jiayuasu commented on pull request #557: URL: https://github.com/apache/incubator-sedona/pull/557#issuecomment-955576126
Scala/Java test passed but Python test failed. This is possibly caused by the Spark 3.2.0 change in UnaryExecNode and BinaryExecNode. So technically, Sedona join extends a different ExecNode in Spark 3.2.0. Spark < 3.2.0 UnaryExecNode and BinaryExecNode implementation:   Spark 3.2.0 UnaryExecNode and BinaryExecNode implementation 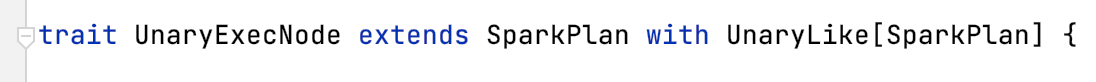  This is related to https://github.com/apache/incubator-sedona/pull/558 However, on Sedona's side, this does not require any actual code change, so Scala/Java test passed. But I don't understand why Python test cannot figure this out. @Kimahriman @Imbruced Can we figure out a solution for this? In the worst case, we have to cut a separate release that is compiled on Spark 3.2+. In short, we have to release Sedona for Spark 2.4, 3.0 (3.0-3.1), 3.2. This is a headache... -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: [email protected] For queries about this service, please contact Infrastructure at: [email protected]
{kind=link}
{kind=link}
{kind=link}
{kind=link}