Repository: kylin Updated Branches: refs/heads/document 254cc9e4d -> 4c1c736eb
Misc updates on v2.0 documentation Project: http://git-wip-us.apache.org/repos/asf/kylin/repo Commit: http://git-wip-us.apache.org/repos/asf/kylin/commit/4c1c736e Tree: http://git-wip-us.apache.org/repos/asf/kylin/tree/4c1c736e Diff: http://git-wip-us.apache.org/repos/asf/kylin/diff/4c1c736e Branch: refs/heads/document Commit: 4c1c736ebb435502a094202491e1c2785e9316e9 Parents: 254cc9e Author: shaofengshi <shaofeng...@apache.org> Authored: Tue Jun 27 17:33:15 2017 +0800 Committer: shaofengshi <shaofeng...@apache.org> Committed: Tue Jun 27 17:33:15 2017 +0800 ---------------------------------------------------------------------- .../_docs20/howto/howto_update_coprocessor.md | 2 +- website/_docs20/install/hadoop_evn.md | 6 +---- .../_docs20/install/manual_install_guide.cn.md | 27 +++----------------- website/_docs20/tutorial/cube_spark.md | 5 ++-- 4 files changed, 9 insertions(+), 31 deletions(-) ---------------------------------------------------------------------- http://git-wip-us.apache.org/repos/asf/kylin/blob/4c1c736e/website/_docs20/howto/howto_update_coprocessor.md ---------------------------------------------------------------------- diff --git a/website/_docs20/howto/howto_update_coprocessor.md b/website/_docs20/howto/howto_update_coprocessor.md index 8f83d70..9df6ca5 100644 --- a/website/_docs20/howto/howto_update_coprocessor.md +++ b/website/_docs20/howto/howto_update_coprocessor.md @@ -10,5 +10,5 @@ Kylin leverages HBase coprocessor to optimize query performance. After new versi There's a CLI tool to update HBase Coprocessor: {% highlight Groff markup %} -$KYLIN_HOME/bin/kylin.sh org.apache.kylin.storage.hbase.util.DeployCoprocessorCLI $KYLIN_HOME/lib/kylin-coprocessor-*.jar all +$KYLIN_HOME/bin/kylin.sh org.apache.kylin.storage.hbase.util.DeployCoprocessorCLI default all {% endhighlight %} http://git-wip-us.apache.org/repos/asf/kylin/blob/4c1c736e/website/_docs20/install/hadoop_evn.md ---------------------------------------------------------------------- diff --git a/website/_docs20/install/hadoop_evn.md b/website/_docs20/install/hadoop_evn.md index 51f82f2..a0be883 100644 --- a/website/_docs20/install/hadoop_evn.md +++ b/website/_docs20/install/hadoop_evn.md @@ -5,7 +5,7 @@ categories: install permalink: /docs20/install/hadoop_env.html --- -Kylin need run in a Hadoop node, to get better stability, we suggest you to deploy it a pure Hadoop client machine, on which it the command lines like `hive`, `hbase`, `hadoop`, `hdfs` already be installed and configured. The Linux account