[GitHub] spark issue #22873: [SPARK-25866][ML] Update KMeans formatVersion
Github user WeichenXu123 commented on the issue: https://github.com/apache/spark/pull/22873 LGTM. Thanks! --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22764: [SPARK-25765][ML] Add training cost to BisectingKMeans s...
Github user WeichenXu123 commented on the issue: https://github.com/apache/spark/pull/22764 I think it can target for 3.0. since 2.4 will be released soon and this PR looks a little complex and need take some time to check carefully. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22764: [SPARK-25765][ML] Add training cost to BisectingK...
Github user WeichenXu123 commented on a diff in the pull request:
https://github.com/apache/spark/pull/22764#discussion_r228527916
--- Diff:
mllib/src/main/scala/org/apache/spark/mllib/clustering/BisectingKMeansModel.scala
---
@@ -225,13 +227,14 @@ object BisectingKMeansModel extends
Loader[BisectingKMeansModel] {
assert(formatVersion == thisFormatVersion)
val rootId = (metadata \ "rootId").extract[Int]
val distanceMeasure = (metadata \ "distanceMeasure").extract[String]
+ val trainingCost = (metadata \ "trainingCost").extract[Double]
--- End diff --
OK. After https://github.com/apache/spark/pull/22790 merged, I think this
PR can work.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22790: [SPARK-25793][ML]call SaveLoadV2_0.load for class...
Github user WeichenXu123 commented on a diff in the pull request:
https://github.com/apache/spark/pull/22790#discussion_r228215468
--- Diff:
mllib/src/main/scala/org/apache/spark/mllib/clustering/BisectingKMeansModel.scala
---
@@ -109,7 +109,7 @@ class BisectingKMeansModel private[clustering] (
@Since("2.0.0")
override def save(sc: SparkContext, path: String): Unit = {
-BisectingKMeansModel.SaveLoadV1_0.save(sc, this, path)
+BisectingKMeansModel.SaveLoadV2_0.save(sc, this, path)
}
override protected def formatVersion: String = "1.0"
--- End diff --
Oh, good catch! need change.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22790: [SPARK-25793][ML]call SaveLoadV2_0.load for classNameV2_...
Github user WeichenXu123 commented on the issue: https://github.com/apache/spark/pull/22790 LGTM. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22675: [SPARK-25347][ML][DOC] Spark datasource for image...
Github user WeichenXu123 commented on a diff in the pull request: https://github.com/apache/spark/pull/22675#discussion_r227193764 --- Diff: docs/ml-datasource.md --- @@ -0,0 +1,113 @@ +--- +layout: global +title: Data sources +displayTitle: Data sources +--- + +In this section, we introduce how to use data source in ML to load data. +Beside some general data sources such as Parquet, CSV, JSON and JDBC, we also provide some specific data source for ML. + +**Table of Contents** + +* This will become a table of contents (this text will be scraped). --- End diff -- Yes. This keep the same with other ML algo page. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22793: [SPARK-25793][ML]Call SaveLoadV2_0.load for classNameV2_...
Github user WeichenXu123 commented on the issue: https://github.com/apache/spark/pull/22793 LGTM pending on Jenkins pass. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22764: [SPARK-25765][ML] Add training cost to BisectingK...
Github user WeichenXu123 commented on a diff in the pull request:
https://github.com/apache/spark/pull/22764#discussion_r226826701
--- Diff:
mllib/src/main/scala/org/apache/spark/mllib/clustering/BisectingKMeansModel.scala
---
@@ -225,13 +227,14 @@ object BisectingKMeansModel extends
Loader[BisectingKMeansModel] {
assert(formatVersion == thisFormatVersion)
val rootId = (metadata \ "rootId").extract[Int]
val distanceMeasure = (metadata \ "distanceMeasure").extract[String]
+ val trainingCost = (metadata \ "trainingCost").extract[Double]
--- End diff --
@mgaido91
(I haven't test this, so correct me if I am wrong).
> I don't see (and think) this change breaks backwards compatibility for
mllib.
I am suspicious of this line:
```
val trainingCost = (metadata \ "trainingCost").extract[Double]
```
When loading an old version spark saved `BisectingKMeansModel`, because it
do not contain "trainingCost" info, I guess this line will throw error.
(Otherwise what will it return ?)
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22780: [DOC][MINOR] Fix minor error in the code of graph...
GitHub user WeichenXu123 opened a pull request: https://github.com/apache/spark/pull/22780 [DOC][MINOR] Fix minor error in the code of graphx guide ## What changes were proposed in this pull request? Fix minor error in the code "sketch of pregel implementation" of GraphX guide ## How was this patch tested? N/A You can merge this pull request into a Git repository by running: $ git pull https://github.com/WeichenXu123/spark minor_doc_update1 Alternatively you can review and apply these changes as the patch at: https://github.com/apache/spark/pull/22780.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #22780 commit 35c77a5ef7b493ac0973ce0af6a66cbdbbbc749b Author: WeichenXu Date: 2018-10-20T02:52:38Z init pr --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22764: [SPARK-25765][ML] Add training cost to BisectingK...
Github user WeichenXu123 commented on a diff in the pull request:
https://github.com/apache/spark/pull/22764#discussion_r226812121
--- Diff:
mllib/src/main/scala/org/apache/spark/mllib/clustering/BisectingKMeansModel.scala
---
@@ -225,13 +227,14 @@ object BisectingKMeansModel extends
Loader[BisectingKMeansModel] {
assert(formatVersion == thisFormatVersion)
val rootId = (metadata \ "rootId").extract[Int]
val distanceMeasure = (metadata \ "distanceMeasure").extract[String]
+ val trainingCost = (metadata \ "trainingCost").extract[Double]
--- End diff --
@mgaido91
What about this way ?
In `ml` reader, we can load `trainingCost` and then construct
`mllib.clustering.BisectingKMeansModel` and pass the `trainingCost` argument
and then construct `ml.clustering.BisectingKMeansModel` to wrap that `mllib`
model.
** Then in `ml` reader we can check the spark major/minor version to keep
backwards compatibility, this is a more important thing. **
** In `mllib` loader we can ignore loading `trainingCost`, because `mllib`
is deprecate, we can ignore adding new features, but we cannot breaking
backwards compatibility (your change breaking backwards compatibility). **
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22764: [SPARK-25765][ML] Add training cost to BisectingK...
Github user WeichenXu123 commented on a diff in the pull request:
https://github.com/apache/spark/pull/22764#discussion_r226520698
--- Diff:
mllib/src/main/scala/org/apache/spark/mllib/clustering/BisectingKMeansModel.scala
---
@@ -225,13 +227,14 @@ object BisectingKMeansModel extends
Loader[BisectingKMeansModel] {
assert(formatVersion == thisFormatVersion)
val rootId = (metadata \ "rootId").extract[Int]
val distanceMeasure = (metadata \ "distanceMeasure").extract[String]
+ val trainingCost = (metadata \ "trainingCost").extract[Double]
--- End diff --
- Could you avoid modifying loading model code in "mllib" package, but
modifying code in "ml" package, i.e., the class
`ml.clustering.BisectingKMeansModel.BisectingKMeansModelReader`, you can
reference the `KMeans` code: `ml.clustering.KMeansModel.KMeansModelReader`.
- And, +1 with @viirya mentioned, we should keep model loading
compatibility, add a version check (when >= 2.4) then we load "training cost" .
Note that add these in
`ml.clustering.BisectingKMeansModel.BisectingKMeansModelReader`.
- And, could you also add version check (when >= 2.4) then we load
"training cost" into `ml.clustering.KMeansModel.KMeansModelReader` ?
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22763: [SPARK-25764][ML][EXAMPLES] Update BisectingKMeans examp...
Github user WeichenXu123 commented on the issue: https://github.com/apache/spark/pull/22763 LGTM. thanks! --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22756: [SPARK-25758][ML] Deprecate computeCost on BisectingKMea...
Github user WeichenXu123 commented on the issue: https://github.com/apache/spark/pull/22756 LGTM. thanks! --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22675: [SPARK-25347][ML][DOC] Spark datasource for image...
Github user WeichenXu123 commented on a diff in the pull request: https://github.com/apache/spark/pull/22675#discussion_r226379993 --- Diff: docs/ml-datasource.md --- @@ -0,0 +1,90 @@ +--- +layout: global +title: Data sources +displayTitle: Data sources --- End diff -- Data sources. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22675: [SPARK-25347][ML][DOC] Spark datasource for image...
Github user WeichenXu123 commented on a diff in the pull request:
https://github.com/apache/spark/pull/22675#discussion_r226161636
--- Diff: docs/ml-datasource.md ---
@@ -0,0 +1,49 @@
+---
+layout: global
+title: Data sources
+displayTitle: Data sources
+---
+
+In this section, we introduce how to use data source in ML to load data.
+Beside some general data sources like Parquet, CSV, JSON, JDBC, we also
provide some specific data source for ML.
+
+**Table of Contents**
+
+* This will become a table of contents (this text will be scraped).
+{:toc}
+
+## Image data source
+
+This image data source is used to load image files from a directory.
+The loaded DataFrame has one StructType column: "image". containing image
data stored as image schema.
--- End diff --
added.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22675: [SPARK-25347][ML][DOC] Spark datasource for image...
Github user WeichenXu123 commented on a diff in the pull request:
https://github.com/apache/spark/pull/22675#discussion_r226161623
--- Diff: docs/ml-datasource.md ---
@@ -0,0 +1,49 @@
+---
+layout: global
+title: Data sources
+displayTitle: Data sources
+---
+
+In this section, we introduce how to use data source in ML to load data.
+Beside some general data sources like Parquet, CSV, JSON, JDBC, we also
provide some specific data source for ML.
+
+**Table of Contents**
+
+* This will become a table of contents (this text will be scraped).
+{:toc}
+
+## Image data source
+
+This image data source is used to load image files from a directory.
+The loaded DataFrame has one StructType column: "image". containing image
data stored as image schema.
--- End diff --
added.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22675: [SPARK-25347][ML][DOC] Spark datasource for image...
Github user WeichenXu123 commented on a diff in the pull request:
https://github.com/apache/spark/pull/22675#discussion_r226161557
--- Diff: docs/ml-datasource.md ---
@@ -0,0 +1,49 @@
+---
+layout: global
+title: Data sources
+displayTitle: Data sources
+---
+
+In this section, we introduce how to use data source in ML to load data.
+Beside some general data sources like Parquet, CSV, JSON, JDBC, we also
provide some specific data source for ML.
+
+**Table of Contents**
+
+* This will become a table of contents (this text will be scraped).
+{:toc}
+
+## Image data source
+
+This image data source is used to load image files from a directory.
+The loaded DataFrame has one StructType column: "image". containing image
data stored as image schema.
+
+
+
+[`ImageDataSource`](api/scala/index.html#org.apache.spark.ml.source.image.ImageDataSource)
+implements a Spark SQL data source API for loading image data as a
DataFrame.
+
+{% highlight scala %}
+scala> spark.read.format("image").load("data/mllib/images/origin")
+res1: org.apache.spark.sql.DataFrame = [image: struct]
+{% endhighlight %}
+
+
+
+[`ImageDataSource`](api/java/org/apache/spark/ml/source/image/ImageDataSource.html)
+implements Spark SQL data source API for loading image data as DataFrame.
+
+{% highlight java %}
+Dataset imagesDF =
spark.read().format("image").load("data/mllib/images/origin");
+{% endhighlight %}
+
+
+
--- End diff --
This looks like SQL features and fit all datasources. Put it in spark SQL
doc will be better.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22675: [SPARK-25347][ML][DOC] Spark datasource for image/libsvm...
Github user WeichenXu123 commented on the issue: https://github.com/apache/spark/pull/22675 This do not block 2.4 release. But merge before 2.4 is better. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22675: [SPARK-25347][ML][DOC] Spark datasource for image...
GitHub user WeichenXu123 opened a pull request: https://github.com/apache/spark/pull/22675 [SPARK-25347][ML][DOC] Spark datasource for image/libsvm user guide ## What changes were proposed in this pull request? Spark datasource for image/libsvm user guide ## How was this patch tested? Scala: 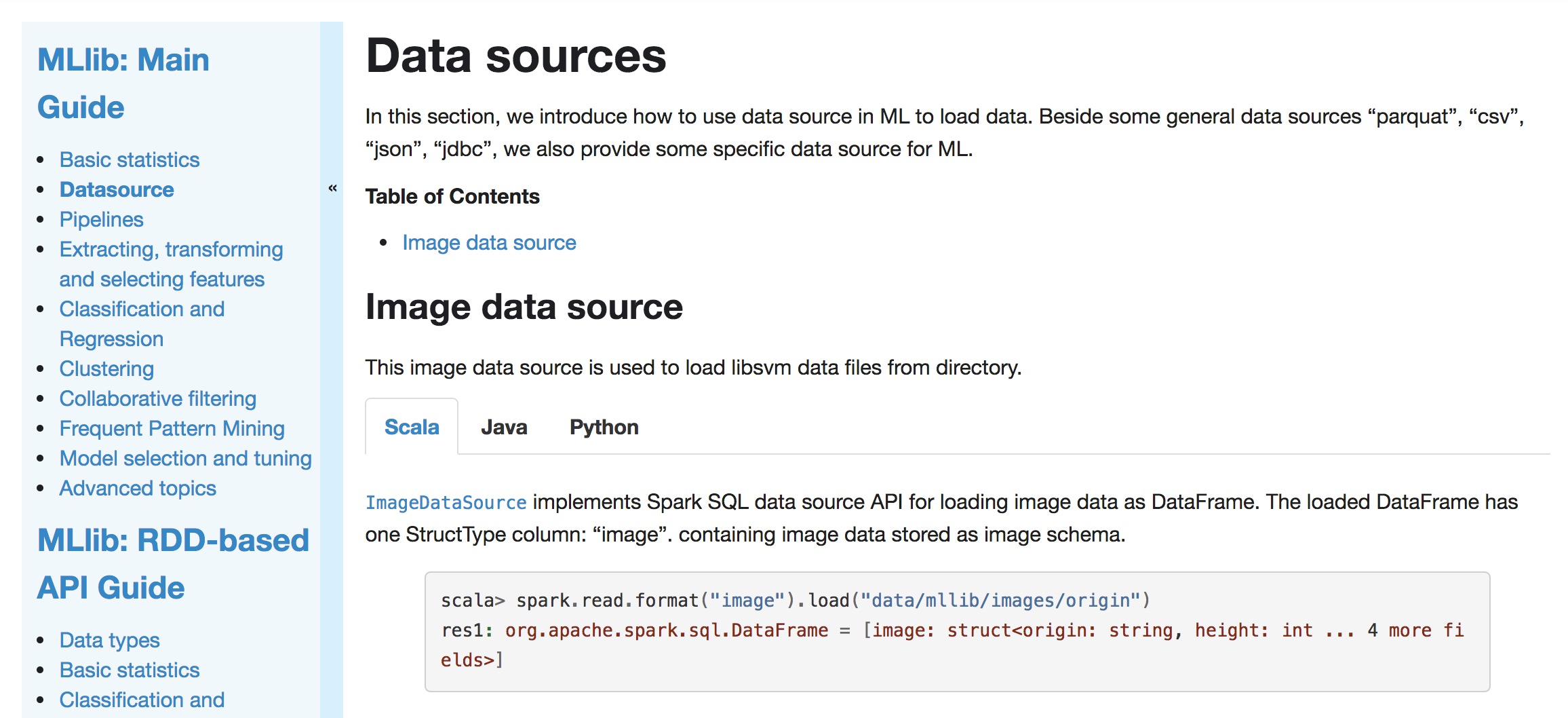 Java: 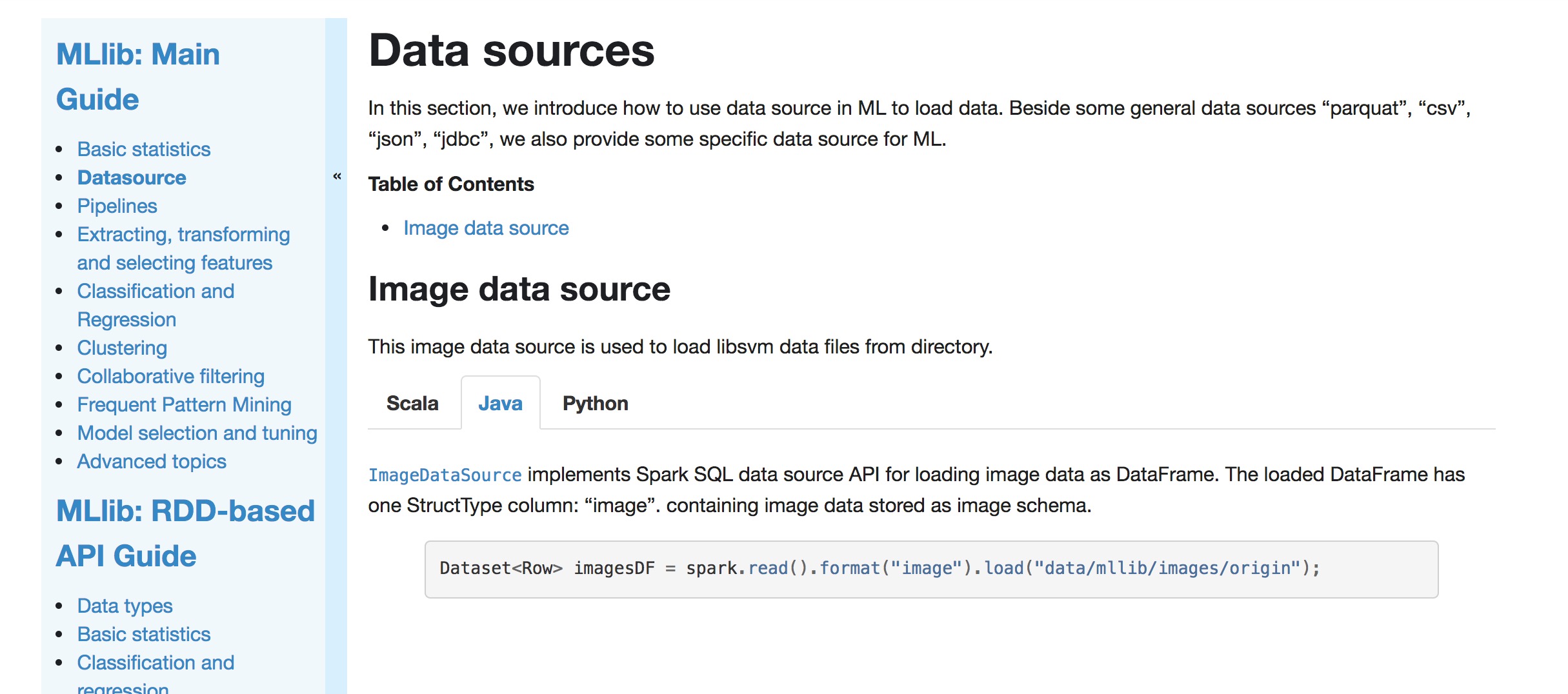 Python: 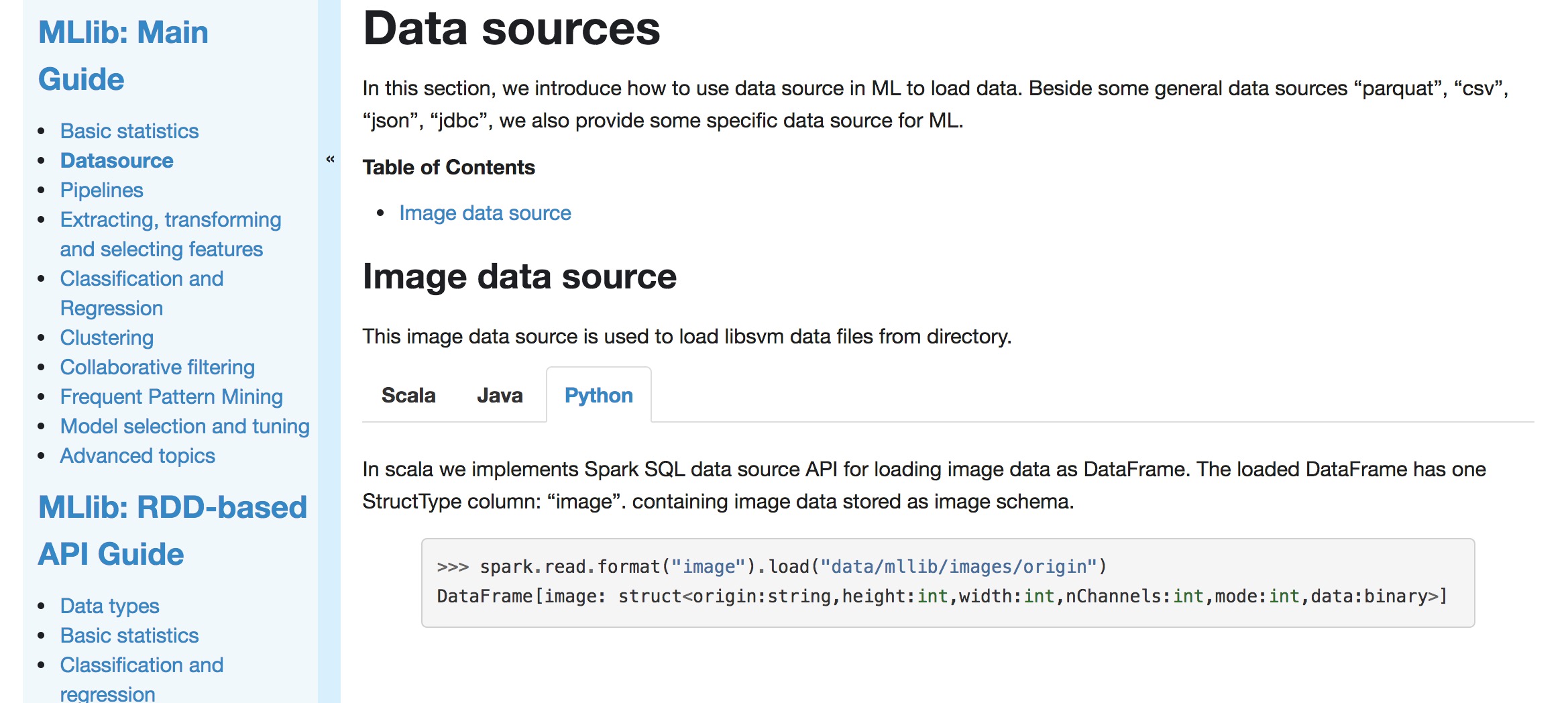 You can merge this pull request into a Git repository by running: $ git pull https://github.com/WeichenXu123/spark add_image_source_doc Alternatively you can review and apply these changes as the patch at: https://github.com/apache/spark/pull/22675.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #22675 commit 887f5282fba8a8a0bcbb9242eb87b27bf94d0210 Author: WeichenXu Date: 2018-10-09T02:54:09Z init --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22618: [SPARK-25321][ML] Revert SPARK-14681 to avoid API breaki...
