Tensor Core is a defining feature of the NVIDIA new Volta and Turing GPU Architecture, which gives a massive boost for matrix multiplication and convolution. Tensor Cores enable us to use mixed-precision to achieve higher throughput without sacrificing accuracy.
## Tensor Core Overview Each Tensor Core provides a 4×4×4 matrix processing array that operates `D = A * B + C`, where `A`, `B`, `C` and `D` are 4×4 matrices as Figure shows. The matrix multiply inputs A and B are FP16 matrices, while the accumulation matrices C and D may be FP16 or FP32 matrices. 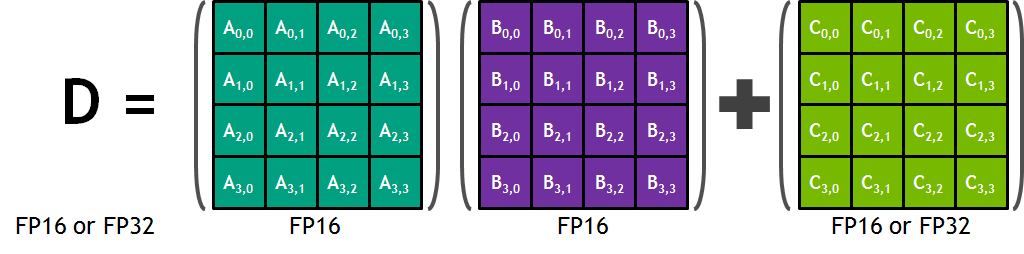 However, CUDA programmers can only use warp-level primitive `wmma::mma_sync(acc_frag, a_frag, b_frag, acc_frag)` to perform 16×16×16 half-precision matrix multiplication on tensor cores. Before invoking the matrix multiplication, programmers must load data from memory into registers with primitive `wmma::load_matrix_sync`, explicitly. The NVCC compiler translates that primitive into multiple memory load instructions. At run time, every thread loads 16 elements from matrix A and 16 elements from B. # Proposed Design It can be regarded as a new hardware instruction just like gemm instruction in vta. So it is easy to use `tensorization` to replace the code. Note that unlike other accelerators, we need also to consider the shared memory when we use tensor cores. Also, `wmma::mma_sync` is a wrap-level instruction, which means it will call all threads (32 threads) in a warp. It is a brand new schedule level. ## Warp Level Schedule Although `wmma::mma_sync` is a warp-level operator, NVIDIA doesn't change the API for kernel launch. It still uses `gridDim`, `blockDim` and `dynamic shared memory` (optional) to launch a kernel. The only thing we should do is ensuring `blockDim.x` be a multiple of warp size(32). In tvm schedule, we can just make the extent of `threadIdx.x` equals 32. It's safe if we want to use `threadIdx.y` and `threadIdx.z`, and their extents have no extra constraint. Note that, `threadIdx.x` can be only used at memory copy or other thread-level operators. ## New Memory Scope As mentioned above, programmers must load data from memory into a new memory scope `wmma::fragment` before using `wmma::mma_sync`. There are three types of fragment: `matrix_a`, `matrix_b` and `accumulator`. So I create three new build-in memory scope in tvm: `wmma.matrix_a`, `wmma.matrix_b` and `wmma.accumulator`. ## Memory layout For now, we must relayout before launching the kernel. The input and output matrix shape is `[n //16, m //16, 16, 16]`, which is the same as the vta input and output. The native Cuda API does support the native shape of [n, m], so we can drop this constraint. ## Tensor Intrinsic Here is a tensor intrinsic example for mma_sync ```python def intrin_wmma_gemm(): n = 16 A = tvm.placeholder((n, n), name='A', dtype='float16') B = tvm.placeholder((n, n), name='B', dtype='float16') k = tvm.reduce_axis((0, n), name="k") C = tvm.compute((n, n), lambda ii, jj: tvm.sum(A[ii, k].astype('float') * B[k, jj].astype('float'), axis=k), name='C') BA = tvm.decl_buffer(A.shape, A.dtype, name='BA', scope='wmma.matrix_a', data_alignment=32, offset_factor=256) BB = tvm.decl_buffer(B.shape, B.dtype, name='BB', scope='wmma.matrix_b', data_alignment=32, offset_factor=256) BC = tvm.decl_buffer(C.shape, C.dtype, name='BC', scope='wmma.accumulator', data_alignment=32, offset_factor=256) def intrin_func(ins, outs): BA, BB = ins BC, = outs def init(): ib = tvm.ir_builder.create() ib.emit(tvm.call_intrin('handle', 'tvm_fill_fragment', BC.data, BC.elem_offset // 256, 0.0)) return ib.get() def update(): ib = tvm.ir_builder.create() ib.emit(tvm.call_intrin('handle', 'tvm_mma_sync', BC.data, BC.elem_offset // 256, BA.data, BA.elem_offset // 256, BB.data, BB.elem_offset // 256, BC.data, BC.elem_offset // 256)) return ib.get() return update(), init(), update() return tvm.decl_tensor_intrin(C.op, intrin_func, binds={A: BA, B: BB, C: BC}) ``` # Performance The speed test of 4096×4096×4096 mixed-precision matrix multiplication. The test is running on a TITAN V GPU - tvm w/o tensor core: 11.7415 ms - cublas w/o tensor core: 11.462592 ms - tvm w/ tensor core: 2.795257 ms - cublas w/ tensor core: 1.787328 ms # Roadmap - [x] schedule for gemm - [ ] schedule for conv2d - [ ] add support for col-major matrix - [ ] add support for native layout # Example code and schedule https://gist.github.com/Hzfengsy/2b13215a926ae439515cc70b4e7027e3 Comments welcome! cc @tqchen @tmoreau89 @merrymercy -- You are receiving this because you are subscribed to this thread. Reply to this email directly or view it on GitHub: https://github.com/dmlc/tvm/issues/4052
{kind=link}