This is an automated email from the ASF dual-hosted git repository.
gengliang pushed a commit to branch asf-site
in repository https://gitbox.apache.org/repos/asf/spark-website.git
The following commit(s) were added to refs/heads/asf-site by this push:
new 84c616d79 [SPARK-39219] Promote Structured Streaming over Spark
Streaming (DStream) (#389)
84c616d79 is described below
commit 84c616d79bc205cd8029666b3013d4ade5986919
Author: Jungtaek Lim <kabhwan.opensou...@gmail.com>
AuthorDate: Thu May 19 10:53:36 2022 +0900
[SPARK-39219] Promote Structured Streaming over Spark Streaming (DStream)
(#389)
This PR proposes to promote Structured Streaming over Spark Streaming, as
we see efforts of community are more focused on Structured Streaming (based on
Spark SQL) than Spark Streaming (DStream). We would like to encourage end users
to use Structured Streaming than Spark Streaming whenever possible for their
workloads.
Here are screenshots of pages this PR changes.

---
faq.md | 8 +-
...-structured-streaming-incremental-execution.png | Bin 0 -> 44119 bytes
images/spark-unified-batch-and-streaming.png | Bin 0 -> 24232 bytes
site/faq.html | 8 +-
...-structured-streaming-incremental-execution.png | Bin 0 -> 44119 bytes
site/images/spark-unified-batch-and-streaming.png | Bin 0 -> 24232 bytes
site/streaming/index.html | 101 +++++++--------------
streaming/index.md | 101 +++++++--------------
8 files changed, 72 insertions(+), 146 deletions(-)
diff --git a/faq.md b/faq.md
index 223a53ea7..963e1cd98 100644
--- a/faq.md
+++ b/faq.md
@@ -36,11 +36,11 @@ Spark is a fast and general processing engine compatible
with Hadoop data. It ca
<p class="question">Does Spark require modified versions of Scala or
Python?</p>
<p class="answer">No. Spark requires no changes to Scala or compiler plugins.
The Python API uses the standard CPython implementation, and can call into
existing C libraries for Python such as NumPy.</p>
-<p class="question">I understand Spark Streaming uses micro-batching. Does
this increase latency?</p>
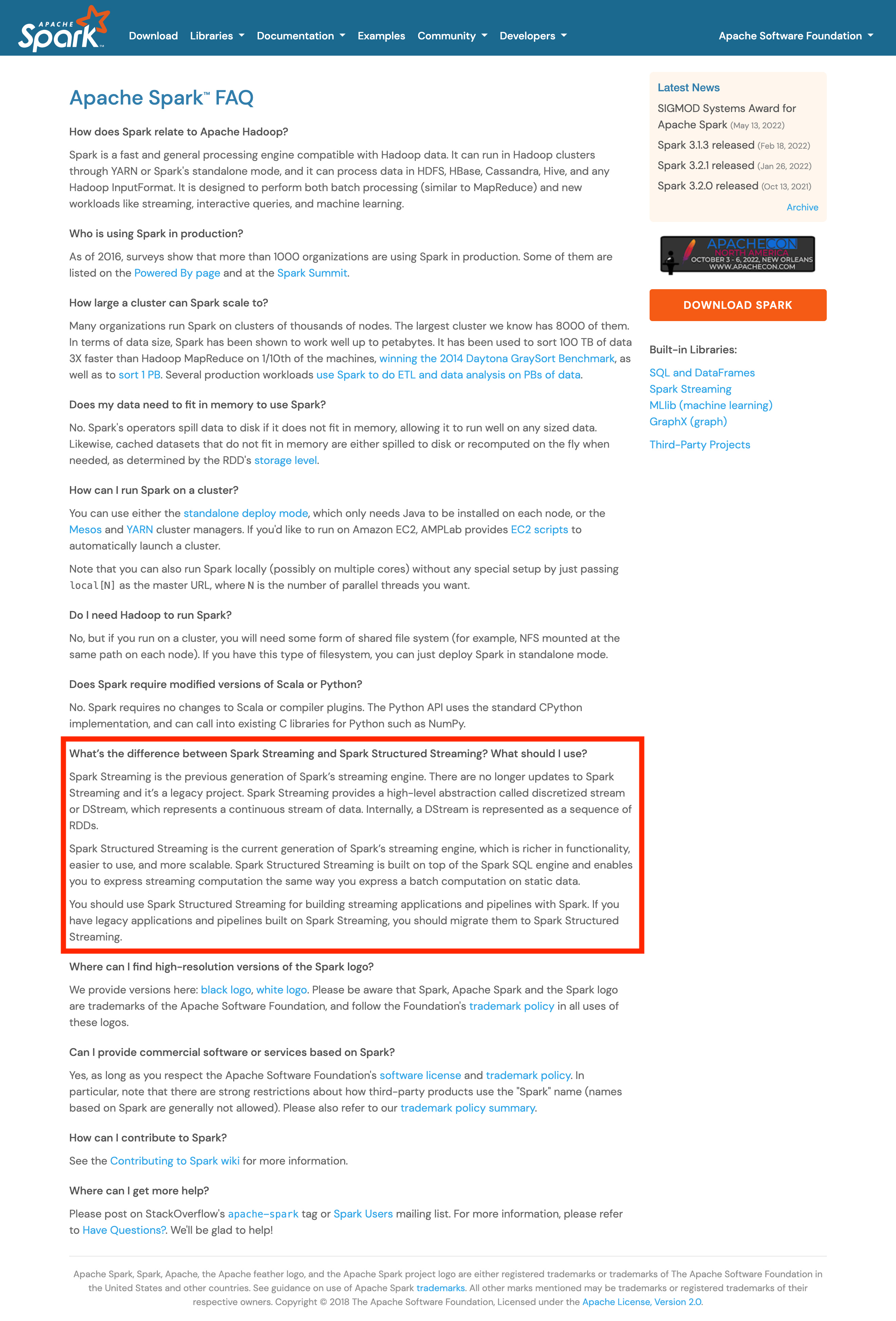
+<p class="question">What’s the difference between Spark Streaming and Spark
Structured Streaming? What should I use?</p>
+<p class="answer">Spark Streaming is the previous generation of Spark’s
streaming engine. There are no longer updates to Spark Streaming and it’s a
