berg-xu opened a new issue, #2064: URL: https://github.com/apache/incubator-seatunnel/issues/2064
### Search before asking - [X] I had searched in the [issues](https://github.com/apache/incubator-seatunnel/issues?q=is%3Aissue+label%3A%22bug%22) and found no similar issues. ### What happened 我尝试基于seatunnel File Source 读取本地文件(本地文件存储在seatunnel节点上),并测试Sink Console。 但我基于flink的standalone模式时,即执行命令: bin/start-seatunnel-flink.sh --config ./config/flink.streaming.local.file.to.hive.conf 最后作业执行完后会在打印出文件内容得结果。 但是我尝试使用flink on yarn模式提交该命令的时候,命令为: bin/start-seatunnel-flink.sh -m yarn-cluster -ynm seatunnel-file-hive-3 --config ./config/flink.streaming.local.file.to.hive.conf 此时出现如下错误: 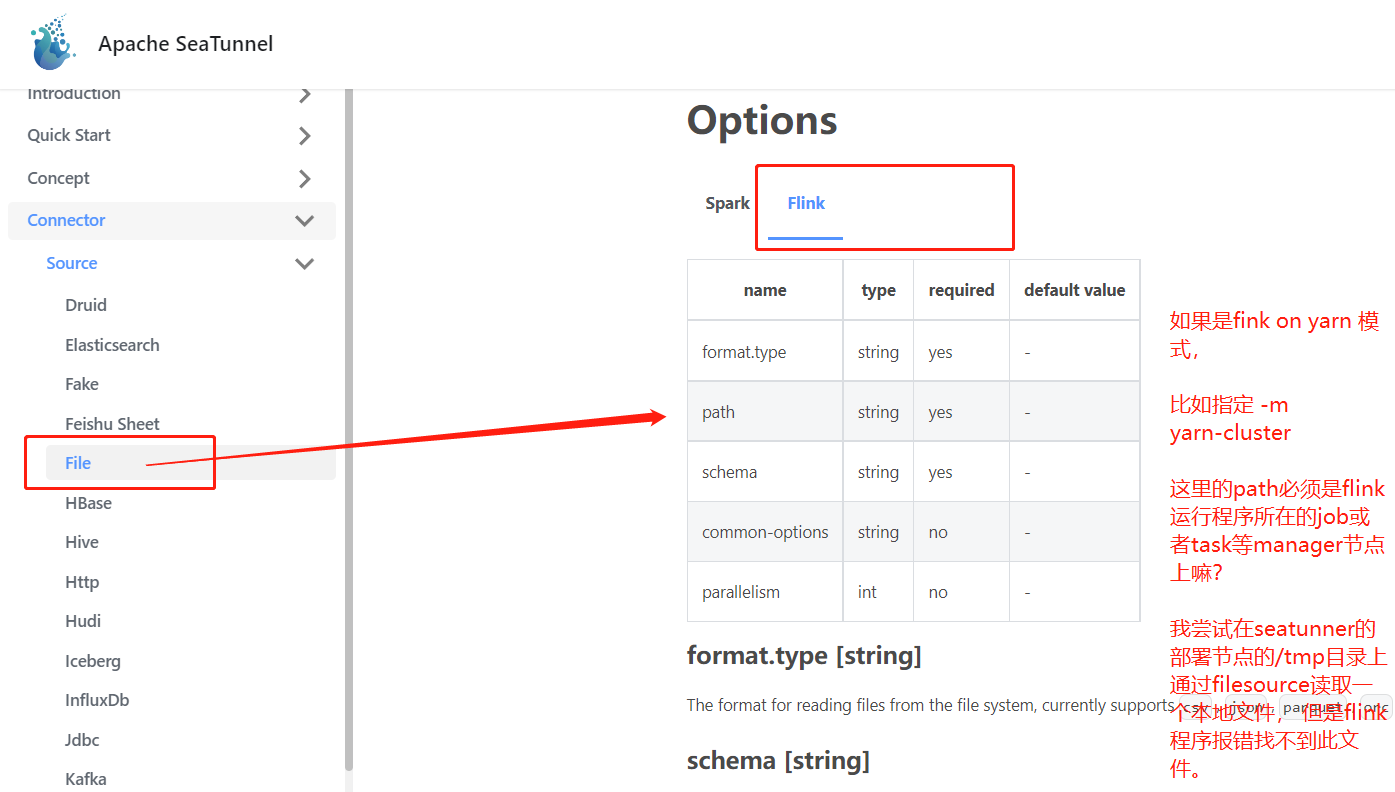 从错误内容可以看到, 应该是执行flink应用程序时候, 读取不到本地文件。 请问,此时的本地文件该如何配置呢? 从需求场景来看, 我在我的数据存储节点上,部署了seatunnel环境,并在当前数据存储节点上执行conf脚本来提交flink任务到yarn上。 但是flink执行应用程序要求本地文件必须在jobmanager上或者taskmanage上,那是否意味着我需要把本地需要同步的文件数据全部复制拷贝一份到yarn的datanode节点上?或者yarndatanode节点上? 或者flink的的resourcemanager节点上? 请问我该如何来处理这个问题? 多谢指导!!! ### SeaTunnel Version 2.1.2 ### SeaTunnel Config ```conf env { execution.parallelism = 1 #execution.checkpoint.interval = 10000 execution.checkpoint.data-uri = "hdfs://nn:9000/flink/checkpoints" } source { FileSource { path = "file:///tmp/wordsit.txt" format.type = "text" schema = "[{\"type\":\"string\"},{\"type\":\"string\"},{\"type\":\"string\"},{\"type\":\"int\"},{\"type\":\"int\"},{\"type\":\"int\"},{\"type\":\"int\"},{\"type\":\"int\"},{\"type\":\"int\"}]" } } transform { Split{ separator = "," fields = ["c1", "c2", "c3", "c4", "c5", "c6", "c7", "c8", "c9"] } } sink { ConsoleSink { } } ``` ### Running Command ```shell bin/start-seatunnel-flink.sh -m yarn-cluster -ynm seatunnel-file-hive-3 --config ./config/flink.streaming.local.file.to.hive.conf ``` ### Error Exception ```log Caused by: org.apache.flink.runtime.client.JobInitializationException: Could not start the JobMaster. at org.apache.flink.runtime.jobmaster.DefaultJobMasterServiceProcess.lambda$new$0(DefaultJobMasterServiceProcess.java:97) ~[flink-dist_2.11-1.13.6.jar:1.13.6] at java.util.concurrent.CompletableFuture.uniWhenComplete(CompletableFuture.java:774) ~[?:1.8.0_301] at java.util.concurrent.CompletableFuture$UniWhenComplete.tryFire(CompletableFuture.java:750) ~[?:1.8.0_301] at java.util.concurrent.CompletableFuture.postComplete(CompletableFuture.java:488) ~[?:1.8.0_301] at