR introduce _any_ user-facing change? User document changes. ### How was this patch tested?  Closes #35914 from TonyDoen/SPARK-38606. Authored-by: zhangxudong1 Signed-off-by: Sean Owen --- docs/running-on-yarn.md | 10 -- 1 file changed, 8 insertions(+), 2 deletions(-) diff --git a/docs/running-on-yarn.md b/docs/running-on-yarn.md index 63c0376..48b0c7d 100644 --- a/docs/running-on-yarn.md +++ b/docs/running-on-yarn.md @@ -925,8 +925,14 @@ have configuration like: ```properties yarn.nodemanager.aux-services = spark_shuffle_x,spark_shuffle_y - yarn.nodemanager.aux-services.spark_shuffle_x.classpath = /path/to/spark-x-yarn-shuffle.jar,/path/to/spark-x-config - yarn.nodemanager.aux-services.spark_shuffle_y.classpath = /path/to/spark-y-yarn-shuffle.jar,/path/to/spark-y-config + yarn.nodemanager.aux-services.spark_shuffle_x.classpath = /path/to/spark-x-path/fat.jar:/path/to/spark-x-config + yarn.nodemanager.aux-services.spark_shuffle_y.classpath = /path/to/spark-y-path/fat.jar:/path/to/spark-y-config +``` +Or +```properties + yarn.nodemanager.aux-services = spark_shuffle_x,spark_shuffle_y + yarn.nodemanager.aux-services.spark_shuffle_x.classpath = /path/to/spark-x-path/*:/path/to/spark-x-config + yarn.nodemanager.aux-services.spark_shuffle_y.classpath = /path/to/spark-y-path/*:/path/to/spark-y-config ``` The two `spark-*-config` directories each contain one file, `spark-shuffle-site.xml`. These are XML - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated (4661455 -> 91614ff)
This is an automated email from the ASF dual-hosted git repository. srowen pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git. from 4661455 [SPARK-38544][BUILD] Upgrade log4j2 to 2.17.2 add 91614ff [SPARK-38510][SQL] Retry ClassSymbol.selfType to work around cyclic references No new revisions were added by this update. Summary of changes: project/SparkBuild.scala | 3 +- .../spark/sql/catalyst/ScalaReflection.scala | 36 -- .../spark/sql/hive/HiveScalaReflectionSuite.scala | 25 --- 3 files changed, 48 insertions(+), 16 deletions(-) copy core/src/main/scala/org/apache/spark/util/CausedBy.scala => sql/hive/src/test/scala/org/apache/spark/sql/hive/HiveScalaReflectionSuite.scala (57%) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch branch-3.3 updated: [SPARK-38544][BUILD] Upgrade log4j2 to 2.17.2
This is an automated email from the ASF dual-hosted git repository.
srowen pushed a commit to branch branch-3.3
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/branch-3.3 by this push:
new 5daf367 [SPARK-38544][BUILD] Upgrade log4j2 to 2.17.2
5daf367 is described below
commit 5daf367e11c71371b8dda139a2ea912e2427936f
Author: jackylee-ch
AuthorDate: Sat Mar 19 08:56:15 2022 -0500
[SPARK-38544][BUILD] Upgrade log4j2 to 2.17.2
### What changes were proposed in this pull request?
This pr aims to upgrade log4j2 to 2.17.2.
### Why are the changes needed?
This version brings a lot of fixes released to log1.x support, the release
notes and change report as follows:
- https://logging.apache.org/log4j/2.x/index.html#News
- https://logging.apache.org/log4j/2.x/changes-report.html#a2.17.2
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
GA
Closes #35898 from jackylee-ch/fix_update_log4j2_to_2.17.2.
Authored-by: jackylee-ch
Signed-off-by: Sean Owen
(cherry picked from commit 4661455aa03e30af3a2fe911ad8c5c5a12e1790b)
Signed-off-by: Sean Owen
---
dev/deps/spark-deps-hadoop-2-hive-2.3 | 8
dev/deps/spark-deps-hadoop-3-hive-2.3 | 8
pom.xml | 2 +-
.../deploy/k8s/integrationtest/SparkConfPropagateSuite.scala | 3 ++-
4 files changed, 11 insertions(+), 10 deletions(-)
diff --git a/dev/deps/spark-deps-hadoop-2-hive-2.3
b/dev/deps/spark-deps-hadoop-2-hive-2.3
index 28cb7c1..06d5939 100644
--- a/dev/deps/spark-deps-hadoop-2-hive-2.3
+++ b/dev/deps/spark-deps-hadoop-2-hive-2.3
@@ -187,10 +187,10 @@ lapack/2.2.1//lapack-2.2.1.jar
leveldbjni-all/1.8//leveldbjni-all-1.8.jar
libfb303/0.9.3//libfb303-0.9.3.jar
libthrift/0.12.0//libthrift-0.12.0.jar
-log4j-1.2-api/2.17.1//log4j-1.2-api-2.17.1.jar
-log4j-api/2.17.1//log4j-api-2.17.1.jar
-log4j-core/2.17.1//log4j-core-2.17.1.jar
-log4j-slf4j-impl/2.17.1//log4j-slf4j-impl-2.17.1.jar
+log4j-1.2-api/2.17.2//log4j-1.2-api-2.17.2.jar
+log4j-api/2.17.2//log4j-api-2.17.2.jar
+log4j-core/2.17.2//log4j-core-2.17.2.jar
+log4j-slf4j-impl/2.17.2//log4j-slf4j-impl-2.17.2.jar
logging-interceptor/3.12.12//logging-interceptor-3.12.12.jar
lz4-java/1.8.0//lz4-java-1.8.0.jar
mesos/1.4.3/shaded-protobuf/mesos-1.4.3-shaded-protobuf.jar
diff --git a/dev/deps/spark-deps-hadoop-3-hive-2.3
b/dev/deps/spark-deps-hadoop-3-hive-2.3
index 07549ef..2e9b0e3 100644
--- a/dev/deps/spark-deps-hadoop-3-hive-2.3
+++ b/dev/deps/spark-deps-hadoop-3-hive-2.3
@@ -172,10 +172,10 @@ lapack/2.2.1//lapack-2.2.1.jar
leveldbjni-all/1.8//leveldbjni-all-1.8.jar
libfb303/0.9.3//libfb303-0.9.3.jar
libthrift/0.12.0//libthrift-0.12.0.jar
-log4j-1.2-api/2.17.1//log4j-1.2-api-2.17.1.jar
-log4j-api/2.17.1//log4j-api-2.17.1.jar
-log4j-core/2.17.1//log4j-core-2.17.1.jar
-log4j-slf4j-impl/2.17.1//log4j-slf4j-impl-2.17.1.jar
+log4j-1.2-api/2.17.2//log4j-1.2-api-2.17.2.jar
+log4j-api/2.17.2//log4j-api-2.17.2.jar
+log4j-core/2.17.2//log4j-core-2.17.2.jar
+log4j-slf4j-impl/2.17.2//log4j-slf4j-impl-2.17.2.jar
logging-interceptor/3.12.12//logging-interceptor-3.12.12.jar
lz4-java/1.8.0//lz4-java-1.8.0.jar
mesos/1.4.3/shaded-protobuf/mesos-1.4.3-shaded-protobuf.jar
diff --git a/pom.xml b/pom.xml
index d8b5b87..a751bdd 100644
--- a/pom.xml
+++ b/pom.xml
@@ -119,7 +119,7 @@
1.6.0
spark
1.7.32
-2.17.1
+2.17.2
3.3.2
2.5.0
diff --git
a/resource-managers/kubernetes/integration-tests/src/test/scala/org/apache/spark/deploy/k8s/integrationtest/SparkConfPropagateSuite.scala
b/resource-managers/kubernetes/integration-tests/src/test/scala/org/apache/spark/deploy/k8s/integrationtest/SparkConfPropagateSuite.scala
index 7ed82e3..318b928 100644
---
a/resource-managers/kubernetes/integration-tests/src/test/scala/org/apache/spark/deploy/k8s/integrationtest/SparkConfPropagateSuite.scala
+++
b/resource-managers/kubernetes/integration-tests/src/test/scala/org/apache/spark/deploy/k8s/integrationtest/SparkConfPropagateSuite.scala
@@ -41,8 +41,9 @@ private[spark] trait SparkConfPropagateSuite { k8sSuite:
KubernetesSuite =>
sparkAppConf.set("spark.executor.extraJavaOptions", "-Dlog4j2.debug")
sparkAppConf.set("spark.kubernetes.executor.deleteOnTermination",
"false")
+ // since 2.17.2, log4j2 loads the original log4j2.properties instead of
the soft link.
