yongfeng-nv commented on a change in pull request #4885: Split node min range
is not stringent.
URL: https://github.com/apache/incubator-tvm/pull/4885#discussion_r379877270
##########
File path: tests/python/unittest/test_schedule_tensor_core.py
##########
@@ -339,17 +339,13 @@ def test_tensor_core_batch_conv():
ty, yo = s[AS].split(xo, nparts=block_col_warps)
t = s[AS].fuse(nn, ii)
to, ti = s[AS].split(t, factor=warp_size)
- s[AS].bind(tx, thread_y)
Review comment:
Sure. Before the test change, thread_y are bound to stage Conv's 3rd
IterVar, n.outer.inner ranging in [0, 0], and W.shared's 3rd, ax3.outer ranging
in [0, 1], as shown blow. These two stages are in one kernel.
Without my change, although its parent's ext is only 1, n.outer.inner is set
to [min=0, ext=2], because the split factor is 2. n.outer.inner and
ax3.outer's are allowed to bind to the same thread, as their ranges match.
With my change, n.outer.inner's range is set to [min=0, ext=1]. Ranges are
different and both IterVars can't bind to the same thread. I got this error:
```
[bt] (0)
/local2/data/tvm/gitlab/tvm-source-yongfeng/build/libtvm.so(dmlc::LogMessageFatal::~LogMessageFatal()+0x4d)
[0x7fd190b9c9b9]
File
"/local2/data/tvm/gitlab/tvm-source-yongfeng/src/te/schedule/message_passing.cc",
line 46
TVMError: Check failed: match: iter_var(threadIdx.y, , threadIdx.y) domain
already inferred, cannot prove their extents are the same 1 vs 2
```
Similar problems happen to other IterVars binding to threadIdx.y and
threadIdx.z.
Stop binding Apad.shared and W.shared's IterVars to threadIdx.y and
threadIdx.z avoids such problem. The generated code are different. I attach
them at the end. Let me show some diff first. Old code is on the left, new on
the right. Here are the first two sets of diff:
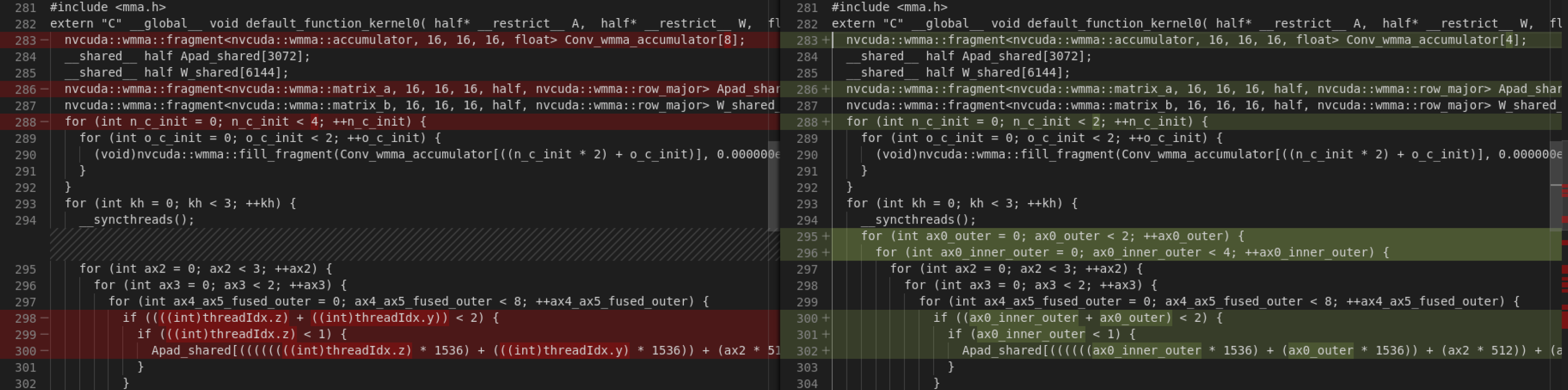
The fill fragment part benefits from this PR. However, since I removed
thread binding for Apad.shared and W.shared, the second diff show some
regression -- more memory copying.
