This is an automated email from the ASF dual-hosted git repository.
pingsutw pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/submarine.git
The following commit(s) were added to refs/heads/master by this push:
new fb5c0f9 SUBMARINE-869. Add distributive pytorch example
fb5c0f9 is described below
commit fb5c0f9769accccf43684ad9b6e1378f02cb8bef
Author: featherchen <[email protected]>
AuthorDate: Fri Aug 27 13:13:18 2021 +0800
SUBMARINE-869. Add distributive pytorch example
### What is this PR for?
<!-- A few sentences describing the overall goals of the pull request's
commits.
First time? Check out the contributing guide -
https://submarine.apache.org/contribution/contributions.html
-->
Add pytorch distributed training example with DistributedDataParallel
strategy.
### What type of PR is it?
Improvement
### Todos
* [ ] - None
### What is the Jira issue?
<!-- * Open an issue on Jira
https://issues.apache.org/jira/browse/SUBMARINE/
* Put link here, and add [SUBMARINE-*Jira number*] in PR title, eg.
`SUBMARINE-23. PR title`
-->
https://issues.apache.org/jira/browse/SUBMARINE-869
### How should this be tested?
<!--
* First time? Setup Travis CI as described on
https://submarine.apache.org/contribution/contributions.html#continuous-integration
* Strongly recommended: add automated unit tests for any new or changed
behavior
* Outline any manual steps to test the PR here.
-->
See the vedio and README
https://www.loom.com/share/46ae1188f5fd47fd8677eb01ab5fe899
### Screenshots (if appropriate)
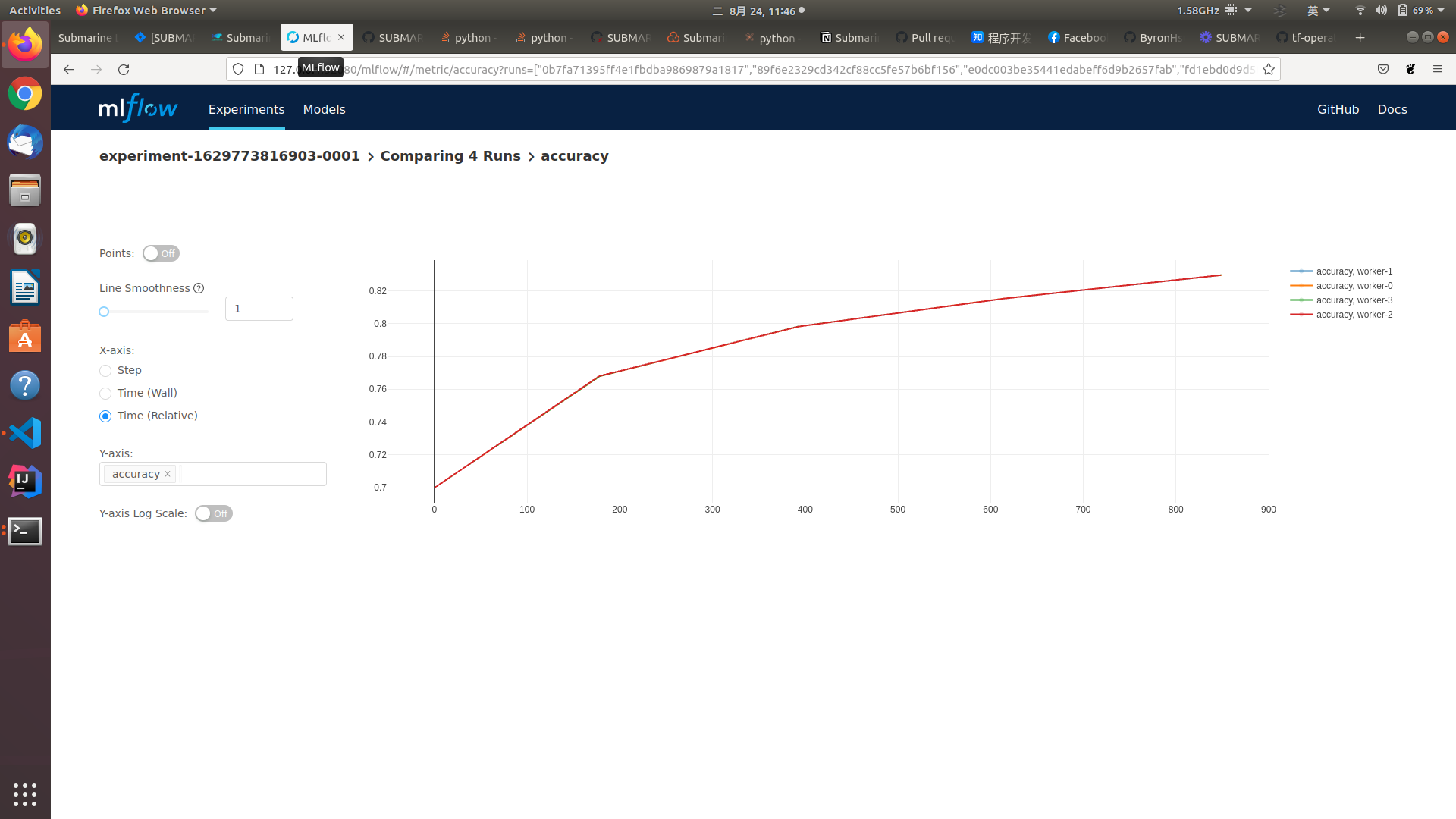
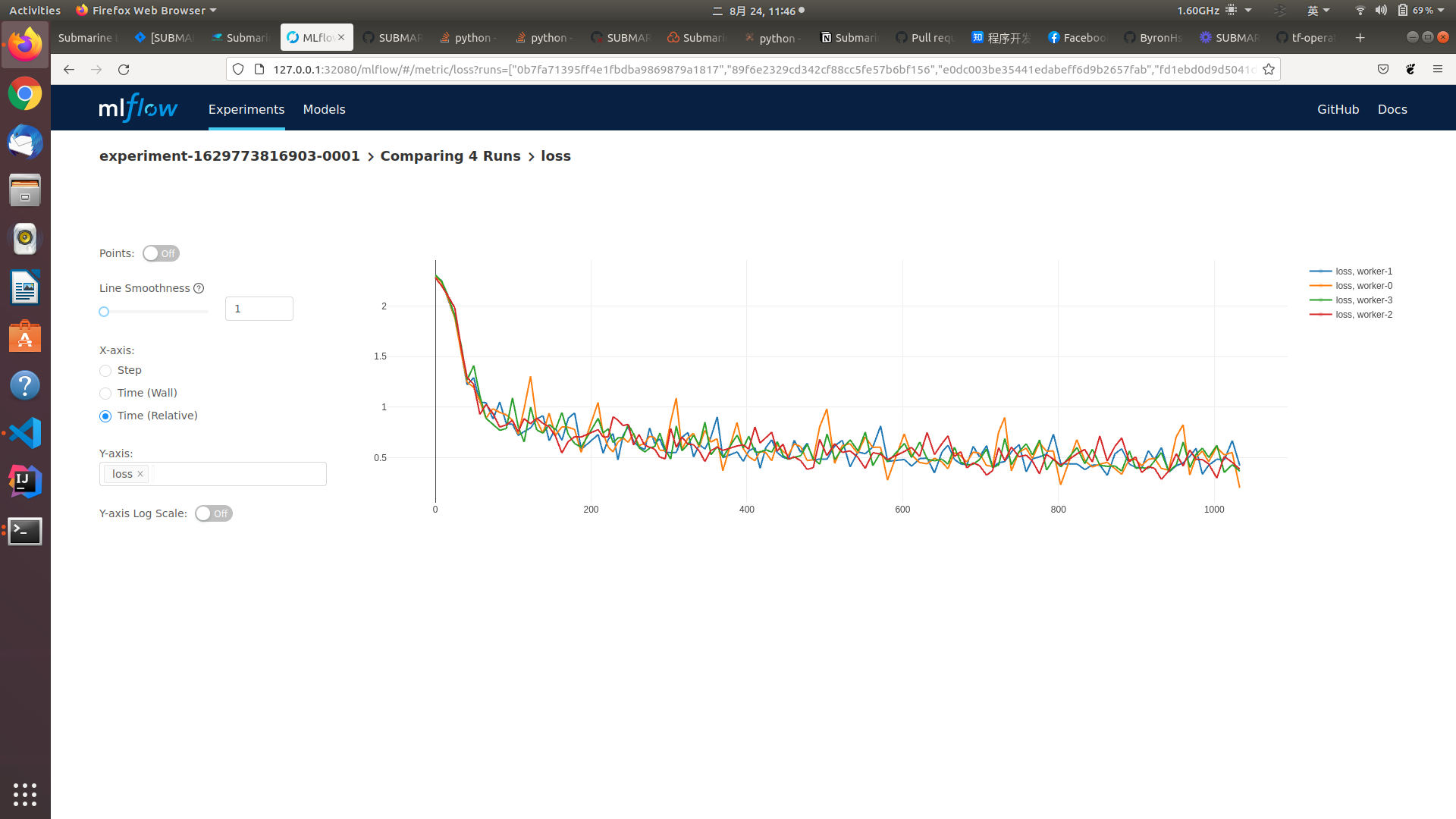
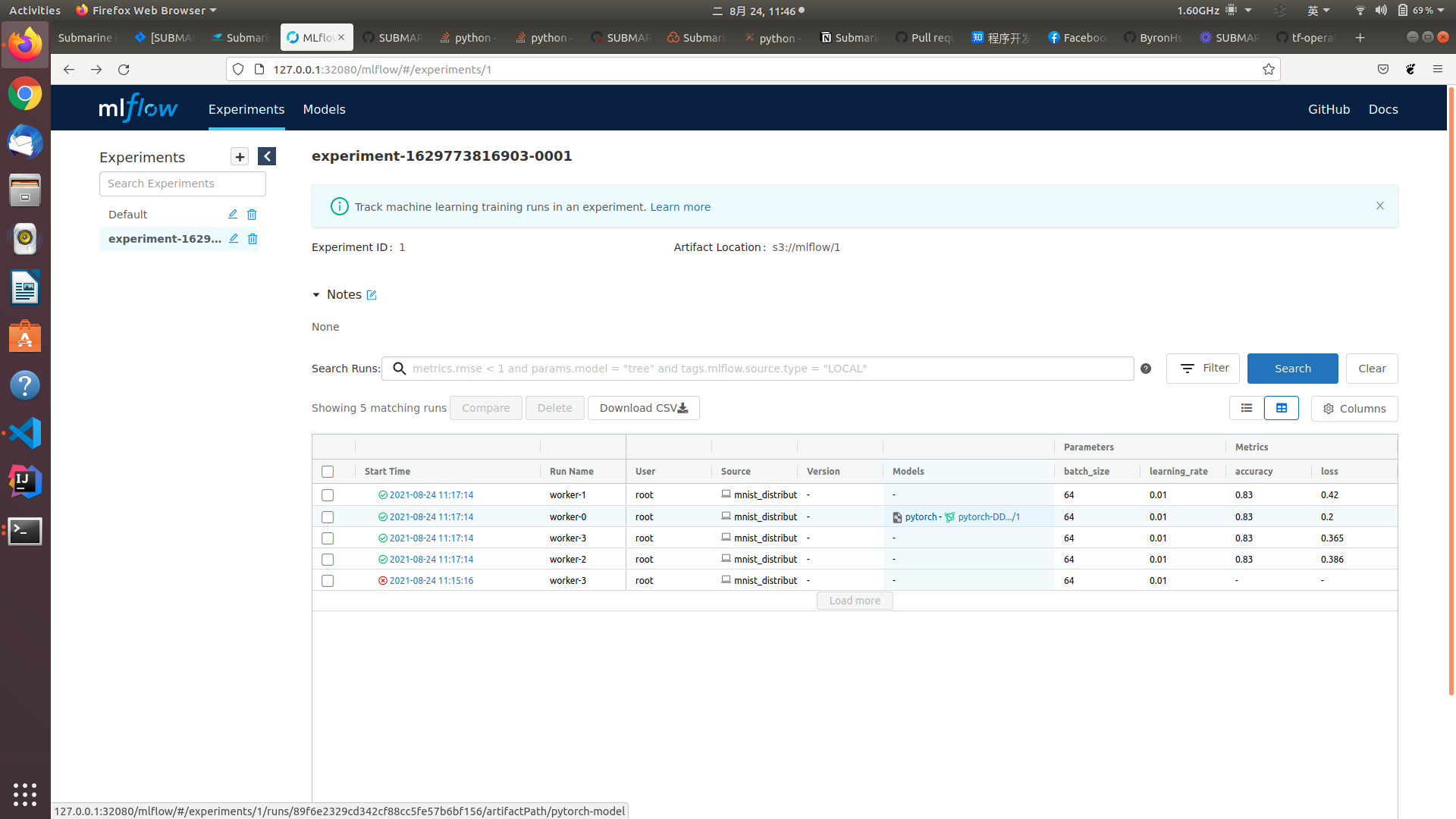
### Questions:
* Do the license files need updating? No
* Are there breaking changes for older versions? No
* Does this need new documentation? No
Author: featherchen <[email protected]>
Author: Kevin Su <[email protected]>
Signed-off-by: Kevin <[email protected]>
Closes #720 from featherchen/SUBMARINE-869 and squashes the following
commits:
04467656 [Kevin Su] Merge branch 'master' into SUBMARINE-869
949452cb [featherchen] SUBMARINE-869. delete redundant comment
e490379f [featherchen] SUBMARINE-869. README
34dc3762 [featherchen] SUBMARINE-869. DDP example
e2fccdbb [featherchen] add log_param and save_model
a95cfe9f [featherchen] DDP example
b137fbed [featherchen] distributive example
57a7e19f [featherchen] SUBMARINE-869. add pytorch operator
---
dev-support/examples/mnist-pytorch/DDP/Dockerfile | 24 +++
