[GitHub] spark issue #22887: [SPARK-25880][CORE] user set's hadoop conf should not ov...
Github user cxzl25 commented on the issue:
https://github.com/apache/spark/pull/22887
user set hadoop conf can't overwrite spark-defaults.conf
**SparkHadoopUtil.get.appendS3AndSparkHadoopConfigurations** overwrite the
user-set spark.hadoop with the default configuration
(sparkSession.sparkContext.conf)
@gengliangwang @cloud-fan @gatorsmile
Could you please give some comments when you have time?
Thanks so much.
https://github.com/apache/spark/blob/80813e198033cd63cc6100ee6ffe7d1eb1dff27b/sql/hive/src/main/scala/org/apache/spark/sql/hive/TableReader.scala#L85-L89
## test:
### spark-defaults.conf
```
spark.hadoop.mapreduce.input.fileinputformat.split.maxsize 2
```
### spark-shell
```scala
val hadoopConfKey="mapreduce.input.fileinputformat.split.maxsize"
spark.conf.get("spark.hadoop."+hadoopConfKey) // 2
var hadoopConf=spark.sessionState.newHadoopConf
hadoopConf.get(hadoopConfKey) // 2
spark.conf.set(hadoopConfKey,1) // set 1
hadoopConf=spark.sessionState.newHadoopConf
hadoopConf.get(hadoopConfKey) // 1
//org.apache.spark.sql.hive.HadoopTableReader append Conf
org.apache.spark.deploy.SparkHadoopUtil.get.appendS3AndSparkHadoopConfigurations(spark.sparkContext.getConf,
hadoopConf)
//org.apache.spark.sql.hive.HadoopTableReader _broadcastedHadoopConf
hadoopConf.get("mapreduce.input.fileinputformat.split.maxsize") // 2
```
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21364: [SPARK-24317][SQL]Float-point numbers are display...
Github user cxzl25 closed the pull request at: https://github.com/apache/spark/pull/21364 --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21656: [SPARK-24677][Core]Avoid NoSuchElementException from Med...
Github user cxzl25 commented on the issue: https://github.com/apache/spark/pull/21656 @tgravescs This is really not difficult. I'm just not sure if we want to ignore or send down the real time. Now I have submitted a change, use actual time of successful task. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21656: [SPARK-24677][Core]MedianHeap is empty when specu...
Github user cxzl25 commented on a diff in the pull request:
https://github.com/apache/spark/pull/21656#discussion_r200236204
--- Diff:
core/src/main/scala/org/apache/spark/scheduler/TaskSetManager.scala ---
@@ -772,6 +772,12 @@ private[spark] class TaskSetManager(
private[scheduler] def markPartitionCompleted(partitionId: Int): Unit = {
partitionToIndex.get(partitionId).foreach { index =>
if (!successful(index)) {
+if (speculationEnabled) {
+ taskAttempts(index).headOption.map { info =>
+info.markFinished(TaskState.FINISHED, clock.getTimeMillis())
+successfulTaskDurations.insert(info.duration)
--- End diff --
TaskSetManager#handleSuccessfulTask update successful task durations, and
write to successfulTaskDurations.
When there are multiple tasksets for this stage,
markPartitionCompletedInAllTaskSets is
accumulate the value of tasksSuccessful.
In this case, when checkSpeculatableTasks is called, the value of
tasksSuccessful matches the condition, but successfulTaskDurations is empty.
https://github.com/apache/spark/blob/master/core/src/main/scala/org/apache/spark/scheduler/TaskSetManager.scala#L723
```scala
def handleSuccessfulTask(tid: Long, result: DirectTaskResult[_]): Unit = {
val info = taskInfos(tid)
val index = info.index
info.markFinished(TaskState.FINISHED, clock.getTimeMillis())
if (speculationEnabled) {
successfulTaskDurations.insert(info.duration)
}
// ...
// There may be multiple tasksets for this stage -- we let all of them
know that the partition
// was completed. This may result in some of the tasksets getting
completed.
sched.markPartitionCompletedInAllTaskSets(stageId,
tasks(index).partitionId)
```
https://github.com/apache/spark/blob/master/core/src/main/scala/org/apache/spark/scheduler/TaskSetManager.scala#L987
```scala
override def checkSpeculatableTasks(minTimeToSpeculation: Int): Boolean = {
//...
if (tasksSuccessful >= minFinishedForSpeculation && tasksSuccessful > 0) {
val time = clock.getTimeMillis()
val medianDuration = successfulTaskDurations.median
```
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21656: [SPARK-24677][Core]MedianHeap is empty when speculation ...
