Hi all, +1 for a hybrid solution. But still a -1 for using skewness even in the hybrid solution :D
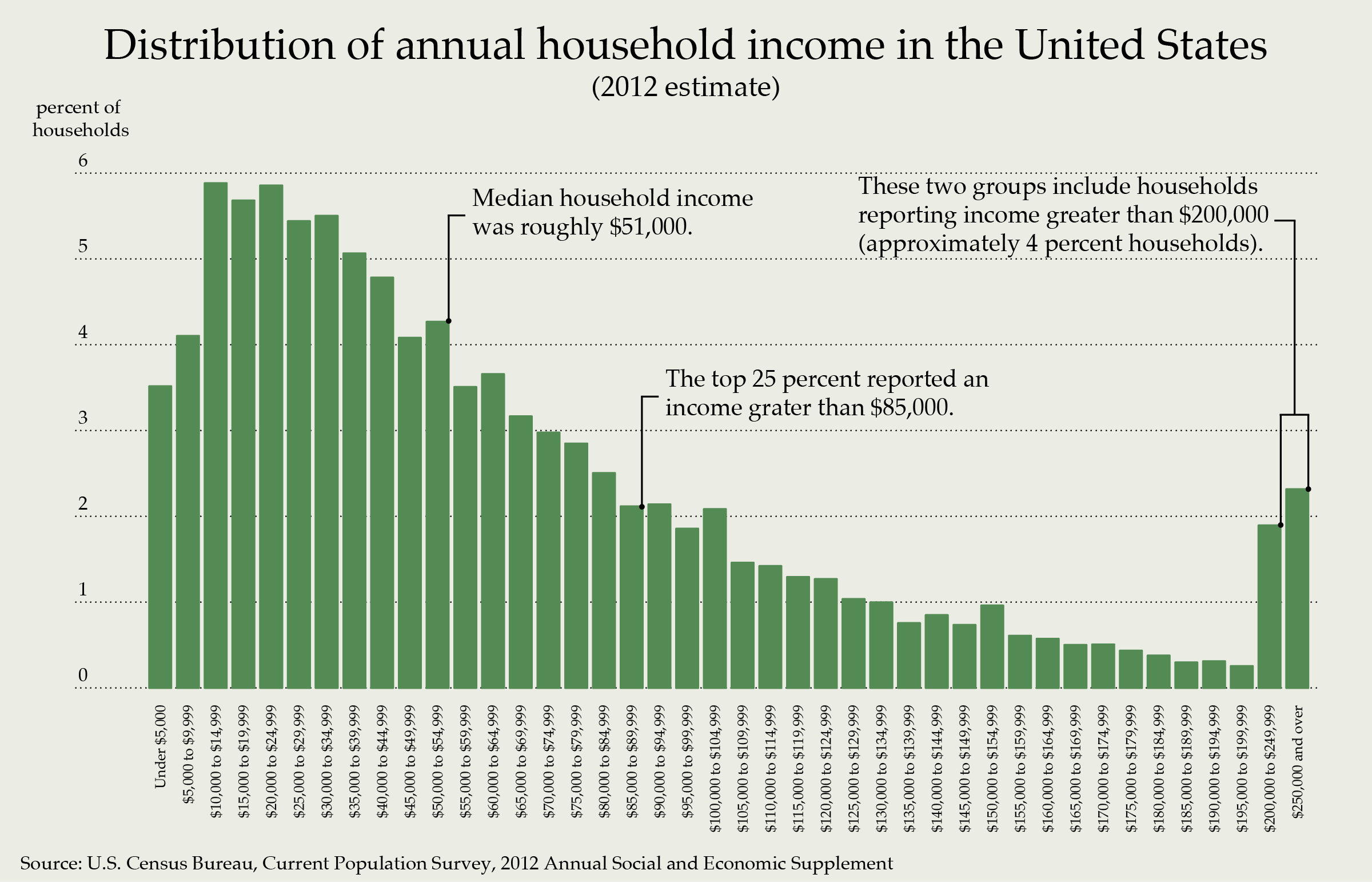
One good example why we shouldn't use skenwness is the income distribution graph in [1]. There, regardless of whether Im using the raw data (then its a continuous feature) or whether Im breaking them in to intervals and categorized the income in to several levels, I would get the same shape for the distribution. i.e skewness would be significant. So the point Im trying to make is, categorical features as well as a continuous features can be skewed/symmetric, and we cant really distinguish. [1] https://cdn2.vox-cdn.com/uploads/chorus_asset/file/2930990/Distribution_of_Annual_Household_Income_in_the_United_States_2012.0.png On Fri, Aug 14, 2015 at 1:03 AM, Nirmal Fernando <[email protected]> wrote: > Thanks Thushan. Good suggestion on the frequency. > > *solutions* > > 1. Categorical threshold: if # of distinct values are less than X, it is a > categorical feature. > 2. Make all features with only integers (no decimals) categorical. > 3. Skewness: if skewness of a distribution of a feature is less than X, it > is a categorical feature. > 4. Gaps between consecutive distinct values > 5. Frequency of distinct values - if they repeat enough, then it is a > categorical feature. > 6. Combined solution > > So, I guess as suggested by many of you, we need to build a combined > solution. > > On Fri, Aug 14, 2015 at 10:29 AM, Thushan Ganegedara <[email protected]> > wrote: > >> Moreover, I think a hybrid approach as follows might work well. >> >> 1. Select a sample >> >> 2. Filter columns by the data type and find potential categorical >> variables (integer / string) >> >> 3. Filter further by checking if same values are repeated multiple times >> in the dataset. >> >> On Fri, Aug 14, 2015 at 2:53 PM, Nirmal Fernando <[email protected]> wrote: >> >>> Thanks for all the input. >>> >>> So let me summarise; >>> >>> *the problem* >>> >>> * We need to determine whether a feature is a categorical one or not, to >>> draw certain graphs to explore a dataset, before a user starts to build >>> analyses (before user input). >>> * We can't get a 100% accuracy, hence it is of course a suggestion that >>> we do. >>> * Question is, what would be the most accurate method. >>> >>> *solutions* >>> >>> 1. Categorical threshold: if # of distinct values are less than X, it is >>> a categorical feature. >>> 2. Make