Github user WeichenXu123 commented on the issue: https://github.com/apache/spark/pull/22618 LGTM. Thanks! --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22492: [SPARK-25321][ML] Revert SPARK-14681 to avoid API...
Github user WeichenXu123 closed the pull request at: https://github.com/apache/spark/pull/22492 --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22510: [SPARK-25321][ML] Fix local LDA model constructor
GitHub user WeichenXu123 opened a pull request: https://github.com/apache/spark/pull/22510 [SPARK-25321][ML] Fix local LDA model constructor ## What changes were proposed in this pull request? change back the constructor to: ``` class LocalLDAModel private[ml] ( uid: String, vocabSize: Int, private[clustering] val oldLocalModel : OldLocalLDAModel, sparkSession: SparkSession) ``` Although it is marked `private[ml]`, it is used in `mleap` and the master change breaks `mleap` building. ## How was this patch tested? Manual. You can merge this pull request into a Git repository by running: $ git pull https://github.com/WeichenXu123/spark LDA_fix Alternatively you can review and apply these changes as the patch at: https://github.com/apache/spark/pull/22510.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #22510 commit 2b2fdaf3f7598fe31161fdd4401728d6b314bbfe Author: WeichenXu Date: 2018-09-21T03:03:30Z init pr --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22492: [SPARK-25321][ML] Revert SPARK-14681 to avoid API breaki...
Github user WeichenXu123 commented on the issue: https://github.com/apache/spark/pull/22492 @mengxr Should this be put into master ? --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22492: [SPARK-25321][ML] Revert SPARK-14681 to avoid API...
GitHub user WeichenXu123 opened a pull request: https://github.com/apache/spark/pull/22492 [SPARK-25321][ML] Revert SPARK-14681 to avoid API breaking change ## What changes were proposed in this pull request? Revert SPARK-14681 to avoid API breaking change. PR [SPARK-14681] will break mleap. ## How was this patch tested? N/A You can merge this pull request into a Git repository by running: $ git pull https://github.com/WeichenXu123/spark revert_tree_change Alternatively you can review and apply these changes as the patch at: https://github.com/apache/spark/pull/22492.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #22492 commit d976a7e8646a61bfb76f417f11557f25cc9e Author: WeichenXu Date: 2018-09-20T11:56:04Z Revert "[SPARK-14681][ML] Provide label/impurity stats for spark.ml decision tree nodes" This reverts commit 252468a744b95082400ba9e8b2e3b3d9d50ab7fa. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22449: [SPARK-22666][ML][FOLLOW-UP] Return a correctly f...
GitHub user WeichenXu123 opened a pull request: https://github.com/apache/spark/pull/22449 [SPARK-22666][ML][FOLLOW-UP] Return a correctly formatted URI for invalid images ## What changes were proposed in this pull request? Change the URI returned in ImageFileFormat for an invalid image row. ## How was this patch tested? N/A You can merge this pull request into a Git repository by running: $ git pull https://github.com/WeichenXu123/spark image_url Alternatively you can review and apply these changes as the patch at: https://github.com/apache/spark/pull/22449.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #22449 commit a91f0a8cdb98fa6bdb1438a425df859250c53356 Author: WeichenXu Date: 2018-09-18T10:18:32Z init pr --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22360: [MINOR][ML] Remove `BisectingKMeansModel.setDistanceMeas...
Github user WeichenXu123 commented on the issue: https://github.com/apache/spark/pull/22360 Do we need to set `distanceMeasure` again for the parent model ? When parent model created, it will use the same `distanceMeasure` with the one used in training. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22349: [SPARK-25345][ML] Deprecate public APIs from Imag...
Github user WeichenXu123 commented on a diff in the pull request:
https://github.com/apache/spark/pull/22349#discussion_r216117396
--- Diff: python/pyspark/ml/image.py ---
@@ -207,6 +207,9 @@ def readImages(self, path, recursive=False,
numPartitions=-1,
.. note:: If sample ratio is less than 1, sampling uses a
PathFilter that is efficient but
potentially non-deterministic.
+.. note:: Deprecated in 2.4.0. Use
`spark.read.format("image").load(path)` instead and
--- End diff --
added.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22360: [MINOR][ML] Remove `BisectingKMeansModel.setDistanceMeas...
Github user WeichenXu123 commented on the issue:
https://github.com/apache/spark/pull/22360
@srowen The delegated `mllib.BisectingKMeansModel` is:
```
class BisectingKMeansModel private[clustering] (
private[clustering] val root: ClusteringTreeNode,
@Since("2.4.0") val distanceMeasure: String
) extends...
```
its constructor argument `distanceMeasure` is immutable and the
`setDistanceMeasure` here only change the wrapper model's param and it effect
nothing.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22360: [MINOR][ML] Remove `BisectingKMeansModel.setDista...
GitHub user WeichenXu123 opened a pull request: https://github.com/apache/spark/pull/22360 [MINOR][ML] Remove `BisectingKMeansModel.setDistanceMeasure` method ## What changes were proposed in this pull request? Remove `BisectingKMeansModel.setDistanceMeasure` method. In `BisectingKMeansModel` set this param is meaningless. ## How was this patch tested? N/A You can merge this pull request into a Git repository by running: $ git pull https://github.com/WeichenXu123/spark bkmeans_update Alternatively you can review and apply these changes as the patch at: https://github.com/apache/spark/pull/22360.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #22360 commit 64a1c278cb9fc53b4908b1194a79a82de8805c75 Author: WeichenXu Date: 2018-09-07T09:54:36Z init pr --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22349: [SPARK-25345][ML] Deprecate public APIs from Imag...
GitHub user WeichenXu123 opened a pull request: https://github.com/apache/spark/pull/22349 [SPARK-25345][ML] Deprecate public APIs from ImageSchema ## What changes were proposed in this pull request? Deprecate public APIs from ImageSchema. ## How was this patch tested? N/A You can merge this pull request into a Git repository by running: $ git pull https://github.com/WeichenXu123/spark image_api_deprecate Alternatively you can review and apply these changes as the patch at: https://github.com/apache/spark/pull/22349.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #22349 commit 23973218e73cd9ccafe07109cd066eee5aaef3cd Author: WeichenXu Date: 2018-09-06T09:58:14Z init pr --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22328: [SPARK-22666][ML][SQL] Spark datasource for image...
Github user WeichenXu123 commented on a diff in the pull request:
https://github.com/apache/spark/pull/22328#discussion_r215200249
--- Diff:
mllib/src/main/scala/org/apache/spark/ml/source/image/ImageOptions.scala ---
@@ -0,0 +1,28 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.ml.source.image
+
+import org.apache.spark.sql.catalyst.util.CaseInsensitiveMap
+
+private[image] class ImageOptions(
+@transient private val parameters: CaseInsensitiveMap[String]) extends
Serializable {
+
+ def this(parameters: Map[String, String]) =
this(CaseInsensitiveMap(parameters))
+
+ val dropImageFailures = parameters.getOrElse("dropImageFailures",
"false").toBoolean
--- End diff --
because `parameters` is `Map[String, String]` type.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22328: [SPARK-22666][ML][SQL] Spark datasource for image...
Github user WeichenXu123 commented on a diff in the pull request:
https://github.com/apache/spark/pull/22328#discussion_r215138998
--- Diff:
mllib/src/main/scala/org/apache/spark/ml/source/image/ImageDataSource.scala ---
@@ -0,0 +1,53 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.ml.source.image
+
+/**
+ * `image` package implements Spark SQL data source API for loading IMAGE
data as `DataFrame`.
+ * The loaded `DataFrame` has one `StructType` column: `image`.
+ * The schema of the `image` column is:
+ * - origin: String (represent the origin of image. If loaded from file,
then it is file path)
+ * - height: Int (height of image)
+ * - width: Int (width of image)
+ * - nChannels: Int (number of image channels)
+ * - mode: Int (OpenCV-compatible type)
+ * - data: BinaryType (Image bytes in OpenCV-compatible order: row-wise
BGR in most cases)
+ *
+ * To use IMAGE data source, you need to set "image" as the format in
`DataFrameReader` and
+ * optionally specify the datasource options, for example:
+ * {{{
+ * // Scala
+ * val df = spark.read.format("image")
+ * .option("dropImageFailures", "true")
+ * .load("data/mllib/images/imagesWithPartitions")
+ *
+ * // Java
+ * Dataset df = spark.read().format("image")
+ * .option("dropImageFailures", "true")
+ * .load("data/mllib/images/imagesWithPartitions");
+ * }}}
+ *
+ * IMAGE data source supports the following options:
+ * - "dropImageFailures": Whether to drop the files that are not valid
images from the result.
+ *
+ * @note This IMAGE data source does not support "write".
+ *
+ * @note This class is public for documentation purpose. Please don't use
this class directly.
+ * Rather, use the data source API as illustrated above.
+ */
+class ImageDataSource private() {}
--- End diff --
for doc.
similar to `LibSVMDataSource`
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22328: [SPARK-22666][ML][SQL] Spark datasource for image...
Github user WeichenXu123 commented on a diff in the pull request:
https://github.com/apache/spark/pull/22328#discussion_r215138889
--- Diff:
sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/DataSource.scala
---
@@ -567,6 +567,7 @@ object DataSource extends Logging {
val parquet = classOf[ParquetFileFormat].getCanonicalName
val csv = classOf[CSVFileFormat].getCanonicalName
val libsvm = "org.apache.spark.ml.source.libsvm.LibSVMFileFormat"
+val image = "org.apache.spark.ml.source.image.ImageFileFormat"
--- End diff --
similar to `libsvm`.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22328: [SPARK-22666][ML][SQL] Spark datasource for image...
Github user WeichenXu123 commented on a diff in the pull request:
https://github.com/apache/spark/pull/22328#discussion_r215138862
--- Diff:
mllib/src/test/scala/org/apache/spark/ml/source/image/ImageFileFormatSuite.scala
---
@@ -0,0 +1,119 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.ml.source.image
+
+import java.nio.file.Paths
+
+import org.apache.spark.SparkFunSuite
+import org.apache.spark.ml.image.ImageSchema._
+import org.apache.spark.mllib.util.MLlibTestSparkContext
+import org.apache.spark.sql.Row
+import org.apache.spark.sql.functions.{col, substring_index}
+
+class ImageFileFormatSuite extends SparkFunSuite with
MLlibTestSparkContext {
+
+ // Single column of images named "image"
+ private lazy val imagePath = "../data/mllib/images/imagesWithPartitions"
+
+ test("image datasource count test") {
+val df1 = spark.read.format("image").load(imagePath)
+assert(df1.count === 9)
+
+val df2 = spark.read.format("image").option("dropImageFailures",
"true").load(imagePath)
+assert(df2.count === 8)
+ }
+
+ test("image datasource test: read jpg image") {
+val df = spark.read.format("image").load(imagePath +
"/cls=kittens/date=2018-02/DP153539.jpg")
+assert(df.count() === 1)
+ }
+
+ test("image datasource test: read png image") {
+val df = spark.read.format("image").load(imagePath +
"/cls=multichannel/date=2018-01/BGRA.png")
+assert(df.count() === 1)
+ }
+
+ test("image datasource test: read non image") {
+val filePath = imagePath + "/cls=kittens/date=2018-01/not-image.txt"
+val df = spark.read.format("image").option("dropImageFailures", "true")
+ .load(filePath)
+assert(df.count() === 0)
+
+val df2 = spark.read.format("image").option("dropImageFailures",
"false")
+ .load(filePath)
+assert(df2.count() === 1)
+val result = df2.head()
+assert(result === invalidImageRow(
+ Paths.get(filePath).toAbsolutePath().normalize().toUri().toString))
+ }
+
+ test("image datasource partition test") {
+val result = spark.read.format("image")
+ .option("dropImageFailures", "true").load(imagePath)
+ .select(substring_index(col("image.origin"), "/", -1).as("origin"),
col("cls"), col("date"))
+ .collect()
+
+assert(Set(result: _*) === Set(
+ Row("29.5.a_b_EGDP022204.jpg", "kittens", "2018-01"),
+ Row("54893.jpg", "kittens", "2018-02"),
+ Row("DP153539.jpg", "kittens", "2018-02"),
+ Row("DP802813.jpg", "kittens", "2018-02"),
+ Row("BGRA.png", "multichannel", "2018-01"),
+ Row("BGRA_alpha_60.png", "multichannel", "2018-01"),
+ Row("chr30.4.184.jpg", "multichannel", "2018-02"),
+ Row("grayscale.jpg", "multichannel", "2018-02")
+))
+ }
+
+ // Images with the different number of channels
+ test("readImages pixel values test") {
+
+val images = spark.read.format("image").option("dropImageFailures",
"true")
+ .load(imagePath + "/cls=multichannel/").collect()
+
+val firstBytes20Map = images.map { rrow =>
+ val row = rrow.getAs[Row]("image")
+ val filename = Paths.get(getOrigin(row)).getFileName().toString()
+ val mode = getMode(row)
+ val bytes20 = getData(row).slice(0, 20).toList
+ filename -> Tuple2(mode, bytes20)
--- End diff --
yea, `(mode, bytes20)` doesn't work, `filename -> (mode, bytes20)` will be
compiled as `filename.->(mode, bytes20)` and `->` receive 2 arguments and
compile error occurs.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22328: [SPARK-22666][ML][SQL] Spark datasource for image...
