zhuwenxi edited a comment on issue #7246: URL: https://github.com/apache/tvm/issues/7246#issuecomment-759976432
> Possible way to resolve the issue: > > * Introduce the packed_arg_alloca intrinsic that is only gauranteed to be valid for the specific packed func call > > * Skip the lifting alloca step, and keep alloca always next to the func call > * Update LLVM codegen to insert alloca always to the beginning of the current function block > * Update StackVM and C codegen to support things accordingly If I understand correctly, you wanna introduce a special "packed_arg_alloca" tir and make sure all backends implement it? Correct me if I'm wrong :) As I mentioned above, the root cause of this problem is the **tir** lowering for packed func in a parallel for is not thread-safe. So have you considered to fix it on tir level, utilizing existing TVM IRs? Thus no new tir type introduction and corresponding backend codegen implementations are required. This is what I propose to fix the problem: re-allocation the stack next to the packed func call, but only in the parallel for loop. 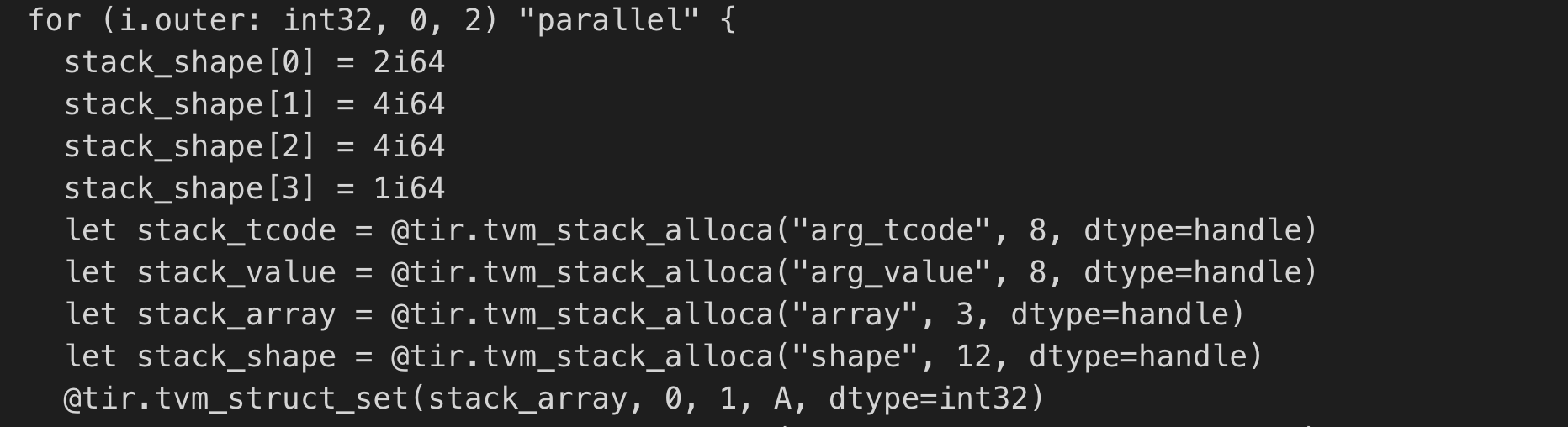 I've already tired the fix and confirmed this approach does work. (I understand the re-allocation is against the SSA constrain, but it can be avoid easily, by making re-allocated stacks have distinct names, such as "stack_value_1", "stack_value_2") ---------------------------------------------------------------- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: [email protected]
{kind=link}