xqhxxx opened a new issue, #4142: URL: https://github.com/apache/incubator-seatunnel/issues/4142
### Search before asking - [X] I had searched in the [issues](https://github.com/apache/incubator-seatunnel/issues?q=is%3Aissue+label%3A%22bug%22) and found no similar issues. ### What happened 在配置source时,使用oracle数据源时,执行时报转换错误 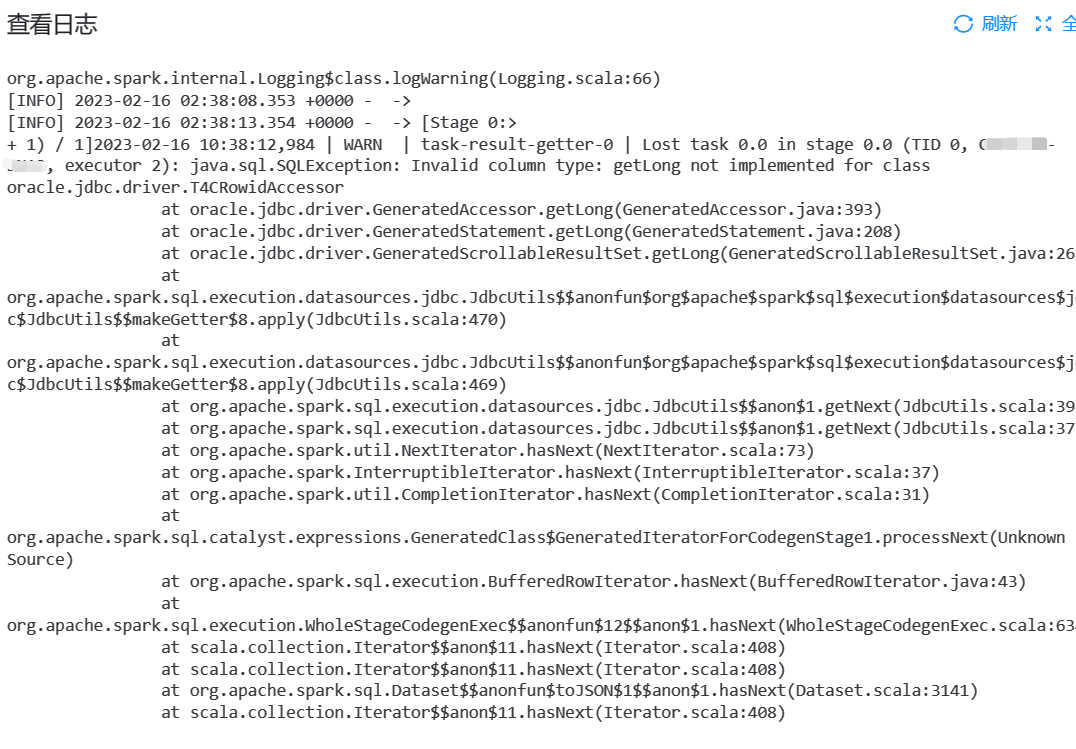 。 请问怎么有什么方法解决,谢 ### SeaTunnel Version 2.1.3 ### SeaTunnel Config ```conf 2.1.3 ``` ### Running Command ```shell ./bin/start-seatunnel-spark.sh \ --master yarn \ --deploy-mode client \ --config ./config/oracle-print.conf ``` ### Error Exception ```log [INFO] 2023-02-16 02:38:08.353 +0000 - -> [INFO] 2023-02-16 02:38:13.354 +0000 - -> [Stage 0:> (0 + 1) / 1]2023-02-16 10:38:12,984 | WARN | task-result-getter-0 | Lost task 0.0 in stage 0.0 (TID 0, xxxxxx, executor 2): java.sql.SQLException: Invalid column type: getLong not implemented for class oracle.jdbc.driver.T4CRowidAccessor at oracle.jdbc.driver.GeneratedAccessor.getLong(GeneratedAccessor.java:393) at oracle.jdbc.driver.GeneratedStatement.getLong(GeneratedStatement.java:208) at oracle.jdbc.driver.GeneratedScrollableResultSet.getLong(GeneratedScrollableResultSet.java:261) at org.apache.spark.sql.execution.datasources.jdbc.JdbcUtils$$anonfun$org$apache$spark$sql$execution$datasources$jdbc$JdbcUtils$$makeGetter$8.apply(JdbcUtils.scala:470) at org.apache.spark.sql.execution.datasources.jdbc.JdbcUtils$$anonfun$org$apache$spark$sql$execution$datasources$jdbc$JdbcUtils$$makeGetter$8.apply(JdbcUtils.scala:469) at org.apache.spark.sql.execution.datasources.jdbc.JdbcUtils$$anon$1.getNext(JdbcUtils.scala:391) at org.apache.spark.sql.execution.datasources.jdbc.JdbcUtils$$anon$1.getNext(JdbcUtils.scala:373) at org.apache.spark.util.NextIterator.hasNext(NextIterator.scala:73) at org.apache.spark.InterruptibleIterator.hasNext(InterruptibleIterator.scala:37) at org.apache.spark.util.CompletionIterator.hasNext(CompletionIterator.scala:31) at org.apache.spark.sql.catalyst.expressions.GeneratedClass$GeneratedIteratorForCodegenStage1.processNext(Unknown Source) at org.apache.spark.sql.execution.BufferedRowIterator.hasNext(BufferedRowIterator.java:43) at org.apache.spark.sql.execution.WholeStageCodegenExec$$anonfun$12$$anon$1.hasNext(WholeStageCodegenExec.scala:634) at scala.collection.Iterator$$anon$11.hasNext(Iterator.scala:408) at scala.collection.Iterator$$anon$11.hasNext(Iterator.scala:408) at org.apache.spark.sql.Dataset$$anonfun$toJSON$1$$anon$1.hasNext(Dataset.scala:3141) at scala.collection.Iterator$$anon$11.hasNext(Iterator.scala:408) at org.apache.spark.sql.catalyst.expressions.GeneratedClass$GeneratedIteratorForCodegenStage2.processNext(Unknown Source) at org.apache.spark.sql.execution.BufferedRowIterator.hasNext(BufferedRowIterator.java:43) at org.apache.spark.sql.execution.WholeStageCodegenExec$$anonfun$12$$anon$1.hasNext(WholeStageCodegenExec.scala:634) at org.apache.spark.sql.execution.SparkPlan$$anonfun$2.apply(SparkPlan.scala:270) at org.apache.spark.sql.execution.SparkPlan$$anonfun$2.apply(SparkPlan.scala:264) at org.apache.spark.rdd.RDD$$anonfun$mapPartitionsInternal$1$$anonfun$apply$25.apply(RDD.scala:860) at org.apache.spark.rdd.RDD$$anonfun$mapPartitionsInternal$1$$anonfun$apply$25.apply(RDD.scala:860) at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:49) at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:348) at org.apache.spark.rdd.RDD.iterator(RDD.scala:312) at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:49) at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:348) at org.apache.spark.rdd.RDD.iterator(RDD.scala:312) at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:87) at org.apache.spark.scheduler.Task.run(Task.scala:110) at