legacy project. Spark Streaming provides a high-level abstraction called
discretized stream or DStream, which represents a continuous stream of data.
Internally, a DStream is represented as a sequence of RDDs.</p>
+<p>Spark Structured Streaming is the current generation of Spark’s streaming
engine, which is richer in functionality, easier to use, and more scalable.
Spark Structured Streaming is built on top of the Spark SQL engine and enables
you to express streaming computation the same way you express a batch
computation on static data.</p>
-<p class="answer">
-While Spark does use a micro-batch execution model, this does not have much
impact on applications, because the batches can be as short as 0.5 seconds. In
most applications of streaming big data, the analytics is done over a larger
window (say 10 minutes), or the latency to get data in is higher (e.g. sensors
collect readings every 10 seconds). Spark's model enables <a
href="http://people.csail.mit.edu/matei/papers/2013/sosp_spark_streaming.pdf";>exactly-once
semantics and consistency</a> [...]
-</p>
+<p>You should use Spark Structured Streaming for building streaming
applications and pipelines with Spark. If you have legacy applications and
pipelines built on Spark Streaming, you should migrate them to Spark Structured
Streaming.</p>
<p class="question">Where can I find high-resolution versions of the Spark
logo?</p>
diff --git a/images/spark-structured-streaming-incremental-execution.png
b/images/spark-structured-streaming-incremental-execution.png
new file mode 100644
index 000000000..3de026a01
Binary files /dev/null and
b/images/spark-structured-streaming-incremental-execution.png differ
diff --git a/images/spark-unified-batch-and-streaming.png
b/images/spark-unified-batch-and-streaming.png
new file mode 100644
index 000000000..bf51d8a5a
Binary files /dev/null and b/images/spark-unified-batch-and-streaming.png differ
diff --git a/site/faq.html b/site/faq.html
index e829db9e1..a62f8206d 100644
--- a/site/faq.html
+++ b/site/faq.html
@@ -151,11 +151,11 @@ Spark is a fast and general processing engine compatible
with Hadoop data. It ca
<p class="question">Does Spark require modified versions of Scala or
Python?</p>
<p class="answer">No. Spark requires no changes to Scala or compiler plugins.