dev-support/examples/mnist-pytorch/DDP/build.sh | 44 +++++
.../mnist-pytorch/DDP/mnist_distributed.py | 191 +++++++++++++++++++++
dev-support/examples/mnist-pytorch/DDP/post.sh | 42 +++++
dev-support/examples/mnist-pytorch/DDP/readme.md | 25 +++
dev-support/examples/nn-pytorch/model.py | 2 +-
.../pysubmarine/submarine/models/utils.py | 5 +-
7 files changed, 328 insertions(+), 5 deletions(-)
diff --git a/dev-support/examples/mnist-pytorch/DDP/Dockerfile
b/dev-support/examples/mnist-pytorch/DDP/Dockerfile
new file mode 100644
index 0000000..e5c217a
--- /dev/null
+++ b/dev-support/examples/mnist-pytorch/DDP/Dockerfile
@@ -0,0 +1,24 @@
+# Licensed to the Apache Software Foundation (ASF) under one or more
+# contributor license agreements. See the NOTICE file distributed with
+# this work for additional information regarding copyright ownership.
+# The ASF licenses this file to You under the Apache License, Version 2.0
+# (the "License"); you may not use this file except in compliance with
+# the License. You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+FROM python:3.7
+MAINTAINER Apache Software Foundation <[email protected]>
+
+ADD ./tmp/submarine-sdk /opt/
+RUN pip install pillow==8.2.0 && \