Github user cxzl25 commented on the issue: https://github.com/apache/spark/pull/21656 @maropu @cloud-fan @squito Can you trigger a test for this? This is the exception stack in the log: ``` ERROR Utils: uncaught error in thread task-scheduler-speculation, stopping SparkContext java.util.NoSuchElementException: MedianHeap is empty. at org.apache.spark.util.collection.MedianHeap.median(MedianHeap.scala:83) at org.apache.spark.scheduler.TaskSetManager.checkSpeculatableTasks(TaskSetManager.scala:968) at org.apache.spark.scheduler.Pool$$anonfun$checkSpeculatableTasks$1.apply(Pool.scala:94) at org.apache.spark.scheduler.Pool$$anonfun$checkSpeculatableTasks$1.apply(Pool.scala:93) at scala.collection.Iterator$class.foreach(Iterator.scala:742) at scala.collection.AbstractIterator.foreach(Iterator.scala:1194) at scala.collection.IterableLike$class.foreach(IterableLike.scala:72) at scala.collection.AbstractIterable.foreach(Iterable.scala:54) at org.apache.spark.scheduler.Pool.checkSpeculatableTasks(Pool.scala:93) at org.apache.spark.scheduler.Pool$$anonfun$checkSpeculatableTasks$1.apply(Pool.scala:94) at org.apache.spark.scheduler.Pool$$anonfun$checkSpeculatableTasks$1.apply(Pool.scala:93) ``` --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21656: [SPARK-24677][Core]MedianHeap is empty when speculation ...
Github user cxzl25 commented on the issue: https://github.com/apache/spark/pull/21656 @maropu I have added a unit test. Can you trigger a test for this? --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21656: [SPARK-24677][Core]MedianHeap is empty when specu...
GitHub user cxzl25 opened a pull request: https://github.com/apache/spark/pull/21656 [SPARK-24677][Core]MedianHeap is empty when speculation is enabled, causing the SparkContext to stop ## What changes were proposed in this pull request? When speculation is enabled, TaskSetManager#markPartitionCompleted should write successful task duration to MedianHeap, not just increase tasksSuccessful. Otherwise when TaskSetManager#checkSpeculatableTasks,tasksSuccessful non-zero, but MedianHeap is empty. Then throw an exception successfulTaskDurations.median java.util.NoSuchElementException: MedianHeap is empty. Finally led to stopping SparkContext. ## How was this patch tested? manual tests You can merge this pull request into a Git repository by running: $ git pull https://github.com/cxzl25/spark fix_MedianHeap_empty Alternatively you can review and apply these changes as the patch at: https://github.com/apache/spark/pull/21656.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #21656 commit 467f0bccb7d1940bed4f1b2e633c9374b0e654f2 Author: sychen Date: 2018-06-28T07:34:38Z MedianHeap is empty when speculation is enabled, causing the SparkContext to stop. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #20739: [SPARK-23603][SQL]When the length of the json is ...
Github user cxzl25 closed the pull request at: https://github.com/apache/spark/pull/20739 --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #20738: [SPARK-23603][SQL]When the length of the json is ...
Github user cxzl25 closed the pull request at: https://github.com/apache/spark/pull/20738 --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21596: [SPARK-24601] Bump Jackson version
Github user cxzl25 commented on the issue:
https://github.com/apache/spark/pull/21596
https://github.com/apache/spark/pull/20738
Bump jackson from 2.6.7&2.6.7.1 to 2.7.7
Jackson(>=2.7.7) fixes the possibility of missing tail data when the length
of the value is in a range
[https://github.com/FasterXML/jackson/wiki/Jackson-Release-2.7.7](https://github.com/FasterXML/jackson/wiki/Jackson-Release-2.7.7)
[https://github.com/FasterXML/jackson-core/issues/30](https://github.com/FasterXML/jackson-core/issues/307)
spark-shell:
```
val value = "x" * 3000
val json = s"""{"big": "$value"}"""
spark.sql("select length(get_json_object(\'"+json+"\','$.big'))" ).collect
res0: Array[org.apache.spark.sql.Row] = Array([2991])
```
expect result : 3000
actual result : 2991
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #18900: [SPARK-21687][SQL] Spark SQL should set createTim...