Github user WeichenXu123 commented on a diff in the pull request:
https://github.com/apache/spark/pull/22328#discussion_r215138728
--- Diff:
mllib/src/test/scala/org/apache/spark/ml/source/image/ImageFileFormatSuite.scala
---
@@ -0,0 +1,119 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.ml.source.image
+
+import java.nio.file.Paths
+
+import org.apache.spark.SparkFunSuite
+import org.apache.spark.ml.image.ImageSchema._
+import org.apache.spark.mllib.util.MLlibTestSparkContext
+import org.apache.spark.sql.Row
+import org.apache.spark.sql.functions.{col, substring_index}
+
+class ImageFileFormatSuite extends SparkFunSuite with
MLlibTestSparkContext {
+
+ // Single column of images named "image"
+ private lazy val imagePath = "../data/mllib/images/imagesWithPartitions"
+
+ test("image datasource count test") {
+val df1 = spark.read.format("image").load(imagePath)
+assert(df1.count === 9)
+
+val df2 = spark.read.format("image").option("dropImageFailures",
"true").load(imagePath)
--- End diff --
ditto.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22328: [SPARK-22666][ML][SQL] Spark datasource for image...
Github user WeichenXu123 commented on a diff in the pull request:
https://github.com/apache/spark/pull/22328#discussion_r215138711
--- Diff:
mllib/src/main/scala/org/apache/spark/ml/source/image/ImageDataSource.scala ---
@@ -0,0 +1,51 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.ml.source.image
+
+/**
+ * `image` package implements Spark SQL data source API for loading IMAGE
data as `DataFrame`.
+ * The loaded `DataFrame` has one `StructType` column: `image`.
+ * The schema of the `image` column is:
+ * - origin: String (represent the origin of image. If loaded from file,
then it is file path)
+ * - height: Int (height of image)
+ * - width: Int (width of image)
+ * - nChannels: Int (number of image channels)
+ * - mode: Int (OpenCV-compatible type)
+ * - data: BinaryType (Image bytes in OpenCV-compatible order: row-wise
BGR in most cases)
+ *
+ * To use IMAGE data source, you need to set "image" as the format in
`DataFrameReader` and
+ * optionally specify options, for example:
+ * {{{
+ * // Scala
+ * val df = spark.read.format("image")
+ * .option("dropImageFailures", "true")
--- End diff --
option API require (k: String, v:String) parameters.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22328: [SPARK-22666][ML][SQL] Spark datasource for image...
Github user WeichenXu123 commented on a diff in the pull request: https://github.com/apache/spark/pull/22328#discussion_r215138174 --- Diff: data/mllib/images/images/license.txt --- @@ -0,0 +1,13 @@ +The images in the folder "kittens" are under the creative commons CC0 license, or no rights reserved: --- End diff -- No worry. Only very few images. And keep old testcase not changed will help this PR get merged ASAP. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22328: [SPARK-22666][ML][SQL] Spark datasource for image...
Github user WeichenXu123 commented on a diff in the pull request: https://github.com/apache/spark/pull/22328#discussion_r215135665 --- Diff: mllib/src/main/scala/org/apache/spark/ml/source/image/ImageDataSource.scala --- @@ -0,0 +1,51 @@ +/* + * Licensed to the Apache Software Foundation (ASF) under one or more + * contributor license agreements. See the NOTICE file distributed with + * this work for additional information regarding copyright ownership. + * The ASF licenses this file to You under the Apache License, Version 2.0 + * (the "License"); you may not use this file except in compliance with + * the License. You may obtain a copy of the License at + * + *http://www.apache.org/licenses/LICENSE-2.0 + * + * Unless required by applicable law or agreed to in writing, software + * distributed under the License is distributed on an "AS IS" BASIS, + * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. + * See the License for the specific language governing permissions and + * limitations under the License. + */ + +package org.apache.spark.ml.source.image + +/** + * `image` package implements Spark SQL data source API for loading IMAGE data as `DataFrame`. + * The loaded `DataFrame` has one `StructType` column: `image`. + * The schema of the `image` column is: + * - origin: String (represent the origin of image. If loaded from file, then it is file path) + * - height: Int (height of image) + * - width: Int (width of image) + * - nChannels: Int (number of image channels) + * - mode: Int (OpenCV-compatible type) + * - data: BinaryType (Image bytes in OpenCV-compatible order: row-wise BGR in most cases) + * + * To use IMAGE data source, you need to set "image" as the format in `DataFrameReader` and + * optionally specify options, for example: --- End diff -- The latter "options" is "datasource options", it is the widely used term. So I prefer to change to "optionally specify the datasource options" --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22328: [SPARK-22666][ML][SQL] Spark datasource for image...
GitHub user WeichenXu123 opened a pull request: https://github.com/apache/spark/pull/22328 [SPARK-22666][ML][SQL] Spark datasource for image format ## What changes were proposed in this pull request? Implement an image schema datasource. This image datasource support: - partition discovery (loading partitioned images) - dropImageFailures (the same behavior with `ImageSchema.readImage`) - path wildcard matching (the same behavior with `ImageSchema.readImage`) - loading recursively from directory (different from `ImageSchema.readImage`, but use such path: `/path/to/dir/**`) This datasource **NOT** support: - specify `numPartitions` (it will be determined by datasource automatically) - sampling (you can use `df.sample` later but the sampling operator won't be pushdown to datasource) ## How was this patch tested? Unit tests. ## Benchmark I benchmark and compare the cost time between old `ImageSchema.read` API and my image datasource. **cluster**: 4 nodes, each with 64GB memory, 8 cores CPU **test dataset**: Flickr8k_Dataset (about 8091 images) **time cost**: My image datasource time (automatically generate 258 partitions): 38.04s `ImageSchema.read` time (set 16 partitions): 68.4s `ImageSchema.read` time (set 258 partitions): 90.6s **time cost when increase image number by double (clone Flickr8k_Dataset and loads double number images): My image datasource time (automatically generate 515 partitions): 95.4s `ImageSchema.read` (set 32 partitions): 109s `ImageSchema.read` (set 515 partitions): 105s So we can see that my image datasource implementation (this PR) bring some performance improvement compared against old`ImageSchema.read` API. You can merge this pull request into a Git repository by running: $ git pull https://github.com/WeichenXu123/spark image_datasource Alternatively you can review and apply these changes as the patch at: https://github.com/apache/spark/pull/22328.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #22328 commit 5b5aee66b2ea819341b624164298f0700ee07ddf Author: WeichenXu Date: 2018-09-04T09:48:50Z init pr --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #19666: [SPARK-22451][ML] Reduce decision tree aggregate ...
Github user WeichenXu123 closed the pull request at: https://github.com/apache/spark/pull/19666 --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20446: [SPARK-23254][ML] Add user guide entry and example for D...
Github user WeichenXu123 commented on the issue: https://github.com/apache/spark/pull/20446 @srowen The reason I do not use `.show` I have already reply here https://github.com/apache/spark/pull/20446#discussion_r165565121 thanks! --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21513: [SPARK-19826][ML][PYTHON]add spark.ml Python API for PIC
Github user WeichenXu123 commented on the issue: https://github.com/apache/spark/pull/21513 LGTM. Thanks! @mengxr Would you mind take a look ? --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21513: [SPARK-19826][ML][PYTHON]add spark.ml Python API ...
Github user WeichenXu123 commented on a diff in the pull request:
https://github.com/apache/spark/pull/21513#discussion_r194214431
--- Diff: python/pyspark/ml/clustering.py ---
@@ -1156,6 +1157,204 @@ def getKeepLastCheckpoint(self):
return self.getOrDefault(self.keepLastCheckpoint)
+@inherit_doc
+class PowerIterationClustering(HasMaxIter, HasWeightCol, JavaParams,
JavaMLReadable,
+ JavaMLWritable):
+"""
+.. note:: Experimental
+
+Power Iteration Clustering (PIC), a scalable graph clustering
algorithm developed by
+http://www.icml2010.org/papers/387.pdf>Lin and Cohen. From
the abstract:
+PIC finds a very low-dimensional embedding of a dataset using
truncated power
+iteration on a normalized pair-wise similarity matrix of the data.
+
+This class is not yet an Estimator/Transformer, use `assignClusters`
method to run the
+PowerIterationClustering algorithm.
+
+.. seealso:: `Wikipedia on Spectral clustering \
+<http://en.wikipedia.org/wiki/Spectral_clustering>`_
+
+>>> from pyspark.sql.types import DoubleType, LongType, StructField,
StructType
+>>> import math
+>>> def genCircle(r, n):
+... points = []
+... for i in range(0, n):
+... theta = 2.0 * math.pi * i / n
+... points.append((r * math.cos(theta), r * math.sin(theta)))
+... return points
+>>> def sim(x, y):
+... dist = (x[0] - y[0]) * (x[0] - y[0]) + (x[1] - y[1]) * (x[1] -
y[1])
+... return math.exp(-dist / 2.0)
+>>> r1 = 1.0
+>>> n1 = 10
+>>> r2 = 4.0
+>>> n2 = 40
+>>> n = n1 + n2
+>>> points = genCircle(r1, n1) + genCircle(r2, n2)
+>>> data = [(i, j, sim(points[i], points[j])) for i in range(1, n) for
j in range(0, i)]
+>>> rdd = sc.parallelize(data, 2)
+>>> schema = StructType([StructField("src", LongType(), False), \
+ StructField("dst", LongType(), True), \
+ StructField("weight", DoubleType(), True)])
+>>> df = spark.createDataFrame(rdd, schema)
+>>> pic = PowerIterationClustering()
+>>> assignments =
pic.setK(2).setMaxIter(40).setWeightCol("weight").assignClusters(df)
+>>> result = sorted(assignments.collect(), key=lambda x: x.id)
+>>> result[0].cluster == result[1].cluster == result[2].cluster ==
result[3].cluster
+True
+>>> result[4].cluster == result[5].cluster == result[6].cluster ==
result[7].cluster
+True
+>>> pic_path = temp_path + "/pic"
+>>> pic.save(pic_path)
+>>> pic2 = PowerIterationClustering.load(pic_path)
+>>> pic2.getK()
+2
+>>> pic2.getMaxIter()
+40
+>>> assignments2 = pic2.assignClusters(df)
+>>> result2 = sorted(assignments2.collect(), key=lambda x: x.id)
+>>> result2[0].cluster == result2[1].cluster == result2[2].cluster ==
result2[3].cluster
+True
+>>> result2[4].cluster == result2[5].cluster == result2[6].cluster ==
result2[7].cluster
+True
+>>> pic3 = PowerIterationClustering(k=4, initMode="degree",
srcCol="source", dstCol="dest")
+>>> pic3.getSrcCol()
+'source'
+>>> pic3.getDstCol()
+'dest'
+>>> pic3.getK()
+4
+>>> pic3.getMaxIter()
+20
+>>> pic3.getInitMode()
+'degree'
+
+.. versionadded:: 2.4.0
+"""
+
+k = Param(Params._dummy(), "k",
+ "The number of clusters to create. Must be > 1.",
+ typeConverter=TypeConverters.toInt)
+initMode = Param(Params._dummy(), "initMode",
+ "The initialization algorithm. This can be either " +
+ "'random' to use a random vector as vertex
properties, or 'degree' to use " +
+ "a normalized sum of similarities with other
vertices. Supported options: " +
+ "'random' and 'degree'.",
+ typeConverter=TypeConverters.toString)
+srcCol = Param(Params._dummy(), "srcCol",
+ "Name of the input column for source vertex IDs.",
+ typeConverter=TypeConve
[GitHub] spark pull request #21513: [SPARK-19826][ML][PYTHON]add spark.ml Python API ...
Github user WeichenXu123 commented on a diff in the pull request:
https://github.com/apache/spark/pull/21513#discussion_r194214516
--- Diff: python/pyspark/ml/clustering.py ---
@@ -1156,6 +1157,204 @@ def getKeepLastCheckpoint(self):
return self.getOrDefault(self.keepLastCheckpoint)
+@inherit_doc
+class PowerIterationClustering(HasMaxIter, HasWeightCol, JavaParams,
JavaMLReadable,
+ JavaMLWritable):
+"""
+.. note:: Experimental
+
+Power Iteration Clustering (PIC), a scalable graph clustering
algorithm developed by
+http://www.icml2010.org/papers/387.pdf>Lin and Cohen. From
the abstract:
+PIC finds a very low-dimensional embedding of a dataset using
truncated power
+iteration on a normalized pair-wise similarity matrix of the data.
+
+This class is not yet an Estimator/Transformer, use `assignClusters`
method to run the
+PowerIterationClustering algorithm.
+
+.. seealso:: `Wikipedia on Spectral clustering \
+<http://en.wikipedia.org/wiki/Spectral_clustering>`_
+
+>>> from pyspark.sql.types import DoubleType, LongType, StructField,
StructType
+>>> import math
+>>> def genCircle(r, n):
+... points = []
+... for i in range(0, n):
+... theta = 2.0 * math.pi * i / n
+... points.append((r * math.cos(theta), r * math.sin(theta)))
+... return points
+>>> def sim(x, y):
+... dist = (x[0] - y[0]) * (x[0] - y[0]) + (x[1] - y[1]) * (x[1] -
y[1])
+... return math.exp(-dist / 2.0)
+>>> r1 = 1.0
+>>> n1 = 10
+>>> r2 = 4.0
+>>> n2 = 40
+>>> n = n1 + n2
+>>> points = genCircle(r1, n1) + genCircle(r2, n2)
+>>> data = [(i, j, sim(points[i], points[j])) for i in range(1, n) for
j in range(0, i)]
+>>> rdd = sc.parallelize(data, 2)
+>>> schema = StructType([StructField("src", LongType(), False), \
+ StructField("dst", LongType(), True), \
+ StructField("weight", DoubleType(), True)])
+>>> df = spark.createDataFrame(rdd, schema)
+>>> pic = PowerIterationClustering()
+>>> assignments =
pic.setK(2).setMaxIter(40).setWeightCol("weight").assignClusters(df)
+>>> result = sorted(assignments.collect(), key=lambda x: x.id)
+>>> result[0].cluster == result[1].cluster == result[2].cluster ==
result[3].cluster
+True
+>>> result[4].cluster == result[5].cluster == result[6].cluster ==
result[7].cluster
+True
+>>> pic_path = temp_path + "/pic"
+>>> pic.save(pic_path)
+>>> pic2 = PowerIterationClustering.load(pic_path)
+>>> pic2.getK()
+2
+>>> pic2.getMaxIter()
+40
+>>> assignments2 = pic2.assignClusters(df)
+>>> result2 = sorted(assignments2.collect(), key=lambda x: x.id)
+>>> result2[0].cluster == result2[1].cluster == result2[2].cluster ==
result2[3].cluster
+True
+>>> result2[4].cluster == result2[5].cluster == result2[6].cluster ==
result2[7].cluster
+True
+>>> pic3 = PowerIterationClustering(k=4, initMode="degree",
srcCol="source", dstCol="dest")
+>>> pic3.getSrcCol()
+'source'
+>>> pic3.getDstCol()
+'dest'
+>>> pic3.getK()
+4
+>>> pic3.getMaxIter()
+20
+>>> pic3.getInitMode()
+'degree'
+
+.. versionadded:: 2.4.0
+"""
+
+k = Param(Params._dummy(), "k",
+ "The number of clusters to create. Must be > 1.",
+ typeConverter=TypeConverters.toInt)
+initMode = Param(Params._dummy(), "initMode",
+ "The initialization algorithm. This can be either " +
+ "'random' to use a random vector as vertex
properties, or 'degree' to use " +
+ "a normalized sum of similarities with other
vertices. Supported options: " +
+ "'random' and 'degree'.",
+ typeConverter=TypeConverters.toString)
+srcCol = Param(Params._dummy(), "srcCol",
+ "Name of the input column for source vertex IDs.",
+ typeConverter=TypeConve
[GitHub] spark pull request #21513: [SPARK-19826][ML][PYTHON]add spark.ml Python API ...
Github user WeichenXu123 commented on a diff in the pull request: https://github.com/apache/spark/pull/21513#discussion_r194214535 --- Diff: python/pyspark/ml/clustering.py --- @@ -1156,6 +1157,204 @@ def getKeepLastCheckpoint(self): return self.getOrDefault(self.keepLastCheckpoint) +@inherit_doc +class PowerIterationClustering(HasMaxIter, HasWeightCol, JavaParams, JavaMLReadable, + JavaMLWritable): +""" +.. note:: Experimental + +Power Iteration Clustering (PIC), a scalable graph clustering algorithm developed by +http://www.icml2010.org/papers/387.pdf>Lin and Cohen. From the abstract: +PIC finds a very low-dimensional embedding of a dataset using truncated power +iteration on a normalized pair-wise similarity matrix of the data. + +This class is not yet an Estimator/Transformer, use `assignClusters` method to run the --- End diff -- ``` ... use :py:func:`assignClusters` method ... ``` --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21513: [SPARK-19826][ML][PYTHON]add spark.ml Python API ...
Github user WeichenXu123 commented on a diff in the pull request:
https://github.com/apache/spark/pull/21513#discussion_r194214831
--- Diff: python/pyspark/ml/clustering.py ---
@@ -1156,6 +1157,204 @@ def getKeepLastCheckpoint(self):
return self.getOrDefault(self.keepLastCheckpoint)
+@inherit_doc
+class PowerIterationClustering(HasMaxIter, HasWeightCol, JavaParams,
JavaMLReadable,
+ JavaMLWritable):
+"""
+.. note:: Experimental
+
+Power Iteration Clustering (PIC), a scalable graph clustering
algorithm developed by
+http://www.icml2010.org/papers/387.pdf>Lin and Cohen. From
the abstract:
+PIC finds a very low-dimensional embedding of a dataset using
truncated power
+iteration on a normalized pair-wise similarity matrix of the data.
+
+This class is not yet an Estimator/Transformer, use `assignClusters`
method to run the
+PowerIterationClustering algorithm.
