ymzx opened a new issue #16803: src/storage/./pooled_storage_manager.h:157: cudaMalloc failed: out of memory URL: https://github.com/apache/incubator-mxnet/issues/16803 ## Description it will get cudaMalloc failed: out of memory when i run pixellink model which likes FCN structure. 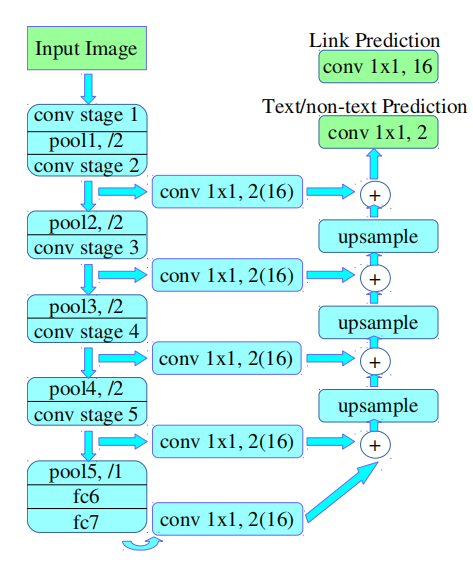 at first epoch, i can see the GPU memory usage is increasing, then, script is dead. 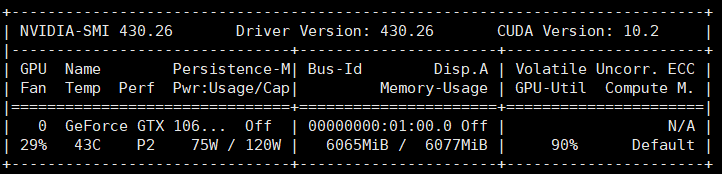 Ubuntu 18.04 net backbone is VGG16 NVIDIA Corporation GP106 [GeForce GTX 1060 6GB] batchsize = 8 512*512 per image I am so amazed that why 8 images can take up 6GB memory ### Error Message Traceback (most recent call last): File "main.py", line 36, in <module> main() File "main.py", line 33, in main train(config.epoch, dataloader, my_net, optimizer, ctx, iter_num) File "/home/djw/text_pixellink_GPU/pixellink-mxnet/train.py", line 25, in train pixel_loss_pos, pixel_loss_neg = loss_instance.pixel_loss(out_1, pixel_masks, pixel_pos_weights, neg_pixel_masks) File "/home/djw/text_pixellink_GPU/pixellink-mxnet/loss.py", line 43, in pixel_loss wrong_input = self.pixel_cross_entropy[i][0].asnumpy()[np.where(neg_pixel_masks[i].asnumpy()==1)] File "/home/dqy/ocr/anaconda3/envs/SSD/lib/python3.6/site-packages/mxnet/ndarray/ndarray.py", line 1996, in asnumpy ctypes.c_size_t(data.size))) File "/home/dqy/ocr/anaconda3/envs/SSD/lib/python3.6/site-packages/mxnet/base.py", line 253, in check_call raise MXNetError(py_str(_LIB.MXGetLastError())) mxnet.base.MXNetError: [20:57:05] src/storage/./pooled_storage_manager.h:157: cudaMalloc failed: out of memory Stack trace: [bt] (0) /home/dqy/ocr/anaconda3/envs/SSD/lib/python3.6/site-packages/mxnet/libmxnet.so(+0x4b04cb) [0x7fe6696cf4cb] [bt] (1) /home/dqy/ocr/anaconda3/envs/SSD/lib/python3.6/site-packages/mxnet/libmxnet.so(+0x2e653eb) [0x7fe66c0843eb] [bt] (2) /home/dqy/ocr/anaconda3/envs/SSD/lib/python3.6/site-packages/mxnet/libmxnet.so(+0x2e6af0f) [0x7fe66c089f0f] [bt] (3) /home/dqy/ocr/anaconda3/envs/SSD/lib/python3.6/site-packages/mxnet/libmxnet.so(mxnet::NDArray::CheckAndAlloc() const+0x1cc) [0x7fe669747aac] [bt] (4) /home/dqy/ocr/anaconda3/envs/SSD/lib/python3.6/site-packages/mxnet/libmxnet.so(+0x2667fdd) [0x7fe66b886fdd] [bt] (5) /home/dqy/ocr/anaconda3/envs/SSD/lib/python3.6/site-packages/mxnet/libmxnet.so(mxnet::imperative::PushFCompute(std::function<void (nnvm::NodeAttrs const&, mxnet::OpContext const&, std::vector<mxnet::TBlob, std::allocator<mxnet::TBlob> > const&, std::vector<mxnet::OpReqType, std::allocator<mxnet::OpReqType> > const&, std::vector<mxnet::TBlob, std::allocator<mxnet::TBlob> > const&)> const&, nnvm::Op const*, nnvm::NodeAttrs const&, mxnet::Context