The Python API uses the standard CPython implementation, and can call into
existing C libraries for Python such as NumPy.</p>
-<p class="question">I understand Spark Streaming uses micro-batching. Does
this increase latency?</p>
+<p class="question">What’s the difference between Spark Streaming and Spark
Structured Streaming? What should I use?</p>
+<p class="answer">Spark Streaming is the previous generation of Spark’s
streaming engine. There are no longer updates to Spark Streaming and it’s a
legacy project. Spark Streaming provides a high-level abstraction called
discretized stream or DStream, which represents a continuous stream of data.
Internally, a DStream is represented as a sequence of RDDs.</p>
+<p>Spark Structured Streaming is the current generation of Spark’s streaming
engine, which is richer in functionality, easier to use, and more scalable.
Spark Structured Streaming is built on top of the Spark SQL engine and enables
you to express streaming computation the same way you express a batch
computation on static data.</p>
-<p class="answer">
-While Spark does use a micro-batch execution model, this does not have much
impact on applications, because the batches can be as short as 0.5 seconds. In
most applications of streaming big data, the analytics is done over a larger
window (say 10 minutes), or the latency to get data in is higher (e.g. sensors
collect readings every 10 seconds). Spark's model enables <a
href="http://people.csail.mit.edu/matei/papers/2013/sosp_spark_streaming.pdf";>exactly-once
semantics and consistency</a> [...]
-</p>
+<p>You should use Spark Structured Streaming for building streaming
applications and pipelines with Spark. If you have legacy applications and
pipelines built on Spark Streaming, you should migrate them to Spark Structured
Streaming.</p>
<p class="question">Where can I find high-resolution versions of the Spark
logo?</p>
diff --git a/site/images/spark-structured-streaming-incremental-execution.png
b/site/images/spark-structured-streaming-incremental-execution.png
new file mode 100644
index 000000000..3de026a01
Binary files /dev/null and
b/site/images/spark-structured-streaming-incremental-execution.png differ
diff --git a/site/images/spark-unified-batch-and-streaming.png
b/site/images/spark-unified-batch-and-streaming.png
new file mode 100644
index 000000000..bf51d8a5a
Binary files /dev/null and b/site/images/spark-unified-batch-and-streaming.png
differ
diff --git a/site/streaming/index.html b/site/streaming/index.html
index 7059058c4..2f0f9ad1c 100644
--- a/site/streaming/index.html
+++ b/site/streaming/index.html
@@ -6,14 +6,14 @@
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>
- Spark Streaming | Apache Spark
+ Spark Structured Streaming | Apache Spark
</title>
- <meta name="description" content="Spark Streaming makes it easy to build
scalable and fault-tolerant streaming applications.">
+ <meta name="description" content="Spark Structured Streaming makes it easy
to build streaming applications and pipelines with the same and familiar Spark
APIs.">
<link
href="https://cdn.jsdelivr.net/npm/bootstrap@5.0.2/dist/css/bootstrap.min.css";
rel="stylesheet"
@@ -125,135 +125,98 @@
<div class="row mt-4">
<div class="col-12 col-md-9">
<div class="jumbotron">
- <b>Spark streaming</b> makes it easy to build scalable fault-tolerant
streaming
- applications.
+ <a href="/docs/latest/structured-streaming-programming-guide.html">Spark
Structured Streaming</a> makes it easy to build streaming applications and
pipelines with the same and familiar Spark APIs.
</div>
<div class="row row-padded">
<div class="col-md-7 col-sm-7">
- <h2>Ease of use</h2>
- <p class="lead">
- Build applications through high-level operators.