val log4jExpectedLog =
-Seq("Reconfiguration complete for context", "at URI
/opt/spark/conf/log4j2.properties")
+Seq("Reconfiguration complete for context", "at URI /opt/spark/conf",
"/log4j2.properties")
runSpa
[spark] branch master updated (56086cb -> 4661455)
This is an automated email from the ASF dual-hosted git repository. srowen pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git. from 56086cb [SPARK-38541][BUILD] Upgrade Netty to 4.1.75 add 4661455 [SPARK-38544][BUILD] Upgrade log4j2 to 2.17.2 No new revisions were added by this update. Summary of changes: dev/deps/spark-deps-hadoop-2-hive-2.3 | 8 dev/deps/spark-deps-hadoop-3-hive-2.3 | 8 pom.xml | 2 +- .../deploy/k8s/integrationtest/SparkConfPropagateSuite.scala | 3 ++- 4 files changed, 11 insertions(+), 10 deletions(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated (b0f21e1 -> 56086cb)
This is an automated email from the ASF dual-hosted git repository. srowen pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git. from b0f21e1 [SPARK-38568][BUILD] Upgrade ZSTD-JNI to 1.5.2-2 add 56086cb [SPARK-38541][BUILD] Upgrade Netty to 4.1.75 No new revisions were added by this update. Summary of changes: common/network-common/pom.xml | 4 +++ .../org/apache/spark/network/util/NettyUtils.java | 8 ++ core/pom.xml | 4 +++ dev/deps/spark-deps-hadoop-2-hive-2.3 | 30 +++--- dev/deps/spark-deps-hadoop-3-hive-2.3 | 30 +++--- pom.xml| 12 - 6 files changed, 57 insertions(+), 31 deletions(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated (4ff40c1 -> 5967f29)
This is an automated email from the ASF dual-hosted git repository. srowen pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git. from 4ff40c1 [SPARK-38561][K8S][DOCS] Add doc for `Customized Kubernetes Schedulers` add 5967f29 [SPARK-38545][BUILD] Upgarde scala-maven-plugin from 4.4.0 to 4.5.6 No new revisions were added by this update. Summary of changes: pom.xml | 2 +- 1 file changed, 1 insertion(+), 1 deletion(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark-website] branch asf-site updated: Add notice for CVE-2021-38296
This is an automated email from the ASF dual-hosted git repository. srowen pushed a commit to branch asf-site in repository https://gitbox.apache.org/repos/asf/spark-website.git The following commit(s) were added to refs/heads/asf-site by this push: new 1569fce Add notice for CVE-2021-38296 1569fce is described below commit 1569fcefeb8b6deba7270acc928a27ee678b6118 Author: Sean Owen AuthorDate: Wed Mar 9 16:11:18 2022 -0600 Add notice for CVE-2021-38296 Author: Sean Owen Closes #382 from srowen/CVE-2021-38296. --- security.md| 27 +++ site/security.html | 32 2 files changed, 59 insertions(+) diff --git a/security.md b/security.md index dc9a9e6..32bbb74 100644 --- a/security.md +++ b/security.md @@ -18,6 +18,33 @@ non-public list that will reach the Apache Security team, as well as the Spark P Known security issues +CVE-2021-38296: Apache Spark Key Negotiation Vulnerability + +Severity: Medium + +Vendor: The Apache Software Foundation + +Versions Affected: + +- Apache Spark 3.1.2 and earlier + +Description: + +Apache Spark supports end-to-end encryption of RPC connections via `spark.authenticate` and `spark.network.crypto.enabled`. +In versions 3.1.2 and earlier, it uses a bespoke mutual authentication protocol that allows for full encryption key +recovery. After an initial interactive attack, this would allow someone to decrypt plaintext traffic offline. +Note that this does not affect security mechanisms controlled by `spark.authenticate.enableSaslEncryption`, +`spark.io.encryption.enabled`, `spark.ssl`, `spark.ui.strictTransportSecurity`. + +Mitigation: + +- Update to Spark 3.1.3 or later + +Credit: + +- Steve Weis (Databricks) + + CVE-2020-9480: Apache Spark RCE vulnerability in auth-enabled standalone master Severity: Important diff --git a/site/security.html b/site/security.html index ff3de6c..be0a8d8 100644 --- a/site/security.html +++ b/site/security.html @@ -155,6 +155,38 @@ non-public list that will reach the Apache Security team, as well as the Spark P Known security issues +CVE-2021-38296: Apache Spark Key Negotiation Vulnerability + +Severity: Medium + +Vendor: The Apache Software Foundation + +Versions Affected: + + + Apache Spark 3.1.2 and earlier + + +Description: + +Apache Spark supports end-to-end encryption of RPC connections via spark.authenticate and spark.network.crypto.enabled. +In versions 3.1.2 and earlier, it uses a bespoke mutual authentication protocol that allows for full encryption key +recovery. After an initial interactive attack, this would allow someone to decrypt plaintext traffic offline. +Note that this does not affect security mechanisms controlled by spark.authenticate.enableSaslEncryption, +spark.io.encryption.enabled, spark.ssl, spark.ui.strictTransportSecurity. + +Mitigation: + + + Update to Spark 3.1.3 or later + + +Credit: + + + Steve Weis (Databricks) + + CVE-2020-9480: Apache Spark RCE vulnerability in auth-enabled standalone master Severity: Important - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated (b99f58a -> d83ab94)
This is an automated email from the ASF dual-hosted git repository. srowen pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git. from b99f58a [SPARK-38267][CORE][SQL][SS] Replace pattern matches on boolean expressions with conditional statements add d83ab94 [SPARK-38419][BUILD] Replace tabs that exist in the script with spaces No new revisions were added by this update. Summary of changes: .../docker/src/main/dockerfiles/spark/entrypoint.sh | 4 ++-- sbin/spark-daemon.sh | 12 ++-- sbin/start-master.sh | 8 sbin/start-mesos-dispatcher.sh | 8 4 files changed, 16 insertions(+), 16 deletions(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated: [SPARK-38267][CORE][SQL][SS] Replace pattern matches on boolean expressions with conditional statements
This is an automated email from the ASF dual-hosted git repository.
srowen pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new b99f58a [SPARK-38267][CORE][SQL][SS] Replace pattern matches on
boolean expressions with conditional statements
b99f58a is described below
commit b99f58a57c880ed9cdec3d37ac8683c31daa4c10
Author: yangjie01
AuthorDate: Sun Mar 6 19:26:45 2022 -0600
[SPARK-38267][CORE][SQL][SS] Replace pattern matches on boolean expressions
with conditional statements
### What changes were proposed in this pull request?
This pr uses `conditional statements` to simplify `pattern matches on
boolean`:
**Before**
```scala
val bool: Boolean
bool match {
case true => do something when bool is true
case false => do something when bool is false
}
```
**After**
```scala
val bool: Boolean
if (bool) {
do something when bool is true
} else {
do something when bool is false
}
```
### Why are the changes needed?
Simplify unnecessary pattern match.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Pass GA
Closes #35589 from LuciferYang/trivial-match.
Authored-by: yangjie01
Signed-off-by: Sean Owen
---
.../BlockManagerDecommissionIntegrationSuite.scala | 7 +--
.../catalyst/expressions/datetimeExpressions.scala | 50 +++---
.../spark/sql/catalyst/parser/AstBuilder.scala | 14 +++---
.../sql/internal/ExecutorSideSQLConfSuite.scala| 7 +--
.../streaming/FlatMapGroupsWithStateSuite.scala| 7 +--
5 files changed, 43 insertions(+), 42 deletions(-)
diff --git
a/core/src/test/scala/org/apache/spark/storage/BlockManagerDecommissionIntegrationSuite.scala
b/core/src/test/scala/org/apache/spark/storage/BlockManagerDecommissionIntegrationSuite.scala
index 8999a12..e004c33 100644
---
a/core/src/test/scala/org/apache/spark/storage/BlockManagerDecommissionIntegrationSuite.scala
+++
b/core/src/test/scala/org/apache/spark/storage/BlockManagerDecommissionIntegrationSuite.scala
@@ -165,9 +165,10 @@ class BlockManagerDecommissionIntegrationSuite extends
SparkFunSuite with LocalS
}
x.map(y => (y, y))
}
-val testRdd = shuffle match {
- case true => baseRdd.reduceByKey(_ + _)
- case false => baseRdd
+val testRdd = if (shuffle) {
+ baseRdd.reduceByKey(_ + _)
+} else {
+ baseRdd
}
// Listen for the job & block updates
diff --git
a/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/datetimeExpressions.scala
b/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/datetimeExpressions.scala
index 8b5a387..d8cf474 100644
---
a/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/datetimeExpressions.scala
+++
b/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/datetimeExpressions.scala
@@ -2903,25 +2903,25 @@ case class SubtractTimestamps(
@transient private lazy val zoneIdInEval: ZoneId =
zoneIdForType(left.dataType)
@transient
- private lazy val evalFunc: (Long, Long) => Any = legacyInterval match {
-case false => (leftMicros, rightMicros) =>
- subtractTimestamps(leftMicros, rightMicros, zoneIdInEval)
-case true => (leftMicros, rightMicros) =>
+ private lazy val evalFunc: (Long, Long) => Any = if (legacyInterval) {
+(leftMicros, rightMicros) =>
new CalendarInterval(0, 0, leftMicros - rightMicros)
+ } else {
+(leftMicros, rightMicros) =>
+ subtractTimestamps(leftMicros, rightMicros, zoneIdInEval)
}
override def nullSafeEval(leftMicros: Any, rightMicros: Any): Any = {
evalFunc(leftMicros.asInstanceOf[Long], rightMicros.asInstanceOf[Long])
}
- override def doGenCode(ctx: CodegenContext, ev: ExprCode): ExprCode =
legacyInterval match {
-case false =>
- val zid = ctx.addReferenceObj("zoneId", zoneIdInEval,
classOf[ZoneId].getName)
- val dtu = DateTimeUtils.getClass.getName.stripSuffix("$")
- defineCodeGen(ctx, ev, (l, r) => s"""$dtu.subtractTimestamps($l, $r,
$zid)""")
-case true =>
- defineCodeGen(ctx, ev, (end, start) =>
-s"new org.apache.spark.unsafe.types.CalendarInterval(0, 0, $end -
$start)")
+ override def doGenCode(ctx: CodegenContext, ev: ExprCode): ExprCode = if
(legacyInterval) {
+defineCodeGen(ctx, ev, (end, start) =>
+ s"new org.apache.spark.unsafe.types.CalendarInterval(0, 0, $end -
$start)")
+ } else {
+val zid = ctx.addReferenceObj("zoneId", zoneIdInEval,
classOf[ZoneId].getName)
+val dtu = DateTimeUtils.getClass.getName.stripSuffix("$")
+defin
[spark] branch master updated: [SPARK-38394][BUILD] Upgrade `scala-maven-plugin` to 4.4.0 for Hadoop 3 profile
This is an automated email from the ASF dual-hosted git repository.
srowen pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new 3175d83 [SPARK-38394][BUILD] Upgrade `scala-maven-plugin` to 4.4.0
for Hadoop 3 profile
3175d83 is described below
commit 3175d830cb029d41909de8960aa790d4272aa188
Author: Steve Loughran
AuthorDate: Sun Mar 6 19:23:31 2022 -0600
[SPARK-38394][BUILD] Upgrade `scala-maven-plugin` to 4.4.0 for Hadoop 3
profile
### What changes were proposed in this pull request?
This sets scala-maven-plugin.version to 4.4.0 except when the hadoop-2.7
profile is used, because SPARK-36547 shows that only 4.3.0 works there.