These are the last sets of diff:
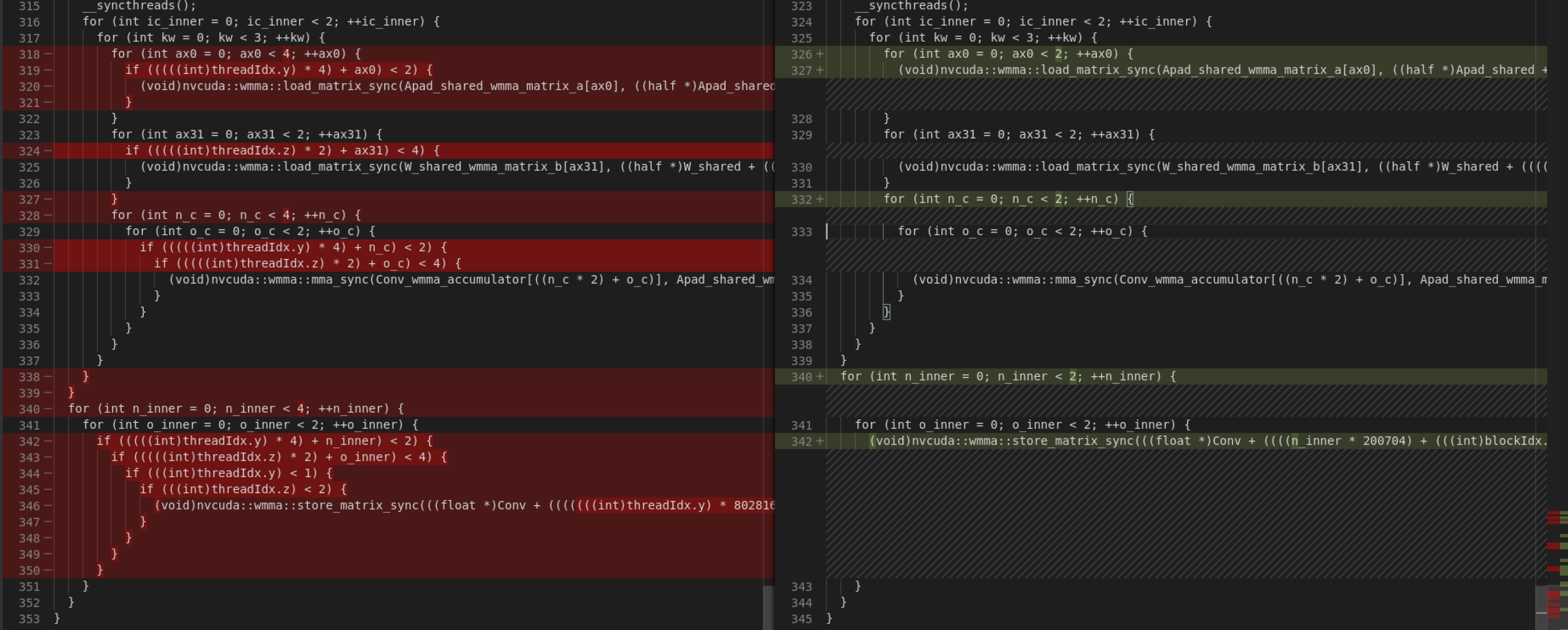
The new code look more concise than the old one in all these cases.
Overall, the test shows running time reduces from 0.060 ms to 0.035 ms. I
haven't done other performance checking.
This PR makes auto bound inference more accurate/reasonable. However, this
old test seems using split to force n.outer.inner's range to be larger than
necessary. This PR changes this behavior of split, making it less expressive.
Is this behavior a semantics by design?
A more general use case for threads binding: we would like to have a kernel
with multiple stages to use same threads differently in each stage. For
example, some stages need more threads than others. We don't mind allocating
enough threads to satisfy the most demanding stage. But we also want to avoid
unnecessary traversal (e.g. the likely statements) or memory allocation (e.g.
Conv_wmma_accumulator shown above) due to the extra range. Is there a good way
to achieve both?
Attach the entire generated CUDA code blow.
Before:
```
#if defined(__CUDA_ARCH__) && (__CUDA_ARCH__ >= 530)
#include <cuda_fp16.h>
__device__ half max(half a, half b)
{
return __hgt(__half(a), __half(b)) ? a : b;
}
__device__ half min(half a, half b)
{
return __hlt(__half(a), __half(b)) ? a : b;
}
#else
typedef unsigned short uint16_t;
typedef unsigned char uint8_t;
typedef signed char int8_t;
typedef int int32_t;
typedef unsigned long long uint64_t;
typedef unsigned int uint32_t;
#define TVM_FORCE_INLINE inline __attribute__((always_inline))
#define TVM_XINLINE TVM_FORCE_INLINE __device__ __host__
#define TVM_ALIGNED(x) __attribute__ ((aligned(x)))
#define TVM_HALF_OPERATOR(RTYPE, OP) \
TVM_XINLINE RTYPE operator OP (half a, half b) { \
return RTYPE(float(a) OP float(b)); \
} \
template<typename T> \
TVM_XINLINE RTYPE operator OP (half a, T b) { \
return RTYPE(float(a) OP float(b)); \
} \
template<typename T> \
TVM_XINLINE RTYPE operator OP (T a, half b) { \
return RTYPE(float(a) OP float(b)); \
}
#define TVM_HALF_ASSIGNOP(AOP, OP) \
template<typename T> \
TVM_XINLINE half operator AOP (const T& a) { \
return *this = half(float(*this) OP float(a)); \
} \
template<typename T> \
TVM_XINLINE half operator AOP (const volatile T& a) volatile { \
return *this = half(float(*this) OP float(a)); \
}
class TVM_ALIGNED(2) half {
public:
uint16_t half_;
static TVM_XINLINE half Binary(uint16_t value) {
half res;
res.half_ = value;
return res;
}
TVM_XINLINE half() {}
TVM_XINLINE half(const float& value) { constructor(value); }
TVM_XINLINE explicit half(const double& value) { constructor(value); }
TVM_XINLINE explicit half(const int8_t& value) { constructor(value); }
TVM_XINLINE explicit half(const uint8_t& value) { constructor(value); }
TVM_XINLINE explicit half(const int32_t& value) { constructor(value); }
TVM_XINLINE explicit half(const uint32_t& value) { constructor(value); }
TVM_XINLINE explicit half(const long long& value) { constructor(value); }
TVM_XINLINE explicit half(const uint64_t& value) { constructor(value); }
TVM_XINLINE operator float() const { \
return float(half2float(half_)); \
} \
TVM_XINLINE operator float() const volatile { \
return float(half2float(half_)); \
}
TVM_HALF_ASSIGNOP(+=, +)
TVM_HALF_ASSIGNOP(-=, -)
TVM_HALF_ASSIGNOP(*=, *)
TVM_HALF_ASSIGNOP(/=, /)
TVM_XINLINE half operator+() {
return *this;
}
TVM_XINLINE half operator-() {
return half(-float(*this));
}
TVM_XINLINE half operator=(const half& a) {
half_ = a.half_;
return a;