- </p>
+ <h2>Ease to use</h2>
<p>
- Spark Streaming brings Apache Spark's
- <a
href="/docs/latest/streaming-programming-guide.html">language-integrated API</a>
- to stream processing, letting you write streaming jobs the same way you
write batch jobs.
- It supports Java, Scala and Python.
+ Spark Structured Streaming abstracts away complex streaming concepts
such as incremental processing, checkpointing, and watermarks
+ so that you can build streaming applications and pipelines without
learning any new concepts or tools.
</p>
</div>
<div class="col-md-5 col-sm-5 col-padded-top col-center">
<div style="margin-top: 15px; text-align: left; display: inline-block;">
<div class="code">
- TwitterUtils.createStream(...)<br />
- .<span class="sparkop">filter</span>(<span
class="closure">_.getText.contains("Spark")</span>)<br />
- .<span
class="sparkop">countByWindow</span>(Seconds(5))
+ spark<br />
+ .<span class="sparkop">readStream</span><br />
+ .<span class="sparkop">select</span>(<span
class="closure">$"value"</span>.cast(<span
class="closure">"string"</span>).alias(<span
class="closure">"jsonData"</span>))<br />
+ .<span class="sparkop">select</span>(from_json(<span
class="closure">$"jsonData"</span>,jsonSchema).alias(<span
class="closure">"payload"</span>))<br />
+ .<span class="sparkop">writeStream</span><br />
+ .<span class="sparkop">trigger</span>(<span
class="closure">"1 seconds"</span>)<br />
+ .<span class="sparkop">start</span>()
</div>
- <div class="caption">Counting tweets on a sliding window</div>
</div>
</div>
</div>
<div class="row row-padded">
<div class="col-md-7 col-sm-7">
- <h2>Fault tolerance</h2>
- <p class="lead">
- Stateful exactly-once semantics out of the box.
- </p>
+ <h2>Unified batch and streaming APIs</h2>
<p>
- Spark Streaming recovers both lost work
- and operator state (e.g. sliding windows) out of the box, without any
extra code on your part.
+ Spark Structured Streaming provides the same structured APIs (DataFrames
and Datasets) as Spark so that you don’t need to develop on or maintain two
different technology stacks for batch and streaming.
+ In addition, unified APIs make it easy to migrate your existing batch
Spark jobs to streaming jobs.
</p>
</div>
<div class="col-md-5 col-sm-5 col-padded-top col-center">
<div style="width: 100%; max-width: 300px; display: inline-block;">
- <img src="/images/spark-streaming-recovery.png" style="width: 100%;
max-width: 300px;" />
+ <img src="/images/spark-unified-batch-and-streaming.png" style="width:
100%; max-width: 300px;" />
</div>
</div>
</div>
<div class="row row-padded">
<div class="col-md-7 col-sm-7">
- <h2>Spark integration</h2>
- <p class="lead">
- Combine streaming with batch and interactive queries.
- </p>
+ <h2>Low latency and cost effective</h2>
<p>
- By running on Spark, Spark Streaming lets you reuse the same code for
batch
- processing, join streams against historical data, or run ad-hoc
- queries on stream state.
- Build powerful interactive applications, not just analytics.
+ Spark Structured Streaming uses the same underlying architecture as
Spark so that you can take advantage of all the performance and cost
optimizations built into the Spark engine.
+ With Spark Structured Streaming, you can build low latency streaming
applications and pipelines cost effectively.
</p>
</div>
<div class="col-md-5 col-sm-5 col-padded-top col-center">
- <div style="margin-top: 20px; text-align: left; display: inline-block;">
- <div class="code">
- stream.<span class="sparkop">join</span>(historicCounts).<span
class="sparkop">filter</span> {<span class="closure"><br />
- case (word, (curCount, oldCount)) =><br />
- curCount > oldCount<br />
- </span>}
- </div>
- <div class="caption">Find words with higher frequency than historic
data</div>
+ <div style="width: 100%; max-width: 300px; display: inline-block;">
+ <img src="/images/spark-structured-streaming-incremental-execution.png"
style="width: 100%; max-width: 300px;" />
</div>
</div>
</div>
<div class="row">
+
<div class="col-md-4 col-padded">
- <h3>Deployment options</h3>
- <p>
- Spark Streaming can read data from
- <a
href="https://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-hdfs/HdfsUserGuide.html";>HDFS</a>,
- <a href="https://flume.apache.org";>Flume</a>,
- <a href="https://kafka.apache.org";>Kafka</a>,
- <a href="https://dev.twitter.com";>Twitter</a> and
- <a href="http://zeromq.org";>ZeroMQ</a>.
