Github user sujith71955 commented on the issue:
https://github.com/apache/spark/pull/16677
@viirya i tested with the above mentioned approach with sample data, it has
improved the performance almost into 3X
Please find the test report
Total No of Executers = 3
Total
Github user sujith71955 commented on a diff in the pull request:
https://github.com/apache/spark/pull/16677#discussion_r100033968
--- Diff:
sql/core/src/main/scala/org/apache/spark/sql/execution/limit.scala ---
@@ -90,25 +95,101 @@ trait BaseLimitExec extends UnaryExecNode
Github user sujith71955 commented on a diff in the pull request:
https://github.com/apache/spark/pull/16677#discussion_r99463628
--- Diff:
sql/core/src/test/scala/org/apache/spark/sql/execution/PlannerSuite.scala ---
@@ -216,7 +216,7 @@ class PlannerSuite extends SharedSQLContext
Github user sujith71955 commented on a diff in the pull request:
https://github.com/apache/spark/pull/17649#discussion_r111696709
--- Diff:
sql/core/src/test/resources/sql-tests/inputs/describe_tbleproperty_validation.sql
---
@@ -0,0 +1,24 @@
+CREATE TABLE table_with_comment
Github user sujith71955 commented on a diff in the pull request:
https://github.com/apache/spark/pull/17649#discussion_r111696418
--- Diff:
sql/core/src/main/scala/org/apache/spark/sql/execution/command/ddl.scala ---
@@ -232,7 +232,9 @@ case class AlterTableSetPropertiesCommand
Github user sujith71955 commented on the issue:
https://github.com/apache/spark/pull/17649
@gatorsmile @wzhfy updated the PR based on the review comments, please let
me know for any suggestions.
---
If your project is set up for it, you can reply to this email and have your
reply
GitHub user sujith71955 opened a pull request:
https://github.com/apache/spark/pull/17649
[SPARK-20023][SQL][follow up] Output table comment for DESC FORMATTED after
adding/modifying table comment using Alter TableSetPropertiesCommand
### What changes were proposed in this pull
Github user sujith71955 commented on the issue:
https://github.com/apache/spark/pull/17649
cc @wzhfy
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so
Github user sujith71955 commented on a diff in the pull request:
https://github.com/apache/spark/pull/17649#discussion_r112840921
--- Diff:
sql/core/src/test/resources/sql-tests/inputs/describe-table-after-alter-table.sql
---
@@ -0,0 +1,29 @@
+CREATE TABLE table_with_comment
Github user sujith71955 commented on a diff in the pull request:
https://github.com/apache/spark/pull/17649#discussion_r112838259
--- Diff:
sql/core/src/test/resources/sql-tests/results/describe-table-after-alter-table.sql.out
---
@@ -0,0 +1,162 @@
+-- Automatically generated
Github user sujith71955 commented on the issue:
https://github.com/apache/spark/pull/17649
@gatorsmile @wzhfy updated the PR by removing the 'comment' from table
properties .
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub
Github user sujith71955 commented on a diff in the pull request:
https://github.com/apache/spark/pull/17649#discussion_r113427428
--- Diff:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/catalog/InMemoryCatalog.scala
---
@@ -295,7 +295,9 @@ class InMemoryCatalog
Github user sujith71955 commented on a diff in the pull request:
https://github.com/apache/spark/pull/17649#discussion_r113599057
--- Diff:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/catalog/InMemoryCatalog.scala
---
@@ -295,7 +295,9 @@ class InMemoryCatalog
Github user sujith71955 commented on the issue:
https://github.com/apache/spark/pull/17649
@wzhfy @gatorsmile fixed all the comments, thanks for reviewing the
changes and providing me valuable sharings and comments. thanks.
---
If your project is set up for it, you can reply
Github user sujith71955 commented on the issue:
https://github.com/apache/spark/pull/17649
@gatorsmile you are right, pr should address the issue which is handled in
alter table set/unset properties ddls, updated the description and title, let
me know for any clarifications. thanks
Github user sujith71955 commented on the issue:
https://github.com/apache/spark/pull/19823
retest this please
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail
Github user sujith71955 commented on the issue:
https://github.com/apache/spark/pull/19823
Basically this validation stands good for both cases where scheme can come
as null and not null, i will update the logic as Sean told. Thanks
Github user sujith71955 commented on the issue:
https://github.com/apache/spark/pull/19823
Thanks for the comments guys, i am working on it.,will update the PR based
on comments.