}
template<typename T>
TVM_XINLINE half operator=(const T& a) {
return *this = half(a);
}
TVM_XINLINE half operator=(const half& a) volatile {
half_ = a.half_;
return a;
}
template<typename T>
TVM_XINLINE half operator=(const T& a) volatile {
return *this = half(a);
}
private:
union Bits {
float f;
int32_t si;
uint32_t ui;
};
static int const fp16FractionBits = 10;
static int const fp32FractionBits = 23;
static int32_t const fp32FractionMask = ~(~0u << fp32FractionBits); //
== 0x7fffff
static int32_t const fp32HiddenBit = 1 << fp32FractionBits; // ==
0x800000
static int const shift = fp32FractionBits - fp16FractionBits; // == 13
static int const shiftSign = 16;
static int32_t const expAdjust = 127 - 15; // exp32-127 = exp16-15, so
exp16 = exp32 - (127-15)
static int32_t const infN = 0x7F800000; // flt32 infinity
static int32_t const maxN = 0x477FFFFF; // max flt32 that's a flt16
normal after >> by shift
static int32_t const minN = 0x38800000; // min flt16 normal as a flt32
static int32_t const maxZ = 0x33000000; // max fp32 number that's still
rounded to zero in fp16
static int32_t const signN = 0x80000000; // flt32 sign bit
static int32_t const infC = infN >> shift;
static int32_t const nanN = (infC + 1) << shift; // minimum flt16 nan as
a flt32
static int32_t const maxC = maxN >> shift;
static int32_t const minC = minN >> shift;
static int32_t const signC = signN >> shiftSign; // flt16 sign bit
static int32_t const mulN = 0x52000000; // (1 << 23) / minN
static int32_t const mulC = 0x33800000; // minN / (1 << (23 - shift))
static int32_t const subC = 0x003FF; // max flt32 subnormal down shifted
static int32_t const norC = 0x00400; // min flt32 normal down shifted
static int32_t const maxD = infC - maxC - 1;
static int32_t const minD = minC - subC - 1;
TVM_XINLINE uint16_t float2half(const float& value) const {
Bits v;
v.f = value;
uint32_t sign = v.si & signN; // grab sign bit
v.si ^= sign; // clear sign bit from v
sign >>= shiftSign; // logical shift sign to fp16 position
if (v.si <= maxZ) {
// Handle eventual zeros here to ensure
// vshift will not exceed 32 below.
v.ui = 0;
} else if (v.si < minN) {
// Handle denorms
uint32_t exp32 = v.ui >> fp32FractionBits;
int32_t exp16 = exp32 - expAdjust;
// If exp16 == 0 (just into the denorm range), then significant should
be shifted right 1.
// Smaller (so negative) exp16 values should result in greater right
shifts.
uint32_t vshift = 1 - exp16;
uint32_t significand = fp32HiddenBit | (v.ui & fp32FractionMask);
v.ui = significand >> vshift;
v.ui += (v.ui & 0x3fff) != 0x1000 || (significand & 0x7ff) ? 0x1000 :
0;
} else if (v.si <= maxN) {
// Handle norms
v.ui += (v.ui & 0x3fff) != 0x1000 ? 0x1000 : 0;
v.ui -= expAdjust << fp32FractionBits;
} else if (v.si <= infN) {
v.si = infN;
} else if (v.si < nanN) {
v.si = nanN;
}
v.ui >>= shift;
return sign | (v.ui & 0x7fff);
}
// Same as above routine, except for addition of volatile keyword
TVM_XINLINE uint16_t float2half(
const volatile float& value) const volatile {
Bits v;
v.f = value;
uint32_t sign = v.si & signN; // grab sign bit
v.si ^= sign; // clear sign bit from v
sign >>= shiftSign; // logical shift sign to fp16 position
if (v.si <= maxZ) {
// Handle eventual zeros here to ensure
// vshift will not exceed 32 below.
v.ui = 0;
} else if (v.si < minN) {
// Handle denorms
uint32_t exp32 = v.ui >> fp32FractionBits;
int32_t exp16 = exp32 - expAdjust;
// If exp16 == 0 (just into the denorm range), then significant should
be shifted right 1.
