ZihengJiang opened a new pull request #6980: URL: https://github.com/apache/tvm/pull/6980
This PR implements the automated quantization framework described in the [RFC](https://discuss.tvm.apache.org/t/rfc-search-based-automated-quantization/5483). More detail can be found in the [paper draft](https://www.ziheng.org/files/hago.pdf) also. We observe that HAGO achieves speedups of 2.09x, 1.97x, and 2.48x on Intel Xeon Cascade Lake CPUs, NVIDIA Tesla T4 GPUs, ARM Cortex-A CPUs on Raspberry Pi4 relative to full precision respectively, while maintaining high post-training quantization accuracy in each case. Still WIP. ## Highlights - Hardware Awareness - Model-Agnostic Graph Transformation - Search-Based Optimization ## Results ### Accuracy for the MXNet Models 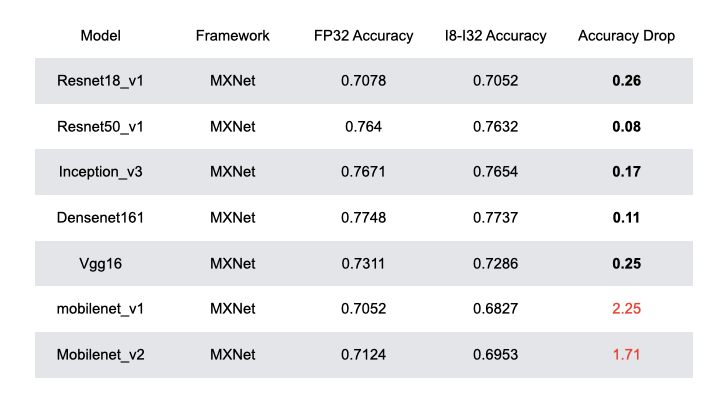 ### Accuracy for the TensorFlow Models 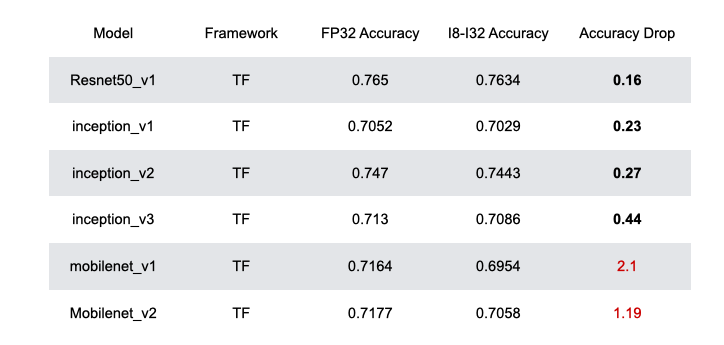 ### Accuracy for the PyTorch Models 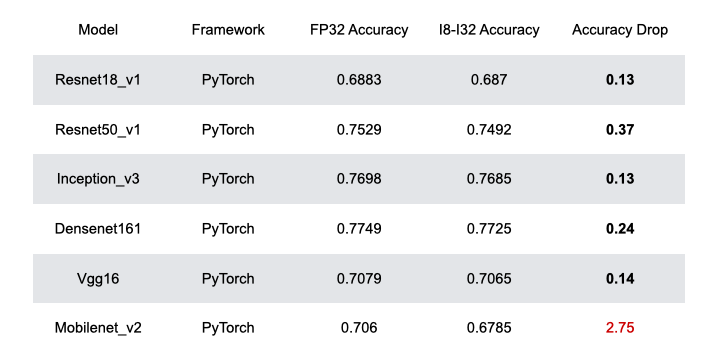 ### Performance on x86 CPU 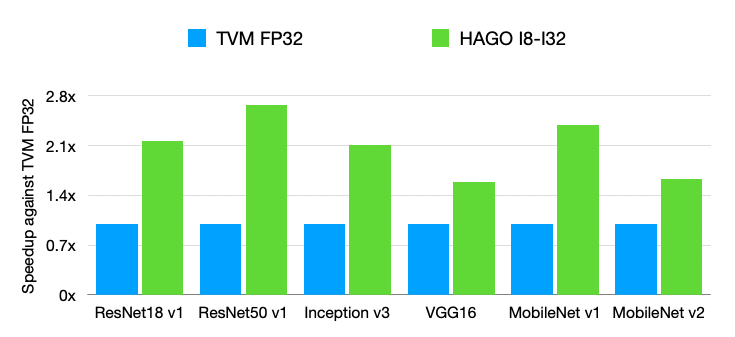 ### Performance on NVIDIA GPU 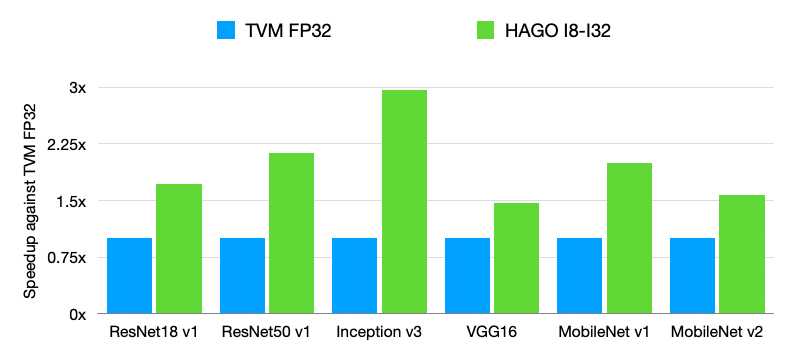 ### Performance on ARM CPU 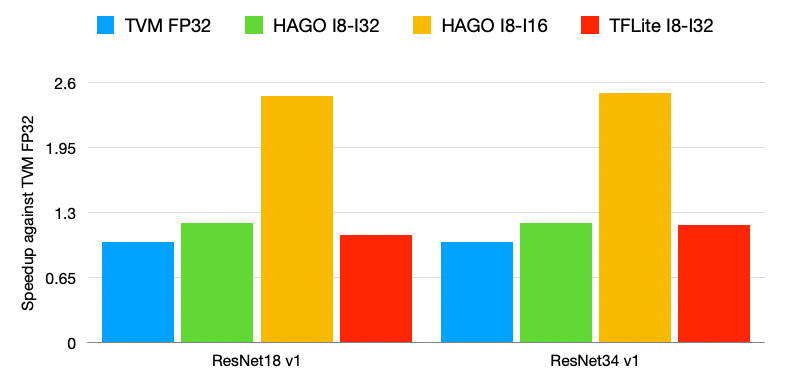 ---------------------------------------------------------------- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: [email protected]
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}