This is an automated email from the ASF dual-hosted git repository.
junrushao pushed a commit to branch main
in repository https://gitbox.apache.org/repos/asf/tvm-ffi.git
The following commit(s) were added to refs/heads/main by this push:
new 0369a07 doc: Tensor and DLPack (#363)
0369a07 is described below
commit 0369a07158685dd260f00f81b5ccfa67c35634c6
Author: Junru Shao <[email protected]>
AuthorDate: Sun Jan 4 15:00:16 2026 -0800
doc: Tensor and DLPack (#363)
---
docs/.rstcheck.cfg | 2 +-
docs/concepts/abi_overview.md | 2 +
docs/concepts/tensor.rst | 483 ++++++++++++++++++++++++++++++++++++
docs/get_started/quickstart.rst | 78 +++---
docs/get_started/stable_c_abi.rst | 35 ++-
docs/index.rst | 1 +
docs/packaging/python_packaging.rst | 91 ++++---
7 files changed, 588 insertions(+), 104 deletions(-)
diff --git a/docs/.rstcheck.cfg b/docs/.rstcheck.cfg
index 080a7cc..4e532c1 100644
--- a/docs/.rstcheck.cfg
+++ b/docs/.rstcheck.cfg
@@ -1,5 +1,5 @@
[rstcheck]
report_level = warning
ignore_directives = automodule, autosummary, currentmodule, toctree, ifconfig,
tab-set, collapse, tabs, dropdown
-ignore_roles = ref, cpp:class, cpp:func, py:func, c:macro,
external+data-api:doc, external+scikit_build_core:doc
+ignore_roles = ref, cpp:class, cpp:func, py:func, c:macro,
external+data-api:doc, external+scikit_build_core:doc, external+dlpack:doc
ignore_languages = cpp, python
diff --git a/docs/concepts/abi_overview.md b/docs/concepts/abi_overview.md
index c8e0cd5..7762ede 100644
--- a/docs/concepts/abi_overview.md
+++ b/docs/concepts/abi_overview.md
@@ -184,6 +184,8 @@ and hash TVMFFIAny in bytes for quick equality checks
without going through
type index switching.
:::
+(object-storage-format)=
+
## Object Storage Format
When TVMFFIAny points to a heap-allocated object (such as n-dimensional
arrays),
diff --git a/docs/concepts/tensor.rst b/docs/concepts/tensor.rst
new file mode 100644
index 0000000..17aeef7
--- /dev/null
+++ b/docs/concepts/tensor.rst
@@ -0,0 +1,483 @@
+.. Licensed to the Apache Software Foundation (ASF) under one
+ or more contributor license agreements. See the NOTICE file
+ distributed with this work for additional information
+ regarding copyright ownership. The ASF licenses this file
+ to you under the Apache License, Version 2.0 (the
+ "License"); you may not use this file except in compliance
+ with the License. You may obtain a copy of the License at
+
+.. http://www.apache.org/licenses/LICENSE-2.0
+
+.. Unless required by applicable law or agreed to in writing,
+ software distributed under the License is distributed on an
+ "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ KIND, either express or implied. See the License for the
+ specific language governing permissions and limitations
+ under the License.
+
+Tensor and DLPack
+=================
+
+At runtime, TVM-FFI often needs to accept tensors from many sources:
+
+* Frameworks (e.g. PyTorch, JAX) via :py:meth:`array_api.array.__dlpack__`;
+* C/C++ callers passing :c:struct:`DLTensor* <DLTensor>`;
+* Tensors allocated by a library but managed by TVM-FFI itself.
+
+TVM-FFI standardizes on **DLPack as the lingua franca**: tensors are
+built on top of DLPack structs with additional C++ convenience methods
+and minimal extensions for ownership management.
+
+.. tip::
+
+ Prefer :cpp:class:`tvm::ffi::TensorView` or :cpp:class:`tvm::ffi::Tensor` in
C++ code;
+ they provide safer and more convenient abstractions over raw DLPack structs.
+
+
+This tutorial is organized as follows:
+
+* **Tensor Classes**: introduces what tensor types are provided, and which one
you should use.
+* **Conversion between TVMFFIAny**: how tensors flow across ABI boundaries.
+* **Tensor APIs**: the most important tensor APIs you will use, including
allocation and stream handling.
+
+Glossary
+--------
+
+DLPack
+ A cross-library tensor interchange standard defined in the small C header
``dlpack.h``.
+ It defines pure C data structures for describing n-dimensional arrays and
their memory layout,
+ including :c:struct:`DLTensor`, :c:struct:`DLManagedTensorVersioned`,
:c:struct:`DLDataType`,
+ :c:struct:`DLDevice`, and related types.
+
+View (non-owning)
+ A "header" that describes a tensor but does not own its memory. When a
consumer
+ receives a view, it must respect that the producer owns the underlying
storage and controls its
+ lifetime. The view is valid only while the producer guarantees it remains
valid.
+
+Managed object (owning)
+ An object that includes lifetime management, using reference counting or a
cleanup callback
+ mechanism. This establishes a contract between producer and consumer about
when the consumer's ownership ends.
+
+.. note::
+
+ As a loose analogy, think of **view** vs. **managed** as similar to
+ ``T*`` (raw pointer) vs. ``std::shared_ptr<T>`` (reference-counted pointer)
in C++.
+
+Tensor Classes
+--------------
+
+This section defines each tensor type you will encounter in the TVM-FFI C++
API and explains the
+*intended* usage. Exact C layout details are covered later in
:ref:`layout-and-conversion`.
+
+.. tip::
+
+ On the Python side, only :py:class:`tvm_ffi.Tensor` exists. It strictly
follows DLPack semantics for interop and can be converted to PyTorch via
:py:func:`torch.from_dlpack`.
+
+
+DLPack Tensors
+~~~~~~~~~~~~~~
+
+DLPack tensors come in two main flavors:
+
+*Non-owning* object, :c:struct:`DLTensor`
+ The tensor descriptor is a **view** of the underlying data.
+ It describes the device the tensor lives on, its shape, dtype, and data
pointer. It does not own the underlying data.
+
+*Owning* object, :c:struct:`DLManagedTensorVersioned`, or its legacy
counterpart :c:struct:`DLManagedTensor`
+ It is a **managed** variant that wraps a :c:struct:`DLTensor` descriptor with
additional fields.
+ Notably, it includes a ``deleter`` callback that releases ownership when the
consumer is done with the tensor,
+ and an opaque ``manager_ctx`` handle used by the producer to store additional
context.
+
+TVM-FFI Tensors
+~~~~~~~~~~~~~~~
+
+Similarly, TVM-FFI defines two main tensor types in C++:
+
+*Non-owning* object, :cpp:class:`tvm::ffi::TensorView`
+ A thin C++ wrapper around :c:struct:`DLTensor` for inspecting metadata and
accessing the data pointer.
+ It is designed for **kernel authors** to inspect metadata and access the
underlying data pointer during a call,
+ without taking ownership of the tensor's memory. Being a **view** also means
you must ensure the backing tensor remains valid while you use it.
+
+*Owning* object, :cpp:class:`tvm::ffi::TensorObj` and
:cpp:class:`tvm::ffi::Tensor`
+ :cpp:class:`Tensor <tvm::ffi::Tensor>`, similar to
``std::shared_ptr<TensorObj>``, is the managed class to hold heap-allocated
+ :cpp:class:`TensorObj <tvm::ffi::TensorObj>`. Once the reference count drops
to zero, the cleanup logic deallocates the descriptor
+ and releases ownership of the underlying data buffer.
+
+
+.. note::
+
+ - For handwritten C++, always use TVM-FFI tensors over DLPack's raw C
tensors.
+
+ - For compiler development, DLPack's raw C tensors are recommended because
C is easier to target from codegen.
+
+The owning :cpp:class:`Tensor <tvm::ffi::Tensor>` is the recommended interface
for passing around managed tensors.