---
-
To unsubscribe, e-mail
Github user sujith71955 commented on the issue:
https://github.com/apache/spark/pull/19823
@gatorsmile @HyukjinKwon @srowen Please review as i modified the code as
per provided comments. thanks
---
-
To unsubscribe
Github user sujith71955 commented on the issue:
https://github.com/apache/spark/pull/19823
 , if you wont mention any
scheme , this api will return
---
-
To unsubscribe
Github user sujith71955 commented on the issue:
https://github.com/apache/spark/pull/20611
@kevinyu98 Even below kind of queries cannot run as exist() api while
validation cannot identify wild chars, this is the reason in my PR i am using
globStatus() API
load data inpath 'hdfs
Github user sujith71955 commented on the issue:
https://github.com/apache/spark/pull/20611
@kevinyu98 Thanks for you feedback, i will test once all my scenario with
your fix, but here one more point i need to mention is like my fix has also has
impact in the logic of local path
Github user sujith71955 commented on the issue:
https://github.com/apache/spark/pull/20611
As @kevinyu98 mentioned below usecase where '?' is been used in the load
command will fail as when we create a Path instance with uri , the chars
followed by ? will be removed as part
Github user sujith71955 commented on the issue:
https://github.com/apache/spark/pull/20611
@kevinyu98 Now my PR addresses the scenario what you mentioned.
---
-
To unsubscribe, e-mail: reviews-unsubscr
Github user sujith71955 commented on the issue:
https://github.com/apache/spark/pull/20611
This PR is open from many days, we need this fix in our version code also,
can someone please review and provide me suggestions if any
Github user sujith71955 commented on a diff in the pull request:
https://github.com/apache/spark/pull/20611#discussion_r196670750
--- Diff:
sql/core/src/main/scala/org/apache/spark/sql/execution/command/tables.scala ---
@@ -303,94 +303,50 @@ case class LoadDataCommand
Github user sujith71955 commented on the issue:
https://github.com/apache/spark/pull/20611
@HyukjinKwon Thanks for the re look.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional
GitHub user sujith71955 opened a pull request:
https://github.com/apache/spark/pull/20611
[SPARK-23425][SQL]When wild card is been used in load command system is
throwing analysis exception
## What changes were proposed in this pull request?
A validaton logic is been added
Github user sujith71955 commented on the issue:
https://github.com/apache/spark/pull/20611
Please review and let me know for any suggestions. Thanks
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
Github user sujith71955 commented on the issue:
https://github.com/apache/spark/pull/20611
retest please
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h
Github user sujith71955 commented on the issue:
https://github.com/apache/spark/pull/20611
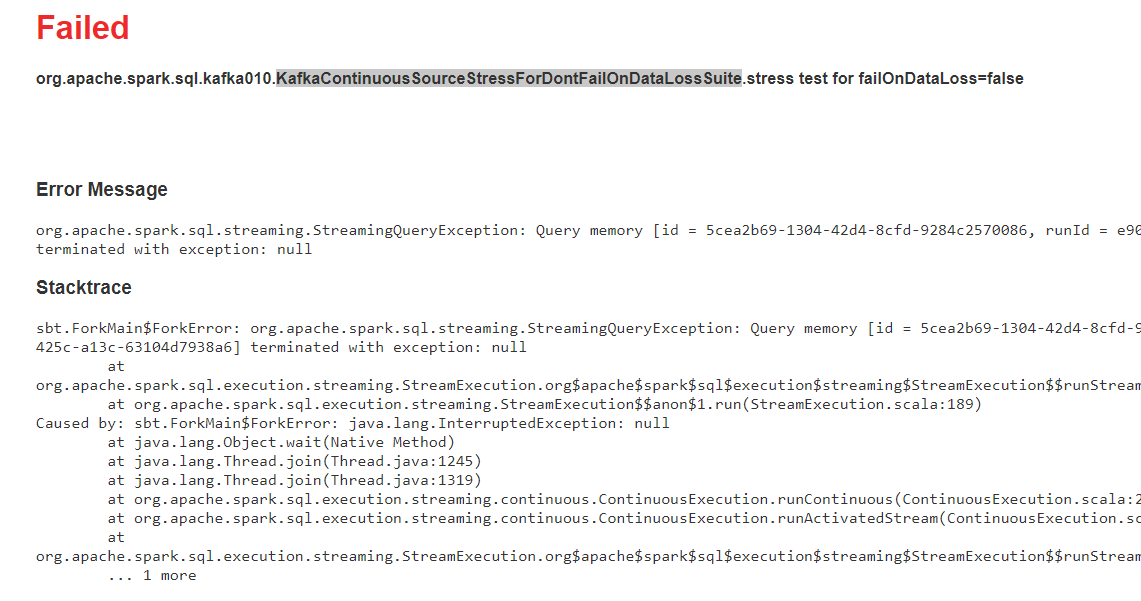
seems to be an invalid failure
Github user sujith71955 commented on the issue:
https://github.com/apache/spark/pull/20611
@gatorsmile Seems to be a random failures, each time random set of test
