[
https://issues.apache.org/jira/browse/SOLR-2155?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=12983550#action_12983550
]
David Smiley commented on SOLR-2155:
------------------------------------
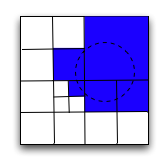
Thanks for the "Damn Cool Algorithms" aritcle! It's fantastic, I'm in
geospatial geek heaven :-) I didn't know what quadtrees were before but now I
know -- it's just a 4-ary grid instead of 32-ary which is geohash. Nick's
illustration http://static.notdot.net/uploads/geohash-query.png should be
useful for anyone coming to my code here to see how it works.
The divergent point in the article with what I'm doing is when he attempts to
limit the number of "ranges" (i.e boxes), 5 in his example. My first geohash
patch had logic akin to this in which I picked a resolution to intersect with
the query shape that limited the number of boxes. I'd seek to the next box I
needed and then iterate over the indexed terms at that box, testing to see if
it's in the query. It could potentially look at way more points than needed.
Now that I'm indexing a token for each geohash precision, I found it
straight-forward to implement a fully recursive algorithm down to the bottom
grid (or one higher than that any way). If there are no points in a given area
then it's short-circuited. The worst-case is when much of the edge of the
shape passes through densely populated points. At some point there's a
trade-off in which you pick between evaluating each point in the current box
with the queried shape versus divide & conquer. My code here is making that
decision simply by a geohash length threshold but I have some comments in there
to make estimations given certain usage scenarios (e.g. one-one relationship
between points and documents), and some sort of cost model for the query shape
complexity.
Hilbert Curves are interesting. Applying that to my code would improve box
adjacency which will reduce the number of seek() calls, which I believe is one
of the more expensive operations.
I've thought about indexing arbitrary shapes instead of being limited to
points. An indexed shape could be put into the payload of the MBR (minimum
bounding rectangle) of the grid box term covering that shape -- potentially
duplicating it twice or worst case four times depending on the ratio of its
size to intersecting grid boxes. At query time, the recursive algorithm here
would examine the payloads to perform a shape intersection. Not too hard. I
assume you are familiar with SOLR-2268 ? It seems Grant needs convincing to
use JTS due to the LGPL license.
Another thing I've been thinking about, by the way, is applying an "equal area
projection" like http://en.wikipedia.org/wiki/Gall%E2%80%93Peters_projection
Using this would enable you to get by with a smaller geohash length to meet a
certain uniform accuracy since you aren't "wasting" bits, as we are now, at the
poles. I have yet to calculate the savings, and it would add some
computational cost at indexing time, but not really at query time.
> Geospatial search using geohash prefixes
> ----------------------------------------
>
> Key: SOLR-2155
> URL: https://issues.apache.org/jira/browse/SOLR-2155
> Project: Solr
> Issue Type: Improvement
> Reporter: David Smiley
> Attachments: GeoHashPrefixFilter.patch, GeoHashPrefixFilter.patch
>
>
> There currently isn't a solution in Solr for doing geospatial filtering on
> documents that have a variable number of points. This scenario occurs when
> there is location extraction (i.e. via a "gazateer") occurring on free text.
> None, one, or many geospatial locations might be extracted from any given
> document and users want to limit their search results to those occurring in a
> user-specified area.
> I've implemented this by furthering the GeoHash based work in Lucene/Solr
> with a geohash prefix based filter. A geohash refers to a lat-lon box on the
> earth. Each successive character added further subdivides the box into a 4x8
> (or 8x4 depending on the even/odd length of the geohash) grid. The first
> step in this scheme is figuring out which geohash grid squares cover the
> user's search query. I've added various extra methods to GeoHashUtils (and
> added tests) to assist in this purpose. The next step is an actual Lucene
> Filter, GeoHashPrefixFilter, that uses these geohash prefixes in
> TermsEnum.seek() to skip to relevant grid squares in the index. Once a
> matching geohash grid is found, the points therein are compared against the
> user's query to see if it matches. I created an abstraction GeoShape
> extended by subclasses named PointDistance... and CartesianBox.... to support
> different queried shapes so that the filter need not care about these details.
> This work was presented at LuceneRevolution in Boston on October 8th.
--
This message is automatically generated by JIRA.
-
You can reply to this email to add a comment to the issue online.
---------------------------------------------------------------------
To unsubscribe, e-mail: [email protected]
For additional commands, e-mail: [email protected]
{kind=link}