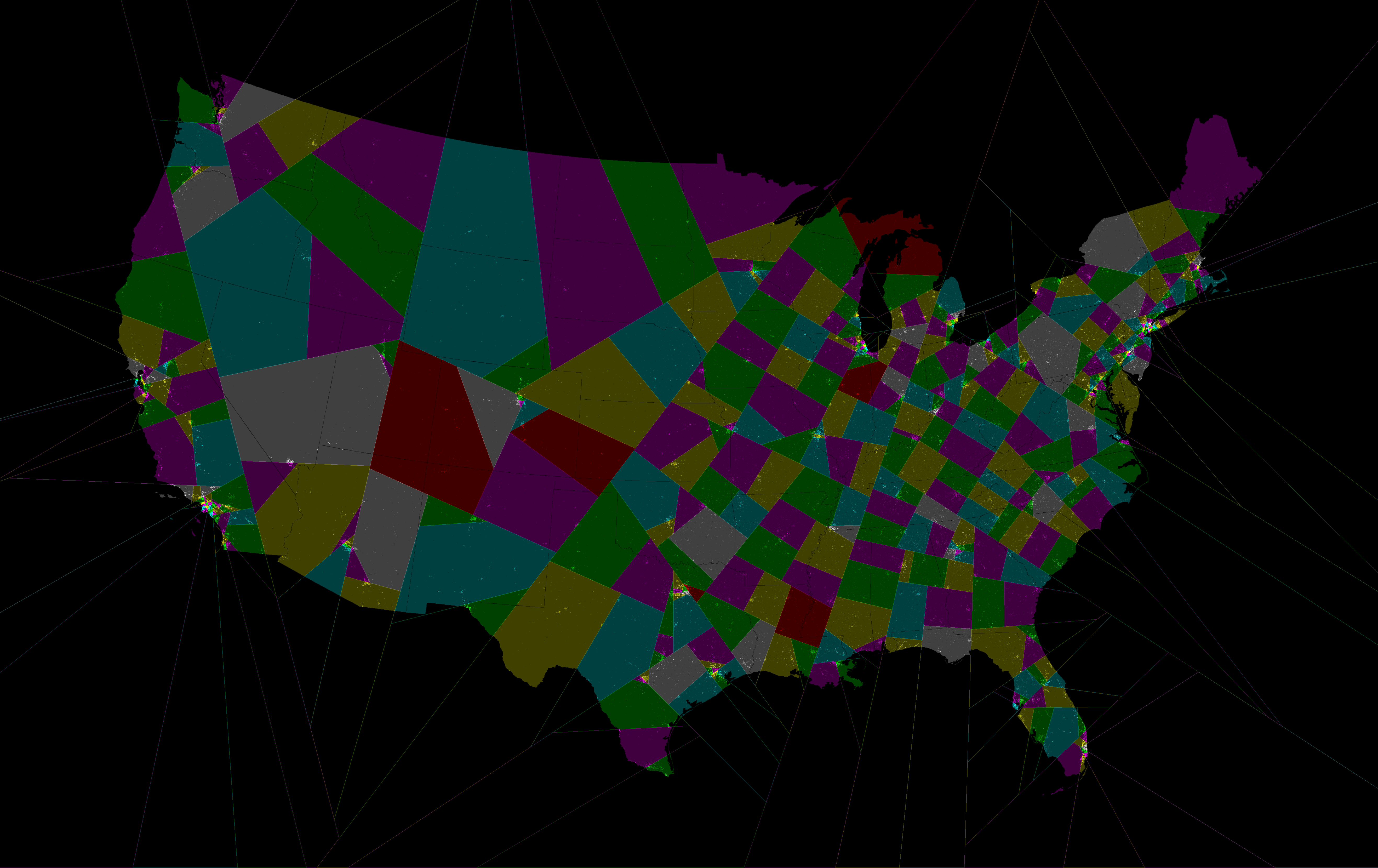
On 9/2/08, Brian Olson <[EMAIL PROTECTED]> wrote: > I have implemented essentially that, and it pretty quickly gets pretty good > results as measured by the "distance per person to land-area-center" test. I > added one thing to deal with variations in population density. Each district > center also has an associated weight. Each 'voronoi cell'/district contains > the people with a weighted distance closest to that district center. So, a > district center in a high population density area doesn't have to reach very > far to gather its allotment of people.