Github user cxzl25 commented on a diff in the pull request:
https://github.com/apache/spark/pull/18900#discussion_r193685282
--- Diff:
sql/hive/src/main/scala/org/apache/spark/sql/hive/client/HiveClientImpl.scala
---
@@ -1019,6 +1021,8 @@ private[hive] object HiveClientImpl {
compressed = apiPartition.getSd.isCompressed,
properties = Option(apiPartition.getSd.getSerdeInfo.getParameters)
.map(_.asScala.toMap).orNull),
+ createTime = apiPartition.getCreateTime.toLong * 1000,
+ lastAccessTime = apiPartition.getLastAccessTime.toLong * 1000)
--- End diff --
Add a comma to the end?
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #18900: [SPARK-21687][SQL] Spark SQL should set createTime for H...
Github user cxzl25 commented on the issue: https://github.com/apache/spark/pull/18900 **Modify the partition will lose createTime.** Reading the hive partitions ignores createTime when converting the CatalogTablePartition, it will also be lost when modifying partitions. Calling this method SessionCatalog#alterPartitions will be lost createTime. So can you reopen this pr? @debugger87 ```sql CREATE TABLE `tmp_test_partition`( `c1` string ) PARTITIONED BY ( `d` string ); ALTER TABLE `tmp_test_partition_1` ADD PARTITION (d='1'); ALTER TABLE `tmp_test_partition_1` PARTITION (d='1') SET LOCATION 'xxx'; ``` --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21164: [SPARK-24098][SQL] ScriptTransformationExec should wait ...
Github user cxzl25 commented on the issue:
https://github.com/apache/spark/pull/21164
@liutang123 cc @cloud-fan @gatorsmile
I also encountered this problem.
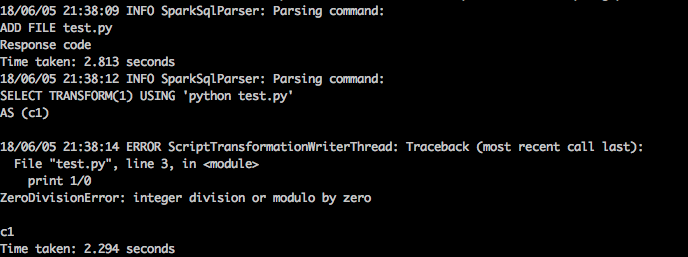
python:
```python
import sys
for line in sys.stdin:
print 1/0
```
sql:
```sql
ADD FILE test.py;
SELECT TRANSFORM(1) USING 'python test.py'
AS (c1)
```
I solved it this way: *writerThread.join()*
```java
if (scriptOutputReader.next(scriptOutputWritable) <= 0) {
writerThread.join()
checkFailureAndPropagate()
return false
}
```
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21364: [SPARK-24317][SQL]Float-point numbers are displayed with...
Github user cxzl25 commented on the issue: https://github.com/apache/spark/pull/21364 ping @gatorsmile @liufengdb --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21311: [SPARK-24257][SQL]LongToUnsafeRowMap calculate the new s...
Github user cxzl25 commented on the issue: https://github.com/apache/spark/pull/21311 @cloud-fan Thank you very much for your help. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21311: [SPARK-24257][SQL]LongToUnsafeRowMap calculate th...
Github user cxzl25 commented on a diff in the pull request:
https://github.com/apache/spark/pull/21311#discussion_r190345942
--- Diff:
sql/core/src/test/scala/org/apache/spark/sql/execution/joins/HashedRelationSuite.scala
---
@@ -254,6 +254,30 @@ class HashedRelationSuite extends SparkFunSuite with
SharedSQLContext {
map.free()
}
+ test("LongToUnsafeRowMap with big values") {
+val taskMemoryManager = new TaskMemoryManager(
+ new StaticMemoryManager(
+new SparkConf().set(MEMORY_OFFHEAP_ENABLED.key, "false"),
+Long.MaxValue,
+Long.MaxValue,
+1),
+ 0)
+val unsafeProj = UnsafeProjection.create(Array[DataType](StringType))
+val map = new LongToUnsafeRowMap(taskMemoryManager, 1)
+
+val key = 0L
+// the page array is initialized with length 1 << 17 (1M bytes),
+// so here we need a value larger than 1 << 18 (2M bytes),to trigger
the bug
+val bigStr = UTF8String.fromString("x" * (1 << 22))
--- End diff --
Yes. I think so.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21311: [SPARK-24257][SQL]LongToUnsafeRowMap calculate th...