// Smaller (so negative) exp16 values should result in greater right
shifts.
uint32_t vshift = 1 - exp16;
uint32_t significand = fp32HiddenBit | (v.ui & fp32FractionMask);
v.ui = significand >> vshift;
v.ui += (v.ui & 0x3fff) != 0x1000 || (significand & 0x7ff) ? 0x1000 :
0;
} else if (v.si <= maxN) {
// Handle norms
v.ui += (v.ui & 0x3fff) != 0x1000 ? 0x1000 : 0;
v.ui -= expAdjust << fp32FractionBits;
} else if (v.si <= infN) {
v.si = infN;
} else if (v.si < nanN) {
v.si = nanN;
}
v.ui >>= shift;
return sign | (v.ui & 0x7fff);
}
TVM_XINLINE float half2float(const uint16_t& value) const {
Bits v;
v.ui = value;
int32_t sign = v.si & signC;
v.si ^= sign;
sign <<= shiftSign;
v.si ^= ((v.si + minD) ^ v.si) & -(v.si > subC);
v.si ^= ((v.si + maxD) ^ v.si) & -(v.si > maxC);
Bits s;
s.si = mulC;
s.f *= v.si;
int32_t mask = -(norC > v.si);
v.si <<= shift;
v.si ^= (s.si ^ v.si) & mask;
v.si |= sign;
return v.f;
}
TVM_XINLINE float half2float(
const volatile uint16_t& value) const volatile {
Bits v;
v.ui = value;
int32_t sign = v.si & signC;
v.si ^= sign;
sign <<= shiftSign;
v.si ^= ((v.si + minD) ^ v.si) & -(v.si > subC);
v.si ^= ((v.si + maxD) ^ v.si) & -(v.si > maxC);
Bits s;
s.si = mulC;
s.f *= v.si;
int32_t mask = -(norC > v.si);
v.si <<= shift;
v.si ^= (s.si ^ v.si) & mask;
v.si |= sign;
return v.f;
}
template<typename T>
TVM_XINLINE void constructor(const T& value) {
half_ = float2half(float(value));
}
};
TVM_HALF_OPERATOR(half, +)
TVM_HALF_OPERATOR(half, -)
TVM_HALF_OPERATOR(half, *)
TVM_HALF_OPERATOR(half, /)
TVM_HALF_OPERATOR(bool, >)
TVM_HALF_OPERATOR(bool, <)
TVM_HALF_OPERATOR(bool, >=)
TVM_HALF_OPERATOR(bool, <=)
TVM_XINLINE half __float2half_rn(const float a) {
return half(a);
}
#endif
// Pack two half values.
static inline __device__ __host__ unsigned
__pack_half2(const half x, const half y) {
unsigned v0 = *((unsigned short *)&x);
unsigned v1 = *((unsigned short *)&y);
return (v0 << 16) | v1;
}
#include <mma.h>
extern "C" __global__ void default_function_kernel0( half* __restrict__ A,
half* __restrict__ W, float* __restrict__ Conv) {
nvcuda::wmma::fragment<nvcuda::wmma::accumulator, 16, 16, 16, float>
Conv_wmma_accumulator[8];
__shared__ half Apad_shared[3072];
__shared__ half W_shared[6144];
nvcuda::wmma::fragment<nvcuda::wmma::matrix_a, 16, 16, 16, half,
nvcuda::wmma::row_major> Apad_shared_wmma_matrix_a[4];
nvcuda::wmma::fragment<nvcuda::wmma::matrix_b, 16, 16, 16, half,
nvcuda::wmma::row_major> W_shared_wmma_matrix_b[2];
for (int n_c_init = 0; n_c_init < 4; ++n_c_init) {
for (int o_c_init = 0; o_c_init < 2; ++o_c_init) {
(void)nvcuda::wmma::fill_fragment(Conv_wmma_accumulator[((n_c_init *
2) + o_c_init)], 0.000000e+00f);
}
}
for (int kh = 0; kh < 3; ++kh) {
__syncthreads();
for (int ax2 = 0; ax2 < 3; ++ax2) {
for (int ax3 = 0; ax3 < 2; ++ax3) {
for (int ax4_ax5_fused_outer = 0; ax4_ax5_fused_outer < 8;
++ax4_ax5_fused_outer) {
if ((((int)threadIdx.z) + ((int)threadIdx.y)) < 2) {
if (((int)threadIdx.z) < 1) {
Apad_shared[((((((((int)threadIdx.z) * 1536) +
(((int)threadIdx.y) * 1536)) + (ax2 * 512)) + (ax3 * 256)) +
(ax4_ax5_fused_outer * 32)) + ((int)threadIdx.x))] = (((((1 <=
((((int)blockIdx.z) / 14) + kh)) && (((((int)blockIdx.z) / 14) + kh) < 15)) &&
(1 <= (ax2 + (((int)blockIdx.z) % 14)))) && ((ax2 + (((int)blockIdx.z) % 14)) <
15)) ? A[(((((((((((int)threadIdx.z) * 100352) + (((int)threadIdx.y) * 100352))
+ (kh * 7168)) + (((int)blockIdx.z) * 512)) + (ax2 * 512)) + (ax3 * 256)) +
