Dear all, I suggest enable "kylin.dictionary.shrunken-from-global-enabled" by default(it is disabled by default), because I found enable it will speed up cube build process when cube have count distinct(bitmap) on a large cardinality column. This feature is contributed in KYLIN-3491.
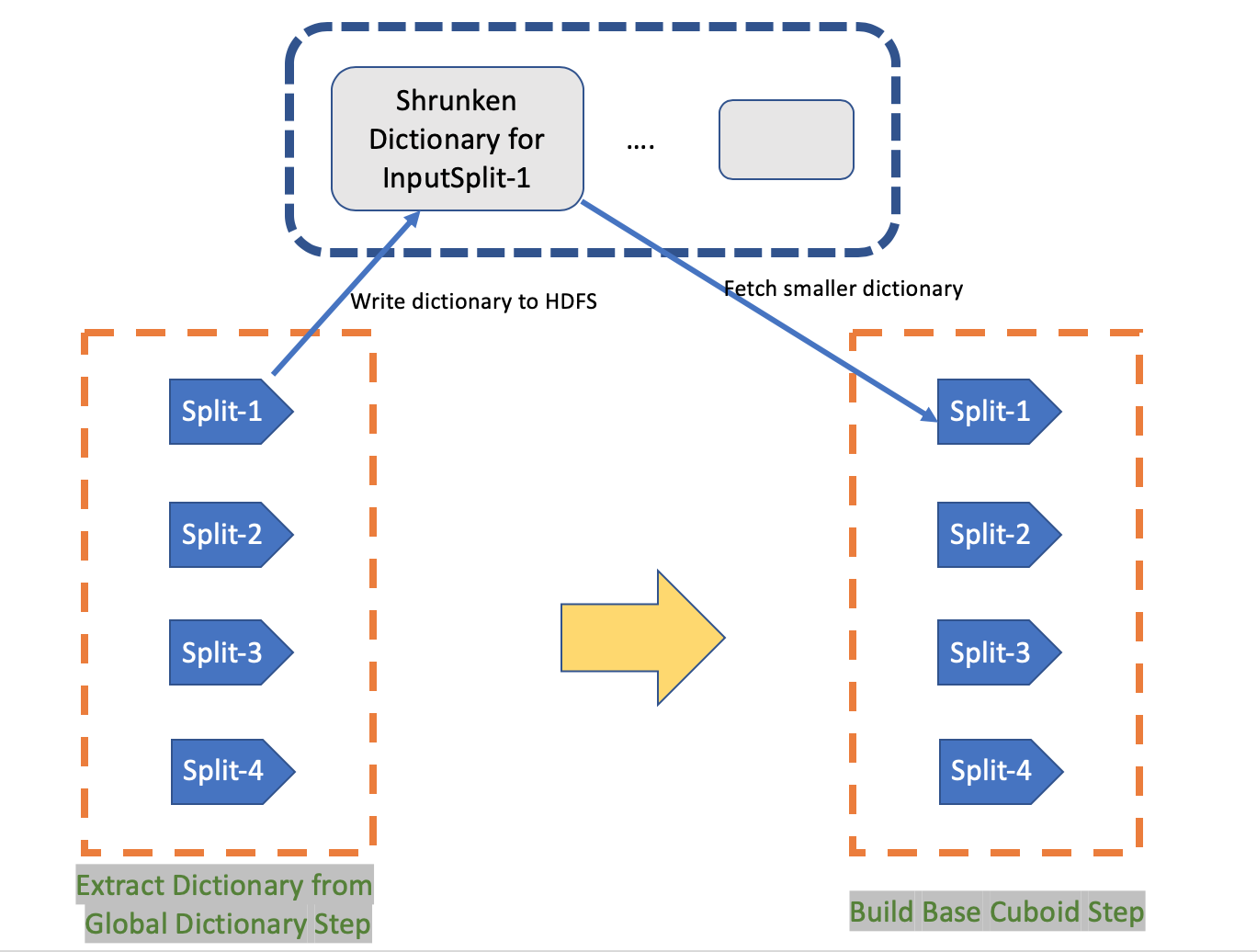
When using count distinct(bitmap) measure on a large cardinality column(this require global dictionary), build base cuboid step need frequent cache swap so it cannot finished within a reasonable period. KYLIN-3491 add a new step to build separated dictionary for each InputSplit before BuildBaseCuboid step. So mapper of BuildBaseCuboid step only has to fetch a smaller dictionary for itself(without unused value), instead of a larger global dictionary. It will reduce cache swap and make BuildBaseCuboid step run as quick as possible. In my test env, my hadoop cluster is a CDH cluster with 56 vcore and 110GB Memory. I create a model with a fact table (153326740 rows) and three dimension tables, there are three count distinct(bitmap) measure which the largest cardinality of single column is 55200325. With ShrunkenDict disabled, the BuildBaseCuboid cannot completed in 22 hours. Comparatively, with ShrunkenDict enabled, build process completed in a reasonable duration(Extra Dictionary cost 5 minutes, Build Base Cuboid costs 5 minutes). https://user-images.githubusercontent.com/14030549/54363305-ad25e200-46a5-11e9-8bc7-fe2c385c0278.png If you want know more, please check https://issues.apache.org/jira/browse/KYLIN-3491. If you have any suggestion, please let me know. ---------------- Best wishes, Xiaoxiang Yu
{kind=link}