This is an automated email from the ASF dual-hosted git repository.
srowen pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new 9f91b82b721 [SPARK-37956][DOCS] Add Python and Java examples of
Parquet encryption in Spark SQL to documentation
9f91b82b721 is described below
commit 9f91b82b7210b95b7ac911ff65af735d1996b337
Author: Maya Anderson <ma...@il.ibm.com>
AuthorDate: Sat May 21 19:34:41 2022 -0500
[SPARK-37956][DOCS] Add Python and Java examples of Parquet encryption in
Spark SQL to documentation
### What changes were proposed in this pull request?
Add Java and Python examples based on the Scala example for the use of
Parquet encryption in Spark.
### Why are the changes needed?
To provide information on how to use Parquet column encryption in Spark SQL
in additional languages: in Python and Java, based on the Scala example.
### Does this PR introduce _any_ user-facing change?
Yes, it adds Parquet encryption usage examples in Python and Java to the
documentation, which currently provides only a scala example.
### How was this patch tested?
SKIP_API=1 bundle exec jekyll build
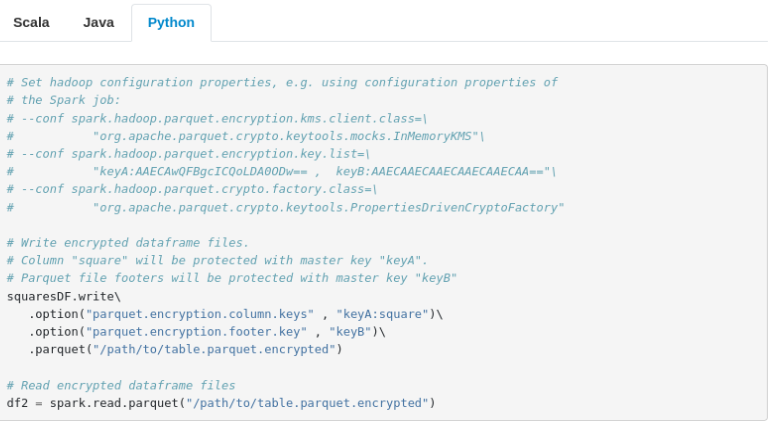
Python tab:
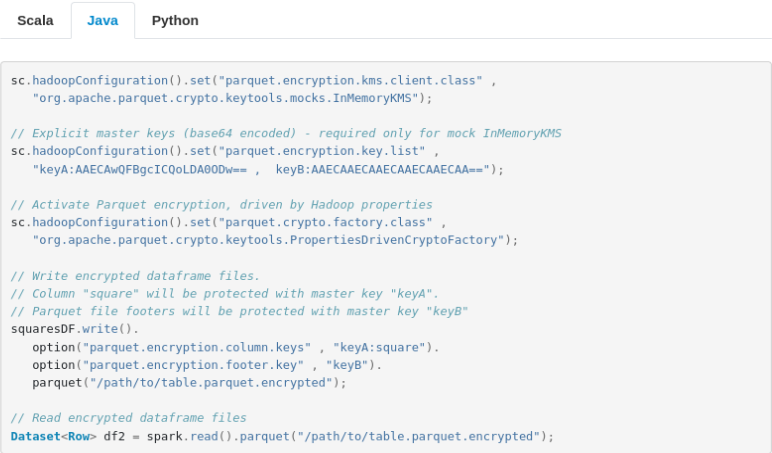
Java tab:
CC ggershinsky
Closes #36523 from andersonm-ibm/pme_docs.
Authored-by: Maya Anderson <ma...@il.ibm.com>
Signed-off-by: Sean Owen <sro...@gmail.com>
---
docs/sql-data-sources-parquet.md | 58 ++++++++++++++++++++++++++++++++++++++++
1 file changed, 58 insertions(+)
diff --git a/docs/sql-data-sources-parquet.md b/docs/sql-data-sources-parquet.md
index 0d97baf1e3a..0c3b5cc6156 100644
--- a/docs/sql-data-sources-parquet.md
+++ b/docs/sql-data-sources-parquet.md
@@ -259,6 +259,8 @@ Since Spark 3.2, columnar encryption is supported for
Parquet tables with Apache
Parquet uses the envelope encryption practice, where file parts are encrypted
with "data encryption keys" (DEKs), and the DEKs are encrypted with "master
encryption keys" (MEKs). The DEKs are randomly generated by Parquet for each
encrypted file/column. The MEKs are generated, stored and managed in a Key
Management Service (KMS) of user’s choice. The Parquet Maven
[repository](https://repo1.maven.org/maven2/org/apache/parquet/parquet-hadoop/1.12.0/)
has a jar with a mock KMS implementati [...]
+<div class="codetabs">
+
<div data-lang="scala" markdown="1">
{% highlight scala %}
@@ -288,6 +290,62 @@ val df2 =
spark.read.parquet("/path/to/table.parquet.encrypted")
</div>
+<div data-lang="java" markdown="1">
+{% highlight java %}
+
+sc.hadoopConfiguration().set("parquet.encryption.kms.client.class" ,
+ "org.apache.parquet.crypto.keytools.mocks.InMemoryKMS");
+
+// Explicit master keys (base64 encoded) - required only for mock InMemoryKMS
+sc.hadoopConfiguration().set("parquet.encryption.key.list" ,
+ "keyA:AAECAwQFBgcICQoLDA0ODw== , keyB:AAECAAECAAECAAECAAECAA==");
+
+// Activate Parquet encryption, driven by Hadoop properties
+sc.hadoopConfiguration().set("parquet.crypto.factory.class" ,
+ "org.apache.parquet.crypto.keytools.PropertiesDrivenCryptoFactory");
+
+// Write encrypted dataframe files.
+// Column "square" will be protected with master key "keyA".
+// Parquet file footers will be protected with master key "keyB"
+squaresDF.write().
+ option("parquet.encryption.column.keys" , "keyA:square").
+ option("parquet.encryption.footer.key" , "keyB").
+ parquet("/path/to/table.parquet.encrypted");
+
+// Read encrypted dataframe files
+Dataset<Row> df2 = spark.read().parquet("/path/to/table.parquet.encrypted");
+
+{% endhighlight %}
+
+</div>
+
+<div data-lang="python" markdown="1">
+{% highlight python %}
+
+# Set hadoop configuration properties, e.g. using configuration properties of
+# the Spark job:
+# --conf spark.hadoop.parquet.encryption.kms.client.class=\
+# "org.apache.parquet.crypto.keytools.mocks.InMemoryKMS"\
+# --conf spark.hadoop.parquet.encryption.key.list=\
+# "keyA:AAECAwQFBgcICQoLDA0ODw== , keyB:AAECAAECAAECAAECAAECAA=="\
+# --conf spark.hadoop.parquet.crypto.factory.class=\
+# "org.apache.parquet.crypto.keytools.PropertiesDrivenCryptoFactory"
+
+# Write encrypted dataframe files.
+# Column "square" will be protected with master key "keyA".
+# Parquet file footers will be protected with master key "keyB"
+squaresDF.write\
+ .option("parquet.encryption.column.keys" , "keyA:square")\
+ .option("parquet.encryption.footer.key" , "keyB")\
+ .parquet("/path/to/table.parquet.encrypted")
+
+# Read encrypted dataframe files
+df2 = spark.read.parquet("/path/to/table.parquet.encrypted")
+
+{% endhighlight %}
+
+</div>
+</div>
#### KMS Client
---------------------------------------------------------------------
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: commits-h...@spark.apache.org
{kind=link}
{kind=link}