+
+.. seealso:: `Wikipedia on Spectral clustering \
+<http://en.wikipedia.org/wiki/Spectral_clustering>`_
+
+>>> from pyspark.sql.types import DoubleType, LongType, StructField,
StructType
+>>> import math
+>>> def genCircle(r, n):
+... points = []
+... for i in range(0, n):
+... theta = 2.0 * math.pi * i / n
+... points.append((r * math.cos(theta), r * math.sin(theta)))
+... return points
+>>> def sim(x, y):
+... dist = (x[0] - y[0]) * (x[0] - y[0]) + (x[1] - y[1]) * (x[1] -
y[1])
+... return math.exp(-dist / 2.0)
+>>> r1 = 1.0
+>>> n1 = 10
+>>> r2 = 4.0
+>>> n2 = 40
+>>> n = n1 + n2
+>>> points = genCircle(r1, n1) + genCircle(r2, n2)
+>>> data = [(i, j, sim(points[i], points[j])) for i in range(1, n) for
j in range(0, i)]
+>>> rdd = sc.parallelize(data, 2)
+>>> schema = StructType([StructField("src", LongType(), False), \
+ StructField("dst", LongType(), True), \
+ StructField("weight", DoubleType(), True)])
+>>> df = spark.createDataFrame(rdd, schema)
--- End diff --
The test code here is too complex to be in doctest. could you change it to
code like:
``
df = sc.parallelize(...).toDF(...)
``
generate a small, hardcoded dataset.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21513: [SPARK-19826][ML][PYTHON]add spark.ml Python API ...
Github user WeichenXu123 commented on a diff in the pull request:
https://github.com/apache/spark/pull/21513#discussion_r194215008
--- Diff: python/pyspark/ml/clustering.py ---
@@ -1156,6 +1157,204 @@ def getKeepLastCheckpoint(self):
return self.getOrDefault(self.keepLastCheckpoint)
+@inherit_doc
+class PowerIterationClustering(HasMaxIter, HasWeightCol, JavaParams,
JavaMLReadable,
+ JavaMLWritable):
+"""
+.. note:: Experimental
+
+Power Iteration Clustering (PIC), a scalable graph clustering
algorithm developed by
+http://www.icml2010.org/papers/387.pdf>Lin and Cohen. From
the abstract:
+PIC finds a very low-dimensional embedding of a dataset using
truncated power
+iteration on a normalized pair-wise similarity matrix of the data.
+
+This class is not yet an Estimator/Transformer, use `assignClusters`
method to run the
+PowerIterationClustering algorithm.
+
+.. seealso:: `Wikipedia on Spectral clustering \
+<http://en.wikipedia.org/wiki/Spectral_clustering>`_
+
+>>> from pyspark.sql.types import DoubleType, LongType, StructField,
StructType
+>>> import math
+>>> def genCircle(r, n):
+... points = []
+... for i in range(0, n):
+... theta = 2.0 * math.pi * i / n
+... points.append((r * math.cos(theta), r * math.sin(theta)))
+... return points
+>>> def sim(x, y):
+... dist = (x[0] - y[0]) * (x[0] - y[0]) + (x[1] - y[1]) * (x[1] -
y[1])
+... return math.exp(-dist / 2.0)
+>>> r1 = 1.0
+>>> n1 = 10
+>>> r2 = 4.0
+>>> n2 = 40
+>>> n = n1 + n2
+>>> points = genCircle(r1, n1) + genCircle(r2, n2)
+>>> data = [(i, j, sim(points[i], points[j])) for i in range(1, n) for
j in range(0, i)]
+>>> rdd = sc.parallelize(data, 2)
+>>> schema = StructType([StructField("src", LongType(), False), \
+ StructField("dst", LongType(), True), \
+ StructField("weight", DoubleType(), True)])
+>>> df = spark.createDataFrame(rdd, schema)
+>>> pic = PowerIterationClustering()
+>>> assignments =
pic.setK(2).setMaxIter(40).setWeightCol("weight").assignClusters(df)
+>>> result = sorted(assignments.collect(), key=lambda x: x.id)
+>>> result[0].cluster == result[1].cluster == result[2].cluster ==
result[3].cluster
+True
+>>> result[4].cluster == result[5].cluster == result[6].cluster ==
result[7].cluster
+True
+>>> pic_path = temp_path + "/pic"
+>>> pic.save(pic_path)
+>>> pic2 = PowerIterationClustering.load(pic_path)
+>>> pic2.getK()
+2
+>>> pic2.getMaxIter()
+40
+>>> assignments2 = pic2.assignClusters(df)
+>>> result2 = sorted(assignments2.collect(), key=lambda x: x.id)
+>>> result2[0].cluster == result2[1].cluster == result2[2].cluster ==
result2[3].cluster
+True
+>>> result2[4].cluster == result2[5].cluster == result2[6].cluster ==
result2[7].cluster
+True
--- End diff --
Let's use a simpler way to check result, like:
```
>>> assignments.sort(assignments.id).show(truncate=False)
...
```
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21513: [SPARK-19826][ML][PYTHON]add spark.ml Python API ...
Github user WeichenXu123 commented on a diff in the pull request:
https://github.com/apache/spark/pull/21513#discussion_r194167552
--- Diff: python/pyspark/ml/clustering.py ---
@@ -1156,6 +1159,216 @@ def getKeepLastCheckpoint(self):
return self.getOrDefault(self.keepLastCheckpoint)
+@inherit_doc
+class PowerIterationClustering(HasMaxIter, HasWeightCol, JavaParams,
JavaMLReadable,
+ JavaMLWritable):
+"""
+.. note:: Experimental
+
+Power Iteration Clustering (PIC), a scalable graph clustering
algorithm developed by
+http://www.icml2010.org/papers/387.pdf>Lin and Cohen. From
the abstract:
+PIC finds a very low-dimensional embedding of a dataset using
truncated power
+iteration on a normalized pair-wise similarity matrix of the data.
+
+This class is not yet an Estimator/Transformer, use `assignClusters`
method to run the
+PowerIterationClustering algorithm.
+
+.. seealso:: `Wikipedia on Spectral clustering \
+<http://en.wikipedia.org/wiki/Spectral_clustering>`_
+
+>>> from pyspark.sql.types import StructField, StructType
+>>> import math
+>>> def genCircle(r, n):
+... points = []
+... for i in range(0, n):
+... theta = 2.0 * math.pi * i / n
+... points.append((r * math.cos(theta), r * math.sin(theta)))
+... return points
+>>> def sim(x, y):
+... dist = (x[0] - y[0]) * (x[0] - y[0]) + (x[1] - y[1]) * (x[1] -
y[1])
+... return math.exp(-dist / 2.0)
+>>> r1 = 1.0
+>>> n1 = 10
+>>> r2 = 4.0
+>>> n2 = 40
+>>> n = n1 + n2
+>>> points = genCircle(r1, n1) + genCircle(r2, n2)
+>>> data = [(i, j, sim(points[i], points[j])) for i in range(1, n) for
j in range(0, i)]
+>>> rdd = sc.parallelize(data, 2)
+>>> schema = StructType([StructField("src", LongType(), False), \
+ StructField("dst", LongType(), True), \
+ StructField("weight", DoubleType(), True)])
+>>> df = spark.createDataFrame(rdd, schema)
+>>> pic = PowerIterationClustering()
+>>> assignments =
pic.setK(2).setMaxIter(40).setWeightCol("weight").assignClusters(df)
+>>> result = sorted(assignments.collect(), key=lambda x: x.id)
+>>> result[0].cluster == result[1].cluster == result[2].cluster ==
result[3].cluster
+True
+>>> result[4].cluster == result[5].cluster == result[6].cluster ==
result[7].cluster
+True
+>>> pic_path = temp_path + "/pic"
+>>> pic.save(pic_path)
+>>> pic2 = PowerIterationClustering.load(pic_path)
+>>> pic2.getK()
+2
+>>> pic2.getMaxIter()
+40
+>>> assignments2 = pic2.assignClusters(df)
+>>> result2 = sorted(assignments2.collect(), key=lambda x: x.id)
+>>> result2[0].cluster == result2[1].cluster == result2[2].cluster ==
result2[3].cluster
+True
+>>> result2[4].cluster == result2[5].cluster == result2[6].cluster ==
result2[7].cluster
+True
+>>> pic3 = PowerIterationClustering(k=4, initMode="degree",
srcCol="source", dstCol="dest")
+>>> pic3.getSrcCol()
+'source'
+>>> pic3.getDstCol()
+'dest'
+>>> pic3.getK()
+4
+>>> pic3.getMaxIter()
+20
+>>> pic3.getInitMode()
+'degree'
+
+.. versionadded:: 2.4.0
+"""
+
+k = Param(Params._dummy(), "k",
+ "The number of clusters to create. Must be > 1.",
+ typeConverter=TypeConverters.toInt)
+initMode = Param(Params._dummy(), "initMode",
+ "The initialization algorithm. This can be either " +
+ "'random' to use a random vector as vertex
properties, or 'degree' to use " +
+ "a normalized sum of similarities with other
vertices. Supported options: " +
+ "'random' and 'degree'.",
+ typeConverter=TypeConverters.toString)
+srcCol = Param(Params._dummy(), "srcCol",
+ "Name of the input column for source vertex IDs.",
+ typeConverter=TypeConverters.toString)
+dstCol = Par
[GitHub] spark issue #21119: [SPARK-19826][ML][PYTHON]add spark.ml Python API for PIC
Github user WeichenXu123 commented on the issue: https://github.com/apache/spark/pull/21119 @huaxingao Create a new PR is better I think. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21493: [SPARK-15784] Add Power Iteration Clustering to s...
GitHub user WeichenXu123 opened a pull request: https://github.com/apache/spark/pull/21493 [SPARK-15784] Add Power Iteration Clustering to spark.ml ## What changes were proposed in this pull request? According to the discussion on JIRA. I rewrite the Power Iteration Clustering API in `spark.ml`. ## How was this patch tested? Unit test. Please review http://spark.apache.org/contributing.html before opening a pull request. You can merge this pull request into a Git repository by running: $ git pull https://github.com/WeichenXu123/spark pic_api Alternatively you can review and apply these changes as the patch at: https://github.com/apache/spark/pull/21493.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #21493 commit a605a2dba4243e5f1526bc239fd6dbe88dd13ce9 Author: WeichenXu Date: 2018-06-04T23:12:41Z init pr --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21265: [SPARK-24146][PySpark][ML] spark.ml parity for sequentia...
Github user WeichenXu123 commented on the issue: https://github.com/apache/spark/pull/21265 Jenkins, test this please. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21265: [SPARK-24146][PySpark][ML] spark.ml parity for se...
Github user WeichenXu123 commented on a diff in the pull request: https://github.com/apache/spark/pull/21265#discussion_r192000596 --- Diff: python/pyspark/ml/fpm.py --- @@ -243,3 +244,105 @@ def setParams(self, minSupport=0.3, minConfidence=0.8, itemsCol="items", def _create_model(self, java_model): return FPGrowthModel(java_model) + + +class PrefixSpan(JavaParams): +""" +.. note:: Experimental + +A parallel PrefixSpan algorithm to mine frequent sequential patterns. +The PrefixSpan algorithm is described in J. Pei, et al., PrefixSpan: Mining Sequential Patterns +Efficiently by Prefix-Projected Pattern Growth +(see http://doi.org/10.1109/ICDE.2001.914830;>here). +This class is not yet an Estimator/Transformer, use :py:func:`findFrequentSequentialPatterns` +method to run the PrefixSpan algorithm. + +@see https://en.wikipedia.org/wiki/Sequential_Pattern_Mining;>Sequential Pattern Mining +(Wikipedia) +.. versionadded:: 2.4.0 + +""" + +minSupport = Param(Params._dummy(), "minSupport", "The minimal support level of the " + + "sequential pattern. Sequential pattern that appears more than " + + "(minSupport * size-of-the-dataset) times will be output. Must be >= 0.", + typeConverter=TypeConverters.toFloat) + +maxPatternLength = Param(Params._dummy(), "maxPatternLength", + "The maximal length of the sequential pattern. Must be > 0.", + typeConverter=TypeConverters.toInt) + +maxLocalProjDBSize = Param(Params._dummy(), "maxLocalProjDBSize", + "The maximum number of items (including delimiters used in the " + + "internal storage format) allowed in a projected database before " + + "local processing. If a projected database exceeds this size, " + + "another iteration of distributed prefix growth is run. " + + "Must be > 0.", + typeConverter=TypeConverters.toInt) --- End diff -- Just test that python 'int' type range is the same with java 'long' type. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21265: [SPARK-24146][PySpark][ML] spark.ml parity for se...
Github user WeichenXu123 commented on a diff in the pull request: https://github.com/apache/spark/pull/21265#discussion_r191996249 --- Diff: python/pyspark/ml/fpm.py --- @@ -243,3 +244,105 @@ def setParams(self, minSupport=0.3, minConfidence=0.8, itemsCol="items", def _create_model(self, java_model): return FPGrowthModel(java_model) + + +class PrefixSpan(JavaParams): +""" +.. note:: Experimental + +A parallel PrefixSpan algorithm to mine frequent sequential patterns. +The PrefixSpan algorithm is described in J. Pei, et al., PrefixSpan: Mining Sequential Patterns +Efficiently by Prefix-Projected Pattern Growth +(see http://doi.org/10.1109/ICDE.2001.914830;>here). +This class is not yet an Estimator/Transformer, use :py:func:`findFrequentSequentialPatterns` +method to run the PrefixSpan algorithm. + +@see https://en.wikipedia.org/wiki/Sequential_Pattern_Mining;>Sequential Pattern Mining +(Wikipedia) +.. versionadded:: 2.4.0 + +""" + +minSupport = Param(Params._dummy(), "minSupport", "The minimal support level of the " + + "sequential pattern. Sequential pattern that appears more than " + + "(minSupport * size-of-the-dataset) times will be output. Must be >= 0.", + typeConverter=TypeConverters.toFloat) + +maxPatternLength = Param(Params._dummy(), "maxPatternLength", + "The maximal length of the sequential pattern. Must be > 0.", + typeConverter=TypeConverters.toInt) + +maxLocalProjDBSize = Param(Params._dummy(), "maxLocalProjDBSize", + "The maximum number of items (including delimiters used in the " + + "internal storage format) allowed in a projected database before " + + "local processing. If a projected database exceeds this size, " + + "another iteration of distributed prefix growth is run. " + + "Must be > 0.", + typeConverter=TypeConverters.toInt) --- End diff -- There isn't `TypeConverters.toLong`, do I need to add it ? My idea is that `TypeConverters.toInt` also fit to Long type in python side so I do not add it for now. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21265: [SPARK-24146][PySpark][ML] spark.ml parity for se...
Github user WeichenXu123 commented on a diff in the pull request:
https://github.com/apache/spark/pull/21265#discussion_r191995667
--- Diff: python/pyspark/ml/fpm.py ---
@@ -243,3 +244,75 @@ def setParams(self, minSupport=0.3, minConfidence=0.8,
itemsCol="items",
def _create_model(self, java_model):
return FPGrowthModel(java_model)
+
+
+class PrefixSpan(object):
+"""
+.. note:: Experimental
+
+A parallel PrefixSpan algorithm to mine frequent sequential patterns.
+The PrefixSpan algorithm is described in J. Pei, et al., PrefixSpan:
Mining Sequential Patterns
+Efficiently by Prefix-Projected Pattern Growth
+(see http://doi.org/10.1109/ICDE.2001.914830;>here).
+
+.. versionadded:: 2.4.0
+
+"""
+@staticmethod
+@since("2.4.0")
+def findFrequentSequentialPatterns(dataset,
+ sequenceCol,
+ minSupport,
+ maxPatternLength,
+ maxLocalProjDBSize):
+"""
+.. note:: Experimental
+Finds the complete set of frequent sequential patterns in the
input sequences of itemsets.
+
+:param dataset: A dataset or a dataframe containing a sequence
column which is
+`Seq[Seq[_]]` type.
+:param sequenceCol: The name of the sequence column in dataset,
rows with nulls in this
+column are ignored.
+:param minSupport: The minimal support level of the sequential
pattern, any pattern that
+ appears more than (minSupport *
size-of-the-dataset) times will be
+ output (recommended value: `0.1`).
+:param maxPatternLength: The maximal length of the sequential
pattern
+ (recommended value: `10`).
+:param maxLocalProjDBSize: The maximum number of items (including
delimiters used in the
+ internal storage format) allowed in a
projected database before
+ local processing. If a projected
database exceeds this size,
+ another iteration of distributed prefix
growth is run
+ (recommended value: `3200`).
+:return: A `DataFrame` that contains columns of sequence and
corresponding frequency.
+ The schema of it will be:
+ - `sequence: Seq[Seq[T]]` (T is the item type)
+ - `freq: Long`
+
+>>> from pyspark.ml.fpm import PrefixSpan
+>>> from pyspark.sql import Row
+>>> df = sc.parallelize([Row(sequence=[[1, 2], [3]]),
--- End diff --
I think it is better to be put in a example. @mengxr What do you think ?
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21393: [SPARK-20114][ML][FOLLOW-UP] spark.ml parity for sequent...
Github user WeichenXu123 commented on the issue: https://github.com/apache/spark/pull/21393 @mengxr @jkbradley --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21393: [SPARK-20114][ML][FOLLOW-UP] spark.ml parity for ...
GitHub user WeichenXu123 opened a pull request: https://github.com/apache/spark/pull/21393 [SPARK-20114][ML][FOLLOW-UP] spark.ml parity for sequential pattern mining - PrefixSpan ## What changes were proposed in this pull request? Change `PrefixSpan` into a class with param setter/getters. This address issues mentioned here: https://github.com/apache/spark/pull/20973#discussion_r186931806 ## How was this patch tested? UT. Please review http://spark.apache.org/contributing.html before opening a pull request. You can merge this pull request into a Git repository by running: $ git pull https://github.com/WeichenXu123/spark fix_prefix_span Alternatively you can review and apply these changes as the patch at: https://github.com/apache/spark/pull/21393.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #21393 commit 07327869fd0ea1a9dc4f32da8d10bde2ff231770 Author: WeichenXu <weichen.xu@...> Date: 2018-05-22T11:52:26Z init pr --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21163: [SPARK-24097][ML] Instrumentation improvements - RandomF...
Github user WeichenXu123 commented on the issue: https://github.com/apache/spark/pull/21163 Jenkins, test this please. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #20973: [SPARK-20114][ML] spark.ml parity for sequential ...