(ax4_ax5_fused_outer * 32)) + ((int)threadIdx.x)) - 7680)] :
__float2half_rn(0.000000e+00f));
}
}
}
}
}
for (int ax1 = 0; ax1 < 3; ++ax1) {
for (int ax21 = 0; ax21 < 2; ++ax21) {
if (((((int)threadIdx.y) * 2) + ((int)threadIdx.z)) < 4) {
if (((int)threadIdx.z) < 2) {
((__shared__ uint4*)(W_shared + (((((ax1 * 2048) + (ax21 *
1024)) + (((int)threadIdx.y) * 512)) + (((int)threadIdx.z) * 256)) +
(((int)threadIdx.x) * 8))))[0] = (( uint4*)(W + ((((((kh * 6144) + (ax1 *
2048)) + (ax21 * 1024)) + (((int)threadIdx.y) * 512)) + (((int)threadIdx.z) *
256)) + (((int)threadIdx.x) * 8))))[0];
}
}
}
}
__syncthreads();
for (int ic_inner = 0; ic_inner < 2; ++ic_inner) {
for (int kw = 0; kw < 3; ++kw) {
for (int ax0 = 0; ax0 < 4; ++ax0) {
if (((((int)threadIdx.y) * 4) + ax0) < 2) {
(void)nvcuda::wmma::load_matrix_sync(Apad_shared_wmma_matrix_a[ax0], ((half
*)Apad_shared + ((((((int)threadIdx.y) * 6144) + (ax0 * 1536)) + (kw * 512)) +
(ic_inner * 256))), 16);
}
}
for (int ax31 = 0; ax31 < 2; ++ax31) {
if (((((int)threadIdx.z) * 2) + ax31) < 4) {
(void)nvcuda::wmma::load_matrix_sync(W_shared_wmma_matrix_b[ax31], ((half
*)W_shared + ((((kw * 2048) + (ic_inner * 1024)) + (((int)threadIdx.z) * 512))
+ (ax31 * 256))), 16);
}
}
for (int n_c = 0; n_c < 4; ++n_c) {
for (int o_c = 0; o_c < 2; ++o_c) {
if (((((int)threadIdx.y) * 4) + n_c) < 2) {
if (((((int)threadIdx.z) * 2) + o_c) < 4) {
(void)nvcuda::wmma::mma_sync(Conv_wmma_accumulator[((n_c *
2) + o_c)], Apad_shared_wmma_matrix_a[n_c], W_shared_wmma_matrix_b[o_c],
Conv_wmma_accumulator[((n_c * 2) + o_c)]);
}
}
}
}
}
}
}
for (int n_inner = 0; n_inner < 4; ++n_inner) {
for (int o_inner = 0; o_inner < 2; ++o_inner) {
if (((((int)threadIdx.y) * 4) + n_inner) < 2) {
if (((((int)threadIdx.z) * 2) + o_inner) < 4) {
if (((int)threadIdx.y) < 1) {
if (((int)threadIdx.z) < 2) {
(void)nvcuda::wmma::store_matrix_sync(((float *)Conv +
(((((((int)threadIdx.y) * 802816) + (n_inner * 200704)) + (((int)blockIdx.z) *
1024)) + (((int)threadIdx.z) * 512)) + (o_inner * 256))),
Conv_wmma_accumulator[((n_inner * 2) + o_inner)], 16,
nvcuda::wmma::mem_row_major);
}
}
}
}
}
}
}
```
After:
```
#if defined(__CUDA_ARCH__) && (__CUDA_ARCH__ >= 530)
#include <cuda_fp16.h>
__device__ half max(half a, half b)
{
return __hgt(__half(a), __half(b)) ? a : b;
}
__device__ half min(half a, half b)
{
return __hlt(__half(a), __half(b)) ? a : b;
}
#else
typedef unsigned short uint16_t;
typedef unsigned char uint8_t;
typedef signed char int8_t;
typedef int int32_t;
typedef unsigned long long uint64_t;
typedef unsigned int uint32_t;
#define TVM_FORCE_INLINE inline __attribute__((always_inline))
#define TVM_XINLINE TVM_FORCE_INLINE __device__ __host__
#define TVM_ALIGNED(x) __attribute__ ((aligned(x)))
#define TVM_HALF_OPERATOR(RTYPE, OP) \
TVM_XINLINE RTYPE operator OP (half a, half b) { \
return RTYPE(float(a) OP float(b)); \
} \
template<typename T> \
TVM_XINLINE RTYPE operator OP (half a, T b) { \
return RTYPE(float(a) OP float(b)); \
} \
template<typename T> \
TVM_XINLINE RTYPE operator OP (T a, half b) { \
return RTYPE(float(a) OP float(b)); \
}
#define TVM_HALF_ASSIGNOP(AOP, OP) \
template<typename T> \
TVM_XINLINE half operator AOP (const T& a) { \
return *this = half(float(*this) OP float(a)); \
} \
template<typename T> \
TVM_XINLINE half operator AOP (const volatile T& a) volatile { \
return *this = half(float(*this) OP float(a)); \
}
class TVM_ALIGNED(2) half {
public:
uint16_t half_;