### Why are the changes needed?
1. If you try to build against a local snapshot of hadoop trunk with
`-Dhadoop.version=3.4.0-SNAPSHOT` the build failes with the error shown in the
JIRA.
2. upgrading the scala plugin version fixes this. It is a plugin issue.
3. the version is made configurable so the hadoop 2.7 profile can switch
back to the one which works there.
As to why this only surfaces when compiling hadoop trunk, or why hadoop-2.7
requires the new one -who knows. they both look certificate related, which is
interesting. maybe something related to signed JARs?
### Does this PR introduce _any_ user-facing change?
no
### How was this patch tested?
by successfully building spark against a local build of hadoop
3.4.0-SNAPSHOT
Closes #35725 from steveloughran/SPARK-38394-compiler-version.
Authored-by: Steve Loughran
Signed-off-by: Sean Owen
---
pom.xml | 8 ++--
1 file changed, 6 insertions(+), 2 deletions(-)
diff --git a/pom.xml b/pom.xml
index 176d3af..8e03167 100644
--- a/pom.xml
+++ b/pom.xml
@@ -163,6 +163,10 @@
2.12.15
2.12
2.0.2
+
+
+4.4.0
--test
true
@@ -2775,8 +2779,7 @@
net.alchim31.maven
scala-maven-plugin
-
- 4.3.0
+ ${scala-maven-plugin.version}
eclipse-add-source
@@ -3430,6 +3433,7 @@
hadoop-client
hadoop-yarn-api
hadoop-client
+4.3.0
-
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated (18219d4 -> 69bc9d1)
This is an automated email from the ASF dual-hosted git repository. srowen pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git. from 18219d4 [SPARK-37400][SPARK-37426][PYTHON][MLLIB] Inline type hints for pyspark.mllib classification and regression add 69bc9d1 [SPARK-38239][PYTHON][MLLIB] Fix pyspark.mllib.LogisticRegressionModel.__repr__ No new revisions were added by this update. Summary of changes: python/pyspark/mllib/classification.py | 5 - 1 file changed, 4 insertions(+), 1 deletion(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated (727f044 -> 97716f7)
This is an automated email from the ASF dual-hosted git repository. srowen pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git. from 727f044 [SPARK-38189][K8S][DOC] Add `Priority scheduling` doc for Spark on K8S add 97716f7 [SPARK-38393][SQL] Clean up deprecated usage of `GenSeq/GenMap` No new revisions were added by this update. Summary of changes: .../org/apache/spark/sql/execution/command/ddl.scala | 19 +-- 1 file changed, 9 insertions(+), 10 deletions(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated: [SPARK-38191][CORE][FOLLOWUP] The staging directory of write job only needs to be initialized once in HadoopMapReduceCommitProtocol
This is an automated email from the ASF dual-hosted git repository.
srowen pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new 23db9b4 [SPARK-38191][CORE][FOLLOWUP] The staging directory of write
job only needs to be initialized once in HadoopMapReduceCommitProtocol
23db9b4 is described below
commit 23db9b440ba70f4edf1f4a604f4829e1831ea502
Author: weixiuli
AuthorDate: Wed Mar 2 18:00:56 2022 -0600
[SPARK-38191][CORE][FOLLOWUP] The staging directory of write job only needs
to be initialized once in HadoopMapReduceCommitProtocol
### What changes were proposed in this pull request?
This pr follows up the https://github.com/apache/spark/pull/35492, try to
use a stagingDir constant instead of the stagingDir method in
HadoopMapReduceCommitProtocol.
### Why are the changes needed?
In the https://github.com/apache/spark/pull/35492#issuecomment-1054910730
```
./build/sbt -mem 4096 -Phadoop-2 "sql/testOnly
org.apache.spark.sql.sources.PartitionedWriteSuite -- -z SPARK-27194"
...
[info] Cause: org.apache.spark.SparkException: Task not serializable
...
[info] Cause: java.io.NotSerializableException: org.apache.hadoop.fs.Path
...
```
It's because org.apache.hadoop.fs.Path is serializable in Hadoop3 but not
in Hadoop2. So, we should make the stagingDir transient to avoid that.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Passed `./build/sbt -mem 4096 -Phadoop-2 "sql/testOnly
org.apache.spark.sql.sources.PartitionedWriteSuite -- -z SPARK-27194"`
Pass the CIs.
Closes #35693 from weixiuli/staging-directory.
Authored-by: weixiuli
Signed-off-by: Sean Owen
---
.../org/apache/spark/internal/io/HadoopMapReduceCommitProtocol.scala| 2 +-
1 file changed, 1 insertion(+), 1 deletion(-)
diff --git
a/core/src/main/scala/org/apache/spark/internal/io/HadoopMapReduceCommitProtocol.scala
b/core/src/main/scala/org/apache/spark/internal/io/HadoopMapReduceCommitProtocol.scala
index a39e9ab..3a24da9 100644
---
a/core/src/main/scala/org/apache/spark/internal/io/HadoopMapReduceCommitProtocol.scala
+++
b/core/src/main/scala/org/apache/spark/internal/io/HadoopMapReduceCommitProtocol.scala
@@ -104,7 +104,7 @@ class HadoopMapReduceCommitProtocol(
* The staging directory of this write job. Spark uses it to deal with files
with absolute output
* path, or writing data into partitioned directory with
dynamicPartitionOverwrite=true.
*/
- protected def stagingDir = getStagingDir(path, jobId)
+ @transient protected lazy val stagingDir = getStagingDir(path, jobId)
protected def setupCommitter(context: TaskAttemptContext): OutputCommitter =
{
val format = context.getOutputFormatClass.getConstructor().newInstance()
-
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated (42db298 -> b141c15)
This is an automated email from the ASF dual-hosted git repository. srowen pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git. from 42db298 Revert "[SPARK-37090][BUILD] Upgrade `libthrift` to 0.16.0 to avoid security vulnerabilities" add b141c15 [SPARK-38342][CORE] Clean up deprecated api usage of Ivy No new revisions were added by this update. Summary of changes: core/src/main/scala/org/apache/spark/deploy/SparkSubmit.scala | 4 ++-- 1 file changed, 2 insertions(+), 2 deletions(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated (1b95cfe -> 615c5d8)
This is an automated email from the ASF dual-hosted git repository. srowen pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git. from 1b95cfe [SPARK-38348][BUILD] Upgrade `tink` to 1.6.1 add 615c5d8 [MINOR] Clean up an unnecessary variable No new revisions were added by this update. Summary of changes: .../org/apache/spark/sql/execution/datasources/FileFormatWriter.scala| 1 - 1 file changed, 1 deletion(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated: [SPARK-38348][BUILD] Upgrade `tink` to 1.6.1
This is an automated email from the ASF dual-hosted git repository.
srowen pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new 1b95cfe [SPARK-38348][BUILD] Upgrade `tink` to 1.6.1
1b95cfe is described below
commit 1b95cfe362db429dcb306e0ff9b73228d18dcc03
Author: yangjie01
AuthorDate: Tue Mar 1 08:28:07 2022 -0600
[SPARK-38348][BUILD] Upgrade `tink` to 1.6.1
### What changes were proposed in this pull request?
This pr aims upgrade `com.google.crypto.tink:tink` from 1.6.0 to 1.6.1
### Why are the changes needed?
The release notes as follows:
- https://github.com/google/tink/releases/tag/v1.6.1
There is a performance optimization related to `AesGcmJce.encrypt` method
in version 1.6.1 and this method used by
`o.a.s.network.crypto.AuthEngine#challenge` and
`o.a.s.network.crypto.AuthEngine#response` methods in Spark:
- [Java: isAndroid() shouldn't cause Exceptions to be
created](https://github.com/google/tink/issues/497)
This optimization reduces the delay of `AesGcmJce.encrypt` method by 70%.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
- Pass GA
- Manual test:
Verify the performance improvement of `AesGcmJce.encrypt` method as follows:
```scala
val valuesPerIteration = 10
val derivedKeyEncryptingKey: Array[Byte] =
Array(119, -25, -98, 34, -61, 102, 101, -97, 86, -27, 25, 88, 94, -55,
40, -103)
val ephemeralX25519PublicKey: Array[Byte] =
Array(-94, 121, -27, 40, -42, -6, 114, 17, -11, 107, 58, -69, -69, -58,
56, -121, 28, -18, 10, 25, 41, -66, 77, 17, 19, -99, -54, 54, 97,
-111, -13, 77)
val aadState: Array[Byte] =
Array(97, 112, 112, 73, 100, -19, 84, 88, -18, -105, 104, 105, 29, -84,
94, -110, 84, 38, -109, -85, -55)
val benchmark = new Benchmark("Test AesGcmJceEncrypt", valuesPerIteration,
output = output)
benchmark.addCase("Test AesGcmJce encrypt") { _: Int =>
for (_ <- 0L until valuesPerIteration) {
new
AesGcmJce(derivedKeyEncryptingKey).encrypt(ephemeralX25519PublicKey, aadState)
}
}
benchmark.run()
```
**Before**: 5423.0 ns/ per row
**After**: 1538.3 ns /per row
Closes #35679 from LuciferYang/upgrade-tink.