+ pip install /opt/pysubmarine[pytorch] && \
+ pip install tensorboardX
+
+ADD ./mnist_distributed.py /opt/
\ No newline at end of file
diff --git a/dev-support/examples/mnist-pytorch/DDP/build.sh
b/dev-support/examples/mnist-pytorch/DDP/build.sh
new file mode 100755
index 0000000..84ece8f
--- /dev/null
+++ b/dev-support/examples/mnist-pytorch/DDP/build.sh
@@ -0,0 +1,44 @@
+#!/usr/bin/env bash
+# Licensed to the Apache Software Foundation (ASF) under one or more
+# contributor license agreements. See the NOTICE file distributed with
+# this work for additional information regarding copyright ownership.
+# The ASF licenses this file to You under the Apache License, Version 2.0
+# (the "License"); you may not use this file except in compliance with
+# the License. You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+set -euxo pipefail
+
+SUBMARINE_VERSION=0.6.0-SNAPSHOT
+SUBMARINE_IMAGE_NAME="ddp:${SUBMARINE_VERSION}"
+
+if [ -L ${BASH_SOURCE-$0} ]; then
+ PWD=$(dirname $(readlink "${BASH_SOURCE-$0}"))
+else
+ PWD=$(dirname ${BASH_SOURCE-$0})
+fi
+export CURRENT_PATH=$(cd "${PWD}">/dev/null; pwd)
+export SUBMARINE_HOME=${CURRENT_PATH}/../../../..
+
+if [ -d "${CURRENT_PATH}/tmp" ] # if old tmp folder is still there, delete it.