Github user WeichenXu123 commented on a diff in the pull request:
https://github.com/apache/spark/pull/20973#discussion_r188853310
--- Diff: mllib/src/main/scala/org/apache/spark/ml/fpm/PrefixSpan.scala ---
@@ -0,0 +1,96 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.ml.fpm
+
+import org.apache.spark.annotation.{Experimental, Since}
+import org.apache.spark.mllib.fpm.{PrefixSpan => mllibPrefixSpan}
+import org.apache.spark.sql.{DataFrame, Dataset, Row}
+import org.apache.spark.sql.functions.col
+import org.apache.spark.sql.types.{ArrayType, LongType, StructField,
StructType}
+
+/**
+ * :: Experimental ::
+ * A parallel PrefixSpan algorithm to mine frequent sequential patterns.
+ * The PrefixSpan algorithm is described in J. Pei, et al., PrefixSpan:
Mining Sequential Patterns
+ * Efficiently by Prefix-Projected Pattern Growth
+ * (see http://doi.org/10.1109/ICDE.2001.914830;>here).
+ *
+ * @see https://en.wikipedia.org/wiki/Sequential_Pattern_Mining;>Sequential
Pattern Mining
+ * (Wikipedia)
+ */
+@Since("2.4.0")
+@Experimental
+object PrefixSpan {
+
+ /**
+ * :: Experimental ::
+ * Finds the complete set of frequent sequential patterns in the input
sequences of itemsets.
+ *
+ * @param dataset A dataset or a dataframe containing a sequence column
which is
+ *{{{Seq[Seq[_]]}}} type
+ * @param sequenceCol the name of the sequence column in dataset, rows
with nulls in this column
+ *are ignored
+ * @param minSupport the minimal support level of the sequential
pattern, any pattern that
+ * appears more than (minSupport *
size-of-the-dataset) times will be output
+ * (recommended value: `0.1`).
+ * @param maxPatternLength the maximal length of the sequential pattern
+ * (recommended value: `10`).
+ * @param maxLocalProjDBSize The maximum number of items (including
delimiters used in the
+ * internal storage format) allowed in a
projected database before
+ * local processing. If a projected database
exceeds this size, another
+ * iteration of distributed prefix growth is
run
+ * (recommended value: `3200`).
+ * @return A `DataFrame` that contains columns of sequence and
corresponding frequency.
+ * The schema of it will be:
+ * - `sequence: Seq[Seq[T]]` (T is the item type)
+ * - `freq: Long`
+ */
+ @Since("2.4.0")
+ def findFrequentSequentialPatterns(
+ dataset: Dataset[_],
+ sequenceCol: String,
--- End diff --
Sure. Will update soon!
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #20973: [SPARK-20114][ML] spark.ml parity for sequential ...
Github user WeichenXu123 commented on a diff in the pull request:
https://github.com/apache/spark/pull/20973#discussion_r188491670
--- Diff: mllib/src/main/scala/org/apache/spark/ml/fpm/PrefixSpan.scala ---
@@ -0,0 +1,96 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.ml.fpm
+
+import org.apache.spark.annotation.{Experimental, Since}
+import org.apache.spark.mllib.fpm.{PrefixSpan => mllibPrefixSpan}
+import org.apache.spark.sql.{DataFrame, Dataset, Row}
+import org.apache.spark.sql.functions.col
+import org.apache.spark.sql.types.{ArrayType, LongType, StructField,
StructType}
+
+/**
+ * :: Experimental ::
+ * A parallel PrefixSpan algorithm to mine frequent sequential patterns.
+ * The PrefixSpan algorithm is described in J. Pei, et al., PrefixSpan:
Mining Sequential Patterns
+ * Efficiently by Prefix-Projected Pattern Growth
+ * (see http://doi.org/10.1109/ICDE.2001.914830;>here).
+ *
+ * @see https://en.wikipedia.org/wiki/Sequential_Pattern_Mining;>Sequential
Pattern Mining
+ * (Wikipedia)
+ */
+@Since("2.4.0")
+@Experimental
+object PrefixSpan {
+
+ /**
+ * :: Experimental ::
+ * Finds the complete set of frequent sequential patterns in the input
sequences of itemsets.
+ *
+ * @param dataset A dataset or a dataframe containing a sequence column
which is
+ *{{{Seq[Seq[_]]}}} type
+ * @param sequenceCol the name of the sequence column in dataset, rows
with nulls in this column
+ *are ignored
+ * @param minSupport the minimal support level of the sequential
pattern, any pattern that
+ * appears more than (minSupport *
size-of-the-dataset) times will be output
+ * (recommended value: `0.1`).
+ * @param maxPatternLength the maximal length of the sequential pattern
+ * (recommended value: `10`).
+ * @param maxLocalProjDBSize The maximum number of items (including
delimiters used in the
+ * internal storage format) allowed in a
projected database before
+ * local processing. If a projected database
exceeds this size, another
+ * iteration of distributed prefix growth is
run
+ * (recommended value: `3200`).
+ * @return A `DataFrame` that contains columns of sequence and
corresponding frequency.
+ * The schema of it will be:
+ * - `sequence: Seq[Seq[T]]` (T is the item type)
+ * - `freq: Long`
+ */
+ @Since("2.4.0")
+ def findFrequentSequentialPatterns(
+ dataset: Dataset[_],
+ sequenceCol: String,
--- End diff --
this way `final class PrefixSpan(override val uid: String) extends Params`
seemingly breaks binary compatibility if later we change it into an estimator ?
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21129: [SPARK-7132][ML] Add fit with validation set to spark.ml...
Github user WeichenXu123 commented on the issue: https://github.com/apache/spark/pull/21129 Jenkins test this please. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #17086: [SPARK-24101][ML][MLLIB] ML Evaluators should use weight...
Github user WeichenXu123 commented on the issue: https://github.com/apache/spark/pull/17086 LGTM. @jkbradley @mengxr Would you mind take a look ? --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21163: [SPARK-24097][ML] Instrumentation improvements - RandomF...
Github user WeichenXu123 commented on the issue: https://github.com/apache/spark/pull/21163 Jenkins, test this please. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21274: [SPARK-24213][ML] Fix for Int id type for PowerIteration...
Github user WeichenXu123 commented on the issue: https://github.com/apache/spark/pull/21274 LGTM. ! --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #20973: [SPARK-20114][ML] spark.ml parity for sequential ...
Github user WeichenXu123 commented on a diff in the pull request:
https://github.com/apache/spark/pull/20973#discussion_r186994754
--- Diff: mllib/src/main/scala/org/apache/spark/ml/fpm/PrefixSpan.scala ---
@@ -0,0 +1,96 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.ml.fpm
+
+import org.apache.spark.annotation.{Experimental, Since}
+import org.apache.spark.mllib.fpm.{PrefixSpan => mllibPrefixSpan}
+import org.apache.spark.sql.{DataFrame, Dataset, Row}
+import org.apache.spark.sql.functions.col
+import org.apache.spark.sql.types.{ArrayType, LongType, StructField,
StructType}
+
+/**
+ * :: Experimental ::
+ * A parallel PrefixSpan algorithm to mine frequent sequential patterns.
+ * The PrefixSpan algorithm is described in J. Pei, et al., PrefixSpan:
Mining Sequential Patterns
+ * Efficiently by Prefix-Projected Pattern Growth
+ * (see http://doi.org/10.1109/ICDE.2001.914830;>here).
+ *
+ * @see https://en.wikipedia.org/wiki/Sequential_Pattern_Mining;>Sequential
Pattern Mining
+ * (Wikipedia)
+ */
+@Since("2.4.0")
+@Experimental
+object PrefixSpan {
+
+ /**
+ * :: Experimental ::
+ * Finds the complete set of frequent sequential patterns in the input
sequences of itemsets.
+ *
+ * @param dataset A dataset or a dataframe containing a sequence column
which is
+ *{{{Seq[Seq[_]]}}} type
+ * @param sequenceCol the name of the sequence column in dataset, rows
with nulls in this column
+ *are ignored
+ * @param minSupport the minimal support level of the sequential
pattern, any pattern that
+ * appears more than (minSupport *
size-of-the-dataset) times will be output
+ * (recommended value: `0.1`).
+ * @param maxPatternLength the maximal length of the sequential pattern
+ * (recommended value: `10`).
+ * @param maxLocalProjDBSize The maximum number of items (including
delimiters used in the
+ * internal storage format) allowed in a
projected database before
+ * local processing. If a projected database
exceeds this size, another
+ * iteration of distributed prefix growth is
run
+ * (recommended value: `3200`).
+ * @return A `DataFrame` that contains columns of sequence and
corresponding frequency.
+ * The schema of it will be:
+ * - `sequence: Seq[Seq[T]]` (T is the item type)
+ * - `freq: Long`
+ */
+ @Since("2.4.0")
+ def findFrequentSequentialPatterns(
+ dataset: Dataset[_],
+ sequenceCol: String,
--- End diff --
I agree with using setters. @jkbradley What do you think of it ?
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21274: [SPARK-24213][ML] Fix for Int id type for PowerIt...
Github user WeichenXu123 commented on a diff in the pull request: https://github.com/apache/spark/pull/21274#discussion_r186986006 --- Diff: mllib/src/main/scala/org/apache/spark/ml/clustering/PowerIterationClustering.scala --- @@ -232,7 +232,7 @@ class PowerIterationClustering private[clustering] ( case _: LongType => uncastPredictions case otherType => --- End diff -- Why not directly use `case intType: IntType: ` so that make a stronger restriction ? Or do we need to support other types besides int/long ? --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21270: [SPARK-24213][ML]Power Iteration Clustering in SparkML t...
Github user WeichenXu123 commented on the issue: https://github.com/apache/spark/pull/21270 @shahidki31 Seemingly what you said above is anothor issue ? You can create another jira for that. :) --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21272: [MINOR][ML][DOC] Improved Naive Bayes user guide explana...
Github user WeichenXu123 commented on the issue: https://github.com/apache/spark/pull/21272 LGTM! --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21129: [SPARK-7132][ML] Add fit with validation set to spark.ml...
Github user WeichenXu123 commented on the issue: https://github.com/apache/spark/pull/21129 Jenkins, test this please. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21265: [SPARK-24146][PySpark][ML] spark.ml parity for se...
GitHub user WeichenXu123 opened a pull request: https://github.com/apache/spark/pull/21265 [SPARK-24146][PySpark][ML] spark.ml parity for sequential pattern mining - PrefixSpan: Python API ## What changes were proposed in this pull request? spark.ml parity for sequential pattern mining - PrefixSpan: Python API ## How was this patch tested? doctests You can merge this pull request into a Git repository by running: $ git pull https://github.com/WeichenXu123/spark prefix_span_py Alternatively you can review and apply these changes as the patch at: https://github.com/apache/spark/pull/21265.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #21265 commit 83eeea1c539d59a4d8496437dcf06d82b43b0ca2 Author: WeichenXu <weichen.xu@...> Date: 2018-05-08T05:29:24Z init pr --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #13493: [SPARK-15750][MLLib][PYSPARK] Constructing FPGrowth fail...
Github user WeichenXu123 commented on the issue: https://github.com/apache/spark/pull/13493 LGTM! --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #20095: [SPARK-22126][ML] Added fitMultiple method with d...
Github user WeichenXu123 commented on a diff in the pull request:
https://github.com/apache/spark/pull/20095#discussion_r186381507
--- Diff: mllib/src/main/scala/org/apache/spark/ml/Estimator.scala ---
@@ -79,7 +82,52 @@ abstract class Estimator[M <: Model[M]] extends
PipelineStage {
*/
@Since("2.0.0")
def fit(dataset: Dataset[_], paramMaps: Array[ParamMap]): Seq[M] = {
--- End diff --
Seemingly we should use the following note to deprecate it:
"""
.. note:: Deprecated in 2.3.0. Use :func:`Estimator.fitMultiple` instead.
"""
and like other places, add a warning
```
warnings.warn("Deprecated in 2.3.0. Use Estimator.fitMultiple instead.",
DeprecationWarning)
```
?
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21097: [SPARK-14682][ML] Provide evaluateEachIteration m...
Github user WeichenXu123 commented on a diff in the pull request:
https://github.com/apache/spark/pull/21097#discussion_r186037589
--- Diff:
mllib/src/test/scala/org/apache/spark/ml/classification/GBTClassifierSuite.scala
---
@@ -365,6 +365,20 @@ class GBTClassifierSuite extends MLTest with
DefaultReadWriteTest {
assert(mostImportantFeature !== mostIF)
}
+ test("model evaluateEachIteration") {
+for (lossType <- Seq("logistic")) {
+ val gbt = new GBTClassifier()
+.setMaxDepth(2)
+.setMaxIter(2)
+.setLossType(lossType)
+ val model = gbt.fit(trainData.toDF)
+ val eval1 = model.evaluateEachIteration(validationData.toDF)
+ val eval2 =
GradientBoostedTrees.evaluateEachIteration(validationData,
--- End diff --
I search scikit-learn doc, there seems no similar method like
`evaluateEachIteration`, we can only use `staged_predict` in
`sklearn.ensemble.GradientBoostingRegressor` and then implement almost the
whole logic again. In R package I also do not find this method.
Now I update the unit test, to compare with hardcoded result.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21218: [SPARK-24155][ML] Instrumentation improvements fo...
Github user WeichenXu123 commented on a diff in the pull request:
https://github.com/apache/spark/pull/21218#discussion_r185970925
--- Diff:
mllib/src/main/scala/org/apache/spark/ml/clustering/GaussianMixture.scala ---
@@ -423,6 +423,8 @@ class GaussianMixture @Since("2.0.0") (
val summary = new GaussianMixtureSummary(model.transform(dataset),
$(predictionCol), $(probabilityCol), $(featuresCol), $(k),
logLikelihood)
model.setSummary(Some(summary))
+instr.logNamedValue("logLikelihood", logLikelihood)
+instr.logNamedValue("clusterSizes", summary.clusterSizes.toString)
--- End diff --
also ok I think.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20261: [SPARK-22885][ML][TEST] ML test for StructuredStreaming:...
Github user WeichenXu123 commented on the issue: https://github.com/apache/spark/pull/20261 Jenkins, test this please. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21218: [SPARK-24155][ML] Instrumentation improvements fo...
Github user WeichenXu123 commented on a diff in the pull request:
https://github.com/apache/spark/pull/21218#discussion_r185756220
--- Diff: mllib/src/main/scala/org/apache/spark/ml/clustering/KMeans.scala
---
@@ -378,6 +378,7 @@ class KMeans @Since("1.5.0") (
model.transform(dataset), $(predictionCol), $(featuresCol), $(k))
model.setSummary(Some(summary))
+instr.logNamedValue("clusterSizes", summary.clusterSizes.toString)
--- End diff --
ditto.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21218: [SPARK-24155][ML] Instrumentation improvements fo...
Github user WeichenXu123 commented on a diff in the pull request:
https://github.com/apache/spark/pull/21218#discussion_r185756193
--- Diff:
mllib/src/main/scala/org/apache/spark/ml/clustering/GaussianMixture.scala ---
@@ -423,6 +423,8 @@ class GaussianMixture @Since("2.0.0") (
val summary = new GaussianMixtureSummary(model.transform(dataset),
$(predictionCol), $(probabilityCol), $(featuresCol), $(k),
logLikelihood)
model.setSummary(Some(summary))
+instr.logNamedValue("logLikelihood", logLikelihood)
+instr.logNamedValue("clusterSizes", summary.clusterSizes.toString)
--- End diff --
The `clusterSizes.toString` will get an unreadable object address string.
We need to print the content of the array. I suggest add a method like:
`def logNamedArray[T](array: Array[T]): Unit`
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20973: [SPARK-20114][ML] spark.ml parity for sequential pattern...
Github user WeichenXu123 commented on the issue: https://github.com/apache/spark/pull/20973 Jenkins, test this please. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20261: [SPARK-22885][ML][TEST] ML test for StructuredStreaming:...
Github user WeichenXu123 commented on the issue: https://github.com/apache/spark/pull/20261 Jenkins, test this please. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20973: [SPARK-20114][ML] spark.ml parity for sequential pattern...
Github user WeichenXu123 commented on the issue: https://github.com/apache/spark/pull/20973 Jenkins, test this please. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #20973: [SPARK-20114][ML] spark.ml parity for sequential ...
Github user WeichenXu123 commented on a diff in the pull request:
https://github.com/apache/spark/pull/20973#discussion_r185149879
--- Diff: mllib/src/main/scala/org/apache/spark/ml/fpm/PrefixSpan.scala ---
@@ -44,26 +43,37 @@ object PrefixSpan {
*
* @param dataset A dataset or a dataframe containing a sequence column
which is
*{{{Seq[Seq[_]]}}} type
- * @param sequenceCol the name of the sequence column in dataset
+ * @param sequenceCol the name of the sequence column in dataset, rows
with nulls in this column
+ *are ignored
* @param minSupport the minimal support level of the sequential
pattern, any pattern that
* appears more than (minSupport *
size-of-the-dataset) times will be output
- * (default: `0.1`).
- * @param maxPatternLength the maximal length of the sequential pattern,
any pattern that appears
- * less than maxPatternLength will be output
(default: `10`).
+ * (recommended value: `0.1`).
+ * @param maxPatternLength the maximal length of the sequential pattern
+ * (recommended value: `10`).
* @param maxLocalProjDBSize The maximum number of items (including
delimiters used in the
* internal storage format) allowed in a
projected database before
* local processing. If a projected database
exceeds this size, another
- * iteration of distributed prefix growth is
run (default: `3200`).
- * @return A dataframe that contains columns of sequence and
corresponding frequency.
+ * iteration of distributed prefix growth is
run
+ * (recommended value: `3200`).
+ * @return A `DataFrame` that contains columns of sequence and
corresponding frequency.
+ * The schema of it will be:
+ * - `sequence: Seq[Seq[T]]` (T is the item type)
+ * - `frequency: Long`
--- End diff --
sure!
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21153: [SPARK-24058][ML][PySpark] Default Params in ML s...
Github user WeichenXu123 commented on a diff in the pull request:
https://github.com/apache/spark/pull/21153#discussion_r184626842
--- Diff: python/pyspark/ml/util.py ---
@@ -523,11 +534,29 @@ def getAndSetParams(instance, metadata):
"""
Extract Params from metadata, and set them in the instance.