Github user cxzl25 commented on a diff in the pull request:
https://github.com/apache/spark/pull/21311#discussion_r190146533
--- Diff:
sql/core/src/test/scala/org/apache/spark/sql/execution/joins/HashedRelationSuite.scala
---
@@ -254,6 +254,30 @@ class HashedRelationSuite extends SparkFunSuite with
SharedSQLContext {
map.free()
}
+ test("LongToUnsafeRowMap with big values") {
+val taskMemoryManager = new TaskMemoryManager(
+ new StaticMemoryManager(
+new SparkConf().set(MEMORY_OFFHEAP_ENABLED.key, "false"),
+Long.MaxValue,
+Long.MaxValue,
+1),
+ 0)
+val unsafeProj = UnsafeProjection.create(Array[DataType](StringType))
+val map = new LongToUnsafeRowMap(taskMemoryManager, 1)
+
+val key = 0L
+// the page array is initialized with length 1 << 17 (1M bytes),
+// so here we need a value larger than 1 << 18 (2M bytes),to trigger
the bug
+val bigStr = UTF8String.fromString("x" * (1 << 22))
--- End diff --
LongToUnsafeRowMap#getRow
resultRow=UnsafeRow#pointTo(page(1<<18), baseOffset(16),
sizeInBytes(1<<21+16))
UTF8String#getBytes
copyMemory(base(page), offset, bytes, BYTE_ARRAY_OFFSET,
numBytes(1<<21+16));
In the case of similar size sometimes, can still read the original value.
When introducing SPARK-10399,UnsafeRow#getUTF8String check the size at this
time.
If we pick 1 << 18 + 1, 100% reproduce this bug.
But when this patch is not introduced, differences that are too small
sometimes do not trigger.
So I chose a larger value.
My understanding may be problematic. Please advise. Thank you.
```java
sun.misc.Unsafe unsafe;
try {
Field unsafeField = Unsafe.class.getDeclaredField("theUnsafe");
unsafeField.setAccessible(true);
unsafe = (sun.misc.Unsafe) unsafeField.get(null);
} catch (Throwable cause) {
unsafe = null;
}
String value = "x";
byte[] src = value.getBytes();
byte[] dst = new byte[3];
byte[] newDst = new byte[5];
unsafe.copyMemory(src, 16, dst, 16, src.length);
unsafe.copyMemory(dst, 16, newDst, 16, src.length);
System.out.println("dst:" + new String(dst));
System.out.println("newDst:" + new String(newDst));
```
output:
>dst:xxx
>newDst:x
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21311: [SPARK-24257][SQL]LongToUnsafeRowMap calculate th...
Github user cxzl25 commented on a diff in the pull request:
https://github.com/apache/spark/pull/21311#discussion_r189997697
--- Diff:
sql/core/src/test/scala/org/apache/spark/sql/execution/joins/HashedRelationSuite.scala
---
@@ -254,6 +254,30 @@ class HashedRelationSuite extends SparkFunSuite with
SharedSQLContext {
map.free()
}
+ test("LongToUnsafeRowMap with big values") {
+val taskMemoryManager = new TaskMemoryManager(
+ new StaticMemoryManager(
+new SparkConf().set(MEMORY_OFFHEAP_ENABLED.key, "false"),
+Long.MaxValue,
+Long.MaxValue,
+1),
+ 0)
+val unsafeProj = UnsafeProjection.create(Array[DataType](StringType))
+val map = new LongToUnsafeRowMap(taskMemoryManager, 1)
+
+val key = 0L
+// the page array is initialized with length 1 << 17 (1M bytes),
+// so here we need a value larger than 1 << 18 (2M bytes),to trigger
the bug
+val bigStr = UTF8String.fromString("x" * (1 << 22))
--- End diff --
Not necessary.
Just chose a larger value to make it easier to lose data.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21311: [SPARK-24257][SQL]LongToUnsafeRowMap calculate th...
Github user cxzl25 commented on a diff in the pull request:
https://github.com/apache/spark/pull/21311#discussion_r189905873
--- Diff:
sql/core/src/main/scala/org/apache/spark/sql/execution/joins/HashedRelation.scala
---
@@ -626,6 +618,32 @@ private[execution] final class LongToUnsafeRowMap(val
mm: TaskMemoryManager, cap
}
}
+ private def grow(neededSize: Int): Unit = {
+// There is 8 bytes for the pointer to next value
+val totalNeededSize = cursor + 8 + neededSize
--- End diff --
@cloud-fan Thank you for your suggestion and code.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21311: [SPARK-24257][SQL]LongToUnsafeRowMap calculate the new s...