+then
+ rm -rf "${CURRENT_PATH}/tmp"
+fi
+
+mkdir -p "${CURRENT_PATH}/tmp"
+cp -r "${SUBMARINE_HOME}/submarine-sdk" "${CURRENT_PATH}/tmp"
+
+# build image
+cd ${CURRENT_PATH}
+echo "Start building the ${SUBMARINE_IMAGE_NAME} docker image ..."
+docker build -t ${SUBMARINE_IMAGE_NAME} .
+
+# clean temp file
+rm -rf "${CURRENT_PATH}/tmp"
diff --git a/dev-support/examples/mnist-pytorch/DDP/mnist_distributed.py
b/dev-support/examples/mnist-pytorch/DDP/mnist_distributed.py
new file mode 100644
index 0000000..fd24a4e
--- /dev/null
+++ b/dev-support/examples/mnist-pytorch/DDP/mnist_distributed.py
@@ -0,0 +1,191 @@
+"""
+ Licensed to the Apache Software Foundation (ASF) under one
+ or more contributor license agreements. See the NOTICE file
+ distributed with this work for additional information
+ regarding copyright ownership. The ASF licenses this file
+ to you under the Apache License, Version 2.0 (the
+ "License"); you may not use this file except in compliance
+ with the License. You may obtain a copy of the License at
+ http://www.apache.org/licenses/LICENSE-2.0
+ Unless required by applicable law or agreed to in writing,
+ software distributed under the License is distributed on an
+ "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ KIND, either express or implied. See the License for the
+ specific language governing permissions and limitations
+ under the License.
+"""
+
+from __future__ import print_function
+from submarine import ModelsClient
+
+import argparse
+import os
+
+from tensorboardX import SummaryWriter
+from torchvision import datasets, transforms
+import torch
+import torch.distributed as dist
+import torch.nn as nn
+import torch.nn.functional as F
+import torch.optim as optim
+
+WORLD_SIZE = int(os.environ.get('WORLD_SIZE', 1))
+rank = int(os.environ.get('RANK', 0))
+
+print('WORLD={} , RANK={}'.format(WORLD_SIZE,rank))
+class Net(nn.Module):
+ def __init__(self):
+ super(Net, self).__init__()
+ self.conv1 = nn.Conv2d(1, 20, 5, 1)
+ self.conv2 = nn.Conv2d(20, 50, 5, 1)
+ self.fc1 = nn.Linear(4*4*50, 500)
+ self.fc2 = nn.Linear(500, 10)
+
+ def forward(self, x):
+ x = F.relu(self.conv1(x))
+ x = F.max_pool2d(x, 2, 2)
+ x = F.relu(self.conv2(x))
+ x = F.max_pool2d(x, 2, 2)
+ x = x.view(-1, 4*4*50)
+ x = F.relu(self.fc1(x))
+ x = self.fc2(x)
+ return F.log_softmax(x, dim=1)
+
+def train(args, model, device, train_loader, optimizer, epoch, writer,
periscope):
+ model.train()
+ for batch_idx, (data, target) in enumerate(train_loader):
+ data, target = data.to(device), target.to(device)
+ optimizer.zero_grad()
+ output = model(data)
+ loss = F.nll_loss(output, target)
+ loss.backward()
+ optimizer.step()
+ if batch_idx % args.log_interval == 0:
+ print('Train Epoch: {} [{}/{} ({:.0f}%)]\tloss={:.4f}'.format(
+ epoch, batch_idx * len(data), len(train_loader.dataset),
+ 100. * batch_idx / len(train_loader), loss.item()))
+ niter = epoch * len(train_loader) + batch_idx
+ writer.add_scalar('loss', loss.item(), niter)
+ periscope.log_metric('loss', loss.item(), niter)
+
+def test(args, model, device, test_loader, writer, epoch, periscope):
+ model.eval()
+ test_loss = 0
+ correct = 0
+ with torch.no_grad():
+ for data, target in test_loader:
+ data, target = data.to(device), target.to(device)
+ output = model(data)
+ test_loss += F.nll_loss(output, target, reduction='sum').item() #
sum up batch loss
+ pred = output.max(1, keepdim=True)[1] # get the index of the max
log-probability
+ correct += pred.eq(target.view_as(pred)).sum().item()
+
+ test_loss /= len(test_loader.dataset)
+ print('\naccuracy={:.4f}\n'.format(float(correct) /
len(test_loader.dataset)))
+ writer.add_scalar('accuracy', float(correct) / len(test_loader.dataset),
epoch)
+ periscope.log_metric('accuracy', float(correct) /
len(test_loader.dataset), epoch)
+
+def should_distribute():
+ return dist.is_available() and WORLD_SIZE > 1
+
+
+def is_distributed():
+ return dist.is_available() and dist.is_initialized()
+
+
+if __name__ == '__main__':
+ # Training settings