org.apache.spark.executor.Executor$TaskRunner$$anonfun$4.apply(Executor.scala:345) at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1424) at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:351) at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149) at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) at java.lang.Thread.run(Thread.java:748) | org.apache.spark.internal.Logging$class.logWarning(Logging.scala:66) [INFO] 2023-02-16 02:38:25.355 +0000 - -> 2023-02-16 10:38:24,928 | WARN | task-result-getter-2 | Lost task 0.2 in stage 0.0 (TID 2, xxxxxxxx, executor 3): java.sql.SQLException: Invalid column type: getLong not implemented for class oracle.jdbc.driver.T4CRowidAccessor at oracle.jdbc.driver.GeneratedAccessor.getLong(GeneratedAccessor.java:393) at oracle.jdbc.driver.GeneratedStatement.getLong(GeneratedStatement.java:208) at oracle.jdbc.driver.GeneratedScrollableResultSet.getLong(GeneratedScrollableResultSet.java:261) at org.apache.spark.sql.execution.datasources.jdbc.JdbcUtils$$anonfun$org$apache$spark$sql$execution$datasources$jdbc$JdbcUtils$$makeGetter$8.apply(JdbcUtils.scala:470) at org.apache.spark.sql.execution.datasources.jdbc.JdbcUtils$$anonfun$org$apache$spark$sql$execution$datasources$jdbc$JdbcUtils$$makeGetter$8.apply(JdbcUtils.scala:469) at org.apache.spark.sql.execution.datasources.jdbc.JdbcUtils$$anon$1.getNext(JdbcUtils.scala:391) at org.apache.spark.sql.execution.datasources.jdbc.JdbcUtils$$anon$1.getNext(JdbcUtils.scala:373) at org.apache.spark.util.NextIterator.hasNext(NextIterator.scala:73) at org.apache.spark.InterruptibleIterator.hasNext(InterruptibleIterator.scala:37) at org.apache.spark.util.CompletionIterator.hasNext(CompletionIterator.scala:31) at org.apache.spark.sql.catalyst.expressions.GeneratedClass$GeneratedIteratorForCodegenStage1.processNext(Unknown Source) at org.apache.spark.sql.execution.BufferedRowIterator.hasNext(BufferedRowIterator.java:43) at org.apache.spark.sql.execution.WholeStageCodegenExec$$anonfun$12$$anon$1.hasNext(WholeStageCodegenExec.scala:634) at scala.collection.Iterator$$anon$11.hasNext(Iterator.scala:408) at scala.collection.Iterator$$anon$11.hasNext(Iterator.scala:408) at org.apache.spark.sql.Dataset$$anonfun$toJSON$1$$anon$1.hasNext(Dataset.scala:3141) at scala.collection.Iterator$$anon$11.hasNext(Iterator.scala:408) at org.apache.spark.sql.catalyst.expressions.GeneratedClass$GeneratedIteratorForCodegenStage2.processNext(Unknown Source) at org.apache.spark.sql.execution.BufferedRowIterator.hasNext(BufferedRowIterator.java:43) at org.apache.spark.sql.execution.WholeStageCodegenExec$$anonfun$12$$anon$1.hasNext(WholeStageCodegenExec.scala:634) at org.apache.spark.sql.execution.SparkPlan$$anonfun$2.apply(SparkPlan.scala:270) at org.apache.spark.sql.execution.SparkPlan$$anonfun$2.apply(SparkPlan.scala:264) at org.apache.spark.rdd.RDD$$anonfun$mapPartitionsInternal$1$$anonfun$apply$25.apply(RDD.scala:860) at org.apache.spark.rdd.RDD$$anonfun$mapPartitionsInternal$1$$anonfun$apply$25.apply(RDD.scala:860) at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:49) at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:348) at org.apache.spark.rdd.RDD.iterator(RDD.scala:312) at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:49) at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:348) at org.apache.spark.rdd.RDD.iterator(RDD.scala:312) at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:87) at org.apache.spark.scheduler.Task.run(Task.scala:110) at org.apache.spark.executor.Executor$TaskRunner$$anonfun$4.apply(Executor.scala:345) at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1424) at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:351) at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149) at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) at