Authored-by: yangjie01
Signed-off-by: Sean Owen
---
dev/deps/spark-deps-hadoop-2-hive-2.3 | 2 +-
dev/deps/spark-deps-hadoop-3-hive-2.3 | 2 +-
pom.xml | 2 +-
3 files changed, 3 insertions(+), 3 deletions(-)
diff --git a/dev/deps/spark-deps-hadoop-2-hive-2.3
b/dev/deps/spark-deps-hadoop-2-hive-2.3
index d9589da..f6687ed 100644
--- a/dev/deps/spark-deps-hadoop-2-hive-2.3
+++ b/dev/deps/spark-deps-hadoop-2-hive-2.3
@@ -255,7 +255,7 @@ stax-api/1.0.1//stax-api-1.0.1.jar
stream/2.9.6//stream-2.9.6.jar
super-csv/2.2.0//super-csv-2.2.0.jar
threeten-extra/1.5.0//threeten-extra-1.5.0.jar
-tink/1.6.0//tink-1.6.0.jar
+tink/1.6.1//tink-1.6.1.jar
transaction-api/1.1//transaction-api-1.1.jar
univocity-parsers/2.9.1//univocity-parsers-2.9.1.jar
velocity/1.5//velocity-1.5.jar
diff --git a/dev/deps/spark-deps-hadoop-3-hive-2.3
b/dev/deps/spark-deps-hadoop-3-hive-2.3
index f01e4b5..eb1e7cd 100644
--- a/dev/deps/spark-deps-hadoop-3-hive-2.3
+++ b/dev/deps/spark-deps-hadoop-3-hive-2.3
@@ -240,7 +240,7 @@ stax-api/1.0.1//stax-api-1.0.1.jar
stream/2.9.6//stream-2.9.6.jar
super-csv/2.2.0//super-csv-2.2.0.jar
threeten-extra/1.5.0//threeten-extra-1.5.0.jar
-tink/1.6.0//tink-1.6.0.jar
+tink/1.6.1//tink-1.6.1.jar
transaction-api/1.1//transaction-api-1.1.jar
univocity-parsers/2.9.1//univocity-parsers-2.9.1.jar
velocity/1.5//velocity-1.5.jar
diff --git a/pom.xml b/pom.xml
index dfa34f4..bcf3468 100644
--- a/pom.xml
+++ b/pom.xml
@@ -196,7 +196,7 @@
1.1.0
1.5.0
1.60
-1.6.0
+1.6.1
[spark] branch master updated (969d672 -> 9336db7)
This is an automated email from the ASF dual-hosted git repository. srowen pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git. from 969d672 [SPARK-37688][CORE] ExecutorMonitor should ignore SparkListenerBlockUpdated event if executor was not active add 9336db7 Revert "[SPARK-38191][CORE] The staging directory of write job only needs to be initialized once in HadoopMapReduceCommitProtocol" No new revisions were added by this update. Summary of changes: .../org/apache/spark/internal/io/HadoopMapReduceCommitProtocol.scala| 2 +- 1 file changed, 1 insertion(+), 1 deletion(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch branch-3.1 updated (b98dc38 -> d7b0567)
This is an automated email from the ASF dual-hosted git repository. srowen pushed a change to branch branch-3.1 in repository https://gitbox.apache.org/repos/asf/spark.git. from b98dc38 [MINOR][DOCS] Fix missing field in query add d7b0567 [SPARK-37090][BUILD][3.1] Upgrade libthrift to 0.16.0 to avoid security vulnerabilities No new revisions were added by this update. Summary of changes: dev/deps/spark-deps-hadoop-2.7-hive-2.3| 2 +- dev/deps/spark-deps-hadoop-3.2-hive-2.3| 2 +- pom.xml| 6 +- .../apache/hive/service/auth/HiveAuthFactory.java | 2 +- .../hive/service/auth/KerberosSaslHelper.java | 5 +- .../apache/hive/service/auth/PlainSaslHelper.java | 3 +- .../hive/service/auth/TSetIpAddressProcessor.java | 5 +- .../service/cli/thrift/ThriftBinaryCLIService.java | 6 - .../hive/service/cli/thrift/ThriftCLIService.java | 10 ++ .../apache/thrift/transport/TFramedTransport.java | 200 + 10 files changed, 226 insertions(+), 15 deletions(-) create mode 100644 sql/hive/src/main/java/org/apache/thrift/transport/TFramedTransport.java - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch branch-3.2 updated (a4b3775 -> 286891b)
This is an automated email from the ASF dual-hosted git repository. srowen pushed a change to branch branch-3.2 in repository https://gitbox.apache.org/repos/asf/spark.git. from a4b3775 [MINOR][DOCS] Fix missing field in query add 286891b [SPARK-37090][BUILD][3.2] Upgrade libthrift to 0.16.0 to avoid security vulnerabilities No new revisions were added by this update. Summary of changes: dev/deps/spark-deps-hadoop-2.7-hive-2.3| 2 +- dev/deps/spark-deps-hadoop-3.2-hive-2.3| 2 +- pom.xml| 6 +- .../apache/hive/service/auth/HiveAuthFactory.java | 2 +- .../hive/service/auth/KerberosSaslHelper.java | 5 +- .../apache/hive/service/auth/PlainSaslHelper.java | 3 +- .../hive/service/auth/TSetIpAddressProcessor.java | 5 +- .../service/cli/thrift/ThriftBinaryCLIService.java | 6 - .../hive/service/cli/thrift/ThriftCLIService.java | 10 ++ .../apache/thrift/transport/TFramedTransport.java | 200 + 10 files changed, 226 insertions(+), 15 deletions(-) create mode 100644 sql/hive/src/main/java/org/apache/thrift/transport/TFramedTransport.java - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated (dc153f5 -> 9eab255)
This is an automated email from the ASF dual-hosted git repository. srowen pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git. from dc153f5 [SPARK-38237][SQL][SS] Allow `ClusteredDistribution` to require full clustering keys add 9eab255 [SPARK-38242][CORE] Sort the SparkSubmit debug output No new revisions were added by this update. Summary of changes: core/src/main/scala/org/apache/spark/deploy/SparkSubmit.scala | 2 +- core/src/main/scala/org/apache/spark/deploy/SparkSubmitArguments.scala | 2 +- 2 files changed, 2 insertions(+), 2 deletions(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated (daa5f9d -> b204710)
This is an automated email from the ASF dual-hosted git repository. srowen pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git. from daa5f9d [MINOR][DOCS] Fix missing field in query add b204710 [MINOR] Add git ignores for vscode and metals No new revisions were added by this update. Summary of changes: .gitignore | 5 + 1 file changed, 5 insertions(+) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch branch-3.1 updated (82765a8 -> b98dc38)
This is an automated email from the ASF dual-hosted git repository. srowen pushed a change to branch branch-3.1 in repository https://gitbox.apache.org/repos/asf/spark.git. from 82765a8 [SPARK-38305][CORE] Explicitly check if source exists in unpack() before calling FileUtil methods add b98dc38 [MINOR][DOCS] Fix missing field in query No new revisions were added by this update. Summary of changes: docs/sql-ref-syntax-qry-select-window.md | 4 ++-- 1 file changed, 2 insertions(+), 2 deletions(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch branch-3.2 updated: [MINOR][DOCS] Fix missing field in query
This is an automated email from the ASF dual-hosted git repository. srowen pushed a commit to branch branch-3.2 in repository https://gitbox.apache.org/repos/asf/spark.git The following commit(s) were added to refs/heads/branch-3.2 by this push: new a4b3775 [MINOR][DOCS] Fix missing field in query a4b3775 is described below commit a4b37757d444182006369d2e4a0b7faaf1d38917 Author: Alfonso AuthorDate: Fri Feb 25 08:38:51 2022 -0600 [MINOR][DOCS] Fix missing field in query ### What changes were proposed in this pull request? This PR fixes sql query in doc, let the query confrom to the query result in the following ### Why are the changes needed? Just a fix to doc ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? use project test Closes #35624 from redsnow1992/patch-1. Authored-by: Alfonso Signed-off-by: Sean Owen (cherry picked from commit daa5f9df4a1c8b3cf5db7142e54b765272c1f24c) Signed-off-by: Sean Owen --- docs/sql-ref-syntax-qry-select-window.md | 4 ++-- 1 file changed, 2 insertions(+), 2 deletions(-) diff --git a/docs/sql-ref-syntax-qry-select-window.md b/docs/sql-ref-syntax-qry-select-window.md index 6e65778..9fbebcf 100644 --- a/docs/sql-ref-syntax-qry-select-window.md +++ b/docs/sql-ref-syntax-qry-select-window.md @@ -109,7 +109,7 @@ SELECT * FROM employees; | Alex| Sales| 3| 33| +-+---+--+-+ -SELECT name, dept, RANK() OVER (PARTITION BY dept ORDER BY salary) AS rank FROM employees; +SELECT name, dept, salary, RANK() OVER (PARTITION BY dept ORDER BY salary) AS rank FROM employees; +-+---+--++ | name| dept|salary|rank| +-+---+--++ @@ -125,7 +125,7 @@ SELECT name, dept, RANK() OVER (PARTITION BY dept ORDER BY salary) AS rank FROM | Jeff| Marketing| 35000| 3| +-+---+--++ -SELECT name, dept, DENSE_RANK() OVER (PARTITION BY dept ORDER BY salary ROWS BETWEEN +SELECT name, dept, salary, DENSE_RANK() OVER (PARTITION BY dept ORDER BY salary ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) AS dense_rank FROM employees; +-+---+--+--+ | name| dept|salary|dense_rank| - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated (64e1f28 -> daa5f9d)
This is an automated email from the ASF dual-hosted git repository. srowen pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git. from 64e1f28 [SPARK-38305][CORE] Explicitly check if source exists in unpack() before calling FileUtil methods add daa5f9d [MINOR][DOCS] Fix missing field in query No new revisions were added by this update. Summary of changes: docs/sql-ref-syntax-qry-select-window.md | 4 ++-- 1 file changed, 2 insertions(+), 2 deletions(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch branch-3.1 updated: [SPARK-38305][CORE] Explicitly check if source exists in unpack() before calling FileUtil methods
This is an automated email from the ASF dual-hosted git repository.
srowen pushed a commit to branch branch-3.1
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/branch-3.1 by this push:
new 82765a8 [SPARK-38305][CORE] Explicitly check if source exists in
unpack() before calling FileUtil methods
82765a8 is described below
commit 82765a826b41311bd3cea2bc454f89ebdc0a3aa1
Author: Sean Owen
AuthorDate: Fri Feb 25 08:34:04 2022 -0600
[SPARK-38305][CORE] Explicitly check if source exists in unpack() before
calling FileUtil methods
### What changes were proposed in this pull request?
Explicitly check existence of source file in Utils.unpack before calling
Hadoop FileUtil methods
### Why are the changes needed?
A discussion from the Hadoop community raised a potential issue in calling
these methods when a file doesn't exist.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Existing tests
Closes #35632 from srowen/SPARK-38305.
