The benefit of having a memory format that’s friendly to non-deterministic order writes is unlocked by the transport and processing of the data being agnostic to the physical order as much as possible.
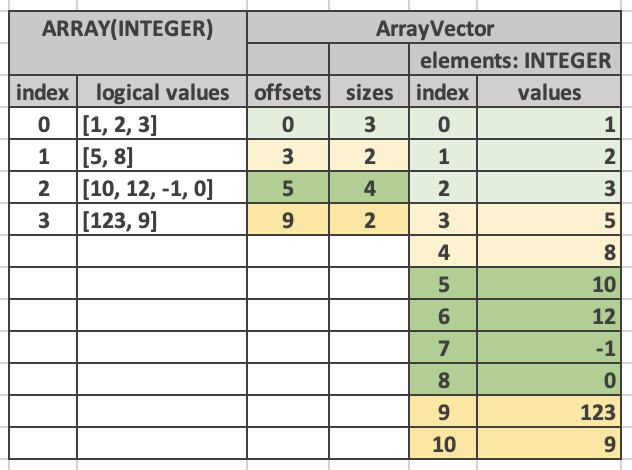
Requiring a conversion could cancel out that benefit. But it can be a provisory step for compatibility between systems that don’t understand the format yet. This is similar to the situation with compression schemes like run-end encoding — the goal is processing the compressed data directly without an expansion step whenever possible. This is why having it as part of the open Arrow format is so important: everyone can agree on a format that’s friendly to parallel and/or vectorized compute kernels without introducing multiple incompatible formats to the ecosystem and without imposing a conversion step between the different systems. — Felipe On Sat, 20 May 2023 at 20:04 Aldrin <[email protected]> wrote: > I don't feel like this representation is necessarily a detail of the query > engine, but I am also not sure why this representation would have to be > converted to a non-view format when serializing. Could you clarify that? My > impression is that this representation could be used for persistence or > data transfer, though it can be more complex to guarantee the portion of > the buffer that an index points to is also present in memory. > > Sent from Proton Mail for iOS > > > On Sat, May 20, 2023 at 15:00, Sasha Krassovsky <[email protected] > <On+Sat,+May+20,+2023+at+15:00,+Sasha+Krassovsky+%3C%3Ca+href=>> wrote: > > Hi everyone, > I understand that there are numerous benefits to this representation > during query processing, but would it be fair to say that this is an > implementation detail of the query engine? Query engines don’t necessarily > need to conform to the Arrow format internally, only at ingest/egress > points, and performing a conversion from the non-view to view format seems > like it would be very cheap (though I understand not necessarily the other > way around, but you’d need to do that anyway if you’re serializing). > > Sasha Krassovsky > > > 20 мая 2023 г., в 13:00, Will Jones <[email protected]> > написал(а): > > > > Thanks for sharing these details, Pedro. The conditional branches > argument > > makes a lot of sense to me. > > > > The tensors point brings up some interesting issues. For now, we've > defined > > our only tensor extension type to be built on a fixed size list. If a use > > case of this might be manipulating tensors with zero copy, perhaps that > > suggests that we want a fixed size list variant? In addition, would we > have > > to define another extension type to be a ListView variant? Or would we > want > > to think about making extension types somehow valid across various > > encodings of the same "logical type"? > > > >> On Fri, May 19, 2023 at 1:59 PM Pedro Eugenio Rocha Pedreira > >> <[email protected]> wrote: > >> > >> Hi all, > >> > >> This is Pedro from the Velox team at Meta. This is my first time here, > so > >> nice to e-meet you! > >> > >> Adding to what Felipe said, the main reason we created “ListView” > (though > >> we just call them ArrayVector/MapVector in Velox) is that, along with > >> StringViews for strings, they allow us to write any columnar buffer > >> out-or-order, regardless of their types or encodings. This is naturally > >> doable for all primitive types (fixed-size), but not for types that > don’t > >> have fixed size and are required to be contiguous. The StringView and > >> ListView formats allow us to keep this invariant in Velox. > >> > >> Being able to write vectors out-of-order is useful when executing > >> conditionals like IF/SWITCH statements, which are pervasive among our > >> workloads. To fully vectorize it, one first evaluates the expression, > then > >> generate a bitmap containing which rows take the THEN and which take the > >> ELSE branch. Then you populate all rows that match the first branch by > >> evaluating the THEN expression in a vectorized (branch-less and cache > >> friendly) way, and subsequently the ELSE branch. If you can’t write them > >> out-of-order, you would either have a big branch per row dispatching to > the > >> right expression (slow), or populate two distinct vectors then merging > them > >> at the end (potentially