Your maps don't look like voronoi diagrams (edges aren't lines). Do you assign based on Assign voter to district with minimum distance to district centre - Cd Where Cd is some coefficient for the district d. Cd is set so as to give equal populations. If so, have you considered using squared distance instead of distance? Assign voter to district with min (distance to centre)^2 - Cd This gives straight district edges (I think). You might need to change your rule to The best district map is the one where people have the lowest average *squared* distance to the center of their district. > There are some states where this doesn't work very well (CA, TX, NV, and a > couple others) and a more exhaustive solving method is needed. I think one > of the weaknesses of the voronoi method is that population is not > continuous, but in discrete census blocks of dozens to thousands of people. > The voronoi method can't necessarily tweak to swap a block here and a block > there to get within a reasonable margin of equal-population. When I was writing the software to implement the shortest splitline for Rangevoting.org, my solution was to split the border block. (or at least that was my plan ... I don't think I actually implemented it). This page has all the states (v1 of the software) http://rangevoting.org/SplitLR.html This page has the entire 'lower 48' all in one go (v2 of the software) http://rangevoting.org/USsplitLine.png Basically, the algorithm picks a slope to test and then sorts all the blocks based on which line with that slope goes through them. e.g. sort by Cn = Yn - m*Xn It then finds the median block. This means that approx half the population is on one side and half the population is on the other side of the line. (Blocks that have equal Cn are differentiated by Dn = m*Yn + Xn, this means that there is only ever one block) The block itself can be placed on one side or the other. If it worked out population above line: 649,700 population of block: 1000 population below line: 649,300 These blocks would be split into 2 sub-blocks of population 300 and 700. These blocks would still be considered to occur at the same point. The 300 would be assigned to the above the line district and the 700 to the below the line district. The result from the algorithm could be District A: <list of blocks that are 100% in district> partial blocks 300 of 1000 from tract X 100 of 800 from tract Y 150 of 1050 from tract Z Unless the blocks are massive, there should only be a few partial blocks, accounting for only a small fraction of the district's population. The boundaries could be drawn by a judge or other group by hand. If you really wanted to be strict, they could be automatically split, but I don't think it is worth the effort. They would be unlikely to make much difference and thus it wouldn't be worth the effort corrupting them. I also added a rule which auto-split blocks prior to starting the algorithm, based on a limit. For example, 650k blocks might be converted into 750k by splitting the largest blocks. If the limit was 500, then a 2250 block would be auto split into 5 blocks, 500, 500, 500, 500, 250. > I think it's worth repeating that I'd prefer to write the law with a way of > measuring what a good district mapping is, rather than writing the law with > a specific procedure for creating the district mapping. Specific procedures > get really complex, and I don't think in this case that a fair procedure > ensures a fair outcome. Sounds reasonable. However, people don't really like randomness. There is considerable resistance to using randomness in elections and people might consider a system where the solution isn't well defined as somewhat random. "You mean that the best solution mightn't be picked because nobody could find it?" Also, there could be issues if a better solution is found after the deadline, especially, if it favoured one party over another. > I used the voronoi technique as just one possible > way of writing a solver to get the desired result. It could even wind up > that the best way to solve for the desired goals is to have a computer do > 99% of the work and have a human come back and clean up the edges. Since > it's subject to the same scoring in the end, the human couldn't deviate too > far from the ideal mapping. Well a person is going to be unlikely to be able to beat a computer, if the algorithm is reasonably optimised. You might need to allow the human slightly degrade the performance slightly. ---- Election-Methods mailing list - see http://electorama.com/em for list info
{kind=link}