java.lang.Thread.run(Thread.java:748) | org.apache.spark.internal.Logging$class.logWarning(Logging.scala:66) [INFO] 2023-02-16 02:38:30.357 +0000 - -> 2023-02-16 10:38:30,078 | ERROR | task-result-getter-3 | Task 0 in stage 0.0 failed 4 times; aborting job | org.apache.spark.internal.Logging$class.logError(Logging.scala:70) [Stage 0:> (0 + 0) / 1]2023-02-16 10:38:30,101 | ERROR | main | =============================================================================== | org.apache.seatunnel.core.base.Seatunnel.showFatalError(Seatunnel.java:61) 2023-02-16 10:38:30,102 | ERROR | main | Fatal Error, | org.apache.seatunnel.core.base.Seatunnel.showFatalError(Seatunnel.java:64) 2023-02-16 10:38:30,102 | ERROR | main | Please submit bug report in https://github.com/apache/incubator-seatunnel/issues | org.apache.seatunnel.core.base.Seatunnel.showFatalError(Seatunnel.java:66) 2023-02-16 10:38:30,105 | ERROR | main | Reason:Execute Spark task error | org.apache.seatunnel.core.base.Seatunnel.showFatalError(Seatunnel.java:68) 2023-02-16 10:38:30,109 | ERROR | main | Exception StackTrace:org.apache.seatunnel.core.base.exception.CommandExecuteException: Execute Spark task error at org.apache.seatunnel.core.spark.command.SparkTaskExecuteCommand.execute(SparkTaskExecuteCommand.java:70) at org.apache.seatunnel.core.base.Seatunnel.run(Seatunnel.java:40) at org.apache.seatunnel.core.spark.SeatunnelSpark.main(SeatunnelSpark.java:33) at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62) at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) at java.lang.reflect.Method.invoke(Method.java:498) at org.apache.spark.deploy.JavaMainApplication.start(SparkApplication.scala:52) at org.apache.spark.deploy.SparkSubmit$.org$apache$spark$deploy$SparkSubmit$$runMain(SparkSubmit.scala:934) at org.apache.spark.deploy.SparkSubmit$.doRunMain$1(SparkSubmit.scala:195) at org.apache.spark.deploy.SparkSubmit$.submit(SparkSubmit.scala:220) at org.apache.spark.deploy.SparkSubmit$.main(SparkSubmit.scala:140) at org.apache.spark.deploy.SparkSubmit.main(SparkSubmit.scala) Caused by: org.apache.spark.SparkException: Job aborted due to stage failure: Task 0 in stage 0.0 failed 4 times, most recent failure: Lost task 0.3 in stage 0.0 (TID 3, xxxxxxxxxxxx, executor 4): java.sql.SQLException: Invalid column type: getLong not implemented for class oracle.jdbc.driver.T4CRowidAccessor at oracle.jdbc.driver.GeneratedAccessor.getLong(GeneratedAccessor.java:393) at oracle.jdbc.driver.GeneratedStatement.getLong(GeneratedStatement.java:208) at oracle.jdbc.driver.GeneratedScrollableResultSet.getLong(GeneratedScrollableResultSet.java:261) at org.apache.spark.sql.execution.datasources.jdbc.JdbcUtils$$anonfun$org$apache$spark$sql$execution$datasources$jdbc$JdbcUtils$$makeGetter$8.apply(JdbcUtils.scala:470) at org.apache.spark.sql.execution.datasources.jdbc.JdbcUtils$$anonfun$org$apache$spark$sql$execution$datasources$jdbc$JdbcUtils$$makeGetter$8.apply(JdbcUtils.scala:469) at org.apache.spark.sql.execution.datasources.jdbc.JdbcUtils$$anon$1.getNext(JdbcUtils.scala:391) at org.apache.spark.sql.execution.datasources.jdbc.JdbcUtils$$anon$1.getNext(JdbcUtils.scala:373) at org.apache.spark.util.NextIterator.hasNext(NextIterator.scala:73) at org.apache.spark.InterruptibleIterator.hasNext(InterruptibleIterator.scala:37) at org.apache.spark.util.CompletionIterator.hasNext(CompletionIterator.scala:31) at org.apache.spark.sql.catalyst.expressions.GeneratedClass$GeneratedIteratorForCodegenStage1.processNext(Unknown Source) at org.apache.spark.sql.execution.BufferedRowIterator.hasNext(BufferedRowIterator.java:43) at org.apache.spark.sql.execution.WholeStageCodegenExec$$anonfun$12$$anon$1.hasNext(WholeStageCodegenExec.scala:634) at scala.collection.Iterator$$anon$11.hasNext(Iterator.scala:408) at scala.collection.Iterator$$anon$11.hasNext(Iterator.scala:408) at