Authored-by: Sean Owen
Signed-off-by: Sean Owen
(cherry picked from commit 64e1f28f1626247cc1361dcb395288227454ca8f)
Signed-off-by: Sean Owen
---
core/src/main/scala/org/apache/spark/util/Utils.scala | 3 +++
1 file changed, 3 insertions(+)
diff --git a/core/src/main/scala/org/apache/spark/util/Utils.scala
b/core/src/main/scala/org/apache/spark/util/Utils.scala
index 1643aa6..efe9cc2 100644
--- a/core/src/main/scala/org/apache/spark/util/Utils.scala
+++ b/core/src/main/scala/org/apache/spark/util/Utils.scala
@@ -577,6 +577,9 @@ private[spark] object Utils extends Logging {
* basically copied from `org.apache.hadoop.yarn.util.FSDownload.unpack`.
*/
def unpack(source: File, dest: File): Unit = {
+if (!source.exists()) {
+ throw new FileNotFoundException(source.getAbsolutePath)
+}
val lowerSrc = StringUtils.toLowerCase(source.getName)
if (lowerSrc.endsWith(".jar")) {
RunJar.unJar(source, dest, RunJar.MATCH_ANY)
-
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch branch-3.2 updated: [SPARK-38305][CORE] Explicitly check if source exists in unpack() before calling FileUtil methods
This is an automated email from the ASF dual-hosted git repository.
srowen pushed a commit to branch branch-3.2
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/branch-3.2 by this push:
new 775a829 [SPARK-38305][CORE] Explicitly check if source exists in
unpack() before calling FileUtil methods
775a829 is described below
commit 775a829c9de3717a8f298146dde0d57dd7c0ab11
Author: Sean Owen
AuthorDate: Fri Feb 25 08:34:04 2022 -0600
[SPARK-38305][CORE] Explicitly check if source exists in unpack() before
calling FileUtil methods
### What changes were proposed in this pull request?
Explicitly check existence of source file in Utils.unpack before calling
Hadoop FileUtil methods
### Why are the changes needed?
A discussion from the Hadoop community raised a potential issue in calling
these methods when a file doesn't exist.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Existing tests
Closes #35632 from srowen/SPARK-38305.
Authored-by: Sean Owen
Signed-off-by: Sean Owen
(cherry picked from commit 64e1f28f1626247cc1361dcb395288227454ca8f)
Signed-off-by: Sean Owen
---
core/src/main/scala/org/apache/spark/util/Utils.scala | 3 +++
1 file changed, 3 insertions(+)
diff --git a/core/src/main/scala/org/apache/spark/util/Utils.scala
b/core/src/main/scala/org/apache/spark/util/Utils.scala
index 31514c8..776c8c4 100644
--- a/core/src/main/scala/org/apache/spark/util/Utils.scala
+++ b/core/src/main/scala/org/apache/spark/util/Utils.scala
@@ -585,6 +585,9 @@ private[spark] object Utils extends Logging {
* basically copied from `org.apache.hadoop.yarn.util.FSDownload.unpack`.
*/
def unpack(source: File, dest: File): Unit = {
+if (!source.exists()) {
+ throw new FileNotFoundException(source.getAbsolutePath)
+}
val lowerSrc = StringUtils.toLowerCase(source.getName)
if (lowerSrc.endsWith(".jar")) {
RunJar.unJar(source, dest, RunJar.MATCH_ANY)
-
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated: [SPARK-38305][CORE] Explicitly check if source exists in unpack() before calling FileUtil methods
This is an automated email from the ASF dual-hosted git repository.
srowen pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new 64e1f28 [SPARK-38305][CORE] Explicitly check if source exists in
unpack() before calling FileUtil methods
64e1f28 is described below
commit 64e1f28f1626247cc1361dcb395288227454ca8f
Author: Sean Owen
AuthorDate: Fri Feb 25 08:34:04 2022 -0600
[SPARK-38305][CORE] Explicitly check if source exists in unpack() before
calling FileUtil methods
### What changes were proposed in this pull request?
Explicitly check existence of source file in Utils.unpack before calling
Hadoop FileUtil methods
### Why are the changes needed?
A discussion from the Hadoop community raised a potential issue in calling
these methods when a file doesn't exist.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Existing tests
Closes #35632 from srowen/SPARK-38305.
Authored-by: Sean Owen
Signed-off-by: Sean Owen
---
core/src/main/scala/org/apache/spark/util/Utils.scala | 3 +++
1 file changed, 3 insertions(+)
diff --git a/core/src/main/scala/org/apache/spark/util/Utils.scala
b/core/src/main/scala/org/apache/spark/util/Utils.scala
index a9d6180..17bec9f 100644
--- a/core/src/main/scala/org/apache/spark/util/Utils.scala
+++ b/core/src/main/scala/org/apache/spark/util/Utils.scala
@@ -593,6 +593,9 @@ private[spark] object Utils extends Logging {
* basically copied from `org.apache.hadoop.yarn.util.FSDownload.unpack`.
*/
def unpack(source: File, dest: File): Unit = {
+if (!source.exists()) {
+ throw new FileNotFoundException(source.getAbsolutePath)
+}
val lowerSrc = StringUtils.toLowerCase(source.getName)
if (lowerSrc.endsWith(".jar")) {
RunJar.unJar(source, dest, RunJar.MATCH_ANY)
-
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated (43c89dc -> e58872d)
This is an automated email from the ASF dual-hosted git repository. srowen pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git. from 43c89dc [SPARK-38273][SQL] `decodeUnsafeRows`'s iterators should close underlying input streams add e58872d [SPARK-38191][CORE] The staging directory of write job only needs to be initialized once in HadoopMapReduceCommitProtocol No new revisions were added by this update. Summary of changes: .../org/apache/spark/internal/io/HadoopMapReduceCommitProtocol.scala| 2 +- 1 file changed, 1 insertion(+), 1 deletion(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark-website] branch asf-site updated: Fix wrong issue link
This is an automated email from the ASF dual-hosted git repository. srowen pushed a commit to branch asf-site in repository https://gitbox.apache.org/repos/asf/spark-website.git The following commit(s) were added to refs/heads/asf-site by this push: new 2bc2501 Fix wrong issue link 2bc2501 is described below commit 2bc2501972dcdecc7305d48cdd8746ddfecc9125 Author: Angerszh AuthorDate: Wed Feb 23 07:05:03 2022 -0600 Fix wrong issue link Fix wrong issue link Author: Angerszh Closes #380 from AngersZh/fix-link-of-spark-35391. --- releases/_posts/2019-09-01-spark-release-2-4-4.md | 2 +- releases/_posts/2021-05-17-spark-release-2-4-8.md | 2 +- releases/_posts/2022-02-18-spark-release-3-1-3.md | 2 +- site/releases/spark-release-2-4-4.html| 2 +- site/releases/spark-release-2-4-8.html| 2 +- site/releases/spark-release-3-1-3.html| 2 +- 6 files changed, 6 insertions(+), 6 deletions(-) diff --git a/releases/_posts/2019-09-01-spark-release-2-4-4.md b/releases/_posts/2019-09-01-spark-release-2-4-4.md index ab60b58..bfa4873 100644 --- a/releases/_posts/2019-09-01-spark-release-2-4-4.md +++ b/releases/_posts/2019-09-01-spark-release-2-4-4.md @@ -17,7 +17,7 @@ Spark 2.4.4 is a maintenance release containing stability fixes. This release is - [[SPARK-26038]](https://issues.apache.org/jira/browse/SPARK-26038): Fix Decimal toScalaBigInt/toJavaBigInteger for decimals not fitting in long - [[SPARK-26812]](https://issues.apache.org/jira/browse/SPARK-26812): Fix PushProjectionThroughUnion nullability issue - [[SPARK-27798]](https://issues.apache.org/jira/browse/SPARK-27798): Fix from_avro not to modify variables in other rows in local mode - - [[SPARK-27907]](https://issues.apache.org/jira/browse/SPARK-27992): Spark 2.4.3 accidentally throws NPE when HiveUDAF meets 0 rows. Fixed to return NULL like all the other releases. + - [[SPARK-27907]](https://issues.apache.org/jira/browse/SPARK-27907): Spark 2.4.3 accidentally throws NPE when HiveUDAF meets 0 rows. Fixed to return NULL like all the other releases. - [[SPARK-27992]](https://issues.apache.org/jira/browse/SPARK-27992): Fix PySpark socket server to sync with JVM connection thread future - [[SPARK-28015]](https://issues.apache.org/jira/browse/SPARK-28015): Check stringToDate() consumes entire input for the and -[m]m formats - [[SPARK-28308]](https://issues.apache.org/jira/browse/SPARK-28308): CalendarInterval sub-second part should be padded before parsing diff --git a/releases/_posts/2021-05-17-spark-release-2-4-8.md b/releases/_posts/2021-05-17-spark-release-2-4-8.md index 68360af..fc7024b 100644 --- a/releases/_posts/2021-05-17-spark-release-2-4-8.md +++ b/releases/_posts/2021-05-17-spark-release-2-4-8.md @@ -21,7 +21,7 @@ Spark 2.4.8 is a maintenance release containing stability, correctness, and secu - [[SPARK-26645]](https://issues.apache.org/jira/browse/SPARK-26645): CSV infer schema bug infers decimal(9,-1) - [[SPARK-27575]](https://issues.apache.org/jira/browse/SPARK-27575): Spark overwrites existing value of spark.yarn.dist.* instead of merging value - [[SPARK-27872]](https://issues.apache.org/jira/browse/SPARK-27872): Driver and executors use a different service account breaking pull secrets - - [[SPARK-29574]](https://issues.apache.org/jira/browse/SPARK-27872): spark with user provided hadoop doesn't work on kubernetes + - [[SPARK-29574]](https://issues.apache.org/jira/browse/SPARK-29574): spark with user provided hadoop doesn't work on kubernetes - [[SPARK-30201]](https://issues.apache.org/jira/browse/SPARK-30201): HiveOutputWriter standardOI should use ObjectInspectorCopyOption.DEFAULT - [[SPARK-32635]](https://issues.apache.org/jira/browse/SPARK-32635): When pyspark.sql.functions.lit() function is used with dataframe cache, it returns wrong result - [[SPARK-32708]](https://issues.apache.org/jira/browse/SPARK-32708): Query optimization fails to reuse exchange with DataSourceV2 diff --git a/releases/_posts/2022-02-18-spark-release-3-1-3.md b/releases/_posts/2022-02-18-spark-release-3-1-3.md index 25a0417..a22c7f1 100644 --- a/releases/_posts/2022-02-18-spark-release-3-1-3.md +++ b/releases/_posts/2022-02-18-spark-release-3-1-3.md @@ -26,7 +26,7 @@ Spark 3.1.3 is a maintenance release containing stability fixes. This release is - [[SPARK-36532]](https://issues.apache.org/jira/browse/SPARK-36532): Deadlock in CoarseGrainedExecutorBackend.onDisconnected - [[SPARK-36489]](https://issues.apache.org/jira/browse/SPARK-36489): Aggregate functions over no grouping keys, on tables with a single bucket, return multiple rows - [[SPARK-36339]](https://issues.apache.org/jira/browse/SPARK-36339): aggsBuffer should collect AggregateExpression in the map range - - [[SPARK-35391]](https://issues.apache.org/jira/browse/SPARK-36339): Memory leak in ExecutorAllocationListener breaks dynamic
[spark] branch master updated: [SPARK-38060][SQL] Respect allowNonNumericNumbers when parsing quoted NaN and Infinity values in JSON reader