"""
+# User-supplied param values
for paramName in metadata['paramMap']:
param = instance.getParam(paramName)
paramValue = metadata['paramMap'][paramName]
instance.set(param, paramValue)
+# Default param values
+majorAndMinorVersions = majorMinorVersion(metadata['sparkVersion'])
+assert majorAndMinorVersions is not None, "Error loading metadata:
Expected " + \
+"Spark version string but found
{}".format(metadata['sparkVersion'])
+
+major = majorAndMinorVersions[0]
+minor = majorAndMinorVersions[1]
+# For metadata file prior to Spark 2.4, there is no default
section.
+if major > 2 or (major == 2 and minor >= 4):
+assert 'defaultParamMap' in metadata, "Error loading metadata:
Expected " + \
+"`defaultParamMap` section not found"
+
+for paramName in metadata['defaultParamMap']:
+param = instance.getParam(paramName)
+paramValue = metadata['defaultParamMap'][paramName]
+instance._setDefault(**{param.name: paramValue})
--- End diff --
remove line `param = instance.getParam(paramName)` and change this line to
`instance._setDefault(**{paramName: paramValue})`
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21153: [SPARK-24058][ML][PySpark] Default Params in ML s...
Github user WeichenXu123 commented on a diff in the pull request:
https://github.com/apache/spark/pull/21153#discussion_r184620777
--- Diff: python/pyspark/ml/util.py ---
@@ -417,15 +419,24 @@ def _get_metadata_to_save(instance, sc,
extraMetadata=None, paramMap=None):
"""
uid = instance.uid
cls = instance.__module__ + '.' + instance.__class__.__name__
-params = instance.extractParamMap()
+
+# User-supplied param values
+params = instance._paramMap
jsonParams = {}
if paramMap is not None:
jsonParams = paramMap
else:
for p in params:
jsonParams[p.name] = params[p]
--- End diff --
I think use `_paramMap.copy()` will be simpler.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21153: [SPARK-24058][ML][PySpark] Default Params in ML s...
Github user WeichenXu123 commented on a diff in the pull request:
https://github.com/apache/spark/pull/21153#discussion_r184620855
--- Diff: python/pyspark/ml/util.py ---
@@ -417,15 +419,24 @@ def _get_metadata_to_save(instance, sc,
extraMetadata=None, paramMap=None):
"""
uid = instance.uid
cls = instance.__module__ + '.' + instance.__class__.__name__
-params = instance.extractParamMap()
+
+# User-supplied param values
+params = instance._paramMap
jsonParams = {}
if paramMap is not None:
jsonParams = paramMap
else:
for p in params:
jsonParams[p.name] = params[p]
+
+# Default param values
+jsonDefaultParams = {}
+for p in instance._defaultParamMap:
+jsonDefaultParams[p.name] = instance._defaultParamMap[p]
--- End diff --
similar, use `_defaultParamMap.copy()`
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #17086: [SPARK-24101][ML][MLLIB] ML Evaluators should use weight...
Github user WeichenXu123 commented on the issue: https://github.com/apache/spark/pull/17086 overall good, @jkbradley Would you mind take a look ? --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #17086: [SPARK-24101][ML][MLLIB] ML Evaluators should use...
Github user WeichenXu123 commented on a diff in the pull request:
https://github.com/apache/spark/pull/17086#discussion_r184584878
--- Diff:
mllib/src/test/scala/org/apache/spark/mllib/evaluation/MulticlassMetricsSuite.scala
---
@@ -55,44 +60,128 @@ class MulticlassMetricsSuite extends SparkFunSuite
with MLlibTestSparkContext {
val f2measure1 = (1 + 2 * 2) * precision1 * recall1 / (2 * 2 *
precision1 + recall1)
val f2measure2 = (1 + 2 * 2) * precision2 * recall2 / (2 * 2 *
precision2 + recall2)
-
assert(metrics.confusionMatrix.toArray.sameElements(confusionMatrix.toArray))
-assert(math.abs(metrics.truePositiveRate(0.0) - tpRate0) < delta)
-assert(math.abs(metrics.truePositiveRate(1.0) - tpRate1) < delta)
-assert(math.abs(metrics.truePositiveRate(2.0) - tpRate2) < delta)
-assert(math.abs(metrics.falsePositiveRate(0.0) - fpRate0) < delta)
-assert(math.abs(metrics.falsePositiveRate(1.0) - fpRate1) < delta)
-assert(math.abs(metrics.falsePositiveRate(2.0) - fpRate2) < delta)
-assert(math.abs(metrics.precision(0.0) - precision0) < delta)
-assert(math.abs(metrics.precision(1.0) - precision1) < delta)
-assert(math.abs(metrics.precision(2.0) - precision2) < delta)
-assert(math.abs(metrics.recall(0.0) - recall0) < delta)
-assert(math.abs(metrics.recall(1.0) - recall1) < delta)
-assert(math.abs(metrics.recall(2.0) - recall2) < delta)
-assert(math.abs(metrics.fMeasure(0.0) - f1measure0) < delta)
-assert(math.abs(metrics.fMeasure(1.0) - f1measure1) < delta)
-assert(math.abs(metrics.fMeasure(2.0) - f1measure2) < delta)
-assert(math.abs(metrics.fMeasure(0.0, 2.0) - f2measure0) < delta)
-assert(math.abs(metrics.fMeasure(1.0, 2.0) - f2measure1) < delta)
-assert(math.abs(metrics.fMeasure(2.0, 2.0) - f2measure2) < delta)
+assert(metrics.confusionMatrix.asML ~== confusionMatrix.asML relTol
delta)
+assert(metrics.truePositiveRate(0.0) ~== tpRate0 absTol delta)
+assert(metrics.truePositiveRate(1.0) ~== tpRate1 absTol delta)
+assert(metrics.truePositiveRate(2.0) ~== tpRate2 absTol delta)
+assert(metrics.falsePositiveRate(0.0) ~== fpRate0 absTol delta)
+assert(metrics.falsePositiveRate(1.0) ~== fpRate1 absTol delta)
+assert(metrics.falsePositiveRate(2.0) ~== fpRate2 absTol delta)
+assert(metrics.precision(0.0) ~== precision0 absTol delta)
+assert(metrics.precision(1.0) ~== precision1 absTol delta)
+assert(metrics.precision(2.0) ~== precision2 absTol delta)
+assert(metrics.recall(0.0) ~== recall0 absTol delta)
+assert(metrics.recall(1.0) ~== recall1 absTol delta)
+assert(metrics.recall(2.0) ~== recall2 absTol delta)
+assert(metrics.fMeasure(0.0) ~== f1measure0 absTol delta)
+assert(metrics.fMeasure(1.0) ~== f1measure1 absTol delta)
+assert(metrics.fMeasure(2.0) ~== f1measure2 absTol delta)
+assert(metrics.fMeasure(0.0, 2.0) ~== f2measure0 absTol delta)
+assert(metrics.fMeasure(1.0, 2.0) ~== f2measure1 absTol delta)
+assert(metrics.fMeasure(2.0, 2.0) ~== f2measure2 absTol delta)
+
+assert(metrics.accuracy ~==
+ (2.0 + 3.0 + 1.0) / ((2 + 3 + 1) + (1 + 1 + 1)) absTol delta)
+assert(metrics.accuracy ~== metrics.precision absTol delta)
+assert(metrics.accuracy ~== metrics.recall absTol delta)
+assert(metrics.accuracy ~== metrics.fMeasure absTol delta)
+assert(metrics.accuracy ~== metrics.weightedRecall absTol delta)
+val weight0 = 4.0 / 9
+val weight1 = 4.0 / 9
+val weight2 = 1.0 / 9
+assert(metrics.weightedTruePositiveRate ~==
+ (weight0 * tpRate0 + weight1 * tpRate1 + weight2 * tpRate2) absTol
delta)
+assert(metrics.weightedFalsePositiveRate ~==
+ (weight0 * fpRate0 + weight1 * fpRate1 + weight2 * fpRate2) absTol
delta)
+assert(metrics.weightedPrecision ~==
+ (weight0 * precision0 + weight1 * precision1 + weight2 * precision2)
absTol delta)
+assert(metrics.weightedRecall ~==
+ (weight0 * recall0 + weight1 * recall1 + weight2 * recall2) absTol
delta)
+assert(metrics.weightedFMeasure ~==
+ (weight0 * f1measure0 + weight1 * f1measure1 + weight2 * f1measure2)
absTol delta)
+assert(metrics.weightedFMeasure(2.0) ~==
+ (weight0 * f2measure0 + weight1 * f2measure1 + weight2 * f2measure2)
absTol delta)
+assert(metrics.labels === labels)
+ }
+
+ test("Multiclass evaluation metrics with weights") {
+/*
+ * Confusion matrix for 3-class classification with total 9 instances
with 2 weights:
+ * |2 * w1|1 * w2 |1 * w1| true class0 (4 instances)
+ * |1 * w2|2 * w1 + 1 * w2|0 | true class1 (4 in
[GitHub] spark pull request #17086: [SPARK-24101][ML][MLLIB] ML Evaluators should use...
Github user WeichenXu123 commented on a diff in the pull request:
https://github.com/apache/spark/pull/17086#discussion_r184566012
--- Diff:
mllib/src/test/scala/org/apache/spark/mllib/evaluation/MulticlassMetricsSuite.scala
---
@@ -95,4 +95,95 @@ class MulticlassMetricsSuite extends SparkFunSuite with
MLlibTestSparkContext {
((4.0 / 9) * f2measure0 + (4.0 / 9) * f2measure1 + (1.0 / 9) *
f2measure2)) < delta)
assert(metrics.labels.sameElements(labels))
}
+
+ test("Multiclass evaluation metrics with weights") {
+/*
+ * Confusion matrix for 3-class classification with total 9 instances
with 2 weights:
+ * |2 * w1|1 * w2 |1 * w1| true class0 (4 instances)
+ * |1 * w2|2 * w1 + 1 * w2|0 | true class1 (4 instances)
+ * |0 |0 |1 * w2| true class2 (1 instance)
+ */
+val w1 = 2.2
+val w2 = 1.5
+val tw = 2.0 * w1 + 1.0 * w2 + 1.0 * w1 + 1.0 * w2 + 2.0 * w1 + 1.0 *
w2 + 1.0 * w2
+val confusionMatrix = Matrices.dense(3, 3,
+ Array(2 * w1, 1 * w2, 0, 1 * w2, 2 * w1 + 1 * w2, 0, 1 * w1, 0, 1 *
w2))
+val labels = Array(0.0, 1.0, 2.0)
+val predictionAndLabelsWithWeights = sc.parallelize(
+ Seq((0.0, 0.0, w1), (0.0, 1.0, w2), (0.0, 0.0, w1), (1.0, 0.0, w2),
+(1.0, 1.0, w1), (1.0, 1.0, w2), (1.0, 1.0, w1), (2.0, 2.0, w2),
+(2.0, 0.0, w1)), 2)
+val metrics = new MulticlassMetrics(predictionAndLabelsWithWeights)
+val delta = 0.001
+val tpRate0 = (2.0 * w1) / (2.0 * w1 + 1.0 * w2 + 1.0 * w1)
+val tpRate1 = (2.0 * w1 + 1.0 * w2) / (2.0 * w1 + 1.0 * w2 + 1.0 * w2)
+val tpRate2 = (1.0 * w2) / (1.0 * w2 + 0)
+val fpRate0 = (1.0 * w2) / (tw - (2.0 * w1 + 1.0 * w2 + 1.0 * w1))
+val fpRate1 = (1.0 * w2) / (tw - (1.0 * w2 + 2.0 * w1 + 1.0 * w2))
+val fpRate2 = (1.0 * w1) / (tw - (1.0 * w2))
+val precision0 = (2.0 * w1) / (2 * w1 + 1 * w2)
+val precision1 = (2.0 * w1 + 1.0 * w2) / (2.0 * w1 + 1.0 * w2 + 1.0 *
w2)
+val precision2 = (1.0 * w2) / (1 * w1 + 1 * w2)
+val recall0 = (2.0 * w1) / (2.0 * w1 + 1.0 * w2 + 1.0 * w1)
+val recall1 = (2.0 * w1 + 1.0 * w2) / (2.0 * w1 + 1.0 * w2 + 1.0 * w2)
+val recall2 = (1.0 * w2) / (1.0 * w2 + 0)
+val f1measure0 = 2 * precision0 * recall0 / (precision0 + recall0)
+val f1measure1 = 2 * precision1 * recall1 / (precision1 + recall1)
+val f1measure2 = 2 * precision2 * recall2 / (precision2 + recall2)
+val f2measure0 = (1 + 2 * 2) * precision0 * recall0 / (2 * 2 *
precision0 + recall0)
+val f2measure1 = (1 + 2 * 2) * precision1 * recall1 / (2 * 2 *
precision1 + recall1)
+val f2measure2 = (1 + 2 * 2) * precision2 * recall2 / (2 * 2 *
precision2 + recall2)
+
+
assert(metrics.confusionMatrix.toArray.sameElements(confusionMatrix.toArray))
--- End diff --
Oh, that's because you use `Matrices` in `mllib`, change it to `Matrices`
in `ml`, i.e., `import org.apache.spark.ml.linalg.Matrices`
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21119: [SPARK-19826][ML][PYTHON]add spark.ml Python API ...
Github user WeichenXu123 commented on a diff in the pull request:
https://github.com/apache/spark/pull/21119#discussion_r184343934
--- Diff: python/pyspark/ml/clustering.py ---
@@ -1156,6 +1156,201 @@ def getKeepLastCheckpoint(self):
return self.getOrDefault(self.keepLastCheckpoint)
+class _PowerIterationClusteringParams(JavaParams, HasMaxIter,
HasPredictionCol):
+"""
+Params for :py:attr:`PowerIterationClustering`.
+.. versionadded:: 2.4.0
+"""
+
+k = Param(Params._dummy(), "k",
+ "The number of clusters to create. Must be > 1.",
+ typeConverter=TypeConverters.toInt)
+initMode = Param(Params._dummy(), "initMode",
+ "The initialization algorithm. This can be either " +
+ "'random' to use a random vector as vertex
properties, or 'degree' to use " +
+ "a normalized sum of similarities with other
vertices. Supported options: " +
+ "'random' and 'degree'.",
+ typeConverter=TypeConverters.toString)
+idCol = Param(Params._dummy(), "idCol",
+ "Name of the input column for vertex IDs.",
+ typeConverter=TypeConverters.toString)
+neighborsCol = Param(Params._dummy(), "neighborsCol",
+ "Name of the input column for neighbors in the
adjacency list " +
+ "representation.",
+ typeConverter=TypeConverters.toString)
+similaritiesCol = Param(Params._dummy(), "similaritiesCol",
+"Name of the input column for non-negative
weights (similarities) " +
+"of edges between the vertex in `idCol` and
each neighbor in " +
+"`neighborsCol`",
+typeConverter=TypeConverters.toString)
+
+@since("2.4.0")
+def getK(self):
+"""
+Gets the value of `k`
+"""
+return self.getOrDefault(self.k)
+
+@since("2.4.0")
+def getInitMode(self):
+"""
+Gets the value of `initMode`
+"""
+return self.getOrDefault(self.initMode)
+
+@since("2.4.0")
+def getIdCol(self):
+"""
+Gets the value of `idCol`
+"""
+return self.getOrDefault(self.idCol)
+
+@since("2.4.0")
+def getNeighborsCol(self):
+"""
+Gets the value of `neighborsCol`
+"""
+return self.getOrDefault(self.neighborsCol)
+
+@since("2.4.0")
+def getSimilaritiesCol(self):
+"""
+Gets the value of `similaritiesCol`
+"""
+return self.getOrDefault(self.binary)
+
+
+@inherit_doc
+class PowerIterationClustering(JavaTransformer,
_PowerIterationClusteringParams, JavaMLReadable,
+ JavaMLWritable):
+"""
+Model produced by [[PowerIterationClustering]].
--- End diff --
The doc is wrong. Copy doc from scala side.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21119: [SPARK-19826][ML][PYTHON]add spark.ml Python API ...
Github user WeichenXu123 commented on a diff in the pull request: https://github.com/apache/spark/pull/21119#discussion_r184342231 --- Diff: python/pyspark/ml/clustering.py --- @@ -1156,6 +1156,201 @@ def getKeepLastCheckpoint(self): return self.getOrDefault(self.keepLastCheckpoint) +class _PowerIterationClusteringParams(JavaParams, HasMaxIter, HasPredictionCol): --- End diff -- Why not directly add params into class `PowerIterationClustering`? --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21119: [SPARK-19826][ML][PYTHON]add spark.ml Python API ...
Github user WeichenXu123 commented on a diff in the pull request:
https://github.com/apache/spark/pull/21119#discussion_r184346287
--- Diff: python/pyspark/ml/clustering.py ---
@@ -1156,6 +1156,201 @@ def getKeepLastCheckpoint(self):
return self.getOrDefault(self.keepLastCheckpoint)
+class _PowerIterationClusteringParams(JavaParams, HasMaxIter,
HasPredictionCol):
+"""
+Params for :py:attr:`PowerIterationClustering`.
+.. versionadded:: 2.4.0
+"""
+
+k = Param(Params._dummy(), "k",
+ "The number of clusters to create. Must be > 1.",
+ typeConverter=TypeConverters.toInt)
+initMode = Param(Params._dummy(), "initMode",
+ "The initialization algorithm. This can be either " +
+ "'random' to use a random vector as vertex
properties, or 'degree' to use " +
+ "a normalized sum of similarities with other
vertices. Supported options: " +
+ "'random' and 'degree'.",
+ typeConverter=TypeConverters.toString)
+idCol = Param(Params._dummy(), "idCol",
+ "Name of the input column for vertex IDs.",
+ typeConverter=TypeConverters.toString)
+neighborsCol = Param(Params._dummy(), "neighborsCol",
+ "Name of the input column for neighbors in the
adjacency list " +
+ "representation.",
+ typeConverter=TypeConverters.toString)
+similaritiesCol = Param(Params._dummy(), "similaritiesCol",
+"Name of the input column for non-negative
weights (similarities) " +
+"of edges between the vertex in `idCol` and
each neighbor in " +
+"`neighborsCol`",
+typeConverter=TypeConverters.toString)
+
+@since("2.4.0")
+def getK(self):
+"""
+Gets the value of `k`
+"""
+return self.getOrDefault(self.k)
+
+@since("2.4.0")
+def getInitMode(self):
+"""
+Gets the value of `initMode`
+"""
+return self.getOrDefault(self.initMode)
+
+@since("2.4.0")
+def getIdCol(self):
+"""
+Gets the value of `idCol`
+"""
+return self.getOrDefault(self.idCol)
+
+@since("2.4.0")
+def getNeighborsCol(self):
+"""
+Gets the value of `neighborsCol`
+"""
+return self.getOrDefault(self.neighborsCol)
+
+@since("2.4.0")
+def getSimilaritiesCol(self):
+"""
+Gets the value of `similaritiesCol`
+"""
+return self.getOrDefault(self.binary)
+
+
+@inherit_doc
+class PowerIterationClustering(JavaTransformer,
_PowerIterationClusteringParams, JavaMLReadable,
+ JavaMLWritable):
+"""
+Model produced by [[PowerIterationClustering]].