Github user cxzl25 commented on the issue: https://github.com/apache/spark/pull/21311 @cloud-fan LongToUnsafeRowMap#append(key: Long, row: UnsafeRow) when row.getSizeInBytes > newPageSize( oldPage.length * 8L * 2),still use newPageSize value. When the new page size is insufficient to hold the entire row of data, Platform.copyMemory is still called.No error. At this time, the last remaining data was discarded. When reading data, read this buffer according to offset and length,the last data is unpredictable. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21311: [SPARK-24257][SQL]LongToUnsafeRowMap calculate the new s...
Github user cxzl25 commented on the issue: https://github.com/apache/spark/pull/21311 @JoshRosen @cloud-fan @gatorsmile When introducing [SPARK-10399](https://issues.apache.org/jira/browse/SPARK-10399),UnsafeRow#getUTF8String check the size at this time. [UnsafeRow#getUTF8String](https://github.com/apache/spark/blob/master/sql/catalyst/src/main/java/org/apache/spark/sql/catalyst/expressions/UnsafeRow.java#L420) [OnHeapMemoryBlock](https://github.com/apache/spark/blob/master/common/unsafe/src/main/java/org/apache/spark/unsafe/memory/OnHeapMemoryBlock.java#L34) >The sum of size 2097152 and offset 32 should not be larger than the size of the given memory space 2097168  But when this patch is not introduced, no error, get wrong value.  --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21364: [SPARK-24317][SQL]Float-point numbers are display...
GitHub user cxzl25 reopened a pull request:
https://github.com/apache/spark/pull/21364
[SPARK-24317][SQL]Float-point numbers are displayed with different
precision in ThriftServer2
## What changes were proposed in this pull request?
When querying float-point numbers , the values displayed on beeline or jdbc
are with different precision.
```
SELECT CAST(1.23 AS FLOAT)
Result:
1.230190734863
```
According to these two jira:
[HIVE-11802](https://issues.apache.org/jira/browse/HIVE-11802)
[HIVE-11832](https://issues.apache.org/jira/browse/HIVE-11832)
Make a slight modification to the spark hive thrift server.
## How was this patch tested?
HiveThriftBinaryServerSuite
test("JDBC query float-point number")
You can merge this pull request into a Git repository by running:
$ git pull https://github.com/cxzl25/spark fix_float_number_display
Alternatively you can review and apply these changes as the patch at:
https://github.com/apache/spark/pull/21364.patch
To close this pull request, make a commit to your master/trunk branch
with (at least) the following in the commit message:
This closes #21364
commit 137abed62a75ea453a0d3c8436d9aa08b9abee36
Author: sychen <sychen@...>
Date: 2018-05-18T15:39:35Z
Float-point numbers are displayed with different precision in Beeline/JDBC
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21364: [SPARK-24317][SQL]Float-point numbers are display...
Github user cxzl25 closed the pull request at: https://github.com/apache/spark/pull/21364 --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21364: [SPARK-20173][SQL]Float-point numbers are display...
GitHub user cxzl25 opened a pull request:
https://github.com/apache/spark/pull/21364
[SPARK-20173][SQL]Float-point numbers are displayed with different
precision in ThriftServer2
## What changes were proposed in this pull request?
When querying float-point numbers , the values displayed on beeline or jdbc
are with different precision.
```
SELECT CAST(1.23 AS FLOAT)
Result:
1.230190734863
```
According to these two jira:
[HIVE-11802](https://issues.apache.org/jira/browse/HIVE-11802)
[HIVE-11832](https://issues.apache.org/jira/browse/HIVE-11832)
Make a slight modification to the spark hive thrift server.
## How was this patch tested?
HiveThriftBinaryServerSuite
test("JDBC query float-point number")
You can merge this pull request into a Git repository by running:
$ git pull https://github.com/cxzl25/spark fix_float_number_display
Alternatively you can review and apply these changes as the patch at:
https://github.com/apache/spark/pull/21364.patch
To close this pull request, make a commit to your master/trunk branch
with (at least) the following in the commit message:
This closes #21364
commit 137abed62a75ea453a0d3c8436d9aa08b9abee36
Author: sychen <sychen@...>
Date: 2018-05-18T15:39:35Z
Float-point numbers are displayed with different precision in Beeline/JDBC
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21311: [SPARK-24257][SQL]LongToUnsafeRowMap calculate the new s...
Github user cxzl25 commented on the issue: https://github.com/apache/spark/pull/21311 Thanks for your review. @maropu @kiszk @cloud-fan I submitted a modification including the following: 1. spliting append func into two parts:grow/appendG 2. doubling the size when growing 3. sys.error instead of UnsupportedOperationException --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21311: [SPARK-24257][SQL]LongToUnsafeRowMap calculate th...