This is an automated email from the ASF dual-hosted git repository. srowen pushed a commit to branch master in repository https://gitbox.apache.org/repos/asf/spark.git The following commit(s) were added to refs/heads/master by this push: new 43822cd [SPARK-38060][SQL] Respect allowNonNumericNumbers when parsing quoted NaN and Infinity values in JSON reader 43822cd is described below commit 43822cdd228a3ba49c47637c525d731d00772f64 Author: Andy Grove AuthorDate: Tue Feb 22 08:42:47 2022 -0600 [SPARK-38060][SQL] Respect allowNonNumericNumbers when parsing quoted NaN and Infinity values in JSON reader Signed-off-by: Andy Grove ### What changes were proposed in this pull request? When parsing JSON unquoted `NaN` and `Infinity`values for floating-point columns we get the expected behavior as shown below where valid values are returned when the parsing option `allowNonNumericNumbers` is enabled and `null` otherwise. | Value | allowNonNumericNumbers=true | allowNonNumericNumbers=false | | - | --- | | | NaN | Double.NaN | null | | +INF | Double.PositiveInfinity | null | | +Infinity | Double.PositiveInfinity | null | | Infinity | Double.PositiveInfinity | null | | -INF | Double.NegativeInfinity | null | | -Infinity | Double.NegativeInfinity | null | However, when these values are quoted we get the following unexpected behavior due to a different code path being used that is inconsistent with Jackson's parsing and that ignores the `allowNonNumericNumbers` parser option. | Value | allowNonNumericNumbers=true | allowNonNumericNumbers=false | | --- | --- | | | "NaN" | Double.NaN | Double.NaN | | "+INF" | null| null | | "+Infinity" | null| null | | "Infinity" | Double.PositiveInfinity | Double.PositiveInfinity | | "-INF" | null| null | | "-Infinity" | Double.NegativeInfinity | Double.NegativeInfinity | This PR updates the code path that handles quoted non-numeric numbers to make it consistent with the path that handles the unquoted values. ### Why are the changes needed? The current behavior does not match the documented behavior in https://spark.apache.org/docs/latest/sql-data-sources-json.html ### Does this PR introduce _any_ user-facing change? Yes, parsing of quoted `NaN` and `Infinity` values will now be consistent with the unquoted versions. ### How was this patch tested? Unit tests are updated. Closes #35573 from andygrove/SPARK-38060. Authored-by: Andy Grove Signed-off-by: Sean Owen --- docs/core-migration-guide.md | 2 ++ .../spark/sql/catalyst/json/JacksonParser.scala| 18 ++ .../datasources/json/JsonParsingOptionsSuite.scala | 39 ++ .../sql/execution/datasources/json/JsonSuite.scala | 6 4 files changed, 59 insertions(+), 6 deletions(-) diff --git a/docs/core-migration-guide.md b/docs/core-migration-guide.md index 745b80d..588433c 100644 --- a/docs/core-migration-guide.md +++ b/docs/core-migration-guide.md @@ -26,6 +26,8 @@ license: | - Since Spark 3.3, Spark migrates its log4j dependency from 1.x to 2.x because log4j 1.x has reached end of life and is no longer supported by the community. Vulnerabilities reported after August 2015 against log4j 1.x were not checked and will not be fixed. Users should rewrite original log4j properties files using log4j2 syntax (XML, JSON, YAML, or properties format). Spark rewrites the `conf/log4j.properties.template` which is included in Spark distribution, to `conf/log4j2.properties [...] +- Since Spark 3.3, when reading values from a JSON attribute defined as `FloatType` or `DoubleType`, the strings `"+Infinity"`, `"+INF"`, and `"-INF"` are now parsed to the appropriate values, in addition to the already supported `"Infinity"` and `"-Infinity"` variations. This change was made to improve consistency with Jackson's parsing of the unquoted versions of these values. Also, the `allowNonNumericNumbers` option is now respected so these strings will now be considered invalid if [...] + ## Upgrading from Core 3.1 to 3.2 - Since Spark 3.2, `spark.scheduler.allocation.file` supports read remote file using hadoop filesystem which means
[spark] branch master updated (ae67add -> 4789e1f)
This is an automated email from the ASF dual-hosted git repository. srowen pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git. from ae67add [MINOR][DOCS] fix default value of history server add 4789e1f [SPARK-37090][BUILD] Upgrade `libthrift` to 0.16.0 to avoid security vulnerabilities No new revisions were added by this update. Summary of changes: dev/deps/spark-deps-hadoop-2-hive-2.3 | 2 +- dev/deps/spark-deps-hadoop-3-hive-2.3 | 2 +- pom.xml| 6 +- .../hive/service/auth/KerberosSaslHelper.java | 5 +- .../apache/hive/service/auth/PlainSaslHelper.java | 3 +- .../hive/service/auth/TSetIpAddressProcessor.java | 5 +- .../service/cli/thrift/ThriftBinaryCLIService.java | 6 - .../hive/service/cli/thrift/ThriftCLIService.java | 10 ++ .../apache/thrift/transport/TFramedTransport.java | 200 + 9 files changed, 225 insertions(+), 14 deletions(-) create mode 100644 sql/hive/src/main/java/org/apache/thrift/transport/TFramedTransport.java - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated: [SPARK-38249][CORE][GRAPHX] Cleanup unused private methods/fields
This is an automated email from the ASF dual-hosted git repository.
srowen pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new 789a510 [SPARK-38249][CORE][GRAPHX] Cleanup unused private
methods/fields
789a510 is described below
commit 789a510c78ca81db0137bba1687102e2d9acd149
Author: yangjie01
AuthorDate: Sat Feb 19 09:04:01 2022 -0600
[SPARK-38249][CORE][GRAPHX] Cleanup unused private methods/fields
### What changes were proposed in this pull request?
This pr aims to cleanup unused ·`private methods/fields`.
### Why are the changes needed?
Code clean.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Pass GA
Closes #35566 from LuciferYang/never-used.
Authored-by: yangjie01
Signed-off-by: Sean Owen
---
core/src/main/scala/org/apache/spark/deploy/master/Master.scala | 9 +
.../org/apache/spark/executor/CoarseGrainedExecutorBackend.scala | 5 -
core/src/main/scala/org/apache/spark/rdd/NewHadoopRDD.scala | 1 -
.../src/main/scala/org/apache/spark/resource/ResourceUtils.scala | 1 -
.../src/main/scala/org/apache/spark/graphx/impl/GraphImpl.scala | 9 -
5 files changed, 1 insertion(+), 24 deletions(-)
diff --git a/core/src/main/scala/org/apache/spark/deploy/master/Master.scala
b/core/src/main/scala/org/apache/spark/deploy/master/Master.scala
index 7dbf6b9..775b27b 100644
--- a/core/src/main/scala/org/apache/spark/deploy/master/Master.scala
+++ b/core/src/main/scala/org/apache/spark/deploy/master/Master.scala
@@ -25,7 +25,7 @@ import scala.collection.mutable.{ArrayBuffer, HashMap,
HashSet}
import scala.util.Random
import org.apache.spark.{SecurityManager, SparkConf, SparkException}
-import org.apache.spark.deploy.{ApplicationDescription, DriverDescription,
ExecutorState, SparkHadoopUtil}
+import org.apache.spark.deploy.{ApplicationDescription, DriverDescription,
ExecutorState}
import org.apache.spark.deploy.DeployMessages._
import org.apache.spark.deploy.master.DriverState.DriverState
import org.apache.spark.deploy.master.MasterMessages._
@@ -53,8 +53,6 @@ private[deploy] class Master(
private val forwardMessageThread =
ThreadUtils.newDaemonSingleThreadScheduledExecutor("master-forward-message-thread")
- private val hadoopConf = SparkHadoopUtil.get.newConfiguration(conf)
-
// For application IDs
private def createDateFormat = new SimpleDateFormat("MMddHHmmss",
Locale.US)
@@ -95,11 +93,6 @@ private[deploy] class Master(
// After onStart, webUi will be set
private var webUi: MasterWebUI = null
- private val masterPublicAddress = {
-val envVar = conf.getenv("SPARK_PUBLIC_DNS")
-if (envVar != null) envVar else address.host
- }
-
private val masterUrl = address.toSparkURL
private var masterWebUiUrl: String = _
diff --git
a/core/src/main/scala/org/apache/spark/executor/CoarseGrainedExecutorBackend.scala
b/core/src/main/scala/org/apache/spark/executor/CoarseGrainedExecutorBackend.scala
index fb7b4e6..a94e636 100644
---
a/core/src/main/scala/org/apache/spark/executor/CoarseGrainedExecutorBackend.scala
+++
b/core/src/main/scala/org/apache/spark/executor/CoarseGrainedExecutorBackend.scala
@@ -42,7 +42,6 @@ import org.apache.spark.resource.ResourceUtils._
import org.apache.spark.rpc._
import org.apache.spark.scheduler.{ExecutorLossMessage, ExecutorLossReason,
TaskDescription}
import org.apache.spark.scheduler.cluster.CoarseGrainedClusterMessages._
-import org.apache.spark.serializer.SerializerInstance
import org.apache.spark.util.{ChildFirstURLClassLoader, MutableURLClassLoader,
SignalUtils, ThreadUtils, Utils}
private[spark] class CoarseGrainedExecutorBackend(
@@ -65,10 +64,6 @@ private[spark] class CoarseGrainedExecutorBackend(
var executor: Executor = null
@volatile var driver: Option[RpcEndpointRef] = None
- // If this CoarseGrainedExecutorBackend is changed to support multiple
threads, then this may need
- // to be changed so that we don't share the serializer instance across
threads
- private[this] val ser: SerializerInstance =
env.closureSerializer.newInstance()
-
private var _resources = Map.empty[String, ResourceInformation]
/**
diff --git a/core/src/main/scala/org/apache/spark/rdd/NewHadoopRDD.scala
b/core/src/main/scala/org/apache/spark/rdd/NewHadoopRDD.scala
index c6959a5..596298b 100644
--- a/core/src/main/scala/org/apache/spark/rdd/NewHadoopRDD.scala
+++ b/core/src/main/scala/org/apache/spark/rdd/NewHadoopRDD.scala
@@ -244,7 +244,6 @@ class NewHadoopRDD[K, V](
}
private var havePair = false
- private var recordsSinceMetricsUpdate = 0
override def hasNext: Boolean = {
if (!finished && !havePair) {
diff --git a/core/src/main/scala/org/apache/spark/resource/Resource
[spark] branch master updated (157dc7f -> 06f4ce4)
This is an automated email from the ASF dual-hosted git repository. srowen pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git. from 157dc7f [SPARK-37428][PYTHON][MLLIB] Inline type hints for pyspark.mllib.util add 06f4ce4 [SPARK-38175][CORE][FOLLOWUP] Remove `urlPattern` from `HistoryAppStatusStore#replaceLogUrls` method signature No new revisions were added by this update. Summary of changes: .../spark/deploy/history/HistoryAppStatusStore.scala | 16 +--- 1 file changed, 9 insertions(+), 7 deletions(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated: [SPARK-38243][PYTHON][ML] Fix pyspark.ml.LogisticRegression.getThreshold error message logic
This is an automated email from the ASF dual-hosted git repository.