+Use owning tensors when you need one or more of the following:
+
+* return a tensor from a function across ABI, which will be converted to
:cpp:class:`tvm::ffi::Any`;
+* allocate an output tensor as the producer, and hand it to a kernel consumer;
+* store a tensor in a long-lived object.
+
+.. admonition:: :cpp:class:`TensorObj <tvm::ffi::TensorObj>` vs
:cpp:class:`Tensor <tvm::ffi::Tensor>`
+ :class: hint
+
+ :cpp:class:`Tensor <tvm::ffi::Tensor>` is an intrusive pointer of a
heap-allocated :cpp:class:`TensorObj <tvm::ffi::TensorObj>`.
+ As an analogy to ``std::shared_ptr``, think of
+
+ .. code-block:: cpp
+
+ using Tensor = std::shared_ptr<TensorObj>;
+
+ You can convert between the two types:
+
+ - :cpp:func:`Tensor::get() <tvm::ffi::Tensor::get>` converts it to
:cpp:class:`TensorObj* <tvm::ffi::TensorObj>`.
+ - :cpp:func:`GetRef\<Tensor\> <tvm::ffi::GetRef>` converts a
:cpp:class:`TensorObj* <tvm::ffi::TensorObj>` back to :cpp:class:`Tensor
<tvm::ffi::Tensor>`.
+
+.. _layout-and-conversion:
+
+Tensor Layouts
+~~~~~~~~~~~~~~
+
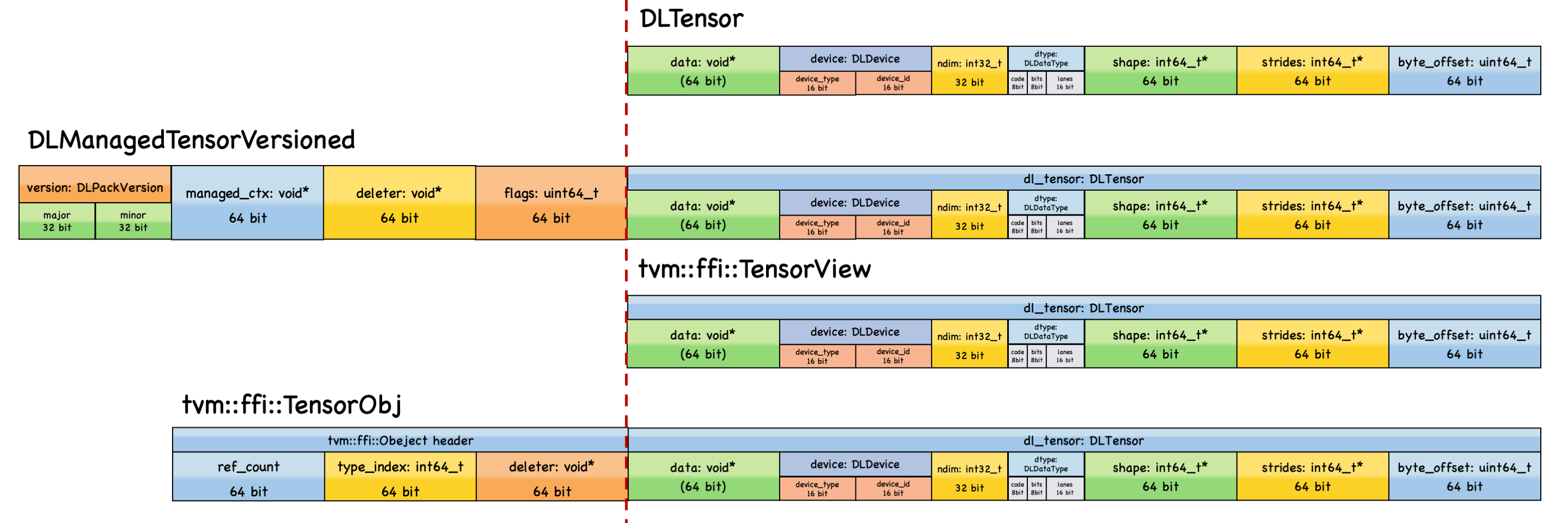
+:ref:`Figure 1 <fig:layout-tensor>` summarizes the layout relationships among
DLPack tensors and TVM-FFI tensors.
+All tensor classes are POD-like; :cpp:class:`tvm::ffi::TensorObj` is also a
standard TVM-FFI object, typically
+heap-allocated and reference-counted.
+
+.. figure::
https://raw.githubusercontent.com/tlc-pack/web-data/main/images/tvm-ffi/tensor-layout.png
+ :alt: Layout of DLPack Tensors and TVM-FFI Tensors
+ :align: center
+ :name: fig:layout-tensor
+
+ Figure 1. Layout specification of DLPack tensors and TVM-FFI tensors. All
the tensor types share :c:struct:`DLTensor` as the common descriptor, while
carrying different metadata and ownership semantics.
+
+As demonstrated in the figure, all tensor classes share :c:struct:`DLTensor`
as the common descriptor.
+In particular,
+
+- :c:struct:`DLTensor` and :cpp:class:`TensorView <tvm::ffi::TensorView>`
share the exact same memory layout.
+- :c:struct:`DLManagedTensorVersioned` and :cpp:class:`TensorObj
<tvm::ffi::TensorObj>` both have a deleter
+ callback to manage the lifetime of the underlying data buffer, while
:c:struct:`DLTensor` and :cpp:class:`TensorView <tvm::ffi::TensorView>` do not.
+- Compared with :cpp:class:`TensorView <tvm::ffi::TensorView>`,
:cpp:class:`TensorObj <tvm::ffi::TensorObj>`
+ has an extra TVM-FFI object header, making it reference-countable via the
standard managed reference :cpp:class:`Tensor <tvm::ffi::Tensor>`.
+
+What Tensor is not
+~~~~~~~~~~~~~~~~~~
+
+TVM-FFI is not a tensor library. While it presents a unified representation
for tensors,
+it does not provide any of the following:
+
+* kernels, such as vector addition, matrix multiplication;
+* host-device copy or synchronization primitives;
+* advanced indexing or slicing;
+* automatic differentiation or computational graph support.
+
+Conversion between :cpp:class:`TVMFFIAny`
+-----------------------------------------
+
+At the stable C ABI boundary, TVM-FFI passes values using an "Any-like"
carrier, often referred
+to as :cpp:class:`Any <tvm::ffi::Any>` (owning) or :cpp:class:`AnyView
<tvm::ffi::AnyView>` (non-owning).
+These are 128-bit tagged unions derived from :cpp:class:`TVMFFIAny` that
contain:
+
+* a :cpp:member:`type_index <TVMFFIAny::type_index>` that indicates the type
of the payload, and
+* a union payload that may contain:
+
+ * A1. Primitive values, such as integers, floats, enums, raw pointers, or
+ * A2. TVM-FFI object handles, which are reference-counted pointers.
+
+Specifically for tensors stored in :cpp:class:`Any <tvm::ffi::Any>` or
:cpp:class:`AnyView <tvm::ffi::AnyView>`,
+there are two possible representations:
+
+* Non-owning views as A1 (primitive values), i.e. :c:struct:`DLTensor*
<DLTensor>` whose type index is
:cpp:enumerator:`TVMFFITypeIndex::kTVMFFIDLTensorPtr`.
+* Owning objects as A2 (TVM-FFI tensor object handles), i.e.,
:cpp:class:`TensorObj* <tvm::ffi::TensorObj>` whose type index is
:cpp:enumerator:`TVMFFITypeIndex::kTVMFFITensor`.
+
+Therefore, when you see a tensor in :cpp:class:`Any <tvm::ffi::Any>` or
:cpp:class:`AnyView <tvm::ffi::AnyView>`,
+first check its :cpp:member:`type_index <TVMFFIAny::type_index>` to determine
whether it is a raw pointer or an object handle
+before converting it to the desired tensor type.
+
+.. important::
+
+ As a rule of thumb, an owning object can be converted to a non-owning view,
but not vice versa.
+
+To Non-Owning Tensor
+~~~~~~~~~~~~~~~~~~~~
+
+This converts an owning :cpp:class:`Any <tvm::ffi::Any>` or non-owning
:cpp:class:`AnyView <tvm::ffi::AnyView>` into a non-owning tensor.