that running Kylin has got permission to the Hadoop cluster, including create/write hdfs, hive tables, hbase tables and submit MR jobs. +Kylin need run in a Hadoop node, to get better stability, we suggest you to deploy it a pure Hadoop client machine, on which the command lines like `hive`, `hbase`, `hadoop`, `hdfs` already be installed and configured. The Linux account that running Kylin has got permission to the Hadoop cluster, including create/write hdfs, hive tables, hbase tables and submit MR jobs. ## Recommended Hadoop Versions @@ -32,9 +32,5 @@ ambari-server start With both command successfully run you can go to ambari homepage at <http://your_sandbox_ip:8080> (user:admin,password:admin) to check everything's status. **By default hortonworks ambari disables Hbase, you need manually start the `Hbase` service at ambari homepage.** -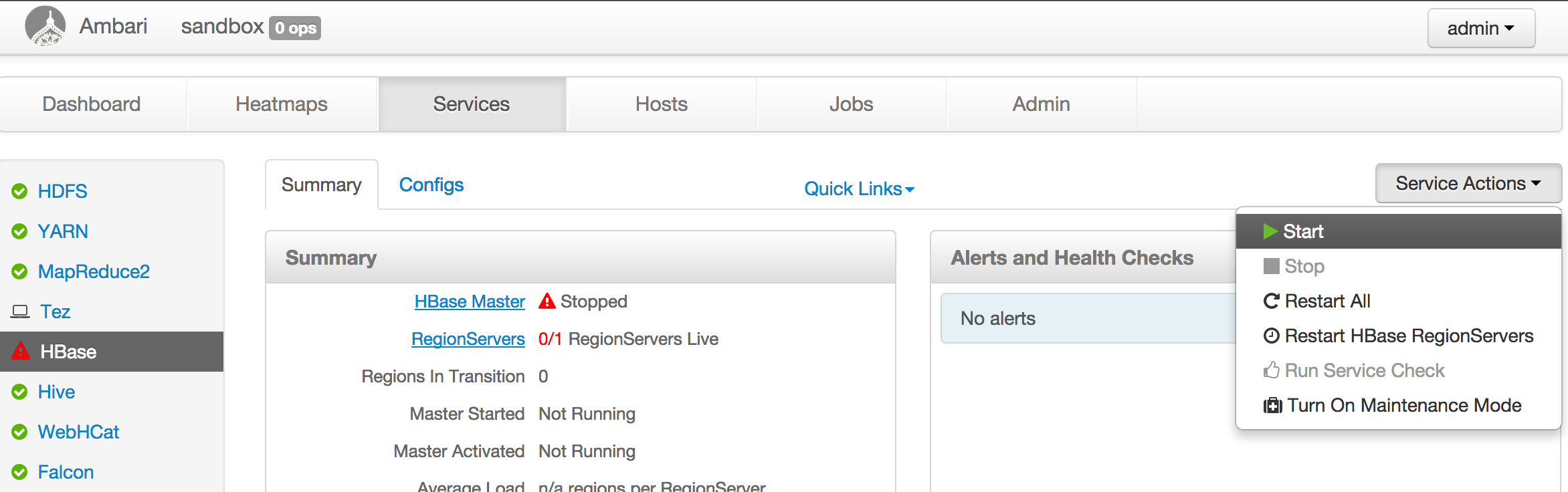 -**Additonal Info for setting up Hortonworks Sandbox on Virtual Box** - - Please make sure Hbase Master port [Default 60000] and Zookeeper [Default 2181] is forwarded to Host OS. http://git-wip-us.apache.org/repos/asf/kylin/blob/4c1c736e/website/_docs20/install/manual_install_guide.cn.md ---------------------------------------------------------------------- diff --git a/website/_docs20/install/manual_install_guide.cn.md b/website/_docs20/install/manual_install_guide.cn.md index b369568..e080c88 100644 --- a/website/_docs20/install/manual_install_guide.cn.md +++ b/website/_docs20/install/manual_install_guide.cn.md @@ -14,35 +14,16 @@ since: v0.7.1 åºæ¬ä¸æ¬æ解éäºèªå¨èæ¬ä¸çæ¯ä¸æ¥éª¤ãæ们åè®¾ä½ å·²ç»å¯¹Linuxä¸çHadoopæä½é常çæã ## åææ¡ä»¶ -* å·²å®è£ Tomcatï¼è¾åºå°CATALINA_HOMEï¼with CATALINA_HOME exported). * Kylin äºè¿å¶æ件æ·è´è³æ¬å°å¹¶è§£åï¼ä¹å使ç¨$KYLIN_HOMEå¼ç¨ - -## æ¥éª¤ - -### åå¤Jars - -Kylinä¼éè¦ä½¿ç¨ä¸¤ä¸ªjarå ï¼ä¸¤ä¸ªjarå åé ç½®å¨é»è®¤kylin.propertiesï¼ï¼there two jars and configured in the default kylin.propertiesï¼ - -``` -kylin.job.jar=/tmp/kylin/kylin-job-latest.jar - -``` - -è¿æ¯Kylinç¨äºMR jobsçjob jarå ãä½ éè¦å¤å¶ $KYLIN_HOME/job/target/kylin-job-latest.jar å° /tmp/kylin/ - -``` -kylin.coprocessor.local.jar=/tmp/kylin/kylin-coprocessor-latest.jar - -``` - -è¿æ¯ä¸ä¸ªKylinä¼æ¾å¨hbaseä¸çhbaseåå¤çjarå ãå®ç¨äºæé«æ§è½ãä½ éè¦å¤å¶ $KYLIN_HOME/storage/target/kylin-coprocessor-latest.jar å° /tmp/kylin/ +`export KYLIN_HOME=/path/to/kylin` +`cd $KYLIN_HOME` ### å¯å¨Kylin -以`./kylin.sh start` +以`./bin/kylin.sh start` å¯å¨Kylin -并以`./Kylin.sh stop` +并以`./bin/Kylin.sh stop` åæ¢Kylin http://git-wip-us.apache.org/repos/asf/kylin/blob/4c1c736e/website/_docs20/tutorial/cube_spark.md ---------------------------------------------------------------------- diff --git a/website/_docs20/tutorial/cube_spark.md b/website/_docs20/tutorial/cube_spark.md index 5f7893a..8ec8f04 100644 --- a/website/_docs20/tutorial/cube_spark.md +++ b/website/_docs20/tutorial/cube_spark.md @@ -24,12 +24,13 @@ export KYLIN_HOME=/usr/local/apache-kylin-2.0.0-SNAPSHOT-bin ## Prepare "kylin.env.hadoop-conf-dir" -To run Spark on Yarn, need specify **HADOOP_CONF_DIR** environment variable, which is the directory that contains the (client side) configuration files for Hadoop. In many Hadoop distributions the directory is "/etc/hadoop/conf"; But Kylin not only need access HDFS, Yarn and Hive, but also HBase, so the default directory might not have all necessary files. In this case, you need create a new directory and then copying or linking those client files (core-site.xml, yarn-site.xml, hive-site.xml and hbase-site.xml) there. In HDP 2.4, there is a conflict between hive-tez and Spark, so need change the default engine from "tez" to "mr" when copy for Kylin. +To run Spark on Yarn, need specify **HADOOP_CONF_DIR** environment variable, which is the directory that contains the (client side) configuration files for Hadoop. In many Hadoop distributions the directory is "/etc/hadoop/conf"; But Kylin not only need access HDFS, Yarn and Hive, but also HBase, so the default directory might not have all necessary files. In this case, you need create a new directory and then copying or linking those client files (core-site.xml, hdfs-site.xml, yarn-site.xml, hive-site.xml and hbase-site.xml) there. In HDP 2.4, there is a conflict between hive-tez and Spark, so need change the default engine from "tez" to "mr" when copy for Kylin. {% highlight Groff markup %} mkdir $KYLIN_HOME/hadoop-conf ln -s /etc/hadoop/conf/core-site.xml $KYLIN_HOME/hadoop-conf/core-site.xml +ln -s /etc/hadoop/conf/hdfs-site.xml $KYLIN_HOME/hadoop-conf/hdfs-site.xml ln -s /etc/hadoop/conf/yarn-site.xml $KYLIN_HOME/hadoop-conf/yarn-site.xml ln -s /etc/hbase/2.4.0.0-169/0/hbase-site.xml $KYLIN_HOME/hadoop-conf/hbase-site.xml cp /etc/hive/2.4.0.0-169/0/hive-site.xml $KYLIN_HOME/hadoop-conf/hive-site.xml @@ -106,7 +107,7 @@ After Kylin is started, access Kylin web, edit the "kylin_sales" cube, in the "A  -Click "Next" to the "Configuration Overwrites" page, click "+Property" to add property "kylin.engine.spark.rdd-partition-cut-mb" with value "100" (reasons below): +Click "Next" to the "Configuration Overwrites" page, click "+Property" to add property "kylin.engine.spark.rdd-partition-cut-mb" with value "500" (reasons below): 
{kind=link}