const&, std::vector<mxnet::engine::Var*, std::allocator<mxnet::engine::Var*> > const&, std::vector<mxnet::engine::Var*, std::allocator<mxnet::engine::Var*> > const&, std::vector<mxnet::Resource, std::allocator<mxnet::Resource> > const&, std::vector<mxnet::NDArray*, std::allocator<mxnet::NDArray*> > const&, std::vector<mxnet::NDArray*, std::allocator<mxnet::NDArray*> > const&, std::vector<unsigned int, std::allocator<unsigned int> > const&, std::vector<mxnet::OpReqType, std::allocator<mxnet::OpReqType> > const&)::{lambda(mxnet::RunContext)#1}::operator()(mxnet::RunContext) const+0x20f) [0x7fe66b8874af] [bt] (6) /home/dqy/ocr/anaconda3/envs/SSD/lib/python3.6/site-packages/mxnet/libmxnet.so(+0x25b5647) [0x7fe66b7d4647] [bt] (7) /home/dqy/ocr/anaconda3/envs/SSD/lib/python3.6/site-packages/mxnet/libmxnet.so(+0x25c1cd1) [0x7fe66b7e0cd1] [bt] (8) /home/dqy/ocr/anaconda3/envs/SSD/lib/python3.6/site-packages/mxnet/libmxnet.so(+0x25c51e0) [0x7fe66b7e41e0] ## To Reproduce train script as follow: def train(epoch, dataloader, net, optimizer, ctx, iter_num): for i in range(epoch): for i_batch, sample in enumerate(dataloader): start = time.time() images = sample[0].as_in_context(ctx) # torch.Size([batchsize, 3, 512, 512]) pixel_masks = sample[1].as_in_context(ctx) neg_pixel_masks = sample[2].as_in_context(ctx) pixel_pos_weights = sample[3].as_in_context(ctx) link_masks = sample[4].as_in_context(ctx) loss_instance = PixelLinkLoss() with autograd.record(): out_1, out_2 = net(images)# (2, 2, 256, 256),(2, 16, 256, 256) pixel_loss_pos, pixel_loss_neg = loss_instance.pixel_loss(out_1, pixel_masks, pixel_pos_weights, neg_pixel_masks) link_loss_pos, link_loss_neg = loss_instance.link_loss(out_2, link_masks) pixel_loss = pixel_loss_pos + pixel_loss_neg link_loss = link_loss_pos + link_loss_neg losses = config.pixel_weight * pixel_loss + config.link_weight * link_loss losses.backward() optimizer.step(images.shape[0]) end = time.time() print('losses:', losses.asscalar(), 'pixel_loss', pixel_loss.asscalar(),'link_loss', link_loss.asscalar(), 'time_cost:', round(end-start, 3), 's') ## What have you tried to solve it? 1. set batchsize = 2 or 4 , after about 10 epoch, also get out of memory as above. 2. windos is ok with batchsize = 4 and run successful ## Environment x86_64 DISTRIB_ID=Ubuntu DISTRIB_RELEASE=18.04 DISTRIB_CODENAME=bionic DISTRIB_DESCRIPTION="Ubuntu 18.04.2 LTS" NAME="Ubuntu" VERSION="18.04.2 LTS (Bionic Beaver)" ID=ubuntu ID_LIKE=debian PRETTY_NAME="Ubuntu 18.04.2 LTS" VERSION_ID="18.04" HOME_URL="https://www.ubuntu.com/"; SUPPORT_URL="https://help.ubuntu.com/"; BUG_REPORT_URL="https://bugs.launchpad.net/ubuntu/"; PRIVACY_POLICY_URL="https://www.ubuntu.com/legal/terms-and-policies/privacy-policy"; VERSION_CODENAME=bionic UBUNTU_CODENAME=bionic net backbone is VGG16 NVIDIA Corporation GP106 [GeForce GTX 1060 6GB] # paste outputs here ```
{kind=link}
{kind=link}
---------------------------------------------------------------- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services