renatocron opened a new issue, #12986:
URL: https://github.com/apache/druid/issues/12986
Hi! I'm having druid returning wrong / unexpected results,
I have a rollup set up with daily segments, ingesting from kafka, and two
metrics (count and longmax),
The query objective is to get the most recent value (even if some dimensions
changed values during the day) using order-by "max(last_seen) desc" in order to
get the most recent version of the rollup in the querySegment.
The query is bellow (the original query has more columns, but I keep
reducing the query to make it easier):
```sql
SELECT
mm,
apikey,
version,
MAX( last_seen ) as last_seen
FROM datasource
WHERE
__time >= CURRENT_TIMESTAMP - INTERVAL '18' DAY
AND "mm" = '1234'
and apikey IN ('foo', 'bar')
GROUP BY
mm, version, apikey
```
The data source has data about ~30 million rows,
but the column `mm` was filtered and returned just 4 rows (2 for each
apikey, for each day, after the rollup daily)
before rollup, on one of the days, there were 75 rows collapsed into one.
Here I set a few example data with the same schema, but no error can be
reproduced with just this ingestion spec
https://gist.github.com/renatocron/11a43d7ad4ee1fc3d43c4cda9a17fee2
The column `last_seen` is generated from the `LongMax` value for `_time`,
both segmentGranularity and queryGranularity are set to DAY, so, it should
always return some timestamp between midnight and the next day, but I was
getting some values 30 years in the future. That was how I discovered that
something was wrong with the results of some executions.
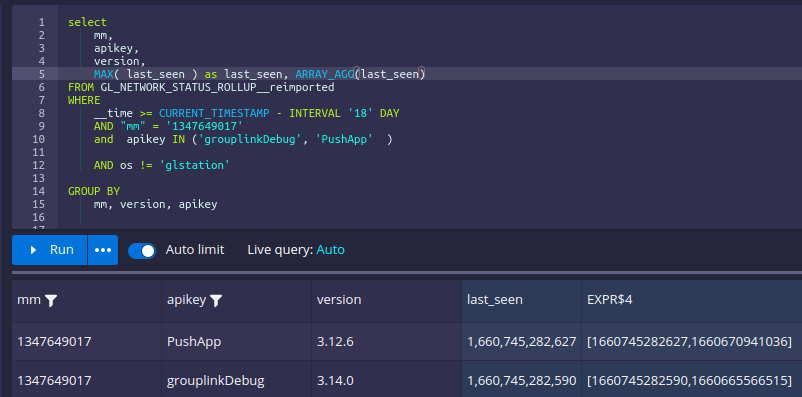
The crazy thing is, to get the correct result, I can either change the
SELECT to add any column using LATEST or add `array_agg(distinct last_seen)`,
then the Max(last_seen) column returns the correct data (100% of the time?
IDK,but what I would expect from a database, even without the array_agg to
begin with :P [I'm not dropping shade towards druid, but that's the truth])
If you want to see it happening in 'real time', here's a video where I ran
some queries https://youtu.be/X1zHJ05GoJ8
Further Information/data can be found on this slack thread:
https://apachedruidworkspace.slack.com/archives/C0309C9L90D/p1661203934675279
since I reported this on Slack (2022-08-23), I keep testing to get more
information:
during the initial re-ingestion from Kafka, the new data source showed wrong
results initially (see
https://apachedruidworkspace.slack.com/archives/C0309C9L90D/p1661248129192669?thread_ts=1661203934.675279&cid=C0309C9L90D)
but after the first task was completed, the results were correct for the next
~24 hours. Then, enabled compression, the same I set on the production data
source (see
https://gist.github.com/renatocron/11a43d7ad4ee1fc3d43c4cda9a17fee2?permalink_comment_id=4281304#gistcomment-4281304
for the setting), and waited until today (2022-08-26) and now all the results
are wrong again:
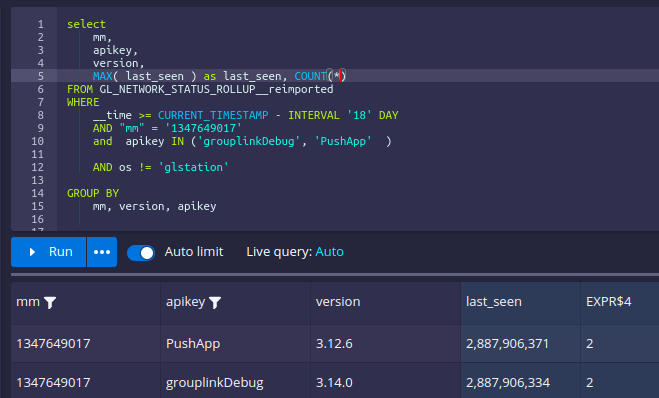
if I add the `array_agg`
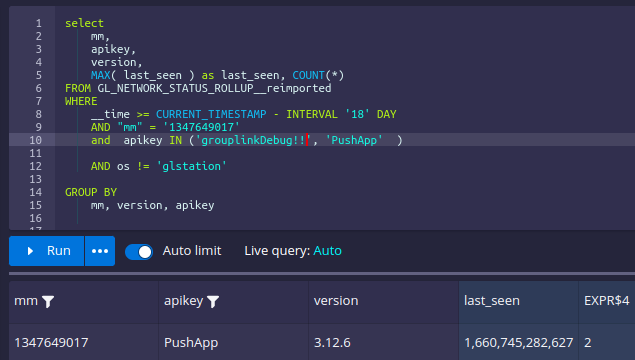
or change the filter to only match one of the apikeys:
The reingested currenly has 14M rows and is 90.48% segments compacted, so
the auto compaction is already 'done', so now I think that could be something
related to the compaction process.
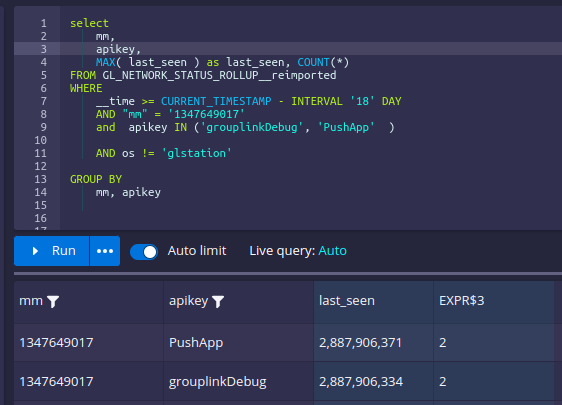
Running the query with group-by but not selecting the 'apikey' column
returns the right result (and two rows, one for each apikey):

but adding the apikey in the select, returns bad results again:
##
Druid version is 0.23 from the official docker image.
Thanks for reading until here!
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: [email protected]
For queries about this service, please contact Infrastructure at:
[email protected]
---------------------------------------------------------------------
To unsubscribe, e-mail: [email protected]
For additional commands, e-mail: [email protected]
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}