static TVM_XINLINE half Binary(uint16_t value) {
half res;
res.half_ = value;
return res;
}
TVM_XINLINE half() {}
TVM_XINLINE half(const float& value) { constructor(value); }
TVM_XINLINE explicit half(const double& value) { constructor(value); }
TVM_XINLINE explicit half(const int8_t& value) { constructor(value); }
TVM_XINLINE explicit half(const uint8_t& value) { constructor(value); }
TVM_XINLINE explicit half(const int32_t& value) { constructor(value); }
TVM_XINLINE explicit half(const uint32_t& value) { constructor(value); }
TVM_XINLINE explicit half(const long long& value) { constructor(value); }
TVM_XINLINE explicit half(const uint64_t& value) { constructor(value); }
TVM_XINLINE operator float() const { \
return float(half2float(half_)); \
} \
TVM_XINLINE operator float() const volatile { \
return float(half2float(half_)); \
}
TVM_HALF_ASSIGNOP(+=, +)
TVM_HALF_ASSIGNOP(-=, -)
TVM_HALF_ASSIGNOP(*=, *)
TVM_HALF_ASSIGNOP(/=, /)
TVM_XINLINE half operator+() {
return *this;
}
TVM_XINLINE half operator-() {
return half(-float(*this));
}
TVM_XINLINE half operator=(const half& a) {
half_ = a.half_;
return a;
}
template<typename T>
TVM_XINLINE half operator=(const T& a) {
return *this = half(a);
}
TVM_XINLINE half operator=(const half& a) volatile {
half_ = a.half_;
return a;
}
template<typename T>
TVM_XINLINE half operator=(const T& a) volatile {
return *this = half(a);
}
private:
union Bits {
float f;
int32_t si;
uint32_t ui;
};
static int const fp16FractionBits = 10;
static int const fp32FractionBits = 23;
static int32_t const fp32FractionMask = ~(~0u << fp32FractionBits); //
== 0x7fffff
static int32_t const fp32HiddenBit = 1 << fp32FractionBits; // ==
0x800000
static int const shift = fp32FractionBits - fp16FractionBits; // == 13
static int const shiftSign = 16;
static int32_t const expAdjust = 127 - 15; // exp32-127 = exp16-15, so
exp16 = exp32 - (127-15)
static int32_t const infN = 0x7F800000; // flt32 infinity
static int32_t const maxN = 0x477FFFFF; // max flt32 that's a flt16
normal after >> by shift
static int32_t const minN = 0x38800000; // min flt16 normal as a flt32
static int32_t const maxZ = 0x33000000; // max fp32 number that's still
rounded to zero in fp16
static int32_t const signN = 0x80000000; // flt32 sign bit
static int32_t const infC = infN >> shift;
static int32_t const nanN = (infC + 1) << shift; // minimum flt16 nan as
a flt32
static int32_t const maxC = maxN >> shift;
static int32_t const minC = minN >> shift;
static int32_t const signC = signN >> shiftSign; // flt16 sign bit
static int32_t const mulN = 0x52000000; // (1 << 23) / minN
static int32_t const mulC = 0x33800000; // minN / (1 << (23 - shift))
static int32_t const subC = 0x003FF; // max flt32 subnormal down shifted
static int32_t const norC = 0x00400; // min flt32 normal down shifted
static int32_t const maxD = infC - maxC - 1;
static int32_t const minD = minC - subC - 1;
TVM_XINLINE uint16_t float2half(const float& value) const {
Bits v;
v.f = value;
uint32_t sign = v.si & signN; // grab sign bit
v.si ^= sign; // clear sign bit from v
sign >>= shiftSign; // logical shift sign to fp16 position
if (v.si <= maxZ) {
// Handle eventual zeros here to ensure
// vshift will not exceed 32 below.
v.ui = 0;
} else if (v.si < minN) {
// Handle denorms
uint32_t exp32 = v.ui >> fp32FractionBits;
int32_t exp16 = exp32 - expAdjust;
// If exp16 == 0 (just into the denorm range), then significant should
be shifted right 1.
