Hi José,
On 11/03/2011 14:16, José Pedro Magalhães wrote:
I've played a bit with Intel's Manycore Testing Lab
(http://software.intel.com/en-us/articles/intel-many-core-testing-lab/).
Part of the agreement to use it requires that you report back your
experiences, which I did in an Intel forum post
(http://software.intel.com/en-us/forums/showthread.php?t=81396). I
thought this could be interesting to the Haskell community in general as
well, so I'm reposting here, and pasting the text below for convenience.
I've replaced the images with links.
Is it possible for you to make the code for your benchmarks available?
I'd be interested in analysing the results further.
In our testing I've been able to achieve speedups over 20 on 24 cores
with GHC 7.0.2, so there should be no reason in principle that you
couldn't achieve similar results for obviously parallel problems, which
yours seem to be. Some tweaking of GC parameters might be necessary:
e.g. I've found that +RTS -A1m helps if your L2 caches are large enough.
A good starting point for profiling is ThreadScope, which will tell
you if the program is really trying to use all the cores or not.
Cheers,
Simon
Cheers,
Pedro
As per the agreement with Intel, I am reporting my experiences with
the Intel Manycore Testing Lab (Linux). This was my first time in
the lab, and I wanted to test GHC's [1] SMP parallelism [2] features.
The first challenge was to actually get GHC to work on the lab.
There was a working version of ghc under /opt/ghc6.13/bin/ghc, but I
really needed GHC 7. So first I built GHC 7.0.2-rc2, which worked
without much trouble.
Next step was to get all the necessary libraries in place. Since the
lab has no direct internet access, cabal-install [3] wouldn't be of
much use. Instead, I downloaded a snapshot of hackage [4] with the
latest version of every package and manually installed the packages
I needed. A bit boring, but doable.
Finally I was ready to compile my programs and test. First thing I
tried was an existing algorithm I had which, at some point, takes a
list of about 500 trees and, for each tree, computes a measure which
is expressed as a floating point number. This is basically a map
over a list transforming each tree into a float. Each operation is
independent of the others, and all require the same input, so it
seems ideal for parallelisation. A quick benchmark revealed the
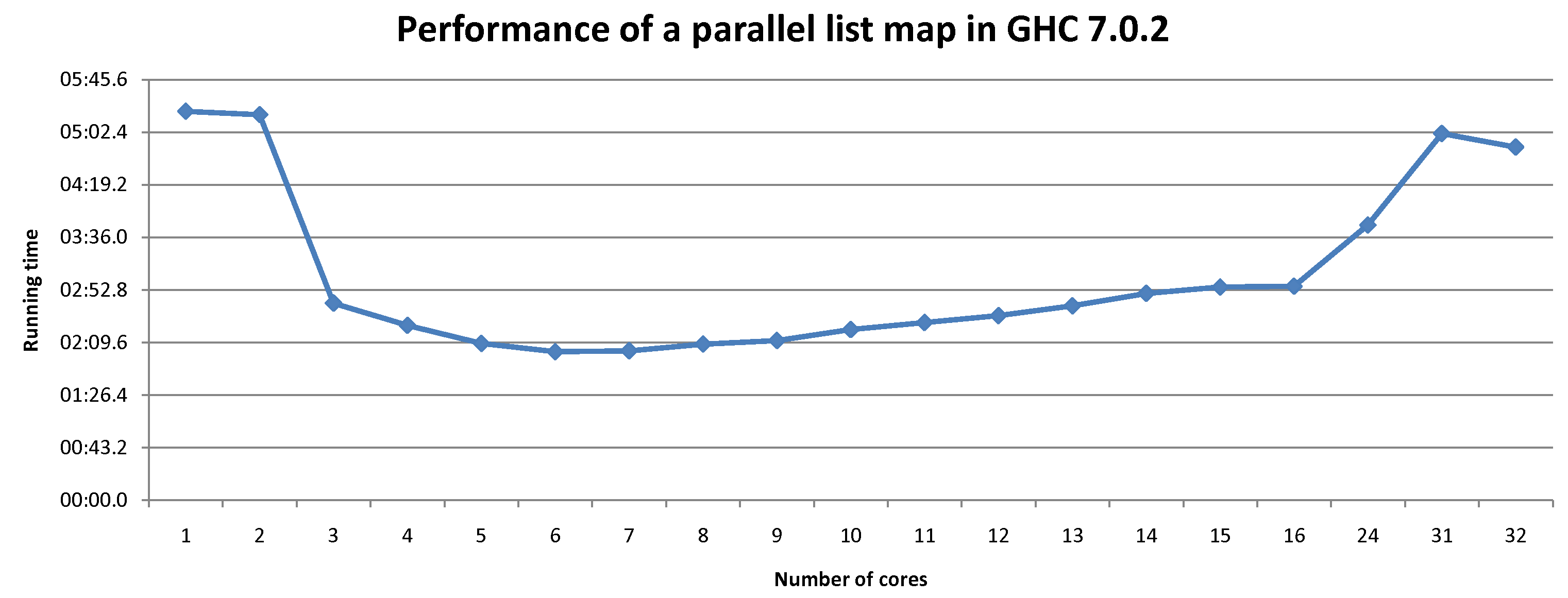
following running times:
http://dreixel.net/images/perm/ParList.png
(Note the non-linear number of cores at the end of the x-axis.)
Apparently there are performance gains with up to 6 cores; adding