+Two type indices can be converted to a non-owning tensor view:
+
+- :cpp:enumerator:`TVMFFITypeIndex::kTVMFFIDLTensorPtr`: the payload is a raw
pointer :c:struct:`DLTensor* <DLTensor>`.
+- :cpp:enumerator:`TVMFFITypeIndex::kTVMFFITensor`: the payload is a TVM-FFI
tensor object handle, from which you can extract the underlying
:c:struct:`DLTensor` according to the layout defined in :ref:`Figure 1
<fig:layout-tensor>`.
+
+The snippets below are plain C (C99-compatible) and assume the TVM-FFI C ABI
definitions from
+``tvm/ffi/c_api.h`` are available.
+
+.. code-block:: cpp
+
+ // Converts Any/AnyView to DLTensor*
+ int AnyToDLTensorView(const TVMFFIAny* value, DLTensor** out) {
+ if (value->type_index == kTVMFFIDLTensorPtr) {
+ *out = (DLTensor*)value->v_ptr;
+ return SUCCESS;
+ }
+ if (value->type_index == kTVMFFITensor) {
+ // See Figure 1 for layout of tvm::ffi::TensorObj
+ TVMFFIObject* obj = value->v_obj;
+ *out = (DLTensor*)((char*)obj + sizeof(TVMFFIObject));
+ return SUCCESS;
+ }
+ return FAILURE;
+ }
+
+:cpp:class:`TensorView <tvm::ffi::TensorView>` can be constructed directly
from the returned :c:struct:`DLTensor* <DLTensor>`.
+
+To Owning Tensor
+~~~~~~~~~~~~~~~~
+
+This converts an owning :cpp:class:`Any <tvm::ffi::Any>` or non-owning
:cpp:class:`AnyView <tvm::ffi::AnyView>` into an owning :cpp:class:`TensorObj
<tvm::ffi::TensorObj>`. Only type index
:cpp:enumerator:`TVMFFITypeIndex::kTVMFFITensor` can be converted to an owning
tensor because it contains a TVM-FFI tensor object handle. The conversion
involves incrementing the reference count to take ownership.
+
+.. code-block:: cpp
+
+ // Converts Any/AnyView to TensorObj*
+ int AnyToOwnedTensor(const TVMFFIAny* value, TVMFFIObjectHandle* out) {
+ if (value->type_index == kTVMFFITensor) {
+ *out = (TVMFFIObjectHandle)value->v_obj;
+ return SUCCESS;
+ }
+ return FAILURE;
+ }
+
+The caller can obtain shared ownership by calling
:cpp:func:`TVMFFIObjectIncRef` on the returned handle,
+and later release it with :cpp:func:`TVMFFIObjectDecRef`.
+
+From Owning Tensor
+~~~~~~~~~~~~~~~~~~
+
+This converts an owning :cpp:class:`TensorObj <tvm::ffi::TensorObj>` to an
owning :cpp:class:`Any <tvm::ffi::Any>` or non-owning :cpp:class:`AnyView
<tvm::ffi::AnyView>`. It sets the type index to
:cpp:enumerator:`TVMFFITypeIndex::kTVMFFITensor` and stores the tensor object
handle in the payload.
+
+.. code-block:: cpp
+
+ // Converts TensorObj* to AnyView
+ int TensorToAnyView(TVMFFIObjectHandle tensor, TVMFFIAny* out_any_view) {
+ out_any_view->type_index = kTVMFFITensor;
+ out_any_view->zero_padding = 0;
+ out_any_view->v_obj = (TVMFFIObject*)tensor;
+ return SUCCESS;
+ }
+
+ // Converts TensorObj* to Any
+ int TensorToAny(TVMFFIObjectHandle tensor, TVMFFIAny* out_any) {
+ TVMFFIAny any_view;
+ int ret = TensorToAnyView(tensor, &any_view);
+ if (ret != SUCCESS) {
+ return ret;
+ }
+ TVMFFIObjectIncRef(tensor);
+ *out_any = any_view;
+ return SUCCESS;
+ }
+
+The C API :cpp:func:`TVMFFIObjectIncRef` obtains shared ownership of the
tensor into `out_any`. Later, release it with
+:cpp:func:`TVMFFIObjectDecRef` on its :cpp:member:`TVMFFIAny::v_obj` field.
+
+From Non-Owning Tensor
+~~~~~~~~~~~~~~~~~~~~~~
+
+This converts a non-owning :cpp:class:`TensorView <tvm::ffi::TensorView>` to
non-owning :cpp:class:`AnyView <tvm::ffi::AnyView>`.
+It sets the type index to
:cpp:enumerator:`TVMFFITypeIndex::kTVMFFIDLTensorPtr` and stores a raw pointer
to :c:struct:`DLTensor* <DLTensor>` in the payload.
+
+.. warning::
+
+ Non-owning :c:struct:`DLTensor` or :cpp:class:`TensorView
<tvm::ffi::TensorView>` can be converted to non-owning :cpp:class:`AnyView
<tvm::ffi::AnyView>`, but cannot be converted to owning :cpp:class:`Any
<tvm::ffi::Any>`.
+
+.. code-block:: cpp
+
+ // Converts DLTensor* to AnyView
+ int DLTensorToAnyView(DLTensor* tensor, TVMFFIAny* out) {
+ out->type_index = kTVMFFIDLTensorPtr;
+ out->zero_padding = 0;
+ out->v_ptr = tensor;
+ return SUCCESS;
+ }
+
+ // Converts TensorView to AnyView
+ int TensorViewToAnyView(const tvm::ffi::TensorView& tensor_view,
TVMFFIAny* out) {
+ return DLTensorToAnyView(tensor_view.GetDLTensorPtr(), out);
+ }
+
+Tensor APIs
+-----------
+
+This section introduces the most important APIs you will use in C++ and
Python. It intentionally
+focuses on introductory, day-to-day methods.
+
+C++ APIs
+~~~~~~~~
+
+**Common pattern**. A typical kernel implementation includes accepting a
:cpp:class:`TensorView <tvm::ffi::TensorView>` parameter,
+validating its metadata (dtype, shape, device), and then accessing its data
pointer for computation.
+
+.. code-block:: cpp
+
+ void MyKernel(tvm::ffi::TensorView input, tvm::ffi::TensorView output) {
+ // Validate dtype & device
+ if (input.dtype() != DLDataType{kDLFloat, 32, 1})
+ TVM_FFI_THROW(TypeError) << "Expect float32 input, but got " <<
input.dtype();
+ if (input.device() != DLDevice{kDLCUDA, 0})
+ TVM_FFI_THROW(ValueError) << "Expect input on CUDA:0, but got " <<
input.device();
+ // Access data pointer
+ float* input_data_ptr = static_cast<float*>(input.data_ptr());
+ float* output_data_ptr = static_cast<float*>(output.data_ptr());
+ Kernel<<<...>>>(..., input_data_ptr, output_data_ptr, ...);
+ }
+
+**Metadata APIs**. The example above uses metadata APIs for querying tensor
shapes, data types, device information, data pointers, etc. Common ones include:
+
+ :cpp:func:`TensorView::shape() <tvm::ffi::TensorView::shape>` and
:cpp:func:`Tensor::shape() <tvm::ffi::Tensor::shape>`
+ shape array
+
+ :cpp:func:`TensorView::dtype() <tvm::ffi::TensorView::dtype>` and
:cpp:func:`Tensor::dtype() <tvm::ffi::Tensor::dtype>`
+ element data type
+
+ :cpp:func:`TensorView::data_ptr() <tvm::ffi::TensorView::data_ptr>` and
:cpp:func:`Tensor::data_ptr() <tvm::ffi::Tensor::data_ptr>`
+ base pointer to the tensor's data
+
+ :cpp:func:`TensorView::device() <tvm::ffi::TensorView::device>` and
:cpp:func:`Tensor::device() <tvm::ffi::Tensor::device>`
+ device type and id
+
+ :cpp:func:`TensorView::byte_offset() <tvm::ffi::TensorView::byte_offset>` and
:cpp:func:`Tensor::byte_offset() <tvm::ffi::Tensor::byte_offset>`
+ byte offset to the first element
+
+ :cpp:func:`TensorView::ndim() <tvm::ffi::TensorView::ndim>` and
:cpp:func:`Tensor::ndim() <tvm::ffi::Tensor::ndim>`
+ number of dimensions (:cpp:func:`ShapeView::size
<tvm::ffi::ShapeView::size>`)
+
+ :cpp:func:`TensorView::numel() <tvm::ffi::TensorView::numel>` and
:cpp:func:`Tensor::numel() <tvm::ffi::Tensor::numel>`
+ total number of elements (:cpp:func:`ShapeView::Product
<tvm::ffi::ShapeView::Product>`)
+
+
+Python APIs
+~~~~~~~~~~~
+
+The Python-facing :py:class:`tvm_ffi.Tensor` is a managed n-dimensional array
that:
+
+* Can be created via :py:func:`tvm_ffi.from_dlpack(ext_tensor, ...)