org.apache.spark.sql.Dataset$$anonfun$toJSON$1$$anon$1.hasNext(Dataset.scala:3141) at scala.collection.Iterator$$anon$11.hasNext(Iterator.scala:408) at org.apache.spark.sql.catalyst.expressions.GeneratedClass$GeneratedIteratorForCodegenStage2.processNext(Unknown Source) at org.apache.spark.sql.execution.BufferedRowIterator.hasNext(BufferedRowIterator.java:43) at org.apache.spark.sql.execution.WholeStageCodegenExec$$anonfun$12$$anon$1.hasNext(WholeStageCodegenExec.scala:634) at org.apache.spark.sql.execution.SparkPlan$$anonfun$2.apply(SparkPlan.scala:270) at org.apache.spark.sql.execution.SparkPlan$$anonfun$2.apply(SparkPlan.scala:264) at org.apache.spark.rdd.RDD$$anonfun$mapPartitionsInternal$1$$anonfun$apply$25.apply(RDD.scala:860) at org.apache.spark.rdd.RDD$$anonfun$mapPartitionsInternal$1$$anonfun$apply$25.apply(RDD.scala:860) at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:49) at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:348) at org.apache.spark.rdd.RDD.iterator(RDD.scala:312) at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:49) at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:348) at org.apache.spark.rdd.RDD.iterator(RDD.scala:312) at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:87) at org.apache.spark.scheduler.Task.run(Task.scala:110) at org.apache.spark.executor.Executor$TaskRunner$$anonfun$4.apply(Executor.scala:345) at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1424) at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:351) at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149) at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) at java.lang.Thread.run(Thread.java:748) Driver stacktrace: at org.apache.spark.scheduler.DAGScheduler.org$apache$spark$scheduler$DAGScheduler$$failJobAndIndependentStages(DAGScheduler.scala:1705) at org.apache.spark.scheduler.DAGScheduler$$anonfun$abortStage$1.apply(DAGScheduler.scala:1693) at org.apache.spark.scheduler.DAGScheduler$$anonfun$abortStage$1.apply(DAGScheduler.scala:1692) at scala.collection.mutable.ResizableArray$class.foreach(ResizableArray.scala:59) at scala.collection.mutable.ArrayBuffer.foreach(ArrayBuffer.scala:48) at org.apache.spark.scheduler.DAGScheduler.abortStage(DAGScheduler.scala:1692) at org.apache.spark.scheduler.DAGScheduler$$anonfun$handleTaskSetFailed$1.apply(DAGScheduler.scala:874) at org.apache.spark.scheduler.DAGScheduler$$anonfun$handleTaskSetFailed$1.apply(DAGScheduler.scala:874) at scala.Option.foreach(Option.scala:257) at org.apache.spark.scheduler.DAGScheduler.handleTaskSetFailed(DAGScheduler.scala:874) at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.doOnReceive(DAGScheduler.scala:1926) at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.onReceive(DAGScheduler.scala:1875) at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.onReceive(DAGScheduler.scala:1864) at org.apache.spark.util.EventLoop$$anon$1.run(EventLoop.scala:48) at org.apache.spark.scheduler.DAGScheduler.runJob(DAGScheduler.scala:683) at org.apache.spark.SparkContext.runJob(SparkContext.scala:2047) at org.apache.spark.SparkContext.runJob(SparkContext.scala:2068) at org.apache.spark.SparkContext.runJob(SparkContext.scala:2087) at org.apache.spark.sql.execution.SparkPlan.executeTake(SparkPlan.scala:380) at org.apache.spark.sql.execution.CollectLimitExec.executeCollect(limit.scala:38) at org.apache.spark.sql.Dataset.org$apache$spark$sql$Dataset$$collectFromPlan(Dataset.scala:3275) at org.apache.spark.sql.Dataset$$anonfun$head$1.apply(Dataset.scala:2486) at org.apache.spark.sql.Dataset$$anonfun$head$1.apply(Dataset.scala:2486) at org.apache.spark.sql.Dataset$$anonfun$52.apply(Dataset.scala:3256) at org.apache.spark.sql.execution.SQLExecution$.withNewExecutionId(SQLExecution.scala:90) at