// Smaller (so negative) exp16 values should result in greater right
shifts.
uint32_t vshift = 1 - exp16;
uint32_t significand = fp32HiddenBit | (v.ui & fp32FractionMask);
v.ui = significand >> vshift;
v.ui += (v.ui & 0x3fff) != 0x1000 || (significand & 0x7ff) ? 0x1000 :
0;
} else if (v.si <= maxN) {
// Handle norms
v.ui += (v.ui & 0x3fff) != 0x1000 ? 0x1000 : 0;
v.ui -= expAdjust << fp32FractionBits;
} else if (v.si <= infN) {
v.si = infN;
} else if (v.si < nanN) {
v.si = nanN;
}
v.ui >>= shift;
return sign | (v.ui & 0x7fff);
}
// Same as above routine, except for addition of volatile keyword
TVM_XINLINE uint16_t float2half(
const volatile float& value) const volatile {
Bits v;
v.f = value;
uint32_t sign = v.si & signN; // grab sign bit
v.si ^= sign; // clear sign bit from v
sign >>= shiftSign; // logical shift sign to fp16 position
if (v.si <= maxZ) {
// Handle eventual zeros here to ensure
// vshift will not exceed 32 below.
v.ui = 0;
} else if (v.si < minN) {
// Handle denorms
uint32_t exp32 = v.ui >> fp32FractionBits;
int32_t exp16 = exp32 - expAdjust;
// If exp16 == 0 (just into the denorm range), then significant should
be shifted right 1.
// Smaller (so negative) exp16 values should result in greater right
shifts.
uint32_t vshift = 1 - exp16;
uint32_t significand = fp32HiddenBit | (v.ui & fp32FractionMask);
v.ui = significand >> vshift;
v.ui += (v.ui & 0x3fff) != 0x1000 || (significand & 0x7ff) ? 0x1000 :
0;
} else if (v.si <= maxN) {
// Handle norms
v.ui += (v.ui & 0x3fff) != 0x1000 ? 0x1000 : 0;
v.ui -= expAdjust << fp32FractionBits;
} else if (v.si <= infN) {
v.si = infN;
} else if (v.si < nanN) {
v.si = nanN;
}
v.ui >>= shift;
return sign | (v.ui & 0x7fff);
}
TVM_XINLINE float half2float(const uint16_t& value) const {
Bits v;
v.ui = value;
int32_t sign = v.si & signC;
v.si ^= sign;
sign <<= shiftSign;
v.si ^= ((v.si + minD) ^ v.si) & -(v.si > subC);
v.si ^= ((v.si + maxD) ^ v.si) & -(v.si > maxC);
Bits s;
s.si = mulC;
s.f *= v.si;
int32_t mask = -(norC > v.si);
v.si <<= shift;
v.si ^= (s.si ^ v.si) & mask;
v.si |= sign;
return v.f;
}
TVM_XINLINE float half2float(
const volatile uint16_t& value) const volatile {
Bits v;
v.ui = value;
int32_t sign = v.si & signC;
v.si ^= sign;
sign <<= shiftSign;
v.si ^= ((v.si + minD) ^ v.si) & -(v.si > subC);
v.si ^= ((v.si + maxD) ^ v.si) & -(v.si > maxC);
Bits s;
s.si = mulC;
s.f *= v.si;
int32_t mask = -(norC > v.si);
v.si <<= shift;
v.si ^= (s.si ^ v.si) & mask;
v.si |= sign;
return v.f;
}
template<typename T>
TVM_XINLINE void constructor(const T& value) {
half_ = float2half(float(value));
}
};
TVM_HALF_OPERATOR(half, +)
TVM_HALF_OPERATOR(half, -)
TVM_HALF_OPERATOR(half, *)
TVM_HALF_OPERATOR(half, /)
TVM_HALF_OPERATOR(bool, >)
TVM_HALF_OPERATOR(bool, <)
TVM_HALF_OPERATOR(bool, >=)
TVM_HALF_OPERATOR(bool, <=)
TVM_XINLINE half __float2half_rn(const float a) {
return half(a);
}
#endif
// Pack two half values.