java.util.concurrent.CompletableFuture$AsyncSupply.run(CompletableFuture.java:1609) ~[?:1.8.0_301] at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511) ~[?:1.8.0_301] at java.util.concurrent.FutureTask.run(FutureTask.java:266) ~[?:1.8.0_301] at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.access$201(ScheduledThreadPoolExecutor.java:180) ~[?:1.8.0_301] at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.run(ScheduledThreadPoolExecutor.java:293) ~[?:1.8.0_301] at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149) ~[?:1.8.0_301] at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) ~[?:1.8.0_301] at java.lang.Thread.run(Thread.java:748) ~[?:1.8.0_301] Caused by: java.util.concurrent.CompletionException: java.lang.RuntimeException: org.apache.flink.runtime.JobException: Creating the input splits caused an error: File file:/tmp/wordsit.txt does not exist or the user running Flink ('hadoop') has insufficient permissions to access it. at java.util.concurrent.CompletableFuture.encodeThrowable(CompletableFuture.java:273) ~[?:1.8.0_301] at java.util.concurrent.CompletableFuture.completeThrowable(CompletableFuture.java:280) ~[?:1.8.0_301] at java.util.concurrent.CompletableFuture$AsyncSupply.run(CompletableFuture.java:1606) ~[?:1.8.0_301] at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511) ~[?:1.8.0_301] at java.util.concurrent.FutureTask.run(FutureTask.java:266) ~[?:1.8.0_301] at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.access$201(ScheduledThreadPoolExecutor.java:180) ~[?:1.8.0_301] at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.run(ScheduledThreadPoolExecutor.java:293) ~[?:1.8.0_301] at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149) ~[?:1.8.0_301] at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) ~[?:1.8.0_301] at java.lang.Thread.run(Thread.java:748) ~[?:1.8.0_301] ``` ### Flink or Spark Version flink version: 1.13.6 ### Java or Scala Version scala version: 2.11.12 java version: 8 ### Screenshots _No response_ ### Are you willing to submit PR? - [ ] Yes I am willing to submit a PR! ### Code of Conduct - [X] I agree to follow this project's [Code of Conduct](https://www.apache.org/foundation/policies/conduct) -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: [email protected] For queries about this service, please contact Infrastructure at: [email protected]
{kind=link}