<tvm_ffi.from_dlpack>` to import tensors from external frameworks, e.g.
:ref:`PyTorch <ship-to-pytorch>`, :ref:`JAX <ship-to-jax>`, :ref:`NumPy/CuPy
<ship-to-numpy>`.
+* Implements the DLPack protocol so it can be passed back to frameworks
without copying, e.g. :py:func:`torch.from_dlpack`.
+
+Typical import pattern:
+
+.. code-block:: python
+
+ import tvm_ffi
+ import torch
+
+ x = torch.randn(1024, device="cuda")
+ t = tvm_ffi.from_dlpack(x, require_contiguous=True)
+
+ # t is a tvm_ffi.Tensor that views the same memory.
+ # You can pass t into TVM-FFI-exposed functions.
+
+Allocation in C++
+~~~~~~~~~~~~~~~~~
+
+TVM-FFI is not a kernel library per se and is not linked to any specific
device memory allocator or runtime.
+However, for kernel library developers, it provides standardized allocation
entry points by
+interfacing with the surrounding framework's allocator. For example, it uses
PyTorch's allocator when running inside
+a PyTorch environment.
+
+**Env Allocator.** Use :cpp:func:`Tensor::FromEnvAlloc()
<tvm::ffi::Tensor::FromEnvAlloc>` along with C API
+:cpp:func:`TVMFFIEnvTensorAlloc` to allocate a tensor using the framework's
allocator.
+
+.. code-block:: cpp
+
+ Tensor tensor = Tensor::FromEnvAlloc(
+ TVMFFIEnvTensorAlloc,
+ /*shape=*/{1, 2, 3},
+ /*dtype=*/DLDataType({kDLFloat, 32, 1}),
+ /*device=*/DLDevice({kDLCPU, 0})
+ );
+
+In a PyTorch environment, this is equivalent to :py:func:`torch.empty`.
+
+.. warning::
+
+ While allocation APIs are available, it is generally **recommended** to
avoid allocating tensors inside kernels.
+ Instead, prefer pre-allocating outputs and passing them in as
:cpp:class:`tvm::ffi::TensorView` parameters.
+ Reasons include:
+
+ - Avoiding fragmentation and performance pitfalls;
+ - Avoiding cudagraph incompatibilities on GPU;
+ - Allowing the outer framework to control allocation policy (pools, device
strategies, etc.).
+
+
+**Custom Allocator.** Use :cpp:func:`Tensor::FromNDAlloc(custom_alloc, ...)
<tvm::ffi::Tensor::FromNDAlloc>`,
+or its advanced variant :cpp:func:`Tensor::FromNDAllocStrided(custom_alloc,
...) <tvm::ffi::Tensor::FromNDAllocStrided>`,
+to allocate a tensor with user-provided allocation callback.
+
+Below is an example that uses ``cudaMalloc``/``cudaFree`` as custom allocators
for GPU tensors.
+
+.. code-block:: cpp
+
+ struct CUDANDAlloc {
+ void AllocData(DLTensor* tensor) {
+ size_t data_size = ffi::GetDataSize(*tensor);
+ void* ptr = nullptr;
+ cudaError_t err = cudaMalloc(&ptr, data_size);
+ TVM_FFI_ICHECK_EQ(err, cudaSuccess) << "cudaMalloc failed: " <<
cudaGetErrorString(err);
+ tensor->data = ptr;
+ }
+
+ void FreeData(DLTensor* tensor) {
+ if (tensor->data != nullptr) {
+ cudaError_t err = cudaFree(tensor->data);
+ TVM_FFI_ICHECK_EQ(err, cudaSuccess) << "cudaFree failed: " <<
cudaGetErrorString(err);
+ tensor->data = nullptr;
+ }
+ }
+ };
+
+ ffi::Tensor cuda_tensor = ffi::Tensor::FromNDAlloc(
+ CUDANDAlloc(),
+ /*shape=*/{3, 4, 5},
+ /*dtype=*/DLDataType({kDLFloat, 32, 1}),
+ /*device=*/DLDevice({kDLCUDA, 0})
+ );
+
+
+
+Stream Handling in C++
+~~~~~~~~~~~~~~~~~~~~~~
+
+Besides tensors, stream context is another key concept in a kernel library,
especially for kernel execution. While CUDA does not have a global context for
default streams, frameworks like PyTorch maintain a "current stream" per device
(:py:func:`torch.cuda.current_stream`), and kernel libraries must read the
current stream from the embedding environment.
+
+As a hardware-agnostic abstraction layer, TVM-FFI is not linked to any
specific stream management library, but to ensure GPU kernels launch on the
correct stream, it provides standardized APIs to obtain stream context from the
upper framework (e.g. PyTorch).
+
+**Obtain Stream Context.** Use C API :cpp:func:`TVMFFIEnvGetStream` to obtain
the current stream for a given device.
+
+.. code-block:: c++
+
+ void func(ffi::TensorView input, ...) {
+ ffi::DLDevice device = input.device();
+ cudaStream_t stream =
reinterpret_cast<cudaStream_t>(TVMFFIEnvGetStream(device.device_type,
device.device_id));
+ }
+
+which is equivalent to:
+
+.. code-block:: c++
+
+ void func(at::Tensor input, ...) {
+ c10::Device device = input.device();
+ cudaStream_t stream =
reinterpret_cast<cudaStream_t>(c10::cuda::getCurrentCUDAStream(device.index()).stream());
+ }
+
+
+**Auto-Update Stream Context.** When converting framework tensors as mentioned
above, TVM-FFI automatically updates the stream context to match the device of
the converted tensors.
+
+For example, when converting a PyTorch tensor at ``torch.device('cuda:3')``,
TVM-FFI automatically sets the stream context to
:py:func:`torch.cuda.current_stream(device='cuda:3')`.
+
+**Set Stream Context.** :py:func:`tvm_ffi.use_torch_stream` and
:py:func:`tvm_ffi.use_raw_stream` are provided to manually update the stream
context when the automatic update is insufficient.
+
+Further Reading
+---------------
+
+- :cpp:class:`TensorObj <tvm::ffi::TensorObj>` and :cpp:class:`Tensor
<tvm::ffi::Tensor>` are part of the standard TVM-FFI object system.
+ See :ref:`Object System <object-storage-format>` for details on how TVM-FFI
objects work.
+- :cpp:class:`AnyView <tvm::ffi::AnyView>` and :cpp:class:`Any
<tvm::ffi::Any>` are part of the stable C ABI.
+ Tutorial :doc:`Stable C ABI<../get_started/stable_c_abi>` explains the ABI
design at a high level,
+ and :doc:`ABI Overview <abi_overview>` shares details on the design.
+- DLPack specification can be found at :external+data-api:doc:`DLPack protocol
<design_topics/data_interchange>`, and documentation at :external+dlpack:doc:`C
API <c_api>` and :external+dlpack:doc:`Python API <python_spec>`.