cases are failing. Please let me know for any suggestions
Github user sujith71955 commented on the issue:
https://github.com/apache/spark/pull/20611
@gatorsmile @jiangxb1987 @wzhfy @HyukjinKwon @vinodkc please review and
let me know for any suggestions. i think all the gaps which we discussed as
part of the PR is been addressed
Github user sujith71955 commented on the issue:
https://github.com/apache/spark/pull/20611
No other changes in the load command behavior
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
Github user sujith71955 commented on the issue:
https://github.com/apache/spark/pull/20611
i think support wildcard is confusing term :)
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
Github user sujith71955 commented on the issue:
https://github.com/apache/spark/pull/20611
I will reiterate again, actually this PR was intended for fixing the issue
related to wildcard character issue in the hdfs file system scenarios , with
the current solution we are also able
Github user sujith71955 commented on a diff in the pull request:
https://github.com/apache/spark/pull/20611#discussion_r207320333
--- Diff:
sql/core/src/main/scala/org/apache/spark/sql/execution/command/tables.scala ---
@@ -303,94 +303,44 @@ case class LoadDataCommand
Github user sujith71955 commented on a diff in the pull request:
https://github.com/apache/spark/pull/20611#discussion_r206411960
--- Diff:
sql/core/src/main/scala/org/apache/spark/sql/execution/command/tables.scala ---
@@ -303,94 +303,44 @@ case class LoadDataCommand
Github user sujith71955 commented on a diff in the pull request:
https://github.com/apache/spark/pull/20611#discussion_r206961528
--- Diff:
sql/core/src/main/scala/org/apache/spark/sql/execution/command/tables.scala ---
@@ -303,94 +303,44 @@ case class LoadDataCommand
Github user sujith71955 commented on the issue:
https://github.com/apache/spark/pull/20611
@gatorsmile Yes there is a change in the behavior, As i mentioned above in
descriptions now we will be able to support wildcard even in the folder level
for local file systems. Previous
Github user sujith71955 commented on the issue:
https://github.com/apache/spark/pull/20611
ok, i missed it, let me have a look. Thanks
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
Github user sujith71955 commented on a diff in the pull request:
https://github.com/apache/spark/pull/20611#discussion_r206037303
--- Diff:
sql/core/src/main/scala/org/apache/spark/sql/execution/command/tables.scala ---
@@ -303,94 +303,44 @@ case class LoadDataCommand
Github user sujith71955 commented on the issue:
https://github.com/apache/spark/pull/20611
@gatorsmile i added the comment. Thanks
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional
Github user sujith71955 commented on a diff in the pull request:
https://github.com/apache/spark/pull/22120#discussion_r210599272
--- Diff:
resource-managers/yarn/src/main/scala/org/apache/spark/scheduler/cluster/YarnClientSchedulerBackend.scala
---
@@ -62,6 +62,10 @@ private
Github user sujith71955 commented on the issue:
https://github.com/apache/spark/pull/20611
Working fine with latest code. Thanks !!!
