psylambda edited a comment on issue #1154: URL: https://github.com/apache/incubator-brpc/issues/1154#issuecomment-853546823
场景是情况1, server端异常宕机/断电, client端的tcp包会一直重传, 且重传间隔越来越长, 如下图所示。 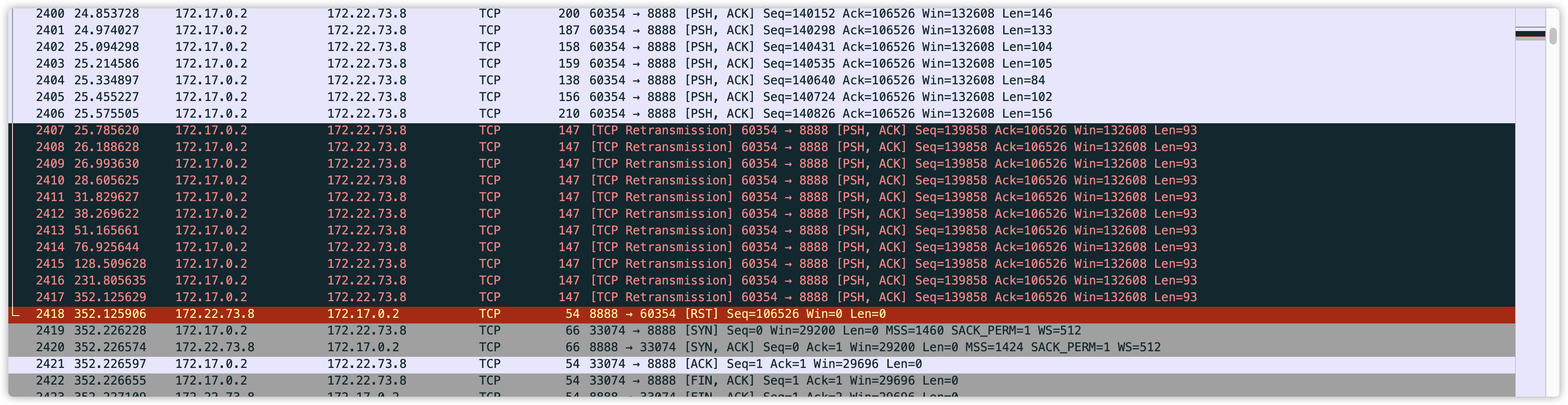 在上图的例子中, client端在231秒和352秒分别发了一个重传包。 如果server端恰好在232秒恢复正常, 那么client端并不会立刻感知到, 而是在352秒时刻发重传包的时候才感知到, 并重新建tcp连接, 之后的请求才能正常被server端处理。 这意味着232秒到352秒时间内, 虽然server端恢复了, 但是client端的所有请求都持续报错。 * 对于grpc, 可以通过配置tcp_user_timeout, 来控制重传时间, 避免重传间隔过长导致server端恢复后, client端还要较长时间才能感知到 * 对于brpc, 现在有办法避免这个问题么? @zyearn -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org --------------------------------------------------------------------- To unsubscribe, e-mail: dev-unsubscr...@brpc.apache.org For additional commands, e-mail: dev-h...@brpc.apache.org
{kind=link}