- You can also define your own custom data sources.
- </p>
+ <h3>Getting started</h3>
<p>
- You can run Spark Streaming on Spark's <a
href="/docs/latest/spark-standalone.html">standalone cluster mode</a>
- or other supported cluster resource managers.
- It also includes a local run mode for development.
- In production,
- Spark Streaming uses <a
href="https://zookeeper.apache.org";>ZooKeeper</a> and <a
href="https://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-hdfs/HdfsUserGuide.html";>HDFS</a>
for high availability.
+ To get started with Spark Structured Streaming:
</p>
+ <ul class="list-narrow">
+ <li><a href="/downloads.html">Download Spark</a>. It includes Structured
Streaming as a module.</li>
+ <li>Read the <a
href="/docs/latest/structured-streaming-programming-guide.html">Spark
Structured Streaming programming guide</a>, which includes programming models,
tutorials, configurations, etc.</li>
+ </ul>
</div>
<div class="col-md-4 col-padded">
<h3>Community</h3>
<p>
- Spark Streaming is developed as part of Apache Spark. It thus gets
- tested and updated with each Spark release.
+ Spark Structured Streaming is developed as part of Apache Spark. It thus
gets tested and updated with each Spark release.
</p>
<p>
If you have questions about the system, ask on the
<a href="/community.html#mailing-lists">Spark mailing lists</a>.
</p>
<p>
- The Spark Streaming developers welcome contributions. If you'd like to
help out,
+ The Spark Structured Streaming developers welcome contributions. If
you'd like to help out,
read <a href="/contributing.html">how to
contribute to Spark</a>, and send us a patch!
</p>
</div>
- <div class="col-md-4 col-padded">
- <h3>Getting started</h3>
- <p>
- To get started with Spark Streaming:
- </p>
- <ul class="list-narrow">
- <li><a href="/downloads.html">Download Spark</a>. It includes Streaming
as a module.</li>
- <li>Read the <a
href="/docs/latest/streaming-programming-guide.html">Spark Streaming
programming guide</a>, which includes a tutorial and describes system
architecture, configuration and high availability.</li>
- <li>Check out example programs in <a
href="https://github.com/apache/spark/tree/master/examples/src/main/scala/org/apache/spark/examples/streaming";>Scala</a>
and <a
href="https://github.com/apache/spark/tree/master/examples/src/main/java/org/apache/spark/examples/streaming";>Java</a>.</li>
- </ul>
- </div>
</div>
<div class="row">
<div class="col-sm-12 col-center">
<a href="/downloads.html" class="btn btn-cta btn-lg btn-multiline">
- Download Apache Spark<br /><span class="small">Includes Spark
Streaming</span>
+ Download Apache Spark<br /><span class="small">Includes Spark Structured
Streaming</span>
</a>
</div>
</div>
diff --git a/streaming/index.md b/streaming/index.md
index ae710c12d..9e1d63cf9 100644
--- a/streaming/index.md
+++ b/streaming/index.md
@@ -1,144 +1,107 @@
---
layout: global
type: "page singular"
-title: Spark Streaming
-description: Spark Streaming makes it easy to build scalable and
fault-tolerant streaming applications.
+title: Spark Structured Streaming
+description: Spark Structured Streaming makes it easy to build streaming
applications and pipelines with the same and familiar Spark APIs.
subproject: Streaming
---
<div class="jumbotron">
- <b>Spark streaming</b> makes it easy to build scalable fault-tolerant
streaming
- applications.
+ <a
href="{{site.baseurl}}/docs/latest/structured-streaming-programming-guide.html">Spark
Structured Streaming</a> makes it easy to build streaming applications and
pipelines with the same and familiar Spark APIs.