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional
Github user sujith71955 commented on the issue:
https://github.com/apache/spark/pull/20611
Did some testing in my cluster with updated code for verifying the load
command with hdfs paths, please find the test results. Local path testing is
already covered in my UT
Github user sujith71955 commented on the issue:
https://github.com/apache/spark/pull/20611
Updated the PR by fixing the comment from sean. Hope i addressed all the
issues :)
---
-
To unsubscribe, e-mail: reviews
Github user sujith71955 commented on the issue:
https://github.com/apache/spark/pull/20611
Hi All, can we have a re-look into this PR and let me know whether is it
looking fine. Thanks
---
-
To unsubscribe, e-mail
Github user sujith71955 commented on the issue:
https://github.com/apache/spark/pull/20611
@srowen
Make this method private -- can be right?
This is more like a Util method where any feature deals with file system
can use this method to form a path instance without
Github user sujith71955 commented on the issue:
https://github.com/apache/spark/pull/20611
@srowen got your point, i will update
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional
Github user sujith71955 commented on the issue:
https://github.com/apache/spark/pull/20611
@srowen Fixed the pending comments. Kindly recheck. Thanks
---
-
To unsubscribe, e-mail: reviews-unsubscr
Github user sujith71955 commented on a diff in the pull request:
https://github.com/apache/spark/pull/22199#discussion_r212356336
--- Diff:
resource-managers/yarn/src/main/scala/org/apache/spark/deploy/yarn/Client.scala
---
@@ -338,13 +338,14 @@ private[spark] class Client
Github user sujith71955 commented on a diff in the pull request:
https://github.com/apache/spark/pull/22199#discussion_r212354862
--- Diff:
resource-managers/yarn/src/main/scala/org/apache/spark/deploy/yarn/Client.scala
---
@@ -338,13 +338,14 @@ private[spark] class Client
Github user sujith71955 commented on a diff in the pull request:
https://github.com/apache/spark/pull/22199#discussion_r212356651
--- Diff:
resource-managers/yarn/src/main/scala/org/apache/spark/deploy/yarn/Client.scala
---
@@ -338,13 +338,14 @@ private[spark] class Client
Github user sujith71955 commented on a diff in the pull request:
https://github.com/apache/spark/pull/22199#discussion_r212392740
--- Diff:
resource-managers/yarn/src/main/scala/org/apache/spark/deploy/yarn/Client.scala
---
@@ -338,13 +338,14 @@ private[spark] class Client
Github user sujith71955 commented on a diff in the pull request:
https://github.com/apache/spark/pull/22199#discussion_r212370528
--- Diff:
resource-managers/yarn/src/main/scala/org/apache/spark/deploy/yarn/Client.scala
---
@@ -338,13 +338,14 @@ private[spark] class Client
Github user sujith71955 commented on a diff in the pull request:
https://github.com/apache/spark/pull/22199#discussion_r212396099
--- Diff:
resource-managers/yarn/src/main/scala/org/apache/spark/deploy/yarn/Client.scala
---
@@ -338,13 +338,14 @@ private[spark] class Client
GitHub user sujith71955 opened a pull request:
https://github.com/apache/spark/pull/22199
[SPARK-25073][SQL]When wild card is been used in load command system
## What changes were proposed in this pull request?
When the yarn.nodemanager.resource.memory-mb
Github user sujith71955 commented on the issue:
https://github.com/apache/spark/pull/21775
sure, i will update the PR based on the comments, Thanks for suggestions.
---
-
To unsubscribe, e-mail: reviews-unsubscr
GitHub user sujith71955 opened a pull request:
https://github.com/apache/spark/pull/21775
[SPARK-24812][SQL] Last Access Time in the table description is not valid
## What changes were proposed in this pull request?
Last Access Time will always displayed wrong date Wed Dec 31 15
Github user sujith71955 commented on the issue:
https://github.com/apache/spark/pull/21775
@HyukjinKwon @gatorsmile All issues has been addressed, please let me know
how this patch looks like. Thanks
Github user sujith71955 commented on the issue:
https://github.com/apache/spark/pull/21775
@HyukjinKwon
seems to be a limitation as of now even from hive, better we can follow the
hive behavior unless the limitation has been resolved from hive.
