simon824 opened a new issue, #2144: URL: https://github.com/apache/incubator-hugegraph/issues/2144
### Feature Description (功能描述) In this version(`hugegraph-1.0.0`), if hugegraph's backend store is rocksdb, it only supports the replica mode, and each node stores a full amount of data, which cannot support scenarios with a large amount of data. This issue will describe an implementation of raft sharding mode which base on JRaft `MULTI-RAFT-GROUP `. At present, a basic version has been implemented, which has passed the basic test of insert, delete and query , but there are still many places that need to be optimized and improved. If you are interested, you can contact me or comment in this issue and participate together. # Design When `hugegraph-server` starts and initializes `RaftBackendStoreProvider`, a routeTable (hugegraph+rr) will be generated in schemaStore initialization method, and routeTable will generates a `shardId -> peers` mapping according to the number of shards and replicas .After getting the route table, `RaftBackendStoreProvider` generates the corresponding number of `RocksDBStore` and `RaftContext` according to the shardId. `RocksDBStore` is responsible for selecting `RaftContext` to execute commands according to shardId. The data of each shard is stored independently on different rocksdb paths,and each path is managed by a separate `RocksDBStore`. Each shard independently maintains consistency with other shard copies through raft. 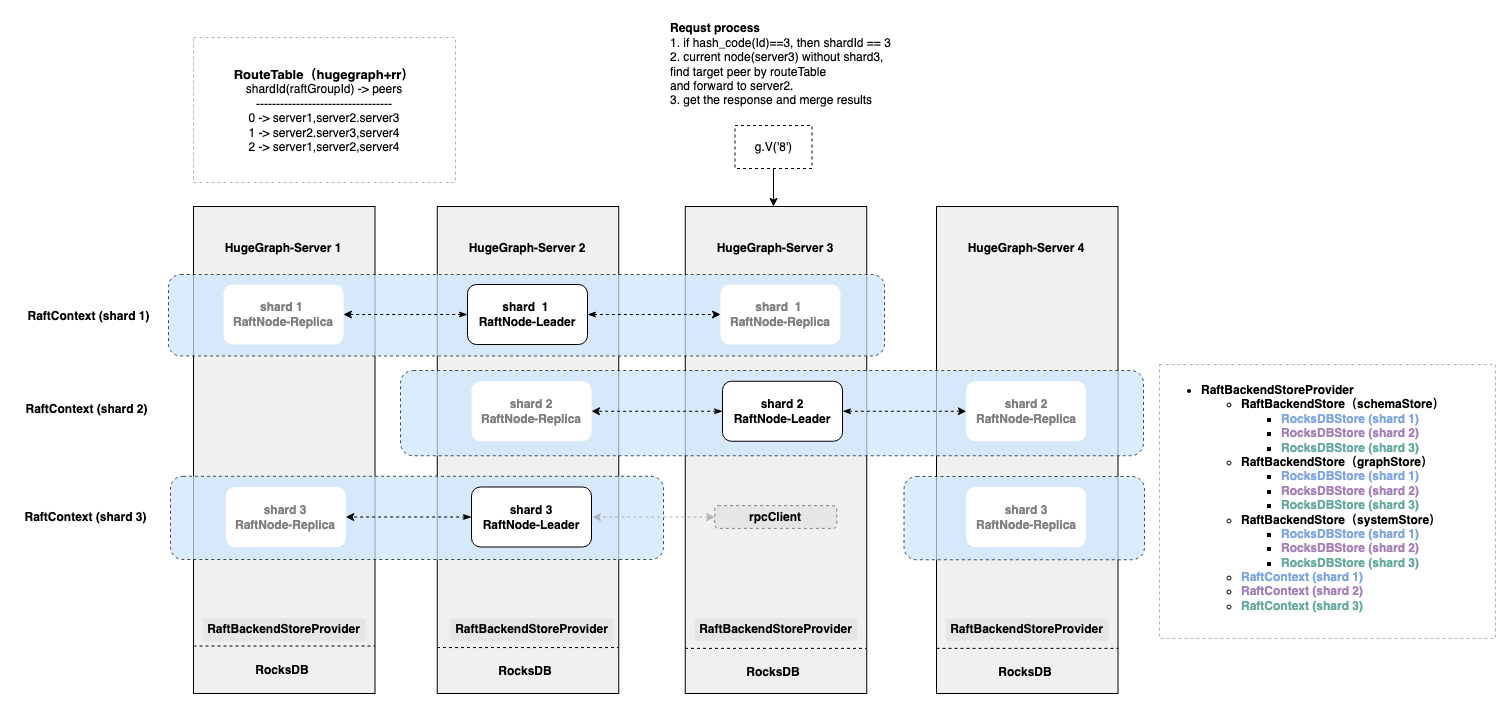 When `RaftBackendStore` receives the client request, it will calculate the shardId according to the request ID, and then forward the request to the corresponding shard (If there is no ID, it needs to be executed on all shards). There are three scenarios for data reading and writing: 1. If the requested shard does not exist on the current node, find the peers corresponding to the shard recorded in the route table, select a node to forward, and wait for the result to be returned. 2. If the requested shard exists on the current node, go directly to the local query logic. 3. If there are multiple requests, some of them need to be forwarded (1), and some of them can be executed locally (2), then execute them separately, and merge all the data into the same iterator (`BinaryEntryIterator`). # TODO - [ ] Implement `raftNodeManager` for multiple raft groups - [ ] Support dynamic update of routeTabel when raft config being modified. - [ ] Reuse the rpclicent of `RpcForwarder` - [ ] query local shards by asynchronous method - [ ] Synchronize the leader ip of each shard to the routing table, and forward the request directly to the leader - [ ] Optimize the graph instance directory structure when there are multiple shards - [ ] Improve UT - [ ] Improve documentation -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: [email protected] For queries about this service, please contact Infrastructure at: [email protected]
{kind=link}