+ parser = argparse.ArgumentParser(description='PyTorch MNIST Example')
+ parser.add_argument('--batch-size', type=int, default=64, metavar='N',
+ help='input batch size for training (default: 64)')
+ parser.add_argument('--test-batch-size', type=int, default=1000,
metavar='N',
+ help='input batch size for testing (default: 1000)')
+ parser.add_argument('--epochs', type=int, default=5, metavar='N',
+ help='number of epochs to train (default: 5)')
+ parser.add_argument('--lr', type=float, default=0.01, metavar='LR',
+ help='learning rate (default: 0.01)')
+ parser.add_argument('--momentum', type=float, default=0.5, metavar='M',
+ help='SGD momentum (default: 0.5)')
+ parser.add_argument('--no-cuda', action='store_true', default=False,
+ help='disables CUDA training')
+ parser.add_argument('--seed', type=int, default=1, metavar='S',
+ help='random seed (default: 1)')
+ parser.add_argument('--log-interval', type=int, default=10, metavar='N',
+ help='how many batches to wait before logging training
status')
+ parser.add_argument('--save-model', action='store_true', default=False,
+ help='For Saving the current Model')
+ parser.add_argument('--dir', default='logs', metavar='L',
+ help='directory where summary logs are stored')
+ if dist.is_available():
+ parser.add_argument('--backend', type=str, help='Distributed backend',
+ choices=[dist.Backend.GLOO, dist.Backend.NCCL,
dist.Backend.MPI],
+ default=dist.Backend.GLOO)
+ args = parser.parse_args()
+ use_cuda = not args.no_cuda and torch.cuda.is_available()
+ if use_cuda:
+ print('Using CUDA')
+ else :
+ print('Not Using CUDA')
+
+ writer = SummaryWriter(args.dir)
+
+ torch.manual_seed(args.seed)
+
+ device = torch.device("cuda" if use_cuda else "cpu")
+
+ if should_distribute():
+ print('Using distributed PyTorch with {} backend'.format(args.backend))
+ dist.init_process_group(
+ backend=args.backend,
+ world_size=WORLD_SIZE,
+ rank=rank)
+
+ kwargs = {'num_workers': 1, 'pin_memory': True} if use_cuda else {}
+
+ train_dataset = datasets.FashionMNIST('../data', train=True, download=True,
+ transform=transforms.Compose([
+ transforms.ToTensor(),
+ transforms.Normalize((0.1307,), (0.3081,))
+ ]))
+ train_sampler = torch.utils.data.distributed.DistributedSampler(
+ train_dataset,
+ num_replicas = WORLD_SIZE,
+ rank=rank
+ )
+
+ train_loader = torch.utils.data.DataLoader(
+ dataset = train_dataset,
+ batch_size = args.batch_size,
+ shuffle = False,
+ sampler = train_sampler,
+ **kwargs)
+
+ test_loader = torch.utils.data.DataLoader(
+ datasets.FashionMNIST('../data', train=False,
transform=transforms.Compose([
+ transforms.ToTensor(),
+ transforms.Normalize((0.1307,), (0.3081,))
+ ])),
+ batch_size=args.test_batch_size, shuffle=False, **kwargs)
+
+ model = Net().to(device)
+
+ if is_distributed():
+ Distributor = nn.parallel.DistributedDataParallel if use_cuda \
+ else nn.parallel.DistributedDataParallelCPU
+ model = Distributor(model)
+
+ optimizer = optim.SGD(model.parameters(), lr=args.lr,
momentum=args.momentum)
+ periscope = ModelsClient()
+ with periscope.start() as run:
+ periscope.log_param("learning_rate", args.lr)
+ periscope.log_param("batch_size", args.batch_size)
+ for epoch in range(1, args.epochs + 1):
+ train(args, model, device, train_loader, optimizer, epoch, writer,
periscope)
+ test(args, model, device, test_loader, writer, epoch, periscope)
+ if (args.save_model):
+ torch.save(model.state_dict(),"mnist_cnn.pt")
+
+"""
+Reference:
+https://github.com/kubeflow/pytorch-operator/blob/master/examples/mnist/mnist.py
+"""
\ No newline at end of file
diff --git a/dev-support/examples/mnist-pytorch/DDP/post.sh
b/dev-support/examples/mnist-pytorch/DDP/post.sh
new file mode 100755
index 0000000..ec2d0cf
--- /dev/null
+++ b/dev-support/examples/mnist-pytorch/DDP/post.sh
@@ -0,0 +1,42 @@
+#!/usr/bin/env bash
+# Licensed to the Apache Software Foundation (ASF) under one or more
+# contributor license agreements. See the NOTICE file distributed with
+# this work for additional information regarding copyright ownership.