org.apache.spark.sql.Dataset.withAction(Dataset.scala:3255) at org.apache.spark.sql.Dataset.head(Dataset.scala:2486) at org.apache.spark.sql.Dataset.take(Dataset.scala:2700) at org.apache.seatunnel.spark.console.sink.Console.output(Console.scala:47) at org.apache.seatunnel.spark.console.sink.Console.output(Console.scala:28) at org.apache.seatunnel.spark.SparkEnvironment.sinkProcess(SparkEnvironment.java:179) at org.apache.seatunnel.spark.batch.SparkBatchExecution.start(SparkBatchExecution.java:54) at org.apache.seatunnel.core.spark.command.SparkTaskExecuteCommand.execute(SparkTaskExecuteCommand.java:67) ... 12 more Caused by: java.sql.SQLException: Invalid column type: getLong not implemented for class oracle.jdbc.driver.T4CRowidAccessor at oracle.jdbc.driver.GeneratedAccessor.getLong(GeneratedAccessor.java:393) at oracle.jdbc.driver.GeneratedStatement.getLong(GeneratedStatement.java:208) at oracle.jdbc.driver.GeneratedScrollableResultSet.getLong(GeneratedScrollableResultSet.java:261) at org.apache.spark.sql.execution.datasources.jdbc.JdbcUtils$$anonfun$org$apache$spark$sql$execution$datasources$jdbc$JdbcUtils$$makeGetter$8.apply(JdbcUtils.scala:470) at org.apache.spark.sql.execution.datasources.jdbc.JdbcUtils$$anonfun$org$apache$spark$sql$execution$datasources$jdbc$JdbcUtils$$makeGetter$8.apply(JdbcUtils.scala:469) at org.apache.spark.sql.execution.datasources.jdbc.JdbcUtils$$anon$1.getNext(JdbcUtils.scala:391) at org.apache.spark.sql.execution.datasources.jdbc.JdbcUtils$$anon$1.getNext(JdbcUtils.scala:373) at org.apache.spark.util.NextIterator.hasNext(NextIterator.scala:73) at org.apache.spark.InterruptibleIterator.hasNext(InterruptibleIterator.scala:37) at org.apache.spark.util.CompletionIterator.hasNext(CompletionIterator.scala:31) at org.apache.spark.sql.catalyst.expressions.GeneratedClass$GeneratedIteratorForCodegenStage1.processNext(Unknown Source) at org.apache.spark.sql.execution.BufferedRowIterator.hasNext(BufferedRowIterator.java:43) at org.apache.spark.sql.execution.WholeStageCodegenExec$$anonfun$12$$anon$1.hasNext(WholeStageCodegenExec.scala:634) at scala.collection.Iterator$$anon$11.hasNext(Iterator.scala:408) at scala.collection.Iterator$$anon$11.hasNext(Iterator.scala:408) at org.apache.spark.sql.Dataset$$anonfun$toJSON$1$$anon$1.hasNext(Dataset.scala:3141) at scala.collection.Iterator$$anon$11.hasNext(Iterator.scala:408) at org.apache.spark.sql.catalyst.expressions.GeneratedClass$GeneratedIteratorForCodegenStage2.processNext(Unknown Source) at org.apache.spark.sql.execution.BufferedRowIterator.hasNext(BufferedRowIterator.java:43) at org.apache.spark.sql.execution.WholeStageCodegenExec$$anonfun$12$$anon$1.hasNext(WholeStageCodegenExec.scala:634) at org.apache.spark.sql.execution.SparkPlan$$anonfun$2.apply(SparkPlan.scala:270) at org.apache.spark.sql.execution.SparkPlan$$anonfun$2.apply(SparkPlan.scala:264) at org.apache.spark.rdd.RDD$$anonfun$mapPartitionsInternal$1$$anonfun$apply$25.apply(RDD.scala:860) at org.apache.spark.rdd.RDD$$anonfun$mapPartitionsInternal$1$$anonfun$apply$25.apply(RDD.scala:860) at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:49) at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:348) at org.apache.spark.rdd.RDD.iterator(RDD.scala:312) at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:49) at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:348) at org.apache.spark.rdd.RDD.iterator(RDD.scala:312) at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:87) at org.apache.spark.scheduler.Task.run(Task.scala:110) at org.apache.spark.executor.Executor$TaskRunner$$anonfun$4.apply(Executor.scala:345) at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1424) at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:351) at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149) at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) at