Github user cxzl25 commented on a diff in the pull request:
https://github.com/apache/spark/pull/21311#discussion_r187907410
--- Diff:
sql/core/src/main/scala/org/apache/spark/sql/execution/joins/HashedRelation.scala
---
@@ -568,13 +568,16 @@ private[execution] final class LongToUnsafeRowMap(val
mm: TaskMemoryManager, cap
}
// There is 8 bytes for the pointer to next value
-if (cursor + 8 + row.getSizeInBytes > page.length * 8L +
Platform.LONG_ARRAY_OFFSET) {
+val needSize = cursor + 8 + row.getSizeInBytes
+val nowSize = page.length * 8L + Platform.LONG_ARRAY_OFFSET
+if (needSize > nowSize) {
val used = page.length
if (used >= (1 << 30)) {
sys.error("Can not build a HashedRelation that is larger than 8G")
--- End diff --
ok. sys.error instead of UnsupportedOperationException
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21311: [SPARK-24257][SQL]LongToUnsafeRowMap calculate th...
Github user cxzl25 commented on a diff in the pull request:
https://github.com/apache/spark/pull/21311#discussion_r187907559
--- Diff:
sql/core/src/main/scala/org/apache/spark/sql/execution/joins/HashedRelation.scala
---
@@ -568,13 +568,16 @@ private[execution] final class LongToUnsafeRowMap(val
mm: TaskMemoryManager, cap
}
// There is 8 bytes for the pointer to next value
-if (cursor + 8 + row.getSizeInBytes > page.length * 8L +
Platform.LONG_ARRAY_OFFSET) {
+val needSize = cursor + 8 + row.getSizeInBytes
+val nowSize = page.length * 8L + Platform.LONG_ARRAY_OFFSET
+if (needSize > nowSize) {
val used = page.length
if (used >= (1 << 30)) {
sys.error("Can not build a HashedRelation that is larger than 8G")
}
- ensureAcquireMemory(used * 8L * 2)
- val newPage = new Array[Long](used * 2)
+ val multiples = math.max(math.ceil(needSize.toDouble / (used *
8L)).toInt, 2)
+ ensureAcquireMemory(used * 8L * multiples)
--- End diff --
ok.Spliting append func into two parts: grow/append.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21311: [SPARK-24257][SQL]LongToUnsafeRowMap calculate th...
Github user cxzl25 commented on a diff in the pull request:
https://github.com/apache/spark/pull/21311#discussion_r187907473
--- Diff:
sql/core/src/main/scala/org/apache/spark/sql/execution/joins/HashedRelation.scala
---
@@ -568,13 +568,16 @@ private[execution] final class LongToUnsafeRowMap(val
mm: TaskMemoryManager, cap
}
// There is 8 bytes for the pointer to next value
-if (cursor + 8 + row.getSizeInBytes > page.length * 8L +
Platform.LONG_ARRAY_OFFSET) {
+val needSize = cursor + 8 + row.getSizeInBytes
+val nowSize = page.length * 8L + Platform.LONG_ARRAY_OFFSET
+if (needSize > nowSize) {
val used = page.length
if (used >= (1 << 30)) {
sys.error("Can not build a HashedRelation that is larger than 8G")
}
- ensureAcquireMemory(used * 8L * 2)
--- End diff --
ok . Doubling the size when growing.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21311: [SPARK-24257][SQL]LongToUnsafeRowMap calculate th...
GitHub user cxzl25 opened a pull request:
https://github.com/apache/spark/pull/21311
[SPARK-24257][SQL]LongToUnsafeRowMap calculate the new size may be wrong
## What changes were proposed in this pull request?
LongToUnsafeRowMap
Calculate the new size simply by multiplying by 2
At this time, the size of the application may not be enough to store data
Some data is lost and the data read out is dirty
## How was this patch tested?
HashedRelationSuite
test("LongToUnsafeRowMap with big values")
Please review http://spark.apache.org/contributing.html before opening a
pull request.
You can merge this pull request into a Git repository by running:
$ git pull https://github.com/cxzl25/spark fix_LongToUnsafeRowMap_page_size
Alternatively you can review and apply these changes as the patch at:
https://github.com/apache/spark/pull/21311.patch
To close this pull request, make a commit to your master/trunk branch
with (at least) the following in the commit message:
This closes #21311
commit d9d8e62c2de7d9d04534396ab3bbf984ab16c7f5
Author: sychen <sychen@...>
Date: 2018-05-12T11:14:17Z
LongToUnsafeRowMap Calculate the new correct size
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20739: [SPARK-23603][SQL]When the length of the json is in a ra...