+- Kernel library developers may also refer to
:doc:`../guides/kernel_library_guide` and `FlashInfer
<https://github.com/flashinfer-ai/flashinfer/>`_ for best practices on building
high-performance kernel libraries with TVM-FFI.
diff --git a/docs/get_started/quickstart.rst b/docs/get_started/quickstart.rst
index 8dd0fe5..6d608e7 100644
--- a/docs/get_started/quickstart.rst
+++ b/docs/get_started/quickstart.rst
@@ -20,16 +20,16 @@ Quick Start
.. note::
- All the code in this tutorial can be found under `examples/quickstart
<https://github.com/apache/tvm-ffi/tree/main/examples/quickstart>`_ in the
repository.
+ All the code in this tutorial is under `examples/quickstart
<https://github.com/apache/tvm-ffi/tree/main/examples/quickstart>`_ in the
repository.
This guide walks through shipping a minimal ``add_one`` function that computes
``y = x + 1`` in C++ and CUDA.
TVM-FFI's Open ABI and FFI make it possible to **ship one library** for
multiple frameworks and languages.
We can build a single shared library that works across:
-- **ML frameworks**, e.g. PyTorch, JAX, NumPy, CuPy, etc., and
-- **Languages**, e.g. C++, Python, Rust, etc.,
-- **Python ABI versions**, e.g. ship one wheel to support all Python versions,
including free-threaded ones.
+- **ML frameworks**, e.g. PyTorch, JAX, NumPy, CuPy, and others;
+- **Languages**, e.g. C++, Python, Rust, and others;
+- **Python ABI versions**, e.g. one wheel that supports all Python versions,
including free-threaded ones.
.. admonition:: Prerequisite
:class: hint
@@ -39,7 +39,7 @@ We can build a single shared library that works across:
- Compiler: C++17-capable toolchain (GCC/Clang/MSVC)
- Optional ML frameworks for testing: NumPy, PyTorch, JAX, CuPy
- CUDA: Any modern version (if you want to try the CUDA part)
- - TVM-FFI installed via
+ - TVM-FFI installed via:
.. code-block:: bash
@@ -52,7 +52,7 @@ Write a Simple ``add_one``
Source Code
~~~~~~~~~~~
-Suppose we implement a C++ function ``AddOne`` that performs elementwise ``y =
x + 1`` for a 1-D ``float32`` vector. The source code (C++, CUDA) is:
+Suppose we implement a C++ function ``AddOne`` that performs elementwise ``y =
x + 1`` for a 1-D ``float32`` vector. The source code (C++ and CUDA) is:
.. hint::
@@ -84,23 +84,23 @@ Suppose we implement a C++ function ``AddOne`` that
performs elementwise ``y = x
The macro :c:macro:`TVM_FFI_DLL_EXPORT_TYPED_FUNC` exports the C++ function
``AddOne``
-as a TVM FFI compatible symbol ``__tvm_ffi_add_one_cpu/cuda``. If
:c:macro:`TVM_FFI_DLL_EXPORT_INCLUDE_METADATA` is set to 1,
+as a TVM-FFI-compatible symbol ``__tvm_ffi_add_one_cpu/cuda``. If
:c:macro:`TVM_FFI_DLL_EXPORT_INCLUDE_METADATA` is set to 1,
it also exports the function's metadata as a symbol
``__tvm_ffi__metadata_add_one_cpu/cuda`` for type checking and stub generation.
-The class :cpp:class:`tvm::ffi::TensorView` allows zero-copy interop with
tensors from different ML frameworks:
+The class :cpp:class:`tvm::ffi::TensorView` enables zero-copy interop with
tensors from different ML frameworks:
- NumPy, CuPy,
- PyTorch, JAX, or
- any array type that supports the standard :external+data-api:doc:`DLPack
protocol <design_topics/data_interchange>`.
-Finally, :cpp:func:`TVMFFIEnvGetStream` can be used in the CUDA code to launch
a kernel on the caller's stream.
+Finally, :cpp:func:`TVMFFIEnvGetStream` can be used in the CUDA code to launch
kernels on the caller's stream.
.. _sec-cpp-compile-with-tvm-ffi:
Compile with TVM-FFI
~~~~~~~~~~~~~~~~~~~~
-**Raw command.** We can use the following minimal commands to compile the
source code:
+**Raw command.** Use the following minimal commands to compile the source code:
.. tabs::
@@ -118,16 +118,16 @@ Compile with TVM-FFI
:start-after: [cuda_compile.begin]
:end-before: [cuda_compile.end]
-This step produces a shared library ``add_one_cpu.so`` and ``add_one_cuda.so``
that can be used across languages and frameworks.
+These steps produce shared libraries ``add_one_cpu.so`` and
``add_one_cuda.so`` that can be used across languages and frameworks.
.. hint::
- For a single-file C++/CUDA project, a convenient method
:py:func:`tvm_ffi.cpp.load_inline`
- is provided to minimize boilerplate code in compilation, linking, and
loading.
+ For a single-file C++/CUDA project, :py:func:`tvm_ffi.cpp.load_inline`
+ minimizes boilerplate for compilation, linking, and loading.
**CMake.** CMake is the preferred approach for building across platforms.
-TVM-FFI natively integrates with CMake via ``find_package`` as demonstrated
below:
+TVM-FFI integrates with CMake via ``find_package`` as demonstrated below:
.. tabs::
@@ -158,19 +158,19 @@ TVM-FFI natively integrates with CMake via
``find_package`` as demonstrated belo
add_library(add_one_cuda SHARED compile/add_one_cuda.cu)
tvm_ffi_configure_target(add_one_cuda)
-**Artifact.** The resulting ``add_one_cpu.so`` and ``add_one_cuda.so`` are
minimal libraries that are agnostic to:
+**Artifact.** The resulting ``add_one_cpu.so`` and ``add_one_cuda.so`` are
small libraries that are agnostic to:
-- Python version/ABI. It is not compiled/linked with Python and depends only
on TVM-FFI's stable C ABI;
-- Languages, including C++, Python, Rust or any other language that can
interop with C ABI;
-- ML frameworks, such as PyTorch, JAX, NumPy, CuPy, or anything with standard
:external+data-api:doc:`DLPack protocol <design_topics/data_interchange>`.
+- Python version/ABI. They are not compiled or linked with Python and depend
only on TVM-FFI's stable C ABI;
+- Languages, including C++, Python, Rust, or any other language that can
interop with the C ABI;
+- ML frameworks, such as PyTorch, JAX, NumPy, CuPy, or any array library that
implements the standard :external+data-api:doc:`DLPack protocol
<design_topics/data_interchange>`.
.. _sec-use-across-framework:
Ship Across ML Frameworks
-------------------------
-TVM-FFI's Python package provides :py:func:`tvm_ffi.load_module`, which can
load either
-the ``add_one_cpu.so`` or ``add_one_cuda.so`` into :py:class:`tvm_ffi.Module`.
+TVM-FFI's Python package provides :py:func:`tvm_ffi.load_module` to load either
+``add_one_cpu.so`` or ``add_one_cuda.so`` into a :py:class:`tvm_ffi.Module`.
.. code-block:: python
@@ -179,7 +179,7 @@ the ``add_one_cpu.so`` or ``add_one_cuda.so`` into
:py:class:`tvm_ffi.Module`.
func : tvm_ffi.Function = mod.add_one_cpu
``mod.add_one_cpu`` retrieves a callable :py:class:`tvm_ffi.Function` that
accepts tensors from host frameworks
-directly. This process is done zero-copy, without any boilerplate code, under
extremely low latency.
+directly. This is zero-copy, requires no boilerplate code, and adds very
little overhead.
We can then use these functions in the following ways:
@@ -198,13 +198,13 @@ PyTorch
JAX
~~~
-Support via `nvidia/jax-tvm-ffi <https://github.com/nvidia/jax-tvm-ffi>`_.
This can be installed via
+Support is provided via `nvidia/jax-tvm-ffi
<https://github.com/nvidia/jax-tvm-ffi>`_. Install it with:
.. code-block:: bash
pip install jax-tvm-ffi
-After installation, ``add_one_cuda`` can be registered as a target to JAX's
``ffi_call``.