+>>> from pyspark.sql.types import ArrayType, DoubleType, LongType,
StructField, StructType
+>>> import math
+>>> def genCircle(r, n):
+... points = []
+... for i in range(0, n):
+... theta = 2.0 * math.pi * i / n
+... points.append((r * math.cos(theta), r * math.sin(theta)))
+... return points
+>>> def sim(x, y):
+... dist = (x[0] - y[0]) * (x[0] - y[0]) + (x[1] - y[1]) * (x[1] -
y[1])
+... return math.exp(-dist / 2.0)
+>>> r1 = 1.0
+>>> n1 = 10
+>>> r2 = 4.0
+>>> n2 = 40
+>>> n = n1 + n2
+>>> points = genCircle(r1, n1) + genCircle(r2, n2)
+>>> similarities = []
+>>> for i in range (1, n):
+...neighbor = []
+...weight = []
+...for j in range (i):
+...neighbor.append((long)(j))
+...weight.append(sim(points[i], points[j]))
+...similarities.append([(long)(i), neighbor, weight])
--- End diff --
The doctest code looks like too long, maybe more proper to put it in
examples.
Could you replace the data generation code here by using a simple hardcoded
dataset ?
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21119: [SPARK-19826][ML][PYTHON]add spark.ml Python API ...
Github user WeichenXu123 commented on a diff in the pull request:
https://github.com/apache/spark/pull/21119#discussion_r184344777
--- Diff: python/pyspark/ml/clustering.py ---
@@ -1156,6 +1156,201 @@ def getKeepLastCheckpoint(self):
return self.getOrDefault(self.keepLastCheckpoint)
+class _PowerIterationClusteringParams(JavaParams, HasMaxIter,
HasPredictionCol):
+"""
+Params for :py:attr:`PowerIterationClustering`.
+.. versionadded:: 2.4.0
+"""
+
+k = Param(Params._dummy(), "k",
+ "The number of clusters to create. Must be > 1.",
+ typeConverter=TypeConverters.toInt)
+initMode = Param(Params._dummy(), "initMode",
+ "The initialization algorithm. This can be either " +
+ "'random' to use a random vector as vertex
properties, or 'degree' to use " +
+ "a normalized sum of similarities with other
vertices. Supported options: " +
+ "'random' and 'degree'.",
+ typeConverter=TypeConverters.toString)
+idCol = Param(Params._dummy(), "idCol",
+ "Name of the input column for vertex IDs.",
+ typeConverter=TypeConverters.toString)
+neighborsCol = Param(Params._dummy(), "neighborsCol",
+ "Name of the input column for neighbors in the
adjacency list " +
+ "representation.",
+ typeConverter=TypeConverters.toString)
+similaritiesCol = Param(Params._dummy(), "similaritiesCol",
+"Name of the input column for non-negative
weights (similarities) " +
+"of edges between the vertex in `idCol` and
each neighbor in " +
+"`neighborsCol`",
+typeConverter=TypeConverters.toString)
+
+@since("2.4.0")
+def getK(self):
+"""
+Gets the value of `k`
+"""
+return self.getOrDefault(self.k)
+
+@since("2.4.0")
+def getInitMode(self):
+"""
+Gets the value of `initMode`
+"""
+return self.getOrDefault(self.initMode)
+
+@since("2.4.0")
+def getIdCol(self):
+"""
+Gets the value of `idCol`
+"""
+return self.getOrDefault(self.idCol)
+
+@since("2.4.0")
+def getNeighborsCol(self):
+"""
+Gets the value of `neighborsCol`
+"""
+return self.getOrDefault(self.neighborsCol)
+
+@since("2.4.0")
+def getSimilaritiesCol(self):
+"""
+Gets the value of `similaritiesCol`
+"""
+return self.getOrDefault(self.binary)
+
+
+@inherit_doc
+class PowerIterationClustering(JavaTransformer,
_PowerIterationClusteringParams, JavaMLReadable,
+ JavaMLWritable):
+"""
+Model produced by [[PowerIterationClustering]].
+>>> from pyspark.sql.types import ArrayType, DoubleType, LongType,
StructField, StructType
+>>> import math
+>>> def genCircle(r, n):
+... points = []
+... for i in range(0, n):
+... theta = 2.0 * math.pi * i / n
+... points.append((r * math.cos(theta), r * math.sin(theta)))
+... return points
+>>> def sim(x, y):
+... dist = (x[0] - y[0]) * (x[0] - y[0]) + (x[1] - y[1]) * (x[1] -
y[1])
+... return math.exp(-dist / 2.0)
+>>> r1 = 1.0
+>>> n1 = 10
+>>> r2 = 4.0
+>>> n2 = 40
+>>> n = n1 + n2
+>>> points = genCircle(r1, n1) + genCircle(r2, n2)
+>>> similarities = []
+>>> for i in range (1, n):
+...neighbor = []
+...weight = []
+...for j in range (i):
+...neighbor.append((long)(j))
+...weight.append(sim(points[i], points[j]))
+...similarities.append([(long)(i), neighbor, weight])
+>>> rdd = sc.parallelize(similarities, 2)
+>>> schema = StructType([StructField("id", LongType(), False), \
+ StructField(&
[GitHub] spark pull request #21119: [SPARK-19826][ML][PYTHON]add spark.ml Python API ...
Github user WeichenXu123 commented on a diff in the pull request:
https://github.com/apache/spark/pull/21119#discussion_r184344901
--- Diff: python/pyspark/ml/clustering.py ---
@@ -1156,6 +1156,201 @@ def getKeepLastCheckpoint(self):
return self.getOrDefault(self.keepLastCheckpoint)
+class _PowerIterationClusteringParams(JavaParams, HasMaxIter,
HasPredictionCol):
+"""
+Params for :py:attr:`PowerIterationClustering`.
+.. versionadded:: 2.4.0
+"""
+
+k = Param(Params._dummy(), "k",
+ "The number of clusters to create. Must be > 1.",
+ typeConverter=TypeConverters.toInt)
+initMode = Param(Params._dummy(), "initMode",
+ "The initialization algorithm. This can be either " +
+ "'random' to use a random vector as vertex
properties, or 'degree' to use " +
+ "a normalized sum of similarities with other
vertices. Supported options: " +
+ "'random' and 'degree'.",
+ typeConverter=TypeConverters.toString)
+idCol = Param(Params._dummy(), "idCol",
+ "Name of the input column for vertex IDs.",
+ typeConverter=TypeConverters.toString)
+neighborsCol = Param(Params._dummy(), "neighborsCol",
+ "Name of the input column for neighbors in the
adjacency list " +
+ "representation.",
+ typeConverter=TypeConverters.toString)
+similaritiesCol = Param(Params._dummy(), "similaritiesCol",
+"Name of the input column for non-negative
weights (similarities) " +
+"of edges between the vertex in `idCol` and
each neighbor in " +
+"`neighborsCol`",
+typeConverter=TypeConverters.toString)
+
+@since("2.4.0")
+def getK(self):
+"""
+Gets the value of `k`
+"""
+return self.getOrDefault(self.k)
+
+@since("2.4.0")
+def getInitMode(self):
+"""
+Gets the value of `initMode`
+"""
+return self.getOrDefault(self.initMode)
+
+@since("2.4.0")
+def getIdCol(self):
+"""
+Gets the value of `idCol`
+"""
+return self.getOrDefault(self.idCol)
+
+@since("2.4.0")
+def getNeighborsCol(self):
+"""
+Gets the value of `neighborsCol`
+"""
+return self.getOrDefault(self.neighborsCol)
+
+@since("2.4.0")
+def getSimilaritiesCol(self):
+"""
+Gets the value of `similaritiesCol`
+"""
+return self.getOrDefault(self.binary)
+
+
+@inherit_doc
+class PowerIterationClustering(JavaTransformer,
_PowerIterationClusteringParams, JavaMLReadable,
+ JavaMLWritable):
+"""
+Model produced by [[PowerIterationClustering]].
+>>> from pyspark.sql.types import ArrayType, DoubleType, LongType,
StructField, StructType
+>>> import math
+>>> def genCircle(r, n):
+... points = []
+... for i in range(0, n):
+... theta = 2.0 * math.pi * i / n
+... points.append((r * math.cos(theta), r * math.sin(theta)))
+... return points
+>>> def sim(x, y):
+... dist = (x[0] - y[0]) * (x[0] - y[0]) + (x[1] - y[1]) * (x[1] -
y[1])
+... return math.exp(-dist / 2.0)
+>>> r1 = 1.0
+>>> n1 = 10
+>>> r2 = 4.0
+>>> n2 = 40
+>>> n = n1 + n2
+>>> points = genCircle(r1, n1) + genCircle(r2, n2)
+>>> similarities = []
+>>> for i in range (1, n):
+...neighbor = []
+...weight = []
+...for j in range (i):
+...neighbor.append((long)(j))
+...weight.append(sim(points[i], points[j]))
+...similarities.append([(long)(i), neighbor, weight])
+>>> rdd = sc.parallelize(similarities, 2)
+>>> schema = StructType([StructField("id", LongType(), False), \
+ StructField(&
[GitHub] spark pull request #21119: [SPARK-19826][ML][PYTHON]add spark.ml Python API ...
Github user WeichenXu123 commented on a diff in the pull request:
https://github.com/apache/spark/pull/21119#discussion_r184345688
--- Diff: python/pyspark/ml/clustering.py ---
@@ -1156,6 +1156,201 @@ def getKeepLastCheckpoint(self):
return self.getOrDefault(self.keepLastCheckpoint)
+class _PowerIterationClusteringParams(JavaParams, HasMaxIter,
HasPredictionCol):
+"""
+Params for :py:attr:`PowerIterationClustering`.
+.. versionadded:: 2.4.0
+"""
+
+k = Param(Params._dummy(), "k",
+ "The number of clusters to create. Must be > 1.",
+ typeConverter=TypeConverters.toInt)
+initMode = Param(Params._dummy(), "initMode",
+ "The initialization algorithm. This can be either " +
+ "'random' to use a random vector as vertex
properties, or 'degree' to use " +
+ "a normalized sum of similarities with other
vertices. Supported options: " +
+ "'random' and 'degree'.",
+ typeConverter=TypeConverters.toString)
+idCol = Param(Params._dummy(), "idCol",
+ "Name of the input column for vertex IDs.",
+ typeConverter=TypeConverters.toString)
+neighborsCol = Param(Params._dummy(), "neighborsCol",
+ "Name of the input column for neighbors in the
adjacency list " +
+ "representation.",
+ typeConverter=TypeConverters.toString)
+similaritiesCol = Param(Params._dummy(), "similaritiesCol",
+"Name of the input column for non-negative
weights (similarities) " +
+"of edges between the vertex in `idCol` and
each neighbor in " +
+"`neighborsCol`",
+typeConverter=TypeConverters.toString)
+
+@since("2.4.0")
+def getK(self):
+"""
+Gets the value of `k`
--- End diff --
Should use:
:py:attr:`k`
and update everywhere else.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21163: [SPARK-24097][ML] Instruments improvements - Rand...
GitHub user WeichenXu123 opened a pull request: https://github.com/apache/spark/pull/21163 [SPARK-24097][ML] Instruments improvements - RandomForest and GradientBoostedTree ## What changes were proposed in this pull request? Instruments improvements for `RandomForest` and `GradientBoostedTree` in `ml.tree.impl` package. **Note:** I add `Instrumentation` and `OptionalInstrumentation` with `Serializable`. Because tree algos need to ouput some logs on executor side and the instrumentation object need to be broadcast. ## How was this patch tested? Manual. You can merge this pull request into a Git repository by running: $ git pull https://github.com/WeichenXu123/spark instr_rf_gbt Alternatively you can review and apply these changes as the patch at: https://github.com/apache/spark/pull/21163.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #21163 commit cd5ea88687b72335647d74c0aeef375de01724d9 Author: WeichenXu <weichen.xu@...> Date: 2018-04-26T04:59:18Z init pr --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21120: [SPARK-22448][ML] Added sum function to Summerizer and M...
Github user WeichenXu123 commented on the issue: https://github.com/apache/spark/pull/21120 I doubt that this will slow down the summarizer performance because you add sum statistics internally (and this sum value will possible to overflow). We can directly use `count * mean` to get the sum if we want to use it. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #17086: [SPARK-18693][ML][MLLIB] ML Evaluators should use...
Github user WeichenXu123 commented on a diff in the pull request:
https://github.com/apache/spark/pull/17086#discussion_r183645675
--- Diff:
mllib/src/test/scala/org/apache/spark/mllib/evaluation/MulticlassMetricsSuite.scala
---
@@ -95,4 +95,95 @@ class MulticlassMetricsSuite extends SparkFunSuite with
MLlibTestSparkContext {
((4.0 / 9) * f2measure0 + (4.0 / 9) * f2measure1 + (1.0 / 9) *
f2measure2)) < delta)
assert(metrics.labels.sameElements(labels))
}
+
+ test("Multiclass evaluation metrics with weights") {
+/*
+ * Confusion matrix for 3-class classification with total 9 instances
with 2 weights:
+ * |2 * w1|1 * w2 |1 * w1| true class0 (4 instances)
+ * |1 * w2|2 * w1 + 1 * w2|0 | true class1 (4 instances)
+ * |0 |0 |1 * w2| true class2 (1 instance)
+ */
+val w1 = 2.2
+val w2 = 1.5
+val tw = 2.0 * w1 + 1.0 * w2 + 1.0 * w1 + 1.0 * w2 + 2.0 * w1 + 1.0 *
w2 + 1.0 * w2
+val confusionMatrix = Matrices.dense(3, 3,
+ Array(2 * w1, 1 * w2, 0, 1 * w2, 2 * w1 + 1 * w2, 0, 1 * w1, 0, 1 *
w2))
+val labels = Array(0.0, 1.0, 2.0)
+val predictionAndLabelsWithWeights = sc.parallelize(
+ Seq((0.0, 0.0, w1), (0.0, 1.0, w2), (0.0, 0.0, w1), (1.0, 0.0, w2),
+(1.0, 1.0, w1), (1.0, 1.0, w2), (1.0, 1.0, w1), (2.0, 2.0, w2),
+(2.0, 0.0, w1)), 2)
+val metrics = new MulticlassMetrics(predictionAndLabelsWithWeights)
+val delta = 0.001
+val tpRate0 = (2.0 * w1) / (2.0 * w1 + 1.0 * w2 + 1.0 * w1)
+val tpRate1 = (2.0 * w1 + 1.0 * w2) / (2.0 * w1 + 1.0 * w2 + 1.0 * w2)
+val tpRate2 = (1.0 * w2) / (1.0 * w2 + 0)
+val fpRate0 = (1.0 * w2) / (tw - (2.0 * w1 + 1.0 * w2 + 1.0 * w1))
+val fpRate1 = (1.0 * w2) / (tw - (1.0 * w2 + 2.0 * w1 + 1.0 * w2))
+val fpRate2 = (1.0 * w1) / (tw - (1.0 * w2))
+val precision0 = (2.0 * w1) / (2 * w1 + 1 * w2)
+val precision1 = (2.0 * w1 + 1.0 * w2) / (2.0 * w1 + 1.0 * w2 + 1.0 *
w2)
+val precision2 = (1.0 * w2) / (1 * w1 + 1 * w2)
+val recall0 = (2.0 * w1) / (2.0 * w1 + 1.0 * w2 + 1.0 * w1)
+val recall1 = (2.0 * w1 + 1.0 * w2) / (2.0 * w1 + 1.0 * w2 + 1.0 * w2)
+val recall2 = (1.0 * w2) / (1.0 * w2 + 0)
+val f1measure0 = 2 * precision0 * recall0 / (precision0 + recall0)
+val f1measure1 = 2 * precision1 * recall1 / (precision1 + recall1)
+val f1measure2 = 2 * precision2 * recall2 / (precision2 + recall2)
+val f2measure0 = (1 + 2 * 2) * precision0 * recall0 / (2 * 2 *
precision0 + recall0)
+val f2measure1 = (1 + 2 * 2) * precision1 * recall1 / (2 * 2 *
precision1 + recall1)
+val f2measure2 = (1 + 2 * 2) * precision2 * recall2 / (2 * 2 *
precision2 + recall2)
+
+
assert(metrics.confusionMatrix.toArray.sameElements(confusionMatrix.toArray))
+assert(math.abs(metrics.truePositiveRate(0.0) - tpRate0) < delta)
--- End diff --
Use operator `A ~== B absTol delta` like other tests.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #17086: [SPARK-18693][ML][MLLIB] ML Evaluators should use...
