yaooqinn opened a new issue #1753: URL: https://github.com/apache/incubator-kyuubi/issues/1753
### Code of Conduct - [X] I agree to follow this project's [Code of Conduct](https://www.apache.org/foundation/policies/conduct) ### Search before asking - [X] I have searched in the [issues](https://github.com/apache/incubator-kyuubi/issues?q=is%3Aissue) and found no similar issues. ### Describe the feature https://databricks.com/blog/2021/09/08/new-performance-improvements-in-databricks-sql.html ### Motivation Improving BI results retrieval with Cloud Fetch ### Describe the solution >Once query results are computed, the last mile is to speed up how the system delivers results to the client – typically a BI tool like PowerBI or Tableau. Legacy cloud data warehouses often collect the results on a leader (aka driver) node, and stream it back to the client. This greatly slows down the experience in your BI tool if you are fetching anything more than a few megabytes of results. > That’s why we’ve reimagined this approach with a new architecture called Cloud Fetch. For large results, Databricks SQL writes results in parallel across all of the compute nodes to cloud storage, and then sends the list of files using pre-signed URLs back to the client. The client then can download in parallel all the data from cloud storage. We are delighted to report up to 10x performance improvement in real-world customer scenarios! We are working with the most popular BI tools to enable this capability automatically. by databricks ### Additional context 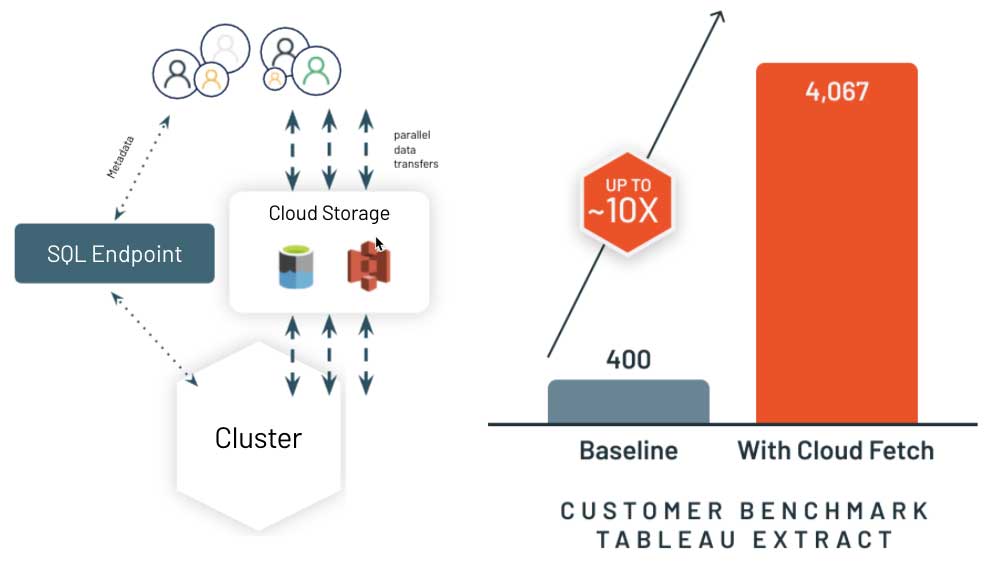 ### Are you willing to submit PR? - [ ] Yes I am willing to submit a PR! -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: [email protected] For queries about this service, please contact Infrastructure at: [email protected]
{kind=link}