more cores after this makes the total running time worse.
While this might sound bad, do note that all that was necessary to
parallelise this algorithm was a one line change: basically, at the
point where the list of floats @l@ is generated, it is replaced with
@l `using` parList rdeepseq@. This change, together with
recompilation using -threaded, is all that is necessary to
parallelise this program.
Later I performed a more accurate benchmark, this time using the
equality function (take two elements and compare them for equality).
The first step was to parallelise the equality function, which,
again, is a very simple task:
-- Tree datatype
data Tree a = Leaf | Bin a (Tree a) (Tree a)
-- Parallel equality
eqTreePar :: Tree Int -> Tree Int -> Bool
eqTreePar Leaf Leaf = True
eqTreePar (Bin x1 l1 r1) (Bin x2 l2 r2) = x1 == x2 && par l (pseq r
(l && r))
where l = eqTreePar l1 l2
r = eqTreePar r1 r2
eqTreePar _ _ = False
`par` and `pseq` are the two primitives for parallelisation in GHC
[5]. The performance graph follows:
http://dreixel.net/images/perm/ParEq.png
(This time I ran the benchmark several times; the error bars on the
graph are the standard deviations.) Again we get performance
improvements with up to 6 cores, and after that performance
decreases. What I find really nice is the improvement with two
cores, which is almost a 50% decrease in running time. The ratios
for 2 to 4 cores wrt. the running time with 1 core are 0.52, 0.39,
and 0.35, respectively. This is really good for such a simple change
in the source code, and most people only have up to 4 cores anyway.
In any case, the results of this (very preliminary) experiment seem
to indicate that GHC's SMP parallelism is not particularly optimized
for a high number of cores (yet).
I'm planning to explore this line of research further, and I'm
hoping to be able to conduct more experiments in the near future.
Feel free to contact me if you want more information on what I've done.
Cheers,
Pedro
[1] http://www.haskell.org/ghc/
[2]
http://www.haskell.org/ghc/docs/latest/html/users_guide/using-smp.html
[3] http://hackage.haskell.org/package/cabal-install
[4] http://hackage.haskell.org
[5]
http://hackage.haskell.org/packages/archive/parallel/latest/doc/html/Control-Parallel.html
_______________________________________________
Haskell-Cafe mailing list
Haskell-Cafe@haskell.org
http://www.haskell.org/mailman/listinfo/haskell-cafe
_______________________________________________
Haskell-Cafe mailing list
Haskell-Cafe@haskell.org
http://www.haskell.org/mailman/listinfo/haskell-cafe
{kind=link}
{kind=link}