static inline __device__ __host__ unsigned
__pack_half2(const half x, const half y) {
unsigned v0 = *((unsigned short *)&x);
unsigned v1 = *((unsigned short *)&y);
return (v0 << 16) | v1;
}
#include <mma.h>
extern "C" __global__ void default_function_kernel0( half* __restrict__ A,
half* __restrict__ W, float* __restrict__ Conv) {
nvcuda::wmma::fragment<nvcuda::wmma::accumulator, 16, 16, 16, float>
Conv_wmma_accumulator[4];
__shared__ half Apad_shared[3072];
__shared__ half W_shared[6144];
nvcuda::wmma::fragment<nvcuda::wmma::matrix_a, 16, 16, 16, half,
nvcuda::wmma::row_major> Apad_shared_wmma_matrix_a[2];
nvcuda::wmma::fragment<nvcuda::wmma::matrix_b, 16, 16, 16, half,
nvcuda::wmma::row_major> W_shared_wmma_matrix_b[2];
for (int n_c_init = 0; n_c_init < 2; ++n_c_init) {
for (int o_c_init = 0; o_c_init < 2; ++o_c_init) {
(void)nvcuda::wmma::fill_fragment(Conv_wmma_accumulator[((n_c_init *
2) + o_c_init)], 0.000000e+00f);
}
}
for (int kh = 0; kh < 3; ++kh) {
__syncthreads();
for (int ax0_outer = 0; ax0_outer < 2; ++ax0_outer) {
for (int ax0_inner_outer = 0; ax0_inner_outer < 4; ++ax0_inner_outer) {
for (int ax2 = 0; ax2 < 3; ++ax2) {
for (int ax3 = 0; ax3 < 2; ++ax3) {
for (int ax4_ax5_fused_outer = 0; ax4_ax5_fused_outer < 8;
++ax4_ax5_fused_outer) {
if ((ax0_inner_outer + ax0_outer) < 2) {
if (ax0_inner_outer < 1) {
Apad_shared[((((((ax0_inner_outer * 1536) + (ax0_outer *
1536)) + (ax2 * 512)) + (ax3 * 256)) + (ax4_ax5_fused_outer * 32)) +
((int)threadIdx.x))] = (((((1 <= ((((int)blockIdx.z) / 14) + kh)) &&
(((((int)blockIdx.z) / 14) + kh) < 15)) && (1 <= (ax2 + (((int)blockIdx.z) %
14)))) && ((ax2 + (((int)blockIdx.z) % 14)) < 15)) ? A[(((((((((ax0_inner_outer
* 100352) + (ax0_outer * 100352)) + (kh * 7168)) + (((int)blockIdx.z) * 512)) +
(ax2 * 512)) + (ax3 * 256)) + (ax4_ax5_fused_outer * 32)) + ((int)threadIdx.x))
- 7680)] : __float2half_rn(0.000000e+00f));
}
}
}
}
}
}
}
for (int ax1 = 0; ax1 < 3; ++ax1) {
for (int ax21 = 0; ax21 < 2; ++ax21) {
for (int ax3_outer = 0; ax3_outer < 2; ++ax3_outer) {
for (int ax3_inner_outer = 0; ax3_inner_outer < 4;
++ax3_inner_outer) {
if (((ax3_outer * 2) + ax3_inner_outer) < 4) {
if (ax3_inner_outer < 2) {
((__shared__ uint4*)(W_shared + (((((ax1 * 2048) + (ax21 *
1024)) + (ax3_outer * 512)) + (ax3_inner_outer * 256)) + (((int)threadIdx.x) *
8))))[0] = (( uint4*)(W + ((((((kh * 6144) + (ax1 * 2048)) + (ax21 * 1024)) +
(ax3_outer * 512)) + (ax3_inner_outer * 256)) + (((int)threadIdx.x) * 8))))[0];
}
}
}
}
}
}
__syncthreads();
for (int ic_inner = 0; ic_inner < 2; ++ic_inner) {
for (int kw = 0; kw < 3; ++kw) {
for (int ax0 = 0; ax0 < 2; ++ax0) {
(void)nvcuda::wmma::load_matrix_sync(Apad_shared_wmma_matrix_a[ax0], ((half
*)Apad_shared + (((ax0 * 1536) + (kw * 512)) + (ic_inner * 256))), 16);
}
for (int ax31 = 0; ax31 < 2; ++ax31) {
(void)nvcuda::wmma::load_matrix_sync(W_shared_wmma_matrix_b[ax31],
((half *)W_shared + ((((kw * 2048) + (ic_inner * 1024)) + (((int)threadIdx.z) *
512)) + (ax31 * 256))), 16);
}
for (int n_c = 0; n_c < 2; ++n_c) {
for (int o_c = 0; o_c < 2; ++o_c) {
(void)nvcuda::wmma::mma_sync(Conv_wmma_accumulator[((n_c * 2) +
o_c)], Apad_shared_wmma_matrix_a[n_c], W_shared_wmma_matrix_b[o_c],
Conv_wmma_accumulator[((n_c * 2) + o_c)]);
}
}
}
}
}
for (int n_inner = 0; n_inner < 2; ++n_inner) {
for (int o_inner = 0; o_inner < 2; ++o_inner) {
(void)nvcuda::wmma::store_matrix_sync(((float *)Conv + ((((n_inner *
200704) + (((int)blockIdx.z) * 1024)) + (((int)threadIdx.z) * 512)) + (o_inner
* 256))), Conv_wmma_accumulator[((n_inner * 2) + o_inner)], 16,
nvcuda::wmma::mem_row_major);
}
}
}
```
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
{kind=link}
{kind=link}