java.lang.Thread.run(Thread.java:748) | org.apache.seatunnel.core.base.Seatunnel.showFatalError(Seatunnel.java:69) 2023-02-16 10:38:30,110 | ERROR | main | =============================================================================== | org.apache.seatunnel.core.base.Seatunnel.showFatalError(Seatunnel.java:70) Exception in thread "main" org.apache.seatunnel.core.base.exception.CommandExecuteException: Execute Spark task error at org.apache.seatunnel.core.spark.command.SparkTaskExecuteCommand.execute(SparkTaskExecuteCommand.java:70) at org.apache.seatunnel.core.base.Seatunnel.run(Seatunnel.java:40) at org.apache.seatunnel.core.spark.SeatunnelSpark.main(SeatunnelSpark.java:33) at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62) at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) at java.lang.reflect.Method.invoke(Method.java:498) at org.apache.spark.deploy.JavaMainApplication.start(SparkApplication.scala:52) at org.apache.spark.deploy.SparkSubmit$.org$apache$spark$deploy$SparkSubmit$$runMain(SparkSubmit.scala:934) at org.apache.spark.deploy.SparkSubmit$.doRunMain$1(SparkSubmit.scala:195) at org.apache.spark.deploy.SparkSubmit$.submit(SparkSubmit.scala:220) at org.apache.spark.deploy.SparkSubmit$.main(SparkSubmit.scala:140) at org.apache.spark.deploy.SparkSubmit.main(SparkSubmit.scala) Caused by: org.apache.spark.SparkException: Job aborted due to stage failure: Task 0 in stage 0.0 failed 4 times, most recent failure: Lost task 0.3 in stage 0.0 (TID 3,xxxxxxxxxxxx, executor 4): java.sql.SQLException: Invalid column type: getLong not implemented for class oracle.jdbc.driver.T4CRowidAccessor at oracle.jdbc.driver.GeneratedAccessor.getLong(GeneratedAccessor.java:393) at oracle.jdbc.driver.GeneratedStatement.getLong(GeneratedStatement.java:208) at oracle.jdbc.driver.GeneratedScrollableResultSet.getLong(GeneratedScrollableResultSet.java:261) at org.apache.spark.sql.execution.datasources.jdbc.JdbcUtils$$anonfun$org$apache$spark$sql$execution$datasources$jdbc$JdbcUtils$$makeGetter$8.apply(JdbcUtils.scala:470) at org.apache.spark.sql.execution.datasources.jdbc.JdbcUtils$$anonfun$org$apache$spark$sql$execution$datasources$jdbc$JdbcUtils$$makeGetter$8.apply(JdbcUtils.scala:469) at org.apache.spark.sql.execution.datasources.jdbc.JdbcUtils$$anon$1.getNext(JdbcUtils.scala:391) at org.apache.spark.sql.execution.datasources.jdbc.JdbcUtils$$anon$1.getNext(JdbcUtils.scala:373) at org.apache.spark.util.NextIterator.hasNext(NextIterator.scala:73) at org.apache.spark.InterruptibleIterator.hasNext(InterruptibleIterator.scala:37) at org.apache.spark.util.CompletionIterator.hasNext(CompletionIterator.scala:31) at org.apache.spark.sql.catalyst.expressions.GeneratedClass$GeneratedIteratorForCodegenStage1.processNext(Unknown Source) at org.apache.spark.sql.execution.BufferedRowIterator.hasNext(BufferedRowIterator.java:43) at org.apache.spark.sql.execution.WholeStageCodegenExec$$anonfun$12$$anon$1.hasNext(WholeStageCodegenExec.scala:634) at scala.collection.Iterator$$anon$11.hasNext(Iterator.scala:408) at scala.collection.Iterator$$anon$11.hasNext(Iterator.scala:408) at org.apache.spark.sql.Dataset$$anonfun$toJSON$1$$anon$1.hasNext(Dataset.scala:3141) at scala.collection.Iterator$$anon$11.hasNext(Iterator.scala:408) at org.apache.spark.sql.catalyst.expressions.GeneratedClass$GeneratedIteratorForCodegenStage2.processNext(Unknown Source) at org.apache.spark.sql.execution.BufferedRowIterator.hasNext(BufferedRowIterator.java:43) at org.apache.spark.sql.execution.WholeStageCodegenExec$$anonfun$12$$anon$1.hasNext(WholeStageCodegenExec.scala:634) at org.apache.spark.sql.execution.SparkPlan$$anonfun$2.apply(SparkPlan.scala:270) at org.apache.spark.sql.execution.SparkPlan$$anonfun$2.apply(SparkPlan.scala:264) at