even slower). How much faster our approach is > >> highly depends on the buffer sizes and expressions, but we found it to > be > >> faster enough on average to justify us extending the underlying layout. > >> > >> With that said, this is all within a single thread of execution. > >> Parallelization is done by feeding each thread its own vector/data. As > >> pointed out in a previous message, this also gives you the flexibility > to > >> implement cardinality increasing/reducing operations, but we don’t use > it > >> for that purpose. Operations like filtering, joining, unnesting and > similar > >> are done by wrapping the internal vector in a dictionary, as these need > to > >> work not only on “ListViews” but on any data types with any encoding. > There > >> are more details on Section 4.2.1 in [1] > >> > >> Beyond this, it also gives function/kernel developers more flexibility > to > >> implement operations that manipulate Arrays/Maps. For example, > operations > >> that slice these containers can be implemented in a zero-copy manner by > >> just rearranging the lengths/offsets indices, without ever touching the > >> larger internal buffers. This is a similar motivation as for StringView > >> (think of substr(), trim(), and similar). One nice last property is that > >> this layout allows for overlapping ranges. This is something discussed > with > >> our ML people to allow deduping feature values in a tensor (which is > fairly > >> common), but not something we have leveraged just yet. > >> > >> [1] - https://vldb.org/pvldb/vol15/p3372-pedreira.pdf > >> > >> Best, > >> -- > >> Pedro Pedreira > >> ________________________________ > >> From: Felipe Oliveira Carvalho <[email protected]> > >> Sent: Friday, May 19, 2023 10:01 AM > >> To: [email protected] <[email protected]> > >> Cc: Pedro Eugenio Rocha Pedreira <[email protected]> > >> Subject: Re: [DISCUSS][Format] Starting the draft implementation of the > >> ArrayView array format > >> > >> +pedroerp On Thu, 11 May 2023 at 17: 51 Raphael Taylor-Davies <r. > >> taylordavies@ googlemail. com. invalid> wrote: Hi All, > if we added > >> this, do we think many Arrow and query > engine implementations (for > >> example, DataFusion) will be > >> ZjQcmQRYFpfptBannerStart > >> This Message Is From an External Sender > >> > >> ZjQcmQRYFpfptBannerEnd > >> +pedroerp > >> > >> On Thu, 11 May 2023 at 17:51 Raphael Taylor-Davies > >> <[email protected]> wrote: > >> Hi All, > >> > >>> if we added this, do we think many Arrow and query > >>> engine implementations (for example, DataFusion) will be eager to add > >> full > >>> support for the type, including compute kernels? Or are they likely to > >> just > >>> convert this type to ListArray at import boundaries? > >> I can't speak for query engines in general, but at least for arrow-rs > >> and by extension DataFusion, and based on my current understanding of > >> the use-cases I would be rather hesitant to add support to the kernels > >> for this array type, definitely instead favouring conversion at the > >> edges. We already have issues with the amount of code generation > >> resulting in binary bloat and long compile times, and I worry this would > >> worsen this situation whilst not really providing compelling advantages > >> for the vast majority of workloads that don't interact with Velox. > >> Whilst I can definitely see that the ListView representation is probably > >> a better way to represent variable length lists than what arrow settled > >> upon, I'm not yet convinced it is sufficiently better to incentivise > >> broad ecosystem adoption. > >> > >> Kind Regards, > >> > >> Raphael Taylor-Davies > >> > >>> On 11/05/2023 21:20, Will Jones wrote: > >>> Hi Felipe, > >>> > >>> Thanks for the additional details. > >>> > >>> > >>>> Velox kernels benefit from being able to append data to the array from > >>>> different threads without care for strict ordering. Only the offsets > >> array > >>>> has to be written according to logical order but that is potentially a > >> much > >>>> smaller buffer than the values buffer. > >>>> > >>> It still seems to me like applications are still pretty niche, as I > >> suspect > >>> in most cases the benefits are outweighed by the costs. The benefit > here > >>> seems pretty limited: if you are trying to split work between