+After installation, ``add_one_cuda`` can be registered as a target for JAX's
``ffi_call``.
.. code-block:: python
@@ -248,9 +248,9 @@ NumPy/CuPy
Ship Across Languages
---------------------
-TVM-FFI's core loading mechanism is ABI stable and works across language
boundaries.
-A single library can be loaded in every language TVM-FFI supports,
-without having to recompile different libraries targeting different ABIs or
languages.
+TVM-FFI's core loading mechanism is ABI-stable and works across language
boundaries.
+A single library can be loaded in any language TVM-FFI supports,
+without recompiling for different ABIs or languages.
.. _ship-to-python:
@@ -258,8 +258,8 @@ Python
~~~~~~
As shown in the :ref:`previous section<sec-use-across-framework>`,
:py:func:`tvm_ffi.load_module` loads a language-
-and framework-independent ``add_one_cpu.so`` or ``add_one_cuda.so`` and can be
used to incorporate it into all Python
-array frameworks that implement the standard :external+data-api:doc:`DLPack
protocol <design_topics/data_interchange>`.
+and framework-independent ``add_one_cpu.so`` or ``add_one_cuda.so`` and can be
used with any Python
+array framework that implements the standard :external+data-api:doc:`DLPack
protocol <design_topics/data_interchange>`.
.. _ship-to-cpp:
@@ -267,7 +267,7 @@ C++
~~~
TVM-FFI's C++ API :cpp:func:`tvm::ffi::Module::LoadFromFile` loads
``add_one_cpu.so`` or ``add_one_cuda.so`` and
-can be used directly in C/C++ with no Python dependency.
+can be used directly from C/C++ without a Python dependency.
.. literalinclude:: ../../examples/quickstart/load/load_cpp.cc
:language: cpp
@@ -290,13 +290,13 @@ Compile and run it with:
.. note::
- Don't like loading shared libraries? Static linking is also supported.
+ Prefer not to load shared libraries? Static linking is also supported.
- In such cases, we can use :cpp:func:`tvm::ffi::Function::FromExternC` to
create a
+ In such cases, use :cpp:func:`tvm::ffi::Function::FromExternC` to create a
:cpp:class:`tvm::ffi::Function` from the exported symbol, or directly use
:cpp:func:`tvm::ffi::Function::InvokeExternC` to invoke the function.
- This feature can be useful on iOS, or when the exported module is generated
by another DSL compiler matching the ABI.
+ This feature can be useful on iOS, or when the exported module is generated
by another DSL compiler targeting the ABI.
.. code-block:: cpp
@@ -321,7 +321,7 @@ Rust
TVM-FFI's Rust API ``tvm_ffi::Module::load_from_file`` loads
``add_one_cpu.so`` or ``add_one_cuda.so`` and
then retrieves a function ``add_one_cpu`` or ``add_one_cuda`` from it.
-This procedure is identical to those in C++ and Python:
+This mirrors the C++ and Python flows:
.. code-block:: rust
@@ -336,8 +336,8 @@ This procedure is identical to those in C++ and Python:
.. hint::
- We can also use the Rust API to target the TVM FFI ABI. This means we can
use Rust to write the function
- implementation and export to Python/C++ in the same fashion.
+ You can also use the Rust API to target the TVM-FFI ABI. This lets you
write the function
+ implementation in Rust and export it to Python/C++ in the same way.
Troubleshooting
@@ -351,7 +351,7 @@ Troubleshooting
Further Reading
---------------
-- :doc:`Python Packaging <../packaging/python_packaging>` provides details on
ABI-agnostic Python wheel building, as well as
- exposing functions, classes and C symbols from TVM-FFI modules.
-- :doc:`Stable C ABI <stable_c_abi>` explains the ABI in depth and how it
enables stability guarantee. Its C examples demonstrate
- how to interoperate through the stable C ABI from both callee and caller
sides.
+- :doc:`Python Packaging <../packaging/python_packaging>` provides details on
ABI-agnostic Python wheel builds and on
+ exposing functions, classes, and C symbols from TVM-FFI modules.
+- :doc:`Stable C ABI <stable_c_abi>` explains the ABI in depth and the
stability guarantees it enables. Its C examples demonstrate
+ how to interoperate through the stable C ABI from both the callee and caller
sides.
diff --git a/docs/get_started/stable_c_abi.rst
b/docs/get_started/stable_c_abi.rst
index bcfe491..abab5c2 100644
--- a/docs/get_started/stable_c_abi.rst
+++ b/docs/get_started/stable_c_abi.rst
@@ -20,7 +20,7 @@ Stable C ABI
.. note::
- All code used in this guide lives under
+ All code used in this guide is under
`examples/stable_c_abi
<https://github.com/apache/tvm-ffi/tree/main/examples/stable_c_abi>`_.
.. admonition:: Prerequisite
@@ -34,11 +34,10 @@ Stable C ABI
pip install --reinstall --upgrade apache-tvm-ffi
-This guide introduces TVM-FFI's stable C ABI: a single, minimal and stable
-ABI that represents any cross-language calls, with DSL and ML compiler codegen
-in mind.
+This guide introduces TVM-FFI's stable C ABI: a single, minimal ABI that
represents
+cross-language calls and is designed for DSL and ML compiler codegen.
-TVM-FFI builds on the following key idea:
+TVM-FFI is built around the following key idea:
.. _tvm_ffi_c_abi:
@@ -56,19 +55,19 @@ TVM-FFI builds on the following key idea:
TVMFFIAny* result, // output: *result
);
- where :cpp:class:`TVMFFIAny`, is a tagged union of all supported types, e.g.
integers, floats, Tensors, strings, etc., and can be further extended to
arbitrary user-defined types.
+ where :cpp:class:`TVMFFIAny` is a tagged union of all supported types, e.g.
integers, floats, tensors, strings, and more, and can be extended to
user-defined types.
-Built on top of this stable C ABI, TVM-FFI defines a common C ABI protocol for
all functions, and further provides an extensible, performant, and
ecosystem-friendly open solution for all.
+Built on top of this stable C ABI, TVM-FFI defines a common C ABI protocol for
all functions and provides an extensible, performant, and ecosystem-friendly
solution.
The rest of this guide covers:
- The stable C layout and calling convention of ``tvm_ffi_c_abi``;
-- C examples from both callee and caller side of this ABI.
+- C examples from both the callee and caller side of this ABI.
Stable C Layout
---------------
-TVM-FFI's :ref:`C ABI <tvm_ffi_c_abi>` uses a stable layout for all the input
and output arguments.
+TVM-FFI's :ref:`C ABI <tvm_ffi_c_abi>` uses a stable layout for all input and
output arguments.
Layout of :cpp:class:`TVMFFIAny`
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
@@ -76,7 +75,7 @@ Layout of :cpp:class:`TVMFFIAny`
:cpp:class:`TVMFFIAny` is a fixed-size (128-bit) tagged union that represents
all supported types.
- First 32 bits: type index indicating which value is stored (supports up to
2^32 types).
-- Next 32 bits: reserved (used for flags in rare cases, e.g. small-string
optimization).
+- Next 32 bits: reserved (used for flags in rare cases, e.g., small-string
optimization).
- Last 64 bits: payload that is either a 64-bit integer, a 64-bit
floating-point number, or a pointer to a heap-allocated object.
.. figure::
https://raw.githubusercontent.com/tlc-pack/web-data/main/images/tvm-ffi/stable-c-abi-layout-any.svg
@@ -137,9 +136,9 @@ Stable ABI in C Code
You can build and run the examples either with raw compiler commands or with
CMake.
Both approaches are demonstrated below.
-TVM FFI's :ref:`C ABI <tvm_ffi_c_abi>` is designed with DSL and ML compilers
in mind. DSL codegen usually relies on MLIR, LLVM or low-level C as the
compilation target, where no access to C++ features is available, and where
stable C ABIs are preferred for simplicity and stability.