org.apache.spark.rdd.RDD$$anonfun$mapPartitionsInternal$1$$anonfun$apply$25.apply(RDD.scala:860) at org.apache.spark.rdd.RDD$$anonfun$mapPartitionsInternal$1$$anonfun$apply$25.apply(RDD.scala:860) at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:49) at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:348) at org.apache.spark.rdd.RDD.iterator(RDD.scala:312) at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:49) at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:348) at org.apache.spark.rdd.RDD.iterator(RDD.scala:312) at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:87) at org.apache.spark.scheduler.Task.run(Task.scala:110) at org.apache.spark.executor.Executor$TaskRunner$$anonfun$4.apply(Executor.scala:345) at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1424) at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:351) at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149) at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) at java.lang.Thread.run(Thread.java:748) Driver stacktrace: at org.apache.spark.scheduler.DAGScheduler.org$apache$spark$scheduler$DAGScheduler$$failJobAndIndependentStages(DAGScheduler.scala:1705) at org.apache.spark.scheduler.DAGScheduler$$anonfun$abortStage$1.apply(DAGScheduler.scala:1693) at org.apache.spark.scheduler.DAGScheduler$$anonfun$abortStage$1.apply(DAGScheduler.scala:1692) at scala.collection.mutable.ResizableArray$class.foreach(ResizableArray.scala:59) at scala.collection.mutable.ArrayBuffer.foreach(ArrayBuffer.scala:48) at org.apache.spark.scheduler.DAGScheduler.abortStage(DAGScheduler.scala:1692) at org.apache.spark.scheduler.DAGScheduler$$anonfun$handleTaskSetFailed$1.apply(DAGScheduler.scala:874) at org.apache.spark.scheduler.DAGScheduler$$anonfun$handleTaskSetFailed$1.apply(DAGScheduler.scala:874) at scala.Option.foreach(Option.scala:257) at org.apache.spark.scheduler.DAGScheduler.handleTaskSetFailed(DAGScheduler.scala:874) at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.doOnReceive(DAGScheduler.scala:1926) at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.onReceive(DAGScheduler.scala:1875) at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.onReceive(DAGScheduler.scala:1864) at org.apache.spark.util.EventLoop$$anon$1.run(EventLoop.scala:48) at org.apache.spark.scheduler.DAGScheduler.runJob(DAGScheduler.scala:683) at org.apache.spark.SparkContext.runJob(SparkContext.scala:2047) at org.apache.spark.SparkContext.runJob(SparkContext.scala:2068) at org.apache.spark.SparkContext.runJob(SparkContext.scala:2087) at org.apache.spark.sql.execution.SparkPlan.executeTake(SparkPlan.scala:380) at org.apache.spark.sql.execution.CollectLimitExec.executeCollect(limit.scala:38) at org.apache.spark.sql.Dataset.org$apache$spark$sql$Dataset$$collectFromPlan(Dataset.scala:3275) at org.apache.spark.sql.Dataset$$anonfun$head$1.apply(Dataset.scala:2486) at org.apache.spark.sql.Dataset$$anonfun$head$1.apply(Dataset.scala:2486) at org.apache.spark.sql.Dataset$$anonfun$52.apply(Dataset.scala:3256) at org.apache.spark.sql.execution.SQLExecution$.withNewExecutionId(SQLExecution.scala:90) at org.apache.spark.sql.Dataset.withAction(Dataset.scala:3255) at org.apache.spark.sql.Dataset.head(Dataset.scala:2486) at org.apache.spark.sql.Dataset.take(Dataset.scala:2700) at org.apache.seatunnel.spark.console.sink.Console.output(Console.scala:47) at org.apache.seatunnel.spark.console.sink.Console.output(Console.scala:28) at org.apache.seatunnel.spark.SparkEnvironment.sinkProcess(SparkEnvironment.java:179) at org.apache.seatunnel.spark.batch.SparkBatchExecution.start(SparkBatchExecution.java:54) at org.apache.seatunnel.core.spark.command.SparkTaskExecuteCommand.execute(SparkTaskExecuteCommand.java:67) ... 