</div>
<div class="row row-padded">
<div class="col-md-7 col-sm-7">
- <h2>Ease of use</h2>
- <p class="lead">
- Build applications through high-level operators.
- </p>
+ <h2>Ease to use</h2>
<p>
- Spark Streaming brings Apache Spark's
- <a
href="{{site.baseurl}}/docs/latest/streaming-programming-guide.html">language-integrated
API</a>
- to stream processing, letting you write streaming jobs the same way you
write batch jobs.
- It supports Java, Scala and Python.
+ Spark Structured Streaming abstracts away complex streaming concepts
such as incremental processing, checkpointing, and watermarks
+ so that you can build streaming applications and pipelines without
learning any new concepts or tools.
</p>
</div>
<div class="col-md-5 col-sm-5 col-padded-top col-center">
<div style="margin-top: 15px; text-align: left; display: inline-block;">
<div class="code">
- TwitterUtils.createStream(...)<br/>
- .<span class="sparkop">filter</span>(<span
class="closure">_.getText.contains("Spark")</span>)<br/>
- .<span
class="sparkop">countByWindow</span>(Seconds(5))
+ spark<br/>
+ .<span class="sparkop">readStream</span><br/>
+ .<span class="sparkop">select</span>(<span
class="closure">$"value"</span>.cast(<span
class="closure">"string"</span>).alias(<span
class="closure">"jsonData"</span>))<br/>
+ .<span class="sparkop">select</span>(from_json(<span
class="closure">$"jsonData"</span>,jsonSchema).alias(<span
class="closure">"payload"</span>))<br/>
+ .<span class="sparkop">writeStream</span><br/>
+ .<span class="sparkop">trigger</span>(<span
class="closure">"1 seconds"</span>)<br/>
+ .<span class="sparkop">start</span>()
</div>
- <div class="caption">Counting tweets on a sliding window</div>
</div>
</div>
</div>
<div class="row row-padded">
<div class="col-md-7 col-sm-7">
- <h2>Fault tolerance</h2>
- <p class="lead">
- Stateful exactly-once semantics out of the box.
- </p>
+ <h2>Unified batch and streaming APIs</h2>
<p>
- Spark Streaming recovers both lost work
- and operator state (e.g. sliding windows) out of the box, without any
extra code on your part.
+ Spark Structured Streaming provides the same structured APIs (DataFrames
and Datasets) as Spark so that you don’t need to develop on or maintain two
different technology stacks for batch and streaming.
+ In addition, unified APIs make it easy to migrate your existing batch
Spark jobs to streaming jobs.
</p>
</div>
<div class="col-md-5 col-sm-5 col-padded-top col-center">
<div style="width: 100%; max-width: 300px; display: inline-block;">
- <img src="{{site.baseurl}}/images/spark-streaming-recovery.png"
style="width: 100%; max-width: 300px;">
+ <img src="{{site.baseurl}}/images/spark-unified-batch-and-streaming.png"
style="width: 100%; max-width: 300px;">
</div>
</div>
</div>
<div class="row row-padded">
<div class="col-md-7 col-sm-7">
- <h2>Spark integration</h2>
- <p class="lead">
- Combine streaming with batch and interactive queries.
- </p>
+ <h2>Low latency and cost effective</h2>
<p>
- By running on Spark, Spark Streaming lets you reuse the same code for
batch
- processing, join streams against historical data, or run ad-hoc
- queries on stream state.
- Build powerful interactive applications, not just analytics.
+ Spark Structured Streaming uses the same underlying architecture as
Spark so that you can take advantage of all the performance and cost
optimizations built into the Spark engine.
+ With Spark Structured Streaming, you can build low latency streaming
applications and pipelines cost effectively.
