Daniel-009497 opened a new pull request, #5247: URL: https://github.com/apache/hadoop/pull/5247
Tens of thousands of meaningless logs are frequently printed during ResourceManager startup and recover container. As we know, ResourceManager will always keep 10k application information by default. In our very big scale cluster, it is very usual that resourcemanager try to recover the containers which already finished and does not exist in ResourceManager but still reported by nodemanager. Under this case, below logs will be frequently printed, more importantly, this log is meaningless, in real production setups, the maintainers actually more care about which containers are properly recovered or killed not the ones are skipped. The related code are as follows, 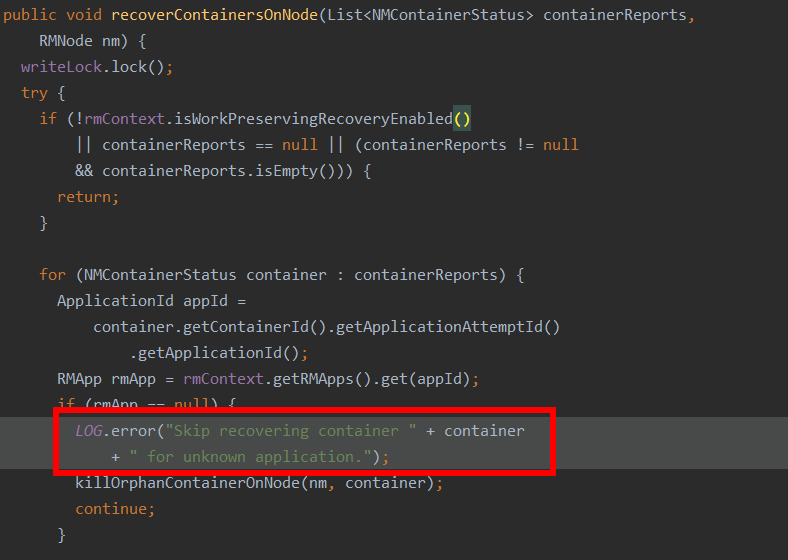 So we move the log into function killOrphanContainerOnNode(). 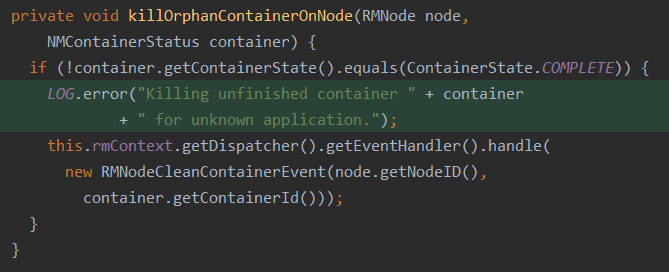 Only the containers to be killed need to be loged which is vital for trouble shooting to distinguish whether the containers are kill by hadoop inner mechanism or by users themselves. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: common-issues-unsubscr...@hadoop.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org --------------------------------------------------------------------- To unsubscribe, e-mail: common-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: common-issues-h...@hadoop.apache.org
{kind=link}
{kind=link}