12 more Caused by: java.sql.SQLException: Invalid column type: getLong not implemented for class oracle.jdbc.driver.T4CRowidAccessor at oracle.jdbc.driver.GeneratedAccessor.getLong(GeneratedAccessor.java:393) at oracle.jdbc.driver.GeneratedStatement.getLong(GeneratedStatement.java:208) at oracle.jdbc.driver.GeneratedScrollableResultSet.getLong(GeneratedScrollableResultSet.java:261) at org.apache.spark.sql.execution.datasources.jdbc.JdbcUtils$$anonfun$org$apache$spark$sql$execution$datasources$jdbc$JdbcUtils$$makeGetter$8.apply(JdbcUtils.scala:470) at org.apache.spark.sql.execution.datasources.jdbc.JdbcUtils$$anonfun$org$apache$spark$sql$execution$datasources$jdbc$JdbcUtils$$makeGetter$8.apply(JdbcUtils.scala:469) at org.apache.spark.sql.execution.datasources.jdbc.JdbcUtils$$anon$1.getNext(JdbcUtils.scala:391) at org.apache.spark.sql.execution.datasources.jdbc.JdbcUtils$$anon$1.getNext(JdbcUtils.scala:373) at org.apache.spark.util.NextIterator.hasNext(NextIterator.scala:73) at org.apache.spark.InterruptibleIterator.hasNext(InterruptibleIterator.scala:37) at org.apache.spark.util.CompletionIterator.hasNext(CompletionIterator.scala:31) at org.apache.spark.sql.catalyst.expressions.GeneratedClass$GeneratedIteratorForCodegenStage1.processNext(Unknown Source) at org.apache.spark.sql.execution.BufferedRowIterator.hasNext(BufferedRowIterator.java:43) at org.apache.spark.sql.execution.WholeStageCodegenExec$$anonfun$12$$anon$1.hasNext(WholeStageCodegenExec.scala:634) at scala.collection.Iterator$$anon$11.hasNext(Iterator.scala:408) at scala.collection.Iterator$$anon$11.hasNext(Iterator.scala:408) at org.apache.spark.sql.Dataset$$anonfun$toJSON$1$$anon$1.hasNext(Dataset.scala:3141) at scala.collection.Iterator$$anon$11.hasNext(Iterator.scala:408) at org.apache.spark.sql.catalyst.expressions.GeneratedClass$GeneratedIteratorForCodegenStage2.processNext(Unknown Source) at org.apache.spark.sql.execution.BufferedRowIterator.hasNext(BufferedRowIterator.java:43) at org.apache.spark.sql.execution.WholeStageCodegenExec$$anonfun$12$$anon$1.hasNext(WholeStageCodegenExec.scala:634) at org.apache.spark.sql.execution.SparkPlan$$anonfun$2.apply(SparkPlan.scala:270) at org.apache.spark.sql.execution.SparkPlan$$anonfun$2.apply(SparkPlan.scala:264) at org.apache.spark.rdd.RDD$$anonfun$mapPartitionsInternal$1$$anonfun$apply$25.apply(RDD.scala:860) at org.apache.spark.rdd.RDD$$anonfun$mapPartitionsInternal$1$$anonfun$apply$25.apply(RDD.scala:860) at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:49) at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:348) at org.apache.spark.rdd.RDD.iterator(RDD.scala:312) at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:49) at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:348) at org.apache.spark.rdd.RDD.iterator(RDD.scala:312) at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:87) at org.apache.spark.scheduler.Task.run(Task.scala:110) at org.apache.spark.executor.Executor$TaskRunner$$anonfun$4.apply(Executor.scala:345) at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1424) at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:351) at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149) at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) at java.lang.Thread.run(Thread.java:748) [INFO] 2023-02-16 02:38:30.944 +0000 - process has exited. execute ``` ### Flink or Spark Version spark2.3 ### Java or Scala Version jdk8 ### Screenshots _No response_ ### Are you willing to submit PR? - [X] Yes I am willing to submit a PR! ### Code of Conduct - [X] I agree to follow this project's [Code of Conduct](https://www.apache.org/foundation/policies/conduct) -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: [email protected] For queries about this service, please contact Infrastructure at: [email protected]
{kind=link}