Github user cxzl25 commented on the issue: https://github.com/apache/spark/pull/20739 Another solution: #20738 --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20738: [SPARK-23603][SQL]When the length of the json is in a ra...
Github user cxzl25 commented on the issue: https://github.com/apache/spark/pull/20738 Another solution: https://github.com/apache/spark/pull/20739 --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #20739: [SPARK-23603][SQL]When the length of the json is ...
GitHub user cxzl25 opened a pull request:
https://github.com/apache/spark/pull/20739
[SPARK-23603][SQL]When the length of the json is in a range,get_json_object
will result in missing tail data
## What changes were proposed in this pull request?
Replace writeRaw(char[] text, int offset, int len) with writeRaw(String
text)
Jackson(>=2.7.7) fixes the possibility of missing tail data when the length
of the value is in a range
[https://github.com/FasterXML/jackson/wiki/Jackson-Release-2.7.7](https://github.com/FasterXML/jackson/wiki/Jackson-Release-2.7.7)
[https://github.com/FasterXML/jackson-core/issues/30](https://github.com/FasterXML/jackson-core/issues/307)
## How was this patch tested?
org.apache.spark.sql.catalyst.expressions.JsonExpressionsSuite
test("some big value")
You can merge this pull request into a Git repository by running:
$ git pull https://github.com/cxzl25/spark fix_udf_get_json_object
Alternatively you can review and apply these changes as the patch at:
https://github.com/apache/spark/pull/20739.patch
To close this pull request, make a commit to your master/trunk branch
with (at least) the following in the commit message:
This closes #20739
commit 5a83def86eb5a75eae0ff8f43e892e3daa52d50c
Author: sychen <sychen@...>
Date: 2018-03-05T15:30:44Z
Replace writeRaw(char[] text, int offset, int len) with writeRaw(String
text)
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #20738: [SPARK-23603][SQL]When the length of the json is ...
GitHub user cxzl25 opened a pull request:
https://github.com/apache/spark/pull/20738
[SPARK-23603][SQL]When the length of the json is in a range,get_json_object
will result in missing tail data
## What changes were proposed in this pull request?
Bump jackson from 2.6.7&2.6.7.1 to 2.7.7
Jackson(>=2.7.7) fixes the possibility of missing tail data when the length
of the value is in a range
[https://github.com/FasterXML/jackson/wiki/Jackson-Release-2.7.7](https://github.com/FasterXML/jackson/wiki/Jackson-Release-2.7.7)
[https://github.com/FasterXML/jackson-core/issues/30](https://github.com/FasterXML/jackson-core/issues/307)
## How was this patch tested?
org.apache.spark.sql.catalyst.expressions.JsonExpressionsSuite
test("some big value")
You can merge this pull request into a Git repository by running:
$ git pull https://github.com/cxzl25/spark update_jackson_version
Alternatively you can review and apply these changes as the patch at:
https://github.com/apache/spark/pull/20738.patch
To close this pull request, make a commit to your master/trunk branch
with (at least) the following in the commit message:
This closes #20738
commit 0da293c1e8a56fd50d9284ab57eb0f24881f08ef
Author: sychen <sychen@...>
Date: 2018-03-05T15:34:51Z
Bump jackson from 2.6.7&2.6.7.1 to 2.7.7
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #20593: [SPARK-23230][SQL][BRANCH-2.2]When hive.default.f...
Github user cxzl25 closed the pull request at: https://github.com/apache/spark/pull/20593 --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20406: [SPARK-23230][SQL]When hive.default.fileformat is other ...
Github user cxzl25 commented on the issue: https://github.com/apache/spark/pull/20406 Thanks for your help , @dongjoon-hyun @gasparms . I submit a separate PR to 2.2 https://github.com/apache/spark/pull/20593 --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #20593: [SPARK-23230][SQL][BRANCH-2.2]When hive.default.f...
GitHub user cxzl25 opened a pull request: https://github.com/apache/spark/pull/20593 [SPARK-23230][SQL][BRANCH-2.2]When hive.default.fileformat is other kinds of file types, create textfile table cause a serde error When hive.default.fileformat is other kinds of file types, create textfile table cause a serde error. We should take the default type of textfile and sequencefile both as org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe. ``` set hive.default.fileformat=orc; create table tbl( i string ) stored as textfile; desc formatted tbl; Serde Library org.apache.hadoop.hive.ql.io.orc.OrcSerde InputFormat org.apache.hadoop.mapred.TextInputFormat OutputFormat org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat ``` You can merge this pull request into a Git repository by running: $ git pull https://github.com/cxzl25/spark default_serde_2.2 Alternatively you can review and apply these changes as the patch at: https://github.com/apache/spark/pull/20593.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #20593 commit 979323a4e05cfdd5473369f5063967d69c40046c Author: sychen <sychen@...> Date: 2018-02-13T01:37:08Z When hive.default.fileformat is other kinds of file types, create textfile table cause a serde error --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #20406: [SPARK-23230][SQL]When hive.default.fileformat is...