>> Hive-2526 is th
Github user sujith71955 commented on a diff in the pull request:
https://github.com/apache/spark/pull/21775#discussion_r204287713
--- Diff: docs/sql-programming-guide.md ---
@@ -1843,6 +1843,7 @@ working with timestamps in `pandas_udf`s to get the
best performance, see
Github user sujith71955 commented on a diff in the pull request:
https://github.com/apache/spark/pull/21775#discussion_r204286227
--- Diff: docs/sql-programming-guide.md ---
@@ -1843,6 +1843,7 @@ working with timestamps in `pandas_udf`s to get the
best performance, see
Github user sujith71955 commented on a diff in the pull request:
https://github.com/apache/spark/pull/16677#discussion_r204361301
--- Diff:
sql/core/src/test/scala/org/apache/spark/sql/execution/TakeOrderedAndProjectSuite.scala
---
@@ -22,6 +22,7 @@ import scala.util.Random
Github user sujith71955 commented on a diff in the pull request:
https://github.com/apache/spark/pull/16677#discussion_r204362254
--- Diff:
sql/core/src/main/scala/org/apache/spark/sql/execution/exchange/ShuffleExchangeExec.scala
---
@@ -231,6 +231,12 @@ object
Github user sujith71955 commented on the issue:
https://github.com/apache/spark/pull/20611
@srowen
The only possible objection I can see is that the behavior for paths that
contains a ? or * would now change :- There is no behavior change currently,
currently user cannot
Github user sujith71955 commented on a diff in the pull request:
https://github.com/apache/spark/pull/20611#discussion_r216417629
--- Diff:
sql/core/src/main/scala/org/apache/spark/sql/execution/command/tables.scala ---
@@ -303,94 +303,44 @@ case class LoadDataCommand
Github user sujith71955 commented on a diff in the pull request:
https://github.com/apache/spark/pull/20611#discussion_r216425911
--- Diff:
sql/core/src/main/scala/org/apache/spark/sql/execution/command/tables.scala ---
@@ -303,94 +303,44 @@ case class LoadDataCommand
Github user sujith71955 commented on a diff in the pull request:
https://github.com/apache/spark/pull/20611#discussion_r216638725
--- Diff:
sql/core/src/main/scala/org/apache/spark/sql/execution/command/tables.scala ---
@@ -303,94 +303,44 @@ case class LoadDataCommand
Github user sujith71955 commented on a diff in the pull request:
https://github.com/apache/spark/pull/20611#discussion_r216638992
--- Diff:
sql/core/src/main/scala/org/apache/spark/sql/execution/command/tables.scala ---
@@ -303,94 +303,44 @@ case class LoadDataCommand
Github user sujith71955 commented on the issue:
https://github.com/apache/spark/pull/20611
@srowen Thanks for the review. all comments has been addressed from my
side. let me know for any clarifications
Github user sujith71955 commented on a diff in the pull request:
https://github.com/apache/spark/pull/20611#discussion_r202255185
--- Diff:
sql/hive/src/test/scala/org/apache/spark/sql/hive/execution/SQLQuerySuite.scala
---
@@ -1912,11 +1912,58 @@ class SQLQuerySuite extends
Github user sujith71955 commented on a diff in the pull request:
https://github.com/apache/spark/pull/20611#discussion_r202255230
--- Diff:
sql/core/src/main/scala/org/apache/spark/sql/execution/command/tables.scala ---
@@ -303,94 +303,49 @@ case class LoadDataCommand
Github user sujith71955 commented on a diff in the pull request:
https://github.com/apache/spark/pull/20611#discussion_r202255324
--- Diff:
sql/core/src/main/scala/org/apache/spark/sql/execution/command/tables.scala ---
@@ -303,94 +303,49 @@ case class LoadDataCommand
Github user sujith71955 commented on a diff in the pull request:
https://github.com/apache/spark/pull/20611#discussion_r202255494
--- Diff:
sql/core/src/main/scala/org/apache/spark/sql/execution/command/tables.scala ---
@@ -303,94 +303,49 @@ case class LoadDataCommand
Github user sujith71955 commented on a diff in the pull request:
