On Thu, 05 Sep 2013 04:42:08 +0200
sandm...@cs.au.dk (Søren Sandmann) wrote:
> Siarhei Siamashka <siarhei.siamas...@gmail.com> writes:
>
> > The loops are already unrolled, so it was just a matter of packing
> > 4 pixels into a single XMM register and doing aligned 128-bit
> > writes to memory via MOVDQA instructions for the SRC compositing
> > operator fast path. For the other fast paths, this XMM register
> > is also directly routed to further processing instead of doing
> > extra reshuffling. This replaces "8 PACKSSDW/PACKUSWB + 4 MOVD"
> > instructions with "3 PACKSSDW/PACKUSWB + 1 MOVDQA" per 4 pixels,
> > which results in a clear performance improvement.
> >
> > There are also some other (less important) tweaks:
> >
> > 1. Convert 'pixman_fixed_t' to 'intptr_t' before using it as an
> > index for addressing memory. The problem is that 'pixman_fixed_t'
> > is a 32-bit data type and it has to be extended to 64-bit
> > offsets, which needs extra instructions on 64-bit systems.
> >
> > 2. Dropped support for 8-bit interpolation precision to simplify
> > the code.
>
> If we are dropping support for 8-bit precision, let's drop it everywhere
> (in a separate patch from this optimization). I'll send a patch as a
> follow-up to this mail.
Sure. This makes sense.
> The other question I have is whether you tested if this makes the SSE2
> fast paths competitive with the SSSE3 iterator?
The SSE2 fast paths are not competitive even with the (not yet existing)
SSE2 iterator. As a simple test, it is possible to run:
A) ./lowlevel-blt-bench -b over_8888_8888
And then for comparison:
B) ./lowlevel-blt-bench -b src_8888_8888
C) ./lowlevel-blt-bench over_8888_8888
The fast path is good if the following is true (A, B and C are the