srowen pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new 4399755 [SPARK-38243][PYTHON][ML] Fix
pyspark.ml.LogisticRegression.getThreshold error message logic
4399755 is described below
commit 439975590cf4f21c2a548a2ac6231eb234e1a2f3
Author: zero323
AuthorDate: Fri Feb 18 11:08:33 2022 -0600
[SPARK-38243][PYTHON][ML] Fix pyspark.ml.LogisticRegression.getThreshold
error message logic
### What changes were proposed in this pull request?
This PR replaces incorrect usage of `str.join` on a `List[float]` in
`LogisticRegression.getThreshold`.
### Why are the changes needed?
To avoid unexpected failure if method is used in case of multi-class
classification.
After this change, the following code:
```python
from pyspark.ml.classification import LogisticRegression
LogisticRegression(thresholds=[1.0, 2.0, 3.0]).getThreshold()
```
raises
```python
Traceback (most recent call last):
Input In [4] in
model.getThreshold()
File /path/to/spark/python/pyspark/ml/classification.py:999 in
getThreshold
raise ValueError(
ValueError: Logistic Regression getThreshold only applies to binary
classification, but thresholds has length != 2. thresholds: [1.0, 2.0, 3.0]
```
instead of current
```python
Traceback (most recent call last):
Input In [7] in
model.getThreshold()
File /path/to/spark/python/pyspark/ml/classification.py:1003 in
getThreshold
+ ",".join(ts)
TypeError: sequence item 0: expected str instance, float found
```
### Does this PR introduce _any_ user-facing change?
No. Bugfix.
### How was this patch tested?
Manual testing.
Closes #35558 from zero323/SPARK-38243.
Authored-by: zero323
Signed-off-by: Sean Owen
---
python/pyspark/ml/classification.py | 3 +--
1 file changed, 1 insertion(+), 2 deletions(-)
diff --git a/python/pyspark/ml/classification.py
b/python/pyspark/ml/classification.py
index 058740e..b791e6f 100644
--- a/python/pyspark/ml/classification.py
+++ b/python/pyspark/ml/classification.py
@@ -999,8 +999,7 @@ class _LogisticRegressionParams(
raise ValueError(
"Logistic Regression getThreshold only applies to"
+ " binary classification, but thresholds has length != 2."
-+ " thresholds: "
-+ ",".join(ts)
++ " thresholds: {ts}".format(ts=ts)
)
return 1.0 / (1.0 + ts[0] / ts[1])
else:
-
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated: [SPARK-38197][CORE] Improve error message of BlockManager.fetchRemoteManagedBuffer
This is an automated email from the ASF dual-hosted git repository.
srowen pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new 3022fd4 [SPARK-38197][CORE] Improve error message of
BlockManager.fetchRemoteManagedBuffer
3022fd4 is described below
commit 3022fd4ccfed676d4ba194afbfde2dd5ec1d348f
Author: Angerszh
AuthorDate: Thu Feb 17 19:52:16 2022 -0600
[SPARK-38197][CORE] Improve error message of
BlockManager.fetchRemoteManagedBuffer
### What changes were proposed in this pull request?
When locations's size is 1, and fetch failed, it only will print a error
message like
```
22/02/13 18:58:11 WARN BlockManager: Failed to fetch block after 1 fetch
failures. Most recent failure cause:
java.lang.IllegalStateException: Empty buffer received for non empty block
at
org.apache.spark.storage.BlockManager.fetchRemoteManagedBuffer(BlockManager.scala:1063)
at
org.apache.spark.storage.BlockManager.$anonfun$getRemoteBlock$8(BlockManager.scala:1005)
at scala.Option.orElse(Option.scala:447)
at
org.apache.spark.storage.BlockManager.getRemoteBlock(BlockManager.scala:1005)
at
org.apache.spark.storage.BlockManager.getRemoteValues(BlockManager.scala:951)
at org.apache.spark.storage.BlockManager.get(BlockManager.scala:1168)
at
org.apache.spark.storage.BlockManager.getOrElseUpdate(BlockManager.scala:1230)
at org.apache.spark.rdd.RDD.getOrCompute(RDD.scala:384)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:335)
at
org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:52)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:373)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:337)
at
org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:52)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:373)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:337)
at
org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:52)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:373)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:337)
at
org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:52)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:373)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:337)
at
org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:52)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:373)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:337)
at
org.apache.spark.shuffle.ShuffleWriteProcessor.write(ShuffleWriteProcessor.scala:59)
at
org.apache.spark.scheduler.ShuffleMapTask.runTask(ShuffleMapTask.scala:99)
at
org.apache.spark.scheduler.ShuffleMapTask.runTask(ShuffleMapTask.scala:52)
at org.apache.spark.scheduler.Task.run(Task.scala:131)
at
org.apache.spark.executor.Executor$TaskRunner.$anonfun$run$3(Executor.scala:497)
at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1439)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:500)
at
java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at
java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
```
We don't know the target nm ip and block id. This pr improve the error
message to show necessary information
### Why are the changes needed?
Improve error message
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Not need
Closes #35505 from AngersZh/SPARK-38197.