+# The ASF licenses this file to You under the Apache License, Version 2.0
+# (the "License"); you may not use this file except in compliance with
+# the License. You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+curl -X POST -H "Content-Type: application/json" -d '
+{
+ "meta": {
+ "name": "ddp-example",
+ "namespace": "default",
+ "framework": "PyTorch",
+ "cmd": "python /opt/mnist_distributed.py",
+ "envVars": {
+ "ENV_1": "ENV1"
+ }
+ },
+ "environment": {
+ "image": "ddp:0.6.0-SNAPSHOT"
+ },
+ "spec": {
+ "Master": {
+ "replicas": 1,
+ "resources": "cpu=1,memory=128M"
+ },
+ "Worker": {
+ "replicas": 3,
+ "resources": "cpu=1,memory=128M"
+ }
+ }
+}
+' http://127.0.0.1:32080/api/v1/experiment
\ No newline at end of file
diff --git a/dev-support/examples/mnist-pytorch/DDP/readme.md
b/dev-support/examples/mnist-pytorch/DDP/readme.md
new file mode 100644
index 0000000..ffa145c
--- /dev/null
+++ b/dev-support/examples/mnist-pytorch/DDP/readme.md
@@ -0,0 +1,25 @@
+# Pytorch DistributedDataParallel(DDP) Example
+
+## Usage
+
+This is an easy mnist example of how to train a distributed pytorch model
using DistributedDataParallel(DDP) method and track the metric and paramater in
submarine-sdk.
+
+## How to execute
+
+0. Set up (for a single terminal, only need to do this one time)
+
+```bash
+eval $(minikube -p minikube docker-env)
+```
+
+1. Build the docker image
+
+```bash
+./dev-support/examples/mnist-pytorch/DDP/build.sh
+```
+
+2. Submit a post request
+
+```bash
+./dev-support/examples/mnist-pytorch/DDP/post.sh
+```
diff --git a/dev-support/examples/nn-pytorch/model.py
b/dev-support/examples/nn-pytorch/model.py
index 6080c4a..10ef94b 100644
--- a/dev-support/examples/nn-pytorch/model.py
+++ b/dev-support/examples/nn-pytorch/model.py
@@ -32,4 +32,4 @@ class LinearNNModel(torch.nn.Module):
if __name__ == "__main__":
client = ModelsClient()
net = LinearNNModel()
- client.save_model(model_type = "pytorch", model = net,
artifact_path="pytorch-nn-model", registered_model_name="simple-nn-model")
\ No newline at end of file
+ client.save_model(model_type = "pytorch", model = net,
artifact_path="pytorch-nn-model", registered_model_name="simple-nn-model")
diff --git a/submarine-sdk/pysubmarine/submarine/models/utils.py
b/submarine-sdk/pysubmarine/submarine/models/utils.py
index 20bb277..d8281a0 100644
--- a/submarine-sdk/pysubmarine/submarine/models/utils.py
+++ b/submarine-sdk/pysubmarine/submarine/models/utils.py
@@ -68,10 +68,7 @@ def get_worker_index():
# Get PyTorch worker index
elif env.get_env(_RANK) is not None:
rank = env.get_env(_RANK)
- if rank == "0":
- worker_index = "master-0"
- else:
- worker_index = "worker-" + rank
+ worker_index = "worker-" + rank
# Set worker index to "worker-0" When running local training
else:
worker_index = "worker-0"
---------------------------------------------------------------------
To unsubscribe, e-mail: [email protected]
For additional commands, e-mail: [email protected]
{kind=link}
{kind=link}
{kind=link}