On Friday, 12 September 2014 at 07:57:43 UTC, Ali Çehreli wrote:
On 09/11/2014 11:38 PM, AsmMan wrote:> If I want ASCII and latin only alphabet which range should I use? > ie, how should I rewrite is_id() function? This seems to be it: import std.stdio; import std.uni; void main() { alias latin = unicode.script.latin; assert('ç' in latin); assert('7' !in latin); writeln(latin); } Ali
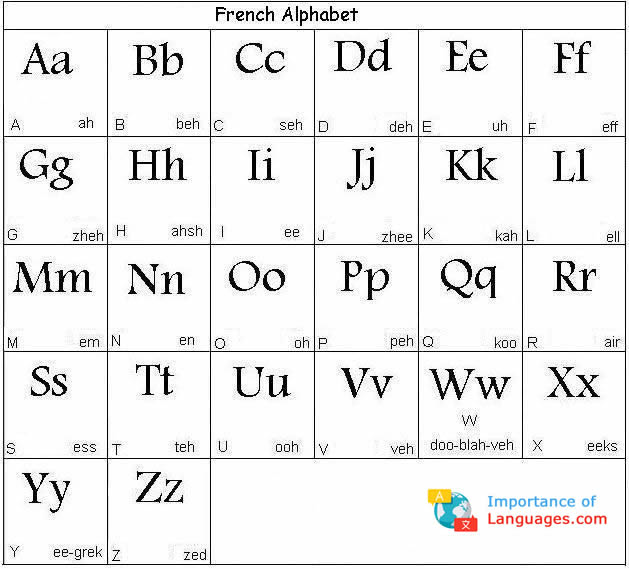
Sorry, I shouldn't asked for latin but an alphabet like French instead of: http://www.importanceoflanguages.com/Images/French/FrenchAlphabet.jpg (including the diacritics, of course)
{kind=link}
As you mentioned, º happend to be a letter so it still pass in: assert('º' in latin);
so isn't different from isAlpha(). Is the UTF-8 table organized so that I can use a range (like we do for ASCII ch >= 'a' && ch <= 'z' || ch >= 'A' && ch <= 'Z') or should I put these alpha characters myself on table and then do look up?