https://github.com/apache/spark/pull/20611#discussion_r202429058
--- Diff:
sql/core/src/main/scala/org/apache/spark/sql/execution/command/tables.scala ---
@@ -303,94 +303,44 @@ case class LoadDataCommand
Github user sujith71955 commented on a diff in the pull request:
https://github.com/apache/spark/pull/20611#discussion_r216685077
--- Diff:
sql/core/src/main/scala/org/apache/spark/sql/execution/command/tables.scala ---
@@ -303,94 +303,44 @@ case class LoadDataCommand
Github user sujith71955 commented on a diff in the pull request:
https://github.com/apache/spark/pull/20611#discussion_r216693375
--- Diff:
sql/core/src/main/scala/org/apache/spark/sql/execution/command/tables.scala ---
@@ -303,94 +303,44 @@ case class LoadDataCommand
Github user sujith71955 commented on a diff in the pull request:
https://github.com/apache/spark/pull/20611#discussion_r216692677
--- Diff:
sql/core/src/main/scala/org/apache/spark/sql/execution/command/tables.scala ---
@@ -303,94 +303,44 @@ case class LoadDataCommand
Github user sujith71955 commented on a diff in the pull request:
https://github.com/apache/spark/pull/20611#discussion_r216694466
--- Diff:
sql/core/src/main/scala/org/apache/spark/sql/execution/command/tables.scala ---
@@ -303,94 +303,44 @@ case class LoadDataCommand
Github user sujith71955 commented on a diff in the pull request:
https://github.com/apache/spark/pull/20611#discussion_r216693154
--- Diff:
sql/core/src/main/scala/org/apache/spark/sql/execution/command/tables.scala ---
@@ -303,94 +303,44 @@ case class LoadDataCommand
Github user sujith71955 commented on the issue:
https://github.com/apache/spark/pull/20611
As above changes are applicable only for hdfs related paths, i did testing
manually, please find the attached test report
Usecase 1: Load data by specifying wild card character in the hdfs
Github user sujith71955 commented on the issue:
https://github.com/apache/spark/pull/20611
@wzhfy
Hive supports specifying wildcard in both file and folder level, please
find test report attached below
Use-case related to Hive File level wild card support
![hive_file
Github user sujith71955 commented on a diff in the pull request:
https://github.com/apache/spark/pull/20611#discussion_r174868215
--- Diff:
sql/core/src/main/scala/org/apache/spark/sql/execution/command/tables.scala ---
@@ -385,8 +385,12 @@ case class LoadDataCommand
Github user sujith71955 commented on the issue:
https://github.com/apache/spark/pull/20611
@wzhfy @gatorsmile @jiangxb1987 updated the test results and PR title based
on zhenhuas comment, please review and let me know if still any improvement
area is present for this particular PR
Github user sujith71955 commented on a diff in the pull request:
https://github.com/apache/spark/pull/20611#discussion_r174791662
--- Diff:
sql/core/src/main/scala/org/apache/spark/sql/execution/command/tables.scala ---
@@ -385,8 +385,12 @@ case class LoadDataCommand
Github user sujith71955 commented on the issue:
https://github.com/apache/spark/pull/20611
Yeah there is a bit confusing, i updated the snapshot, data validation and
consistency i verified
---
-
To unsubscribe, e
Github user sujith71955 commented on the issue:
https://github.com/apache/spark/pull/20611
@wzhfy sure will do it. Thanks for suggestions
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
Github user sujith71955 commented on the issue:
https://github.com/apache/spark/pull/20611
@wzhfy i am working on it, when i ran locally few test-cases were failing,
correcting the same. once done i will update. Thanks
Github user sujith71955 commented on a diff in the pull request:
https://github.com/apache/spark/pull/20611#discussion_r181543985
--- Diff:
sql/core/src/main/scala/org/apache/spark/sql/execution/command/tables.scala ---
@@ -304,45 +304,14 @@ case class LoadDataCommand
1 - 100 of 183 matches
Mail list logo