+TVM-FFI's :ref:`C ABI <tvm_ffi_c_abi>` is designed with DSL and ML compilers
in mind. DSL codegen often targets MLIR, LLVM, or low-level C, where C++
features are unavailable and stable C ABIs are preferred for simplicity and
stability.
-This section shows how to write C code that follows the stable C ABI.
Specifically, we provide two examples:
+This section shows how to write C code that follows the stable C ABI using two
examples:
- Callee side: A CPU ``add_one_cpu`` kernel in C that is equivalent to the
:ref:`C++ example <cpp_add_one_kernel>`.
- Caller side: A loader and runner in C that invokes the kernel, a direct C
translation of the :ref:`C++ example <ship-to-cpp>`.
@@ -149,11 +148,11 @@ The C code is minimal and dependency-free, so it can
serve as a direct reference
Callee: ``add_one_cpu`` Kernel
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-Below is a minimal ``add_one_cpu`` kernel in C that follows the stable C ABI.
It has three steps:
+Below is a minimal ``add_one_cpu`` kernel in C that follows the stable C ABI
in three steps:
- **Step 1**. Extract input ``x`` and output ``y`` as DLPack tensors;
- **Step 2**. Implement the kernel ``y = x + 1`` on CPU with a simple for-loop;
-- **Step 3**. Set the output result to ``result``.
+- **Step 3**. Set the output result in ``result``.
.. literalinclude:: ../../examples/stable_c_abi/src/add_one_cpu.c
:language: c
@@ -188,7 +187,7 @@ Build it with either approach:
**C vs. C++.** Compared to the :ref:`C++ example <cpp_add_one_kernel>`, there
are a few key differences:
- The explicit marshalling in **Step 1** is only needed in C. In C++,
templates hide these details.
-- The C++ macro :c:macro:`TVM_FFI_DLL_EXPORT_TYPED_FUNC` (used to export
``add_one_cpu``) is not needed in C, because this example directly defines the
exported C symbol ``__tvm_ffi_add_one_cpu``.
+- The C++ macro :c:macro:`TVM_FFI_DLL_EXPORT_TYPED_FUNC` (used to export
``add_one_cpu``) is not needed in C, since this example directly defines the
exported C symbol ``__tvm_ffi_add_one_cpu``.
.. hint::
@@ -200,7 +199,7 @@ Build it with either approach:
Caller: Kernel Loader
~~~~~~~~~~~~~~~~~~~~~
-Next, a minimal C loader invokes the ``add_one_cpu`` kernel. It is
functionally identical to the :ref:`C++ example <ship-to-cpp>` and performs:
+Next, a minimal C loader invokes the ``add_one_cpu`` kernel. It mirrors the
:ref:`C++ example <ship-to-cpp>` and performs:
- **Step 1**. Load the shared library ``build/add_one_cpu.so`` that contains
the kernel;
- **Step 2**. Get function ``add_one_cpu`` from the library;
@@ -238,7 +237,7 @@ Build and run the loader with either approach:
cmake --build build --config RelWithDebInfo
build/load
-To call a function via the stable C ABI in C, idiomatically:
+In C, the idiomatic steps to call a function via the stable C ABI are:
- Convert input arguments to the :cpp:class:`TVMFFIAny` type;
- Call the target function (e.g., ``add_one_cpu``) via
:cpp:func:`TVMFFIFunctionCall`;
@@ -247,7 +246,7 @@ To call a function via the stable C ABI in C, idiomatically:
What's Next
-----------
-**ABI specification.** See the complete ABI specification in
:doc:`../concepts/abi_overview`.
+**ABI specification.** See the full ABI specification in
:doc:`../concepts/abi_overview`.
**Convenient compiler target.** The stable C ABI is a simple, portable codegen
target for DSL compilers. Emit C that follows this ABI to integrate with
TVM-FFI and call the result from multiple languages and frameworks. See
:doc:`../concepts/abi_overview`.
diff --git a/docs/index.rst b/docs/index.rst
index 2387846..f6eced7 100644
--- a/docs/index.rst
+++ b/docs/index.rst
@@ -59,6 +59,7 @@ Table of Contents
:caption: Concepts
concepts/abi_overview.md
+ concepts/tensor.rst
.. toctree::
:maxdepth: 1
diff --git a/docs/packaging/python_packaging.rst
b/docs/packaging/python_packaging.rst
index c3d8f81..b89abc0 100644
--- a/docs/packaging/python_packaging.rst
+++ b/docs/packaging/python_packaging.rst
@@ -18,10 +18,10 @@
Python Packaging
================
-This guide walks through a small but complete workflow for packaging a TVM-FFI
extension
+This guide walks through a small, complete workflow for packaging a TVM-FFI
extension
as a Python wheel. The goal is to help you wire up a simple extension, produce
a wheel,
and ship user-friendly typing annotations without needing to know every detail
of TVM
-internals. We will cover three checkpoints:
+internals. We cover three checkpoints:
- Export C++ to Python;
- Build Python wheel;
@@ -29,7 +29,7 @@ internals. We will cover three checkpoints:
.. note::
- All code used in this guide lives under
+ All code used in this guide is under
`examples/python_packaging
<https://github.com/apache/tvm-ffi/tree/main/examples/python_packaging>`_.
.. admonition:: Prerequisite
@@ -55,19 +55,19 @@ Include the umbrella header to access the core TVM-FFI C++
API.
TVM-FFI offers three ways to expose code:
-- C symbols in TVM FFI ABI: Export code as plain C symbols. This is the
recommended way for
- most usecases as it keeps the boundary thin and works well with compiler
codegen;
-- Functions: Reflect functions via the global registry;
-- Classes: Register C++ classes derived from :cpp:class:`tvm::ffi::Object` to
Python dataclasses.
+- C symbols in the TVM-FFI ABI: export code as plain C symbols. This is the
recommended way for
+ most use cases because it keeps the boundary thin and works well with
compiler codegen;
+- Functions: expose functions via the global registry;
+- Classes: register C++ classes derived from :cpp:class:`tvm::ffi::Object` as
Python dataclasses.
-Metadata is automatically captured and is later be turned into type hints for
proper LSP help.
+Metadata is captured automatically and later turned into type hints for LSP
support.
TVM-FFI ABI (Recommended)
~~~~~~~~~~~~~~~~~~~~~~~~~
If you prefer to export plain C symbols, TVM-FFI provides helpers to make them
accessible
-to Python. This option keeps the boundary thin and works well with LLVM
compilers where
-C symbols are easier to call into.
+from Python. This option keeps the boundary thin and works well with
LLVM-based compilers where
+C symbols are easier to call.
.. tabs::
@@ -107,8 +107,8 @@ C symbols are easier to call into.
Global Function
~~~~~~~~~~~~~~~
-This example registers a function into the global registry and then calls it
from Python.
-It registry handles type translation, error handling, and metadata.
+This example registers a function in the global registry and then calls it
from Python.
+The registry handles type translation, error handling, and metadata.
.. tabs::
@@ -164,7 +164,7 @@ It registry handles type translation, error handling, and
metadata.
Class
~~~~~
-Any class derived from :cpp:class:`tvm::ffi::Object` can be registered,
exported and
+Any class derived from :cpp:class:`tvm::ffi::Object` can be registered,
exported, and
instantiated from Python. The reflection helper
:cpp:class:`tvm::ffi::reflection::ObjectDef`
makes it easy to expose:
@@ -205,7 +205,7 @@ makes it easy to expose:
import my_ffi_extension
pair = my_ffi_extension.IntPair(1, 2)
- pair.sum() # -> 3
+ pair.sum() # -> 3
.. group-tab:: Python (Generated)
@@ -227,11 +227,11 @@ makes it easy to expose:
Build Python Wheel
------------------
-Once the C++ side is ready, TVM-FFI provides convenient helpers to build and
ship
-ABI-agnostic Python extensions using any standard packaging tool.
+Once the C++ side is ready, TVM-FFI provides helpers to build and ship
+ABI-agnostic Python extensions using standard packaging tools.