threads, > >>> usually you will have other levels such as array chunks to parallelize. > >> And > >>> if you have an incoming stream of row data, you'll want to append in > >>> predictable order to match the order of the other arrays. Am I missing > >>> something? > >>> > >>> And, IIUC, the cost of using ListView with out-of-order values over > >>> ListArray is you lose memory locality; the values of element 2 are no > >>> longer adjacent to the values of element 1. What do you think about > that > >>> tradeoff? > >>> > >>> I don't mean to be difficult about this. I'm excited for both the REE > and > >>> StringView arrays, but this one I'm not so sure about yet. I suppose > >> what I > >>> am trying to ask is, if we added this, do we think many Arrow and query > >>> engine implementations (for example, DataFusion) will be eager to add > >> full > >>> support for the type, including compute kernels? Or are they likely to > >> just > >>> convert this type to ListArray at import boundaries? > >>> > >>> Because if it turns out to be the latter, then we might as well ask > Velox > >>> to export this type as ListArray and save the rest of the ecosystem > some > >>> work. > >>> > >>> Best, > >>> > >>> Will Jones > >>> > >>> On Thu, May 11, 2023 at 12:32 PM Felipe Oliveira Carvalho < > >>> [email protected]<mailto:[email protected]>> wrote: > >>> > >>>> Initial reason for ListView arrays in Arrow is zero-copy compatibility > >> with > >>>> Velox which uses this format. > >>>> > >>>> Velox kernels benefit from being able to append data to the array from > >>>> different threads without care for strict ordering. Only the offsets > >> array > >>>> has to be written according to logical order but that is potentially a > >> much > >>>> smaller buffer than the values buffer. > >>>> > >>>> Acero kernels could take advantage of that in the future. > >>>> > >>>> In implementing ListViewArray/Type I was able to reuse some C++ > >> templates > >>>> used for ListArray which can reduce some of the burden on kernel > >>>> implementations that aim to work with all the types. > >>>> > >>>> I’m can fix Acero kernels for working with ListView. This is similar > to > >> the > >>>> work I’ve doing in kernels dealing with run-end encoded arrays. > >>>> > >>>> — > >>>> Felipe > >>>> > >>>> > >>>> On Wed, 26 Apr 2023 at 01:03 Will Jones <[email protected] > >> <mailto:[email protected]>> wrote: > >>>> > >>>>> I suppose one common use case is materializing list columns after > some > >>>>> expanding operation like a join or unnest. That's a case where I > could > >>>>> imagine a lot of repetition of values. Haven't yet thought of common > >>>> cases > >>>>> where there is overlap but not full duplication, but am eager to hear > >>>> any. > >>>>> The dictionary encoding point Raphael makes is interesting, > especially > >>>>> given the existence of LargeList and FixedSizeList. For many > >> operations, > >>>> it > >>>>> might make more sense to just compose those existing types. > >>>>> > >>>>> IIUC the operations that would be unique to the ArrayView are ones > >>>> altering > >>>>> the shape. One could truncate each array to a certain length cheaply > >>>> simply > >>>>> by replacing the sizes buffer. Or perhaps there are interesting > >>>> operations > >>>>> on tensors that would benefit. > >>>>> > >>>>> On Tue, Apr 25, 2023 at 7:47 PM Raphael Taylor-Davies > >>>>> <[email protected]> wrote: > >>>>> > >>>>>> Unless I am missing something, I think the selection use-case could > be > >>>>>> equally well served by a dictionary-encoded BinarArray/ListArray, > and > >>>>> would > >>>>>> have the benefit of not requiring any modifications to the existing > >>>>> format > >>>>>> or kernels. > >>>>>> > >>>>>> The major additional flexibility of the proposed encoding would be > >>>>>> permitting disjoint or overlapping ranges, are these common enough > in > >>>>>> practice to represent a meaningful bottleneck? > >>>>>> > >>>>>> > >>>>>> On 26 April 2023 01:40:14 BST, David Li <[email protected] > <mailto: > >> [email protected]>> wrote: > >>>>>>> Is there a need for a 64-bit offsets version the same way we have > >> List > >>>>>> and LargeList? > >>>>>>> And just to be clear, the difference with List is that the lists > >> don't > >>>>>> have to be stored in their logical order (or in other words, offsets > >> do > >>>>> not > >>>>>> have to be nondecreasing and so we also need sizes)? > >>>>>>> On Wed, Apr 26, 2023, at 09:37, Weston Pace wrote: > >>>>>>>> For context, there was some discussion on this back in [1]. At > that > >>>>>> time > >>>>>>>> this was called "sequence view" but I do not like that name. > >>>> However, > >>>>>>>> array-view array is a little confusing. Given this is similar to > >>>> list > >>>>>> can > >>>>>>>> we go with list-view array? > >>>>>>>> > >>>>>>>>> Thanks for the introduction. I'd be interested to hear about the > >>>>>>>>> applications Velox has found for these vectors, and in what > >>>>> situations > >>>>>>>> they > >>>>>>>>> are useful. This could be contrasted with the current ListArray > >>>>>>>>> implementations. > >>>>>>>> I believe one significant benefit is that take (and by proxy, > >>>> filter) > >>>>>> and > >>>>>>>> sort are O(# of items) with the proposed format and O(# of bytes) > >>>> with > >>>>>> the > >>>>>>>> current format. Jorge did some profiling to this effect in [1]. > >>>>>>>> > >>>>>>>> [1] > >>>> https://lists.apache.org/thread/49qzofswg1r5z7zh39pjvd1m2ggz2kdq< > >> https://lists.apache.org/thread/49qzofswg1r5z7zh39pjvd1m2ggz2kdq> > >>>>>>>> On Tue, Apr 25, 2023 at 3:13 PM Will Jones < > [email protected] > >> <mailto:[email protected]> > >>>>>> wrote: > >>>>>>>>> Hi Felipe, > >>>>>>>>> > >>>>>>>>> Thanks for the introduction. I'd be interested to hear about the > >>>>>>>>> applications Velox has found for these vectors, and in what > >>>>> situations > >>>>>> they > >>>>>>>>> are useful. This could be contrasted with the current ListArray > >>>>>>>>> implementations. > >>>>>>>>> > >>>>>>>>> IIUC it would be fairly cheap to transform a ListArray to an > >>>>>> ArrayView, but > >>>>>>>>> expensive to go the other way. > >>>>>>>>> > >>>>>>>>> Best, > >>>>>>>>> > >>>>>>>>> Will Jones > >>>>>>>>> > >>>>>>>>> On Tue, Apr 25, 2023 at 3:00 PM Felipe Oliveira Carvalho < > >>>>>>>>> [email protected]<mailto:[email protected]>> wrote: > >>>>>>>>> > >>>>>>>>>> Hi folks, > >>>>>>>>>> > >>>>>>>>>> I would like to start a public discussion on the inclusion of a > >>>> new > >>>>>> array > >>>>>>>>>> format to Arrow — array-view array. The name is also up for > >>>> debate. > >>>>>>>>>> This format is inspired by Velox's ArrayVector format [1]. > >>>>> Logically, > >>>>>>>>> this > >>>>>>>>>> array represents an array of arrays. Each element is an > >>>> array-view > >>>>>>>>> (offset > >>>>>>>>>> and size pair) that points to a range within a nested "values" > >>>>> array > >>>>>>>>>> (called "elements" in Velox docs). The nested array can be of > any > >>>>>> type, > >>>>>>>>>> which makes this format very flexible and powerful. > >>>>>>>>>> > >>>>>>>>>> [image: ../_images/array-vector.png] > >>>>>>>>>> < > >>>>> https://facebookincubator.github.io/velox/_images/array-vector.png< > >> https://facebookincubator.github.io/velox/_images/array-vector.png>> > >>>>>>>>>> I'm currently working on a C++ implementation and plan to work > >>>> on a > >>>>>> Go > >>>>>>>>>> implementation to fulfill the two-implementations requirement > for > >>>>>> format > >>>>>>>>>> changes. > >>>>>>>>>> > >>>>>>>>>> The draft design: > >>>>>>>>>> > >>>>>>>>>> - 3 buffers: [validity_bitmap, int32 offsets buffer, int32 sizes > >>>>>> buffer] > >>>>>>>>>> - 1 child array: "values" as an array of the type parameter > >>>>>>>>>> > >>>>>>>>>> validity_bitmap is used to differentiate between empty array > >>>> views > >>>>>>>>>> (sizes[i] == 0) and NULL array views (validity_bitmap[i] == 0). > >>>>>>>>>> > >>>>>>>>>> When the validity_bitmap[i] is 0, both sizes and offsets are > >>>>>> undefined > >>>>>>>>> (as > >>>>>>>>>> usual), and when sizes[i] == 0, offsets[i] is undefined. 0 is > >>>>>> recommended > >>>>>>>>>> if setting a value is not an issue to the system producing the > >>>>>> arrays. > >>>>>>>>>> offsets buffer is not required to be ordered and views don't > have > >>>>> to > >>>>>> be > >>>>>>>>>> disjoint. > >>>>>>>>>> > >>>>>>>>>> [1] > >>>>>>>>>> > >>>> > >> > https://facebookincubator.github.io/velox/develop/vectors.html#arrayvector > >> < > >> > https://facebookincubator.github.io/velox/develop/vectors.html#arrayvector > >>> > >>>>>>>>>> Thanks, > >>>>>>>>>> Felipe O. Carvalho > >>>>>>>>>> > >> > >
{kind=link}