performance numbers, reported by lowlevel-blt-bench in MPix/s):
A > 1 / (1 / B + 1 / C)
This provides an estimate about what performance could be expected
if bilinear fetch and then OVER compositing were done in separate
passes one after another. Such fast paths can be only good for something
as trivial as ADD operator. Or when we are getting much closer to or
exceeding the memory bandwidth limit.
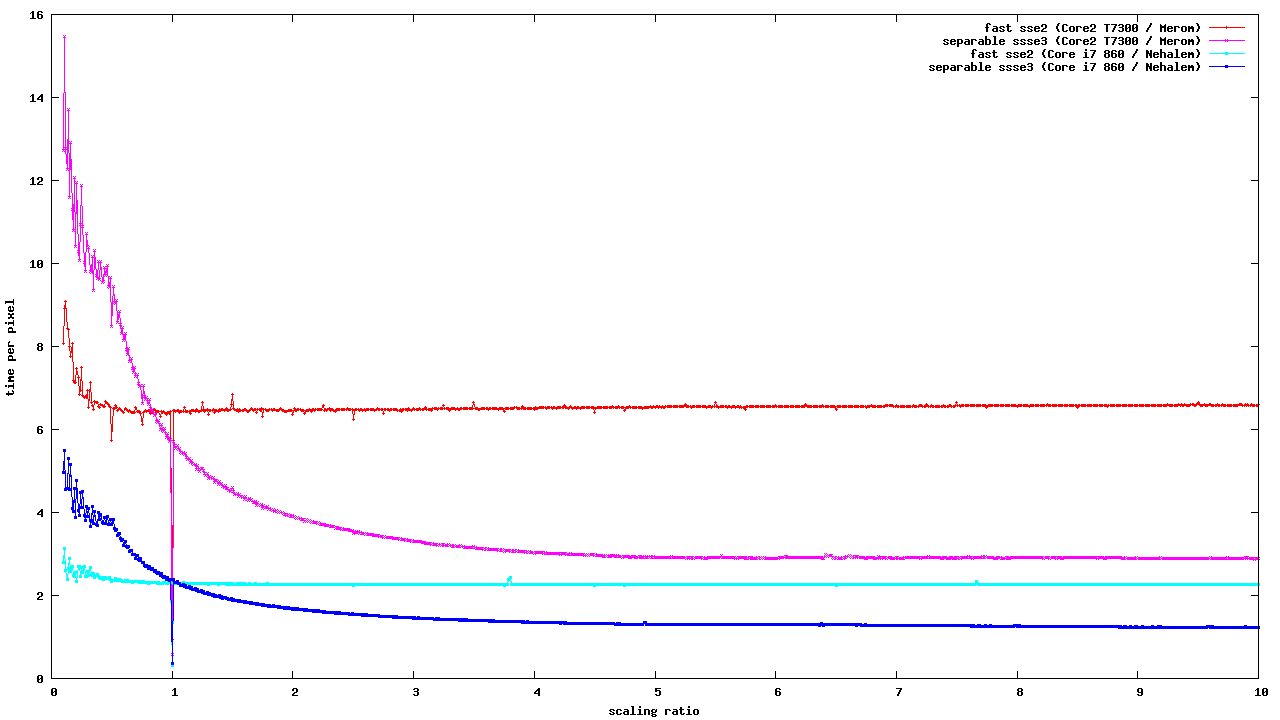
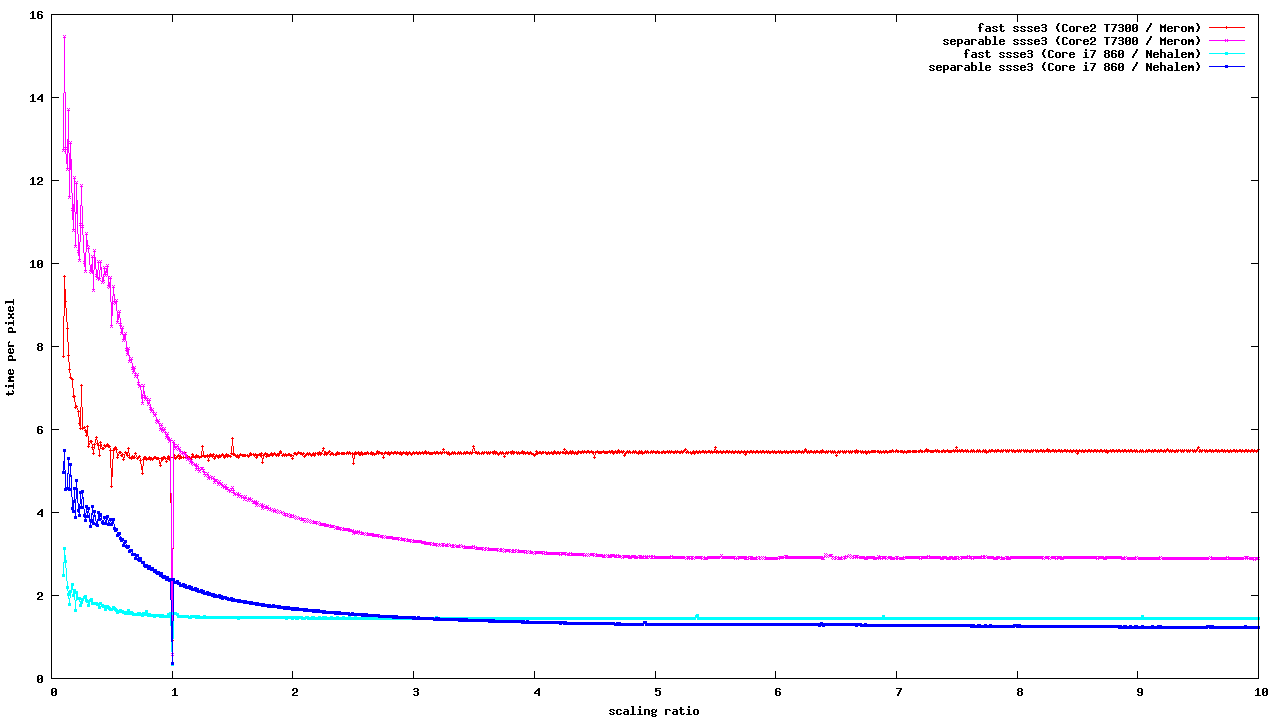
I can see the only good use of this code as an iterator, primarily
intended for downscaling. Here are some benchmarks, comparing the SSE2
and SSSE3 implementations of src_8888_8888 fast paths with the
performance of SSSE3 iterator (using the scaling-bench program, which
has been modified to use SRC instead of OVER, and pixman code patched
to avoid extra memcpy for the SSSE3 iterator):
http://people.freedesktop.org/~siamashka/files/20130905/sse2-scaling-bench.png
http://people.freedesktop.org/~siamashka/files/20130905/ssse3-scaling-bench.png
The raw measurements data and all the sources can be found here:
http://people.freedesktop.org/~siamashka/files/20130905/
But I'll post more details in another thread a bit later.
> If it does, that would allow us to postpone dealing with the
> iterators-vs-fastpaths problem.
The easiest would be to just drop the bilinear fast paths after they
are completely replaced by iterators. The bilinear fast paths were a
place holder solution since the very beginning.
--
Best regards,
Siarhei Siamashka
_______________________________________________
Pixman mailing list
Pixman@lists.freedesktop.org
http://lists.freedesktop.org/mailman/listinfo/pixman
{kind=link}
{kind=link}