all features with only integers (no decimals) categorical. >>> 3. Skewness: if skewness of a distribution of a feature is less than X, >>> it is a categorical feature. >>> 4. Gaps between consecutive distinct values >>> 5. Combined solution >>> >>> On Fri, Aug 14, 2015 at 9:33 AM, Maheshakya Wijewardena < >>> [email protected]> wrote: >>> >>>> Another approach to distinguish between categorical and numerical >>>> features can be elaborated as follows: >>>> >>>> First, we take out the unique values from the column and sort them. If >>>> it's a categorical feature, then the gaps between the elements of this >>>> sorted list should be equal. In a numerical feature, this is extremely >>>> unlikely to happen. This behavior of valid in most scenarios, but there are >>>> a few exceptions as well. eg: when a numerical ID is used as the >>>> categorical label - 19933, 19913, 18832, ... >>>> >>>> This is a very simple hack that can be easily implemented, but not a >>>> standard technique. >>>> >>>> WDYT? >>>> >>>> On Fri, Aug 14, 2015 at 8:55 AM, Srinath Perera <[email protected]> >>>> wrote: >>>> >>>>> I mean current approach and skewness? >>>>> >>>>> On Fri, Aug 14, 2015 at 8:54 AM, Srinath Perera <[email protected]> >>>>> wrote: >>>>> >>>>>> Can we use a combination of both? >>>>>> >>>>>> On Thu, Aug 13, 2015 at 8:46 PM, Supun Sethunga <[email protected]> >>>>>> wrote: >>>>>> >>>>>>> When a dataset is large, in general its said to be approximates to a >>>>>>> Normal Distribution. :) True it Hypothetical, but the point they make >>>>>>> is, >>>>>>> when the datasets are large, then properties of a distribution like >>>>>>> skewness, variance and etc. become closer to the properties Normal >>>>>>> Distribution in most cases.. >>>>>>> >>>>>>> On Thu, Aug 13, 2015 at 11:07 AM, Nirmal Fernando <[email protected]> >>>>>>> wrote: >>>>>>> >>>>>>>> Hi Supun, >>>>>>>> >>>>>>>> Thanks for the reply. >>>>>>>> >>>>>>>> On Thu, Aug 13, 2015 at 8:09 PM, Supun Sethunga <[email protected]> >>>>>>>> wrote: >>>>>>>> >>>>>>>>> Hi Nirmal, >>>>>>>>> >>>>>>>>> IMO don't think we would be able to use skewness in this case. >>>>>>>>> Skewness says how symmetric the distribution is. For example, if we >>>>>>>>> consider a numerical/continuous feature (not categorical) which is >>>>>>>>> Normally >>>>>>>>> Distributed, then the skewness would be 0. Also for a categorical >>>>>>>>> (encoded) >>>>>>>>> feature having a systematic distribution, then again