anijain2305 opened a new pull request #6119: URL: https://github.com/apache/incubator-tvm/pull/6119
After going through multiple frameworks, I found that it is common to ignore -128 for int8 quantization. TFLite - from Pete Warden's blog and TFLite paper - https://petewarden.com/2017/06/22/what-ive-learned-about-neural-network-quantization/  MKLDNN - https://oneapi-src.github.io/oneDNN/ex_int8_simplenet.html  TensorRT - https://blog.tensorflow.org/2019/06/high-performance-inference-with-TensorRT.html 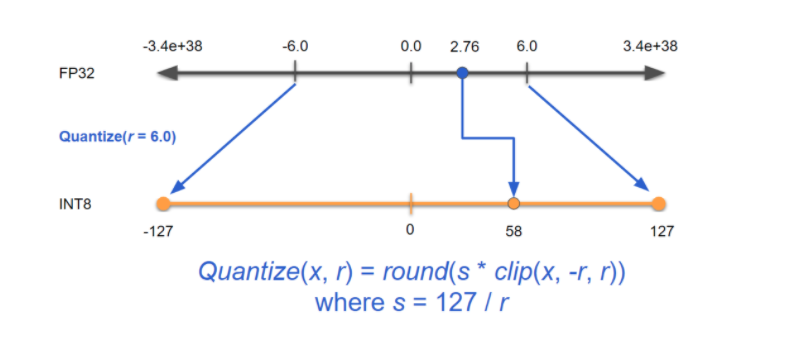 As this is a common practice now, this PR adapts to this change as well. ---------------------------------------------------------------- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: [email protected]
{kind=link}
{kind=link}
{kind=link}