</p>
</div>
<div class="col-md-5 col-sm-5 col-padded-top col-center">
- <div style="margin-top: 20px; text-align: left; display: inline-block;">
- <div class="code">
- stream.<span class="sparkop">join</span>(historicCounts).<span
class="sparkop">filter</span> {<span class="closure"><br/>
- case (word, (curCount, oldCount)) =><br/>
- curCount > oldCount<br/>
- </span>}
- </div>
- <div class="caption">Find words with higher frequency than historic
data</div>
+ <div style="width: 100%; max-width: 300px; display: inline-block;">
+ <img
src="{{site.baseurl}}/images/spark-structured-streaming-incremental-execution.png"
style="width: 100%; max-width: 300px;">
</div>
</div>
</div>
<div class="row">
+
<div class="col-md-4 col-padded">
- <h3>Deployment options</h3>
- <p>
- Spark Streaming can read data from
- <a
href="https://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-hdfs/HdfsUserGuide.html";>HDFS</a>,
- <a href="https://flume.apache.org";>Flume</a>,
- <a href="https://kafka.apache.org";>Kafka</a>,
- <a href="https://dev.twitter.com";>Twitter</a> and
- <a href="http://zeromq.org";>ZeroMQ</a>.
- You can also define your own custom data sources.
- </p>
+ <h3>Getting started</h3>
<p>
- You can run Spark Streaming on Spark's <a
href="{{site.baseurl}}/docs/latest/spark-standalone.html">standalone cluster
mode</a>
- or other supported cluster resource managers.
- It also includes a local run mode for development.
- In production,
- Spark Streaming uses <a
href="https://zookeeper.apache.org";>ZooKeeper</a> and <a
href="https://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-hdfs/HdfsUserGuide.html";>HDFS</a>
for high availability.
+ To get started with Spark Structured Streaming:
</p>
+ <ul class="list-narrow">
+ <li><a href="{{site.baseurl}}/downloads.html">Download Spark</a>. It
includes Structured Streaming as a module.</li>
+ <li>Read the <a
href="{{site.baseurl}}/docs/latest/structured-streaming-programming-guide.html">Spark
Structured Streaming programming guide</a>, which includes programming models,
tutorials, configurations, etc.</li>
+ </ul>
</div>
<div class="col-md-4 col-padded">
<h3>Community</h3>
<p>
- Spark Streaming is developed as part of Apache Spark. It thus gets
- tested and updated with each Spark release.
+ Spark Structured Streaming is developed as part of Apache Spark. It thus
gets tested and updated with each Spark release.
</p>
<p>
If you have questions about the system, ask on the
<a href="{{site.baseurl}}/community.html#mailing-lists">Spark mailing
lists</a>.
</p>
<p>
- The Spark Streaming developers welcome contributions. If you'd like to
help out,
+ The Spark Structured Streaming developers welcome contributions. If
you'd like to help out,
read <a href="{{site.baseurl}}/contributing.html">how to
contribute to Spark</a>, and send us a patch!
</p>
</div>
- <div class="col-md-4 col-padded">
- <h3>Getting started</h3>
- <p>
- To get started with Spark Streaming:
- </p>
- <ul class="list-narrow">
- <li><a href="{{site.baseurl}}/downloads.html">Download Spark</a>. It
includes Streaming as a module.</li>
- <li>Read the <a
href="{{site.baseurl}}/docs/latest/streaming-programming-guide.html">Spark
Streaming programming guide</a>, which includes a tutorial and describes system
architecture, configuration and high availability.</li>
- <li>Check out example programs in <a
href="https://github.com/apache/spark/tree/master/examples/src/main/scala/org/apache/spark/examples/streaming";>Scala</a>
and <a
href="https://github.com/apache/spark/tree/master/examples/src/main/java/org/apache/spark/examples/streaming";>Java</a>.</li>
- </ul>
- </div>
</div>
<div class="row">
<div class="col-sm-12 col-center">
<a href="{{site.baseurl}}/downloads.html" class="btn btn-cta btn-lg
btn-multiline">
- Download Apache Spark<br/><span class="small">Includes Spark
Streaming</span>
+ Download Apache Spark<br/><span class="small">Includes Spark Structured
Streaming</span>
</a>
</div>
</div>
---------------------------------------------------------------------
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: commits-h...@spark.apache.org
{kind=link}
{kind=link}