kaxil edited a comment on issue #5743: [AIRFLOW-5088][AIP-24] Persisting serialized DAG in DB for webserver scalability URL: https://github.com/apache/airflow/pull/5743#issuecomment-528654768 Some more benchmarking:  As you can fetching DAGs from DB is still taking more time than parsing DAGs from files. The flame graphs below show that a good amount of time is spent in loading the json (`json.loads`) into a Python dictionary. 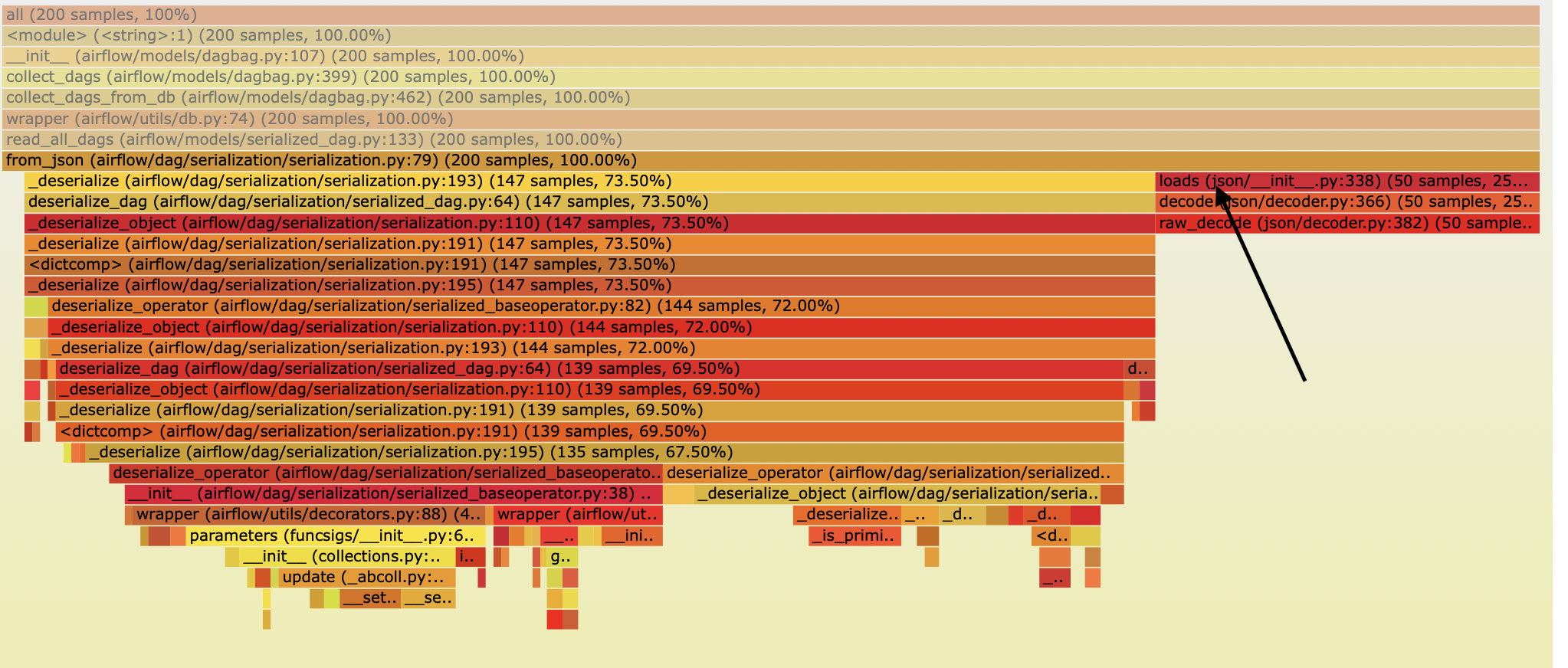  So we have 2 solutions: (1) Replace `json` package with a faster json-parsing package. Many online benchmark showed that the `json` package is relatively slow. Based on that I carried out benchmarks of few popular json packages for our use-case: ``` import json import yajl import ujson In [21]: %timeit -n100 json.loads(testLoad74_w_json) 100 loops, best of 3: 25.5 ms per loop In [20]: %timeit -n100 yajl.loads(testLoad74_w_json) 100 loops, best of 3: 11.2 ms per loop In [22]: %timeit -n100 ujson.loads(testLoad74_w_json) 100 loops, best of 3: 9.67 ms per loop ``` Based on the above results I will change `json.loads` to `ujson.loads` and bechmark again. Will post the results tomorrow. (2) Reduce the number of fields that we store in DB even further. The current size of 1 of our test Serialized DAG is ~1.95 mb 
{kind=link}
{kind=link}
{kind=link}
{kind=link}
---------------------------------------------------------------- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services