The flow below uses :external+scikit_build_core:doc:`scikit-build-core <index>`
-that drives CMake build, but the same ideas translate to setuptools or other
:pep:`517` backends.
+to drive a CMake build, but the same ideas apply to setuptools or other
:pep:`517` backends.
CMake Target
~~~~~~~~~~~~
@@ -244,19 +244,19 @@ creates a shared target ``my_ffi_extension`` and
configures it against TVM-FFI.
:start-after: [example.cmake.begin]
:end-before: [example.cmake.end]
-Function ``tvm_ffi_configure_target`` sets up TVM-FFI include paths, link
against TVM-FFI library,
+Function ``tvm_ffi_configure_target`` sets up TVM-FFI include paths, links
against the TVM-FFI library,
generates stubs under ``STUB_DIR``, and can scaffold stub files when
``STUB_INIT`` is
enabled.
-Function ``tvm_ffi_install`` places necessary information, e.g. debug symbols
in macOS, next to
-the shared library for proper packaging.
+Function ``tvm_ffi_install`` places necessary information (e.g., debug symbols
on macOS) next to
+the shared library for packaging.
Python Build Backend
~~~~~~~~~~~~~~~~~~~~
-Define a :pep:`517` build backend in ``pyproject.toml``, with the following
steps:
+Define a :pep:`517` build backend in ``pyproject.toml`` with the following
steps:
-- Sepcfiy ``apache-tvm-ffi`` as a build requirement, so that CMake can find
TVM-FFI;
+- Specify ``apache-tvm-ffi`` as a build requirement, so that CMake can find
TVM-FFI;
- Configure ``wheel.py-api`` that indicates a Python ABI-agnostic wheel;
- Specify the source directory of the package via ``wheel.packages``, and the
installation
destination via ``wheel.install-dir``.
@@ -266,13 +266,13 @@ Define a :pep:`517` build backend in ``pyproject.toml``,
with the following step
:start-after: [pyproject.build.begin]
:end-before: [pyproject.build.end]
-Once fully specified, scikit-build-core will invoke CMake and drive the
extension building process.
+Once specified, scikit-build-core will invoke CMake and drive the extension
build.
Wheel Auditing
~~~~~~~~~~~~~~
-**Build wheels**. The wheel can be built using the standard workflows, e.g.:
+**Build wheels**. You can build wheels using standard workflows, for example:
- `pip workflow <https://pip.pypa.io/en/stable/cli/pip_wheel/>`_ or `editable
install
<https://pip.pypa.io/en/stable/topics/local-project-installs/#editable-installs>`_
@@ -295,9 +295,9 @@ Wheel Auditing
cibuildwheel --output-dir dist
-**Audit wheels**. In practice, an extra step is usually necessary to remove
redundant
-and error-prone shared library dependencies. In our case, given
``libtvm_ffi.so``
-(or its respective platform variants) is guaranteed to be loaded by importing
``tvm_ffi``,
+**Audit wheels**. In practice, an extra step is usually needed to remove
redundant
+and error-prone shared library dependencies. In our case, because
``libtvm_ffi.so``
+(or its platform variants) is guaranteed to be loaded by importing ``tvm_ffi``,
we can safely exclude this dependency from the final wheel.
.. code-block:: bash
@@ -322,11 +322,11 @@ corresponding Python code **inline** and **statically**.
Inline Directives
~~~~~~~~~~~~~~~~~
-Similar to linter tools, ``tvm-ffi-stubgen`` uses special comments
+Like linter tools, ``tvm-ffi-stubgen`` uses special comments
to identify what to generate and where to write generated code.
-**Directive 1 (Global functions)**. Example below shows an directive
-``global/${prefix}`` marking a type stub section of global functions.
+**Directive 1 (Global functions)**. The example below shows a directive
+``global/${prefix}`` that marks a type stub section for global functions.
.. code-block:: python
@@ -340,10 +340,10 @@ to identify what to generate and where to write generated
code.
Running ``tvm-ffi-stubgen`` fills in the function stubs between the
``begin`` and ``end`` markers based on the loaded registry, and in this case
-introduces all the global functions named ``my_ext.arith.*``.
+adds all the global functions named ``my_ext.arith.*``.
-**Directive 2 (Classes)**. Example below shows an directive
-``object/${type_key}`` marking the fields and methods of a registered class.
+**Directive 2 (Classes)**. The example below shows a directive
+``object/${type_key}`` that marks the fields and methods of a registered class.
.. code-block:: python
@@ -360,12 +360,12 @@ introduces all the global functions named
``my_ext.arith.*``.
Directive-based Generation
~~~~~~~~~~~~~~~~~~~~~~~~~~
-After TVM-FFI extension is built as a shared library, say at
-``build/libmy_ffi_extension.so``
+After the TVM-FFI extension is built as a shared library, for example at
+``build/libmy_ffi_extension.so``:
**Command line tool**. The command below generates stubs for
the package located at ``python/my_ffi_extension``, updating
-all sections marked by the directives.
+all sections marked by directives.
.. code-block:: bash
@@ -384,15 +384,14 @@ every time the target is built.
STUB_DIR "python"
)
-Inside the function, CMake manages to find proper ``--dlls`` arguments
+Inside the function, CMake derives the proper ``--dlls`` arguments
via ``$<TARGET_FILE:${target}>``.
Scaffold Missing Directives
~~~~~~~~~~~~~~~~~~~~~~~~~~~
**Command line tool**. Beyond updating existing directives, ``tvm-ffi-stubgen``
-can be used to scaffold missing directives if they are not yet present in the
-package with a few extra flags.
+can scaffold missing directives with a few extra flags.
.. code-block:: bash
@@ -405,11 +404,11 @@ package with a few extra flags.
- ``--init-pypkg <pypkg>``: Specifies the name of the Python package to
initialize, e.g. ``apache-tvm-ffi``, ``my-ffi-extension``;
- ``--init-lib <libtarget>``: Specifies the name of the CMake target (shared
library) to load for reflection metadata;
-- ``--init-prefix <prefix>``: Specifies the registry prefix to include for
stub generation, e.g. ``my_ffi_extension.``. If names of global functions or
classes start with this prefix, they will be included in the generated stubs.
+- ``--init-prefix <prefix>``: Specifies the registry prefix to include for
stub generation, e.g. ``my_ffi_extension.``. If global function or class names
start with this prefix, they will be included in the generated stubs.
**CMake Integration**. CMake function ``tvm_ffi_configure_target``
-also supports scaffolding missing directives via the extra options
-``STUB_INIT``, ``STUB_PKG``, and ``STUB_PREFIX``.
+also supports scaffolding missing directives via the ``STUB_INIT``,
``STUB_PKG``,
+and ``STUB_PREFIX`` options.
.. code-block:: cmake
@@ -424,7 +423,7 @@ based on the target and package information already
specified.
Other Directives
~~~~~~~~~~~~~~~~
-All the supported directives are documented via:
+All supported directives are documented via:
.. code-block:: bash
@@ -448,8 +447,8 @@ It includes:
from typing import Any, Callable
# tvm-ffi-stubgen(end)
-**Directive 4 (Export)**. It re-exports names defined in `_ffi_api.__all__`
into the current file. Usually
-used in ``__init__.py`` to aggregate all exported names. Example:
+**Directive 4 (Export)**. It re-exports names defined in `_ffi_api.__all__`
into the current file, usually
+in ``__init__.py`` to aggregate exported names. Example:
.. code-block:: python
@@ -481,7 +480,7 @@ classes and functions, as well as ``LIB`` if present. It's
usually placed at the
# tvm-ffi-stubgen(ty-map): ffi.reflection.AccessStep ->
ffi.access_path.AccessStep
-means the class with type key ``ffi.reflection.AccessStep``, is instead class
``ffi.access_path.AccessStep``
+means the class with type key ``ffi.reflection.AccessStep`` is mapped to
``ffi.access_path.AccessStep``
in Python.
**Directive 7 (Import object)**. It injects a custom import into generated
code, optionally
{kind=link}
{kind=link}