the skewness >>>>>>>>> would be >>>>>>>>> 0. >>>>>>>>> >>>>>>>> >>>>>>>> What's the probability of you see a normal distribution of a real >>>>>>>> dataset? IMO it's very less and also since what we're doing here is a >>>>>>>> suggestion, do you see it as an issue? >>>>>>>> >>>>>>>> >>>>>>>>> >>>>>>>>> We did have this concern at the beginning as well, regarding how >>>>>>>>> we could determine whether a feature is categorical or Continuous. >>>>>>>>> Usually >>>>>>>>> this is strictly dependent on the domain of the dataset (i.e. user >>>>>>>>> have to >>>>>>>>> decide this with the knowledge about the data). That was the idea >>>>>>>>> behind >>>>>>>>> letting user change the data type.. But since we needed a default >>>>>>>>> option, >>>>>>>>> we had to go for the threshold thing, which was the olny option we >>>>>>>>> could >>>>>>>>> come-up with. I did a bit of research on this too, but only to find no >>>>>>>>> other solution :( >>>>>>>>> >>>>>>>>> Thanks, >>>>>>>>> Supun >>>>>>>>> >>>>>>>>> On Thu, Aug 13, 2015 at 1:49 AM, Nirmal Fernando <[email protected]> >>>>>>>>> wrote: >>>>>>>>> >>>>>>>>>> Hi All, >>>>>>>>>> >>>>>>>>>> We have a feature in ML where we suggest a given data column of a >>>>>>>>>> dataset is categorical or numerical. Currently, how we determine >>>>>>>>>> this is by >>>>>>>>>> using a threshold value (The maximum number of categories that >>>>>>>>>> can have in a non-string categorical feature. If exceeds, the >>>>>>>>>> feature will be treated as a numerical feature.). But this is >>>>>>>>>> not a successful measurement for most of the datasets. >>>>>>>>>> >>>>>>>>>> Can we use 'skewness' of a distribution as a measurement to >>>>>>>>>> determine this? Can we say, a column is numerical, if the modulus of >>>>>>>>>> the >>>>>>>>>> skewness of the distribution is less than a certain threshold (say >>>>>>>>>> 0.01) ? >>>>>>>>>> >>>>>>>>>> *References*: >>>>>>>>>> >>>>>>>>>> http://www.itrcweb.org/gsmc-1/Content/GW%20Stats/5%20Methods%20in%20indiv%20Topics/5%206%20Distributional%20Tests.htm >>>>>>>>>> >>>>>>>>>> -- >>>>>>>>>> >>>>>>>>>> Thanks & regards, >>>>>>>>>> Nirmal >>>>>>>>>> >>>>>>>>>> Team Lead - WSO2 Machine Learner >>>>>>>>>> Associate Technical Lead - Data Technologies Team, WSO2 Inc. >>>>>>>>>> Mobile: +94715779733 >>>>>>>>>> Blog: http://nirmalfdo.blogspot.com/ >>>>>>>>>> >>>>>>>>>> >>>>>>>>>> >>>>>>>>> >>>>>>>>> >>>>>>>>> -- >>>>>>>>> *Supun Sethunga* >>>>>>>>> Software Engineer >>>>>>>>> WSO2, Inc. >>>>>>>>> http://wso2.com/ >>>>>>>>> lean | enterprise | middleware >>>>>>>>> Mobile : +94 716546324 >>>>>>>>> >>>>>>>> >>>>>>>> >>>>>>>> >>>>>>>> -- >>>>>>>> >>>>>>>> Thanks & regards, >>>>>>>> Nirmal >>>>>>>> >>>>>>>> Team Lead - WSO2 Machine Learner >>>>>>>> Associate Technical Lead - Data Technologies Team, WSO2 Inc. >>>>>>>> Mobile: +94715779733 >>>>>>>> Blog: http://nirmalfdo.blogspot.com/ >>>>>>>> >>>>>>>> >>>>>>>> >>>>>>> >>>>>>> >>>>>>> -- >>>>>>> *Supun Sethunga* >>>>>>> Software Engineer >>>>>>> WSO2, Inc. >>>>>>> http://wso2.com/ >>>>>>> lean | enterprise | middleware >>>>>>> Mobile : +94 716546324 >>>>>>> >>>>>> >>>>>> >>>>>> >>>>>> -- >>>>>> ============================ >>>>>> Blog: http://srinathsview.blogspot.com twitter:@srinath_perera >>>>>> Site: http://people.apache.org/~hemapani/ >>>>>> Photos: http://www.flickr.com/photos/hemapani/ >>>>>> Phone: 0772360902 >>>>>> >>>>> >>>>> >>>>> >>>>> -- >>>>> ============================ >>>>> Blog: http://srinathsview.blogspot.com twitter:@srinath_perera >>>>> Site: http://people.apache.org/~hemapani/ >>>>> Photos: http://www.flickr.com/photos/hemapani/ >>>>> Phone: 0772360902 >>>>> >>>> >>>> >>>> >>>> -- >>>> Pruthuvi Maheshakya Wijewardena >>>> Software Engineer >>>> WSO2 : http://wso2.com/ >>>> Email: [email protected] >>>> Mobile: +94711228855 >>>> >>>> >>>> >>> >>> >>> -- >>> >>> Thanks & regards, >>> Nirmal >>> >>> Team Lead - WSO2 Machine Learner >>> Associate Technical Lead - Data Technologies Team, WSO2 Inc. >>> Mobile: +94715779733 >>> Blog: http://nirmalfdo.blogspot.com/ >>> >>> >>> >>> _______________________________________________ >>> Dev mailing list >>> [email protected] >>> http://wso2.org/cgi-bin/mailman/listinfo/dev >>> >>> >> >> >> -- >> Regards, >> >> Thushan Ganegedara >> School of IT >> University of Sydney, Australia >> > > > > -- > > Thanks & regards, > Nirmal > > Team Lead - WSO2 Machine Learner > Associate Technical Lead - Data Technologies Team, WSO2 Inc. > Mobile: +94715779733 > Blog: http://nirmalfdo.blogspot.com/ > > > > _______________________________________________ > Dev mailing list > [email protected] > http://wso2.org/cgi-bin/mailman/listinfo/dev > > -- *Supun Sethunga* Software Engineer WSO2, Inc. http://wso2.com/ lean | enterprise | middleware Mobile : +94 716546324
{kind=link}
_______________________________________________ Dev mailing list [email protected] http://wso2.org/cgi-bin/mailman/listinfo/dev