Authored-by: Angerszh
Signed-off-by: Sean Owen
---
core/src/main/scala/org/apache/spark/storage/BlockManager.scala | 6 --
1 file changed, 4 insertions(+), 2 deletions(-)
diff --git a/core/src/main/scala/org/apache/spark/storage/BlockManager.scala
b/core/src/main/scala/org/apache/spark/storage/BlockManager.scala
index ec4dc77..7ae57f7 100644
--- a/core/src/main/scala/org/apache/spark/storage/BlockManager.scala
+++ b/core/src/main/scala/org/apache/spark/storage/BlockManager.scala
@@ -1143,7 +1143,8 @@ private[spark] class BlockManager(
val buf = blockTransferService.fetchBlockSync(loc.host, loc.port,
loc.executorId,
blockId.toString, tempFileManager)
if (blockSize > 0 && buf.size() == 0) {
- throw new IllegalStateException("Empty buffer received for non empty
block")
+ throw new IllegalStateException("Empty buffer received for non empty
block " +
+s"when fetching remote block $blockId from $loc")
}
[spark] branch master updated (50256bd -> 344fd5c)
This is an automated email from the ASF dual-hosted git repository. srowen pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git. from 50256bd [SPARK-38054][SQL] Supports list namespaces in JDBC v2 MySQL dialect add 344fd5c [MINOR][CORE] Fix the method description of refill No new revisions were added by this update. Summary of changes: core/src/main/java/org/apache/spark/io/NioBufferedFileInputStream.java | 2 +- 1 file changed, 1 insertion(+), 1 deletion(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated: [SPARK-37925][DOC] Update document to mention the workaround for YARN-11053
This is an automated email from the ASF dual-hosted git repository. srowen pushed a commit to branch master in repository https://gitbox.apache.org/repos/asf/spark.git The following commit(s) were added to refs/heads/master by this push: new 74ebef2 [SPARK-37925][DOC] Update document to mention the workaround for YARN-11053 74ebef2 is described below commit 74ebef243c18e7a8f32bf90ea75ab6afed9e3132 Author: Cheng Pan AuthorDate: Sat Feb 5 09:47:15 2022 -0600 [SPARK-37925][DOC] Update document to mention the workaround for YARN-11053 ### What changes were proposed in this pull request? Update document "Running multiple versions of the Spark Shuffle Service" to mention the workaround for YARN-11053 ### Why are the changes needed? User may stuck when they following the current document to deploy multi-versions Spark Shuffle Service on YARN because of [YARN-11053](https://issues.apache.org/jira/browse/YARN-11053) ### Does this PR introduce _any_ user-facing change? User document changes. ### How was this patch tested?  Closes #35223 from pan3793/SPARK-37925. Authored-by: Cheng Pan Signed-off-by: Sean Owen --- docs/running-on-yarn.md | 9 ++--- 1 file changed, 6 insertions(+), 3 deletions(-) diff --git a/docs/running-on-yarn.md b/docs/running-on-yarn.md index c55ce86..63c0376 100644 --- a/docs/running-on-yarn.md +++ b/docs/running-on-yarn.md @@ -916,9 +916,12 @@ support the ability to run shuffle services within an isolated classloader can coexist within a single NodeManager. The `yarn.nodemanager.aux-services..classpath` and, starting from YARN 2.10.2/3.1.1/3.2.0, `yarn.nodemanager.aux-services..remote-classpath` options can be used to configure -this. In addition to setting up separate classpaths, it's necessary to ensure the two versions -advertise to different ports. This can be achieved using the `spark-shuffle-site.xml` file described -above. For example, you may have configuration like: +this. Note that YARN 3.3.0/3.3.1 have an issue which requires setting +`yarn.nodemanager.aux-services..system-classes` as a workaround. See +[YARN-11053](https://issues.apache.org/jira/browse/YARN-11053) for details. In addition to setting +up separate classpaths, it's necessary to ensure the two versions advertise to different ports. +This can be achieved using the `spark-shuffle-site.xml` file described above. For example, you may +have configuration like: ```properties yarn.nodemanager.aux-services = spark_shuffle_x,spark_shuffle_y - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark-website] branch asf-site updated: Contribution guide to document actual guide for pull requests
This is an automated email from the ASF dual-hosted git repository. srowen pushed a commit to branch asf-site in repository https://gitbox.apache.org/repos/asf/spark-website.git The following commit(s) were added to refs/heads/asf-site by this push: new 991df19 Contribution guide to document actual guide for pull requests 991df19 is described below commit 991df1959e2381dfd32dadce39cbfa2be80ec0c6 Author: khalidmammadov AuthorDate: Fri Feb 4 17:07:55 2022 -0600 Contribution guide to document actual guide for pull requests Currently contribution guide does not reflect actual flow to raise a new PR and hence it's not clear (for a new contributors) what exactly needs to be done to make a PR for Spark repository and test it as per expectation. This PR addresses that by following: - It describes in the Pull request section of the Contributing page the actual procedure and takes a contributor through a step by step process. - It removes optional "Running tests in your forked repository" section on Developer Tools page which is obsolete now and doesn't reflect reality anymore i.e. it says we can test by clicking “Run workflow” button which is not available anymore as workflow does not use "workflow_dispatch" event trigger anymore and was removed in https://github.com/apache/spark/pull/32092 - Instead it documents the new procedure that above PR introduced i.e. contributors needs to use their own GitHub free workflow credits to test new changes they are purposing and a Spark Actions workflow will expect that to be completed before marking PR to be ready for a review. - Some general wording was copied from "Running tests in your forked repository" section on Developer Tools page but main content was rewritten to meet objective - Also fixed URL to developer-tools.html to be resolved by parser (that converted it into relative URI) instead of using hard coded absolute URL. Tested imperically with `bundle exec jekyll serve` and static files were generated with `bundle exec jekyll build` commands This closes https://issues.apache.org/jira/browse/SPARK-37996 Author: khalidmammadov Closes #378 from khalidmammadov/fix_contribution_workflow_guide. --- contributing.md| 21 +++-- developer-tools.md | 17 - images/running-tests-using-github-actions.png | Bin 312696 -> 0 bytes site/contributing.html | 18 +- site/developer-tools.html | 19 --- site/images/running-tests-using-github-actions.png | Bin 312696 -> 0 bytes 6 files changed, 28 insertions(+), 47 deletions(-) diff --git a/contributing.md b/contributing.md index d5f0142..b127afe 100644 --- a/contributing.md +++ b/contributing.md @@ -322,9 +322,16 @@ Example: `Fix typos in Foo scaladoc` Pull request +Before creating a pull request in Apache Spark, it is important to check if tests can pass on your branch because +our GitHub Actions workflows automatically run tests for your pull request/following commits +and every run burdens the limited resources of GitHub Actions in Apache Spark repository. +Below steps will take your through the process. + + 1. https://help.github.com/articles/fork-a-repo/;>Fork the GitHub repository at https://github.com/apache/spark;>https://github.com/apache/spark if you haven't already -1. Clone your fork, create a new branch, push commits to the branch. +1. Go to "Actions" tab on your forked repository and enable "Build and test" and "Report test results" workflows +1. Clone your fork and create a new branch 1. Consider whether documentation or tests need to be added or updated as part of the change, and add them as needed. 1. When you add tests, make sure the tests are self-descriptive. @@ -355,14 +362,16 @@ and add them as needed. ... ``` 1. Consider whether benchmark results should be added or updated as part of the change, and add them as needed by -https://spark.apache.org/developer-tools.html#github-workflow-benchmarks;>Running benchmarks in your forked repository +Running benchmarks in your forked repository to generate benchmark results. 1. Run all tests with `./dev/run-tests` to verify that the code still compiles, passes tests, and -passes style checks. Alternatively you can run the tests via GitHub Actions workflow by -https://spark.apache.org/developer-tools.html#github-workflow-tests;>Running tests in your forked repository. +passes style checks. If style checks fail, review the Code Style Guide below. +1. Push commits to your branch. This will trigger "Build and test" and "Report test results" workflows +on your forked repository and start testing and validating you
[spark] branch master updated (7a613ec -> 54b11fa)
This is an automated email from the ASF dual-hosted git repository. srowen pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git. from 7a613ec [SPARK-38100][SQL] Remove unused private method in `Decimal` add 54b11fa [MINOR] Remove unnecessary null check for exception cause No new revisions were added by this update. Summary of changes: .../src/main/java/org/apache/spark/network/shuffle/ErrorHandler.java | 4 ++-- .../org/apache/spark/network/shuffle/RetryingBlockTransferor.java | 2 +- 2 files changed, 3 insertions(+), 3 deletions(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated: [SPARK-37984][SHUFFLE] Avoid calculating all outstanding requests to improve performance
This is an automated email from the ASF dual-hosted git repository.
srowen pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new f8ff786 [SPARK-37984][SHUFFLE] Avoid calculating all outstanding
requests to improve performance
f8ff786 is described below
commit f8ff7863e792b833afb2ff603878f29d4a9888e6
Author: weixiuli
AuthorDate: Sun Jan 23 20:23:20 2022 -0600
[SPARK-37984][SHUFFLE] Avoid calculating all outstanding requests to
improve performance
### What changes were proposed in this pull request?
Avoid calculating all outstanding requests to improve performance.
### Why are the changes needed?
Follow the comment
(https://github.com/apache/spark/pull/34711#pullrequestreview-835520984) , we
can implement a "has outstanding requests" method in the response handler that
doesn't even need to get a count,let's do this with PR.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Exist unittests.
Closes #35276 from weixiuli/SPARK-37984.
Authored-by: weixiuli
Signed-off-by: Sean Owen
---
.../apache/spark/network/client/TransportResponseHandler.java | 10 --
.../apache/spark/network/server/TransportChannelHandler.java | 3 +--
2 files changed, 9 insertions(+), 4 deletions(-)
diff --git
a/common/network-common/src/main/java/org/apache/spark/network/client/TransportResponseHandler.java
b/common/network-common/src/main/java/org/apache/spark/network/client/TransportResponseHandler.java
index 576c088..261f205 100644
---
a/common/network-common/src/main/java/org/apache/spark/network/client/TransportResponseHandler.java
+++
b/common/network-common/src/main/java/org/apache/spark/network/client/TransportResponseHandler.java
@@ -140,7 +140,7 @@ public class TransportResponseHandler extends
MessageHandler {
@Override
public void channelInactive() {
-if (numOutstandingRequests() > 0) {
+if (hasOutstandingRequests()) {
String remoteAddress = getRemoteAddress(channel);
logger.error("Still have {} requests outstanding when connection from {}
is closed",
numOutstandingRequests(), remoteAddress);
@@ -150,7 +150,7 @@ public class TransportResponseHandler extends
MessageHandler {
@Override
public void exceptionCaught(Throwable cause) {
-if (numOutstandingRequests() > 0) {
+if (hasOutstandingRequests()) {
String remoteAddress = getRemoteAddress(channel);
logger.error("Still have {} requests outstanding when connection from {}
is closed",
numOutstandingRequests(), remoteAddress);
@@ -275,6 +275,12 @@ public class TransportResponseHandler extends
MessageHandler {
(streamActive ? 1 : 0);
}
+ /** Check if there are any outstanding requests (fetch requests + rpcs) */
+ public Boolean hasOutstandingRequests() {
+return streamActive || !outstandingFetches.isEmpty() ||
!outstandingRpcs.isEmpty() ||
+!streamCallbacks.isEmpty();
+ }
+
/** Returns the time in nanoseconds of when the last request was sent out. */
public long getTimeOfLastRequestNs() {
return timeOfLastRequestNs.get();
diff --git
a/common/network-common/src/main/java/org/apache/spark/network/server/TransportChannelHandler.java
b/common/network-common/src/main/java/org/apache/spark/network/server/TransportChannelHandler.java
index 275e64e..d197032 100644
---
a/common/network-common/src/main/java/org/apache/spark/network/server/TransportChannelHandler.java
+++
b/common/network-common/src/main/java/org/apache/spark/network/server/TransportChannelHandler.java
@@ -161,8 +161,7 @@ public class TransportChannelHandler extends
SimpleChannelInboundHandler
requestTimeoutNs;
if (e.state() == IdleState.ALL_IDLE && isActuallyOverdue) {
- boolean hasInFlightRequests =
responseHandler.numOutstandingRequests() > 0;
- if (hasInFlightRequests) {
+ if (responseHandler.hasOutstandingRequests()) {
String address = getRemoteAddress(ctx.channel());
logger.error("Connection to {} has been quiet for {} ms while
there are outstanding " +
"requests. Assuming connection is dead; please adjust" +
-
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: commits-h...@spark.apache.org