wjones127 commented on PR #13857: URL: https://github.com/apache/arrow/pull/13857#issuecomment-1255650375
> @wjones127 These numbers are for the random or monotonic use case? That's for random. Here is it including monotonic, which makes it more complex: 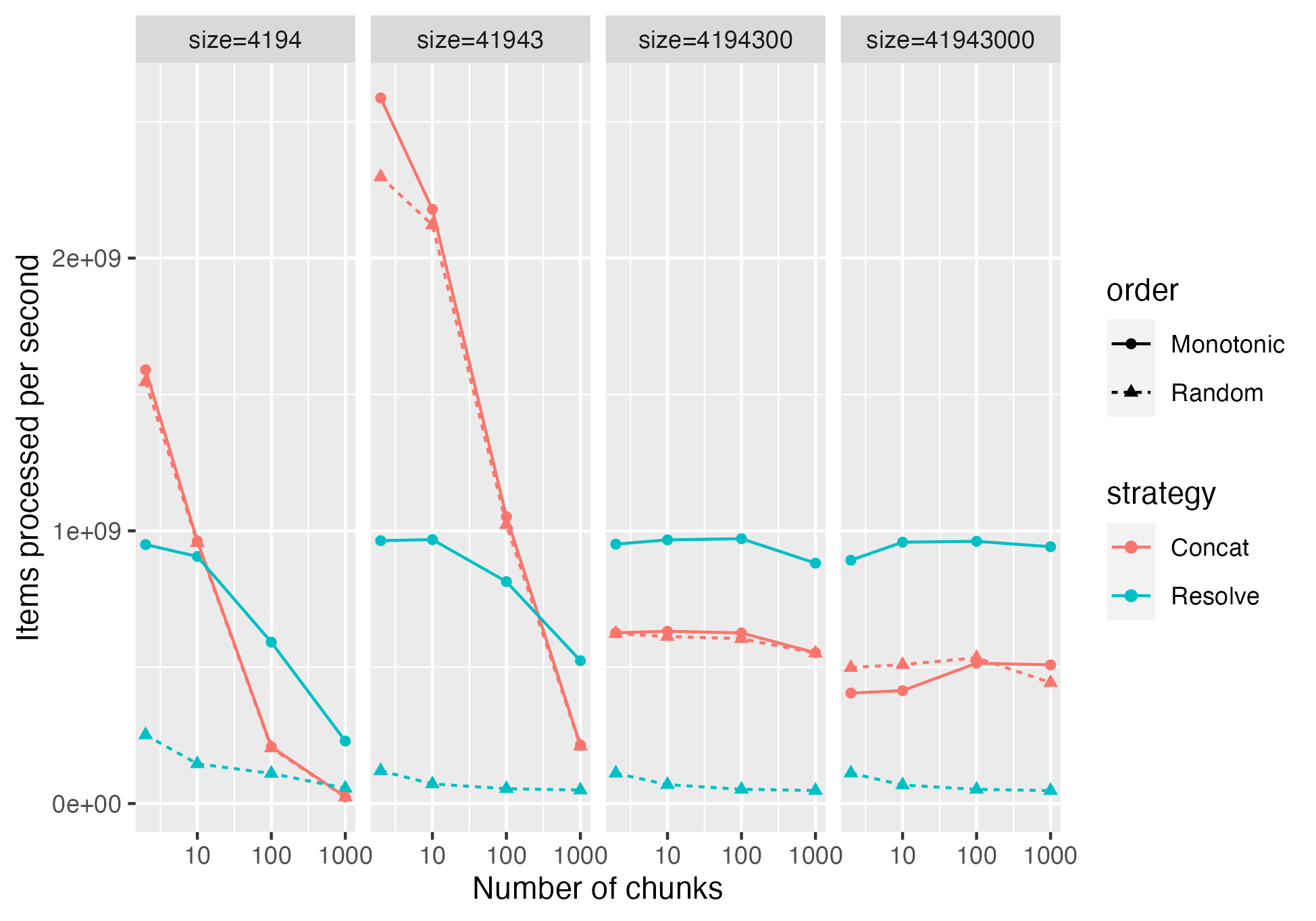 So it seems like it's better in the monotonic case, but worse in the random case. > Are these results measured without the extra overhead of the temporary std::vector for the ChunkResolver case? I hadn't removed it. Removed it in the test that I'm showing results for above. > The ChunkResolver is the most general solution with least overhead on memory use and still reasonable performance. In some cases it seems like it would be a serious regression; so I'm trying to figure out which cases those are if we can avoid using ChunkResolver in those cases. It's hard to say if that extra memory usage is that significant. I feel like some extra memory usage will always happen within compute function. This is large since it needs to operate on the entire chunk, rather than just a chunk at a time. But also with memory pools we can rapidly reuse memory; so I imagine for example if we are running `Take()` on a Table with multiple string columns, the memory used temporarily for the first one could be re-used when processing the second. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: [email protected] For queries about this service, please contact Infrastructure at: [email protected]
{kind=link}