Github user cxzl25 commented on a diff in the pull request:
https://github.com/apache/spark/pull/20406#discussion_r167482913
--- Diff:
sql/hive/src/test/scala/org/apache/spark/sql/hive/execution/HiveSerDeSuite.scala
---
@@ -100,6 +100,25 @@ class HiveSerDeSuite extends HiveComparisonTest with
PlanTest with BeforeAndAfte
assert(output ==
Some("org.apache.hadoop.hive.ql.io.parquet.MapredParquetOutputFormat"))
assert(serde ==
Some("org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe"))
}
+
+withSQLConf("hive.default.fileformat" -> "orc") {
--- End diff --
https://github.com/apache/hive/blob/master/ql/src/java/org/apache/hadoop/hive/ql/parse/StorageFormat.java#L102
hive.default.serde
Default Value: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe
Description: The default SerDe Hive will use for storage formats that do
not specify a SerDe.
https://cwiki.apache.org/confluence/display/Hive/DeveloperGuide#DeveloperGuide-RegistrationofNativeSerDes
hive cli
```
set hive.default.fileformat=orc;
create table tbl( i string ) stored as textfile;
desc formatted tbl;
```
```
SerDe Library:
org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe
InputFormat:org.apache.hadoop.mapred.TextInputFormat
OutputFormat:
org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat
```
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20406: [SPARK-23230][SQL]Error by creating a data table when us...
Github user cxzl25 commented on the issue: https://github.com/apache/spark/pull/20406 ping @gatorsmile @dongjoon-hyun ``` set hive.default.fileformat=orc; create table tbl stored as textfile as select 1 ``` It failed because it used the wrong SERDE ``` Caused by: java.lang.ClassCastException: org.apache.hadoop.hive.ql.io.orc.OrcSerde$OrcSerdeRow cannot be cast to org.apache.hadoop.io.BytesWritable at org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat$1.write(HiveIgnoreKeyTextOutputFormat.java:91) at org.apache.spark.sql.hive.execution.HiveOutputWriter.write(HiveFileFormat.scala:149) at org.apache.spark.sql.execution.datasources.FileFormatWriter$SingleDirectoryWriteTask.execute(FileFormatWriter.scala:327) at org.apache.spark.sql.execution.datasources.FileFormatWriter$$anonfun$org$apache$spark$sql$execution$datasources$FileFormatWriter$$executeTask$3.apply(FileFormatWriter.scala:258) at org.apache.spark.sql.execution.datasources.FileFormatWriter$$anonfun$org$apache$spark$sql$execution$datasources$FileFormatWriter$$executeTask$3.apply(FileFormatWriter.scala:256) at org.apache.spark.util.Utils$.tryWithSafeFinallyAndFailureCallbacks(Utils.scala:1375) at org.apache.spark.sql.execution.datasources.FileFormatWriter$.org$apache$spark$sql$execution$datasources$FileFormatWriter$$executeTask(FileFormatWriter.scala:261) ... 16 more ``` --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #20406: [SPARK-23230][SQL]Error by creating a data table ...
GitHub user cxzl25 opened a pull request: https://github.com/apache/spark/pull/20406 [SPARK-23230][SQL]Error by creating a data table when using hive.default.fileformat=orc When hive.default.fileformat is other kinds of file types, create textfile table cause a serda error. We should take the default type of textfile and sequencefile both as org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe. ``` set hive.default.fileformat=orc; create table tbl( i string ) stored as textfile; desc formatted tbl; Serde Library org.apache.hadoop.hive.ql.io.orc.OrcSerde InputFormat org.apache.hadoop.mapred.TextInputFormat OutputFormat org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat ``` You can merge this pull request into a Git repository by running: $ git pull https://github.com/cxzl25/spark default_serde Alternatively you can review and apply these changes as the patch at: https://github.com/apache/spark/pull/20406.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #20406 commit f370dd6217cf8a590ef52ecc970e4dc33c235631 Author: sychen <sychen@...> Date: 2018-01-26T12:40:48Z take the default type of textfile and sequencefile both as org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org