Github user WeichenXu123 commented on a diff in the pull request:
https://github.com/apache/spark/pull/17086#discussion_r183647005
--- Diff:
mllib/src/test/scala/org/apache/spark/mllib/evaluation/MulticlassMetricsSuite.scala
---
@@ -95,4 +95,95 @@ class MulticlassMetricsSuite extends SparkFunSuite with
MLlibTestSparkContext {
((4.0 / 9) * f2measure0 + (4.0 / 9) * f2measure1 + (1.0 / 9) *
f2measure2)) < delta)
assert(metrics.labels.sameElements(labels))
}
+
+ test("Multiclass evaluation metrics with weights") {
+/*
+ * Confusion matrix for 3-class classification with total 9 instances
with 2 weights:
+ * |2 * w1|1 * w2 |1 * w1| true class0 (4 instances)
+ * |1 * w2|2 * w1 + 1 * w2|0 | true class1 (4 instances)
+ * |0 |0 |1 * w2| true class2 (1 instance)
+ */
+val w1 = 2.2
+val w2 = 1.5
+val tw = 2.0 * w1 + 1.0 * w2 + 1.0 * w1 + 1.0 * w2 + 2.0 * w1 + 1.0 *
w2 + 1.0 * w2
+val confusionMatrix = Matrices.dense(3, 3,
+ Array(2 * w1, 1 * w2, 0, 1 * w2, 2 * w1 + 1 * w2, 0, 1 * w1, 0, 1 *
w2))
+val labels = Array(0.0, 1.0, 2.0)
+val predictionAndLabelsWithWeights = sc.parallelize(
+ Seq((0.0, 0.0, w1), (0.0, 1.0, w2), (0.0, 0.0, w1), (1.0, 0.0, w2),
+(1.0, 1.0, w1), (1.0, 1.0, w2), (1.0, 1.0, w1), (2.0, 2.0, w2),
+(2.0, 0.0, w1)), 2)
+val metrics = new MulticlassMetrics(predictionAndLabelsWithWeights)
+val delta = 0.001
+val tpRate0 = (2.0 * w1) / (2.0 * w1 + 1.0 * w2 + 1.0 * w1)
+val tpRate1 = (2.0 * w1 + 1.0 * w2) / (2.0 * w1 + 1.0 * w2 + 1.0 * w2)
+val tpRate2 = (1.0 * w2) / (1.0 * w2 + 0)
+val fpRate0 = (1.0 * w2) / (tw - (2.0 * w1 + 1.0 * w2 + 1.0 * w1))
+val fpRate1 = (1.0 * w2) / (tw - (1.0 * w2 + 2.0 * w1 + 1.0 * w2))
+val fpRate2 = (1.0 * w1) / (tw - (1.0 * w2))
+val precision0 = (2.0 * w1) / (2 * w1 + 1 * w2)
+val precision1 = (2.0 * w1 + 1.0 * w2) / (2.0 * w1 + 1.0 * w2 + 1.0 *
w2)
+val precision2 = (1.0 * w2) / (1 * w1 + 1 * w2)
+val recall0 = (2.0 * w1) / (2.0 * w1 + 1.0 * w2 + 1.0 * w1)
+val recall1 = (2.0 * w1 + 1.0 * w2) / (2.0 * w1 + 1.0 * w2 + 1.0 * w2)
+val recall2 = (1.0 * w2) / (1.0 * w2 + 0)
+val f1measure0 = 2 * precision0 * recall0 / (precision0 + recall0)
+val f1measure1 = 2 * precision1 * recall1 / (precision1 + recall1)
+val f1measure2 = 2 * precision2 * recall2 / (precision2 + recall2)
+val f2measure0 = (1 + 2 * 2) * precision0 * recall0 / (2 * 2 *
precision0 + recall0)
+val f2measure1 = (1 + 2 * 2) * precision1 * recall1 / (2 * 2 *
precision1 + recall1)
+val f2measure2 = (1 + 2 * 2) * precision2 * recall2 / (2 * 2 *
precision2 + recall2)
+
+
assert(metrics.confusionMatrix.toArray.sameElements(confusionMatrix.toArray))
+assert(math.abs(metrics.truePositiveRate(0.0) - tpRate0) < delta)
+assert(math.abs(metrics.truePositiveRate(1.0) - tpRate1) < delta)
+assert(math.abs(metrics.truePositiveRate(2.0) - tpRate2) < delta)
+assert(math.abs(metrics.falsePositiveRate(0.0) - fpRate0) < delta)
+assert(math.abs(metrics.falsePositiveRate(1.0) - fpRate1) < delta)
+assert(math.abs(metrics.falsePositiveRate(2.0) - fpRate2) < delta)
+assert(math.abs(metrics.precision(0.0) - precision0) < delta)
+assert(math.abs(metrics.precision(1.0) - precision1) < delta)
+assert(math.abs(metrics.precision(2.0) - precision2) < delta)
+assert(math.abs(metrics.recall(0.0) - recall0) < delta)
+assert(math.abs(metrics.recall(1.0) - recall1) < delta)
+assert(math.abs(metrics.recall(2.0) - recall2) < delta)
+assert(math.abs(metrics.fMeasure(0.0) - f1measure0) < delta)
+assert(math.abs(metrics.fMeasure(1.0) - f1measure1) < delta)
+assert(math.abs(metrics.fMeasure(2.0) - f1measure2) < delta)
+assert(math.abs(metrics.fMeasure(0.0, 2.0) - f2measure0) < delta)
+assert(math.abs(metrics.fMeasure(1.0, 2.0) - f2measure1) < delta)
+assert(math.abs(metrics.fMeasure(2.0, 2.0) - f2measure2) < delta)
+
+assert(math.abs(metrics.accuracy -
+ (2.0 * w1 + 2.0 * w1 + 1.0 * w2 + 1.0 * w2) / tw) < delta)
+assert(math.abs(metrics.accuracy - metrics.precision) < delta)
+assert(math.abs(metrics.accuracy - metrics.recall) < delta)
+assert(math.abs(metrics.accuracy - metrics.fMeasure) < delta)
+assert(math.abs(metrics.accuracy - metrics.weightedRecall) < delta)
+assert(math.abs(metrics.weightedTruePositiveRate -
+ (((2 * w1 + 1 * w2 + 1 * w1) / tw) * tpRate0 +
+((1 * w2 + 2 * w1 + 1 * w2) / tw) * tpRate1 +
+(1 * w2 / tw) * tpRate2)) <
[GitHub] spark pull request #17086: [SPARK-18693][ML][MLLIB] ML Evaluators should use...
Github user WeichenXu123 commented on a diff in the pull request:
https://github.com/apache/spark/pull/17086#discussion_r183645265
--- Diff:
mllib/src/test/scala/org/apache/spark/mllib/evaluation/MulticlassMetricsSuite.scala
---
@@ -95,4 +95,95 @@ class MulticlassMetricsSuite extends SparkFunSuite with
MLlibTestSparkContext {
((4.0 / 9) * f2measure0 + (4.0 / 9) * f2measure1 + (1.0 / 9) *
f2measure2)) < delta)
assert(metrics.labels.sameElements(labels))
}
+
+ test("Multiclass evaluation metrics with weights") {
+/*
+ * Confusion matrix for 3-class classification with total 9 instances
with 2 weights:
+ * |2 * w1|1 * w2 |1 * w1| true class0 (4 instances)
+ * |1 * w2|2 * w1 + 1 * w2|0 | true class1 (4 instances)
+ * |0 |0 |1 * w2| true class2 (1 instance)
+ */
+val w1 = 2.2
+val w2 = 1.5
+val tw = 2.0 * w1 + 1.0 * w2 + 1.0 * w1 + 1.0 * w2 + 2.0 * w1 + 1.0 *
w2 + 1.0 * w2
+val confusionMatrix = Matrices.dense(3, 3,
+ Array(2 * w1, 1 * w2, 0, 1 * w2, 2 * w1 + 1 * w2, 0, 1 * w1, 0, 1 *
w2))
+val labels = Array(0.0, 1.0, 2.0)
+val predictionAndLabelsWithWeights = sc.parallelize(
+ Seq((0.0, 0.0, w1), (0.0, 1.0, w2), (0.0, 0.0, w1), (1.0, 0.0, w2),
+(1.0, 1.0, w1), (1.0, 1.0, w2), (1.0, 1.0, w1), (2.0, 2.0, w2),
+(2.0, 0.0, w1)), 2)
+val metrics = new MulticlassMetrics(predictionAndLabelsWithWeights)
+val delta = 0.001
--- End diff --
use `1E-7` ?
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #17086: [SPARK-18693][ML][MLLIB] ML Evaluators should use...
Github user WeichenXu123 commented on a diff in the pull request:
https://github.com/apache/spark/pull/17086#discussion_r183647533
--- Diff:
mllib/src/test/scala/org/apache/spark/mllib/evaluation/MulticlassMetricsSuite.scala
---
@@ -95,4 +95,95 @@ class MulticlassMetricsSuite extends SparkFunSuite with
MLlibTestSparkContext {
((4.0 / 9) * f2measure0 + (4.0 / 9) * f2measure1 + (1.0 / 9) *
f2measure2)) < delta)
assert(metrics.labels.sameElements(labels))
}
+
+ test("Multiclass evaluation metrics with weights") {
+/*
+ * Confusion matrix for 3-class classification with total 9 instances
with 2 weights:
+ * |2 * w1|1 * w2 |1 * w1| true class0 (4 instances)
+ * |1 * w2|2 * w1 + 1 * w2|0 | true class1 (4 instances)
+ * |0 |0 |1 * w2| true class2 (1 instance)
+ */
+val w1 = 2.2
+val w2 = 1.5
+val tw = 2.0 * w1 + 1.0 * w2 + 1.0 * w1 + 1.0 * w2 + 2.0 * w1 + 1.0 *
w2 + 1.0 * w2
+val confusionMatrix = Matrices.dense(3, 3,
+ Array(2 * w1, 1 * w2, 0, 1 * w2, 2 * w1 + 1 * w2, 0, 1 * w1, 0, 1 *
w2))
+val labels = Array(0.0, 1.0, 2.0)
+val predictionAndLabelsWithWeights = sc.parallelize(
+ Seq((0.0, 0.0, w1), (0.0, 1.0, w2), (0.0, 0.0, w1), (1.0, 0.0, w2),
+(1.0, 1.0, w1), (1.0, 1.0, w2), (1.0, 1.0, w1), (2.0, 2.0, w2),
+(2.0, 0.0, w1)), 2)
+val metrics = new MulticlassMetrics(predictionAndLabelsWithWeights)
+val delta = 0.001
+val tpRate0 = (2.0 * w1) / (2.0 * w1 + 1.0 * w2 + 1.0 * w1)
+val tpRate1 = (2.0 * w1 + 1.0 * w2) / (2.0 * w1 + 1.0 * w2 + 1.0 * w2)
+val tpRate2 = (1.0 * w2) / (1.0 * w2 + 0)
+val fpRate0 = (1.0 * w2) / (tw - (2.0 * w1 + 1.0 * w2 + 1.0 * w1))
+val fpRate1 = (1.0 * w2) / (tw - (1.0 * w2 + 2.0 * w1 + 1.0 * w2))
+val fpRate2 = (1.0 * w1) / (tw - (1.0 * w2))
+val precision0 = (2.0 * w1) / (2 * w1 + 1 * w2)
+val precision1 = (2.0 * w1 + 1.0 * w2) / (2.0 * w1 + 1.0 * w2 + 1.0 *
w2)
+val precision2 = (1.0 * w2) / (1 * w1 + 1 * w2)
+val recall0 = (2.0 * w1) / (2.0 * w1 + 1.0 * w2 + 1.0 * w1)
+val recall1 = (2.0 * w1 + 1.0 * w2) / (2.0 * w1 + 1.0 * w2 + 1.0 * w2)
+val recall2 = (1.0 * w2) / (1.0 * w2 + 0)
+val f1measure0 = 2 * precision0 * recall0 / (precision0 + recall0)
+val f1measure1 = 2 * precision1 * recall1 / (precision1 + recall1)
+val f1measure2 = 2 * precision2 * recall2 / (precision2 + recall2)
+val f2measure0 = (1 + 2 * 2) * precision0 * recall0 / (2 * 2 *
precision0 + recall0)
+val f2measure1 = (1 + 2 * 2) * precision1 * recall1 / (2 * 2 *
precision1 + recall1)
+val f2measure2 = (1 + 2 * 2) * precision2 * recall2 / (2 * 2 *
precision2 + recall2)
+
+
assert(metrics.confusionMatrix.toArray.sameElements(confusionMatrix.toArray))
--- End diff --
don't `toArray`, use `assert(metrics.confusionMatrix ~== confusionMatrix
relTol e)`
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #17086: [SPARK-18693][ML][MLLIB] ML Evaluators should use...
Github user WeichenXu123 commented on a diff in the pull request:
https://github.com/apache/spark/pull/17086#discussion_r183646411
--- Diff:
mllib/src/test/scala/org/apache/spark/mllib/evaluation/MulticlassMetricsSuite.scala
---
@@ -95,4 +95,95 @@ class MulticlassMetricsSuite extends SparkFunSuite with
MLlibTestSparkContext {
((4.0 / 9) * f2measure0 + (4.0 / 9) * f2measure1 + (1.0 / 9) *
f2measure2)) < delta)
assert(metrics.labels.sameElements(labels))
}
+
+ test("Multiclass evaluation metrics with weights") {
+/*
+ * Confusion matrix for 3-class classification with total 9 instances
with 2 weights:
+ * |2 * w1|1 * w2 |1 * w1| true class0 (4 instances)
+ * |1 * w2|2 * w1 + 1 * w2|0 | true class1 (4 instances)
+ * |0 |0 |1 * w2| true class2 (1 instance)
+ */
+val w1 = 2.2
+val w2 = 1.5
+val tw = 2.0 * w1 + 1.0 * w2 + 1.0 * w1 + 1.0 * w2 + 2.0 * w1 + 1.0 *
w2 + 1.0 * w2
+val confusionMatrix = Matrices.dense(3, 3,
+ Array(2 * w1, 1 * w2, 0, 1 * w2, 2 * w1 + 1 * w2, 0, 1 * w1, 0, 1 *
w2))
+val labels = Array(0.0, 1.0, 2.0)
+val predictionAndLabelsWithWeights = sc.parallelize(
+ Seq((0.0, 0.0, w1), (0.0, 1.0, w2), (0.0, 0.0, w1), (1.0, 0.0, w2),
+(1.0, 1.0, w1), (1.0, 1.0, w2), (1.0, 1.0, w1), (2.0, 2.0, w2),
+(2.0, 0.0, w1)), 2)
+val metrics = new MulticlassMetrics(predictionAndLabelsWithWeights)
+val delta = 0.001
+val tpRate0 = (2.0 * w1) / (2.0 * w1 + 1.0 * w2 + 1.0 * w1)
+val tpRate1 = (2.0 * w1 + 1.0 * w2) / (2.0 * w1 + 1.0 * w2 + 1.0 * w2)
+val tpRate2 = (1.0 * w2) / (1.0 * w2 + 0)
+val fpRate0 = (1.0 * w2) / (tw - (2.0 * w1 + 1.0 * w2 + 1.0 * w1))
+val fpRate1 = (1.0 * w2) / (tw - (1.0 * w2 + 2.0 * w1 + 1.0 * w2))
+val fpRate2 = (1.0 * w1) / (tw - (1.0 * w2))
+val precision0 = (2.0 * w1) / (2 * w1 + 1 * w2)
+val precision1 = (2.0 * w1 + 1.0 * w2) / (2.0 * w1 + 1.0 * w2 + 1.0 *
w2)
+val precision2 = (1.0 * w2) / (1 * w1 + 1 * w2)
+val recall0 = (2.0 * w1) / (2.0 * w1 + 1.0 * w2 + 1.0 * w1)
+val recall1 = (2.0 * w1 + 1.0 * w2) / (2.0 * w1 + 1.0 * w2 + 1.0 * w2)
+val recall2 = (1.0 * w2) / (1.0 * w2 + 0)
+val f1measure0 = 2 * precision0 * recall0 / (precision0 + recall0)
+val f1measure1 = 2 * precision1 * recall1 / (precision1 + recall1)
+val f1measure2 = 2 * precision2 * recall2 / (precision2 + recall2)
+val f2measure0 = (1 + 2 * 2) * precision0 * recall0 / (2 * 2 *
precision0 + recall0)
+val f2measure1 = (1 + 2 * 2) * precision1 * recall1 / (2 * 2 *
precision1 + recall1)
+val f2measure2 = (1 + 2 * 2) * precision2 * recall2 / (2 * 2 *
precision2 + recall2)
+
+
assert(metrics.confusionMatrix.toArray.sameElements(confusionMatrix.toArray))
+assert(math.abs(metrics.truePositiveRate(0.0) - tpRate0) < delta)
+assert(math.abs(metrics.truePositiveRate(1.0) - tpRate1) < delta)
+assert(math.abs(metrics.truePositiveRate(2.0) - tpRate2) < delta)
+assert(math.abs(metrics.falsePositiveRate(0.0) - fpRate0) < delta)
+assert(math.abs(metrics.falsePositiveRate(1.0) - fpRate1) < delta)
+assert(math.abs(metrics.falsePositiveRate(2.0) - fpRate2) < delta)
+assert(math.abs(metrics.precision(0.0) - precision0) < delta)
+assert(math.abs(metrics.precision(1.0) - precision1) < delta)
+assert(math.abs(metrics.precision(2.0) - precision2) < delta)
+assert(math.abs(metrics.recall(0.0) - recall0) < delta)
+assert(math.abs(metrics.recall(1.0) - recall1) < delta)
+assert(math.abs(metrics.recall(2.0) - recall2) < delta)
+assert(math.abs(metrics.fMeasure(0.0) - f1measure0) < delta)
+assert(math.abs(metrics.fMeasure(1.0) - f1measure1) < delta)
+assert(math.abs(metrics.fMeasure(2.0) - f1measure2) < delta)
+assert(math.abs(metrics.fMeasure(0.0, 2.0) - f2measure0) < delta)
+assert(math.abs(metrics.fMeasure(1.0, 2.0) - f2measure1) < delta)
+assert(math.abs(metrics.fMeasure(2.0, 2.0) - f2measure2) < delta)
+
+assert(math.abs(metrics.accuracy -
+ (2.0 * w1 + 2.0 * w1 + 1.0 * w2 + 1.0 * w2) / tw) < delta)
+assert(math.abs(metrics.accuracy - metrics.precision) < delta)
+assert(math.abs(metrics.accuracy - metrics.recall) < delta)
+assert(math.abs(metrics.accuracy - metrics.fMeasure) < delta)
+assert(math.abs(metrics.accuracy - metrics.weightedRecall) < delta)
+assert(math.abs(metrics.weightedTruePositiveRate -
+ (((2 * w1 + 1 * w2 + 1 * w1) / tw) * tpRate0 +
+((1 * w2 + 2 * w1 + 1 * w2) / tw) * tpRate1 +
+(1 * w2 / tw) * tpRate2)) <
[GitHub] spark issue #21129: [SPARK-7132][ML] Add fit with validation set to spark.ml...
Github user WeichenXu123 commented on the issue: https://github.com/apache/spark/pull/21129 Jenkins, test this please. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org