[
https://issues.apache.org/jira/browse/HDFS-7285?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17335169#comment-17335169
]
Stone commented on HDFS-7285:
-----------------------------
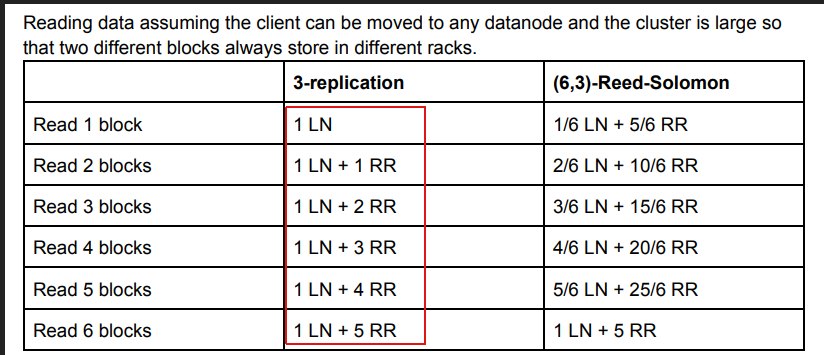
[~zhz] https://img-ask.csdnimg.cn/upload/1619363340018.png
You can see this picture by coping the URL address to the browser.Don't open
this url link directly
> Erasure Coding Support inside HDFS
> ----------------------------------
>
> Key: HDFS-7285
> URL: https://issues.apache.org/jira/browse/HDFS-7285
> Project: Hadoop HDFS
> Issue Type: New Feature
> Reporter: Weihua Jiang
> Assignee: Zhe Zhang
> Priority: Major
> Fix For: 3.0.0-alpha1
>
> Attachments: Compare-consolidated-20150824.diff,
> Consolidated-20150707.patch, Consolidated-20150806.patch,
> Consolidated-20150810.patch, ECAnalyzer.py, ECParser.py,
> HDFS-7285-Consolidated-20150911.patch, HDFS-7285-initial-PoC.patch,
> HDFS-7285-merge-consolidated-01.patch,
> HDFS-7285-merge-consolidated-trunk-01.patch,
> HDFS-7285-merge-consolidated.trunk.03.patch,
> HDFS-7285-merge-consolidated.trunk.04.patch,
> HDFS-EC-Merge-PoC-20150624.patch, HDFS-EC-merge-consolidated-01.patch,
> HDFS-bistriped.patch, HDFSErasureCodingDesign-20141028.pdf,
> HDFSErasureCodingDesign-20141217.pdf, HDFSErasureCodingDesign-20150204.pdf,
> HDFSErasureCodingDesign-20150206.pdf, HDFSErasureCodingPhaseITestPlan.pdf,
> HDFSErasureCodingSystemTestPlan-20150824.pdf,
> HDFSErasureCodingSystemTestReport-20150826.pdf, fsimage-analysis-20150105.pdf
>
>
> Erasure Coding (EC) can greatly reduce the storage overhead without sacrifice
> of data reliability, comparing to the existing HDFS 3-replica approach. For
> example, if we use a 10+4 Reed Solomon coding, we can allow loss of 4 blocks,
> with storage overhead only being 40%. This makes EC a quite attractive
> alternative for big data storage, particularly for cold data.
> Facebook had a related open source project called HDFS-RAID. It used to be
> one of the contribute packages in HDFS but had been removed since Hadoop 2.0
> for maintain reason. The drawbacks are: 1) it is on top of HDFS and depends
> on MapReduce to do encoding and decoding tasks; 2) it can only be used for
> cold files that are intended not to be appended anymore; 3) the pure Java EC
> coding implementation is extremely slow in practical use. Due to these, it
> might not be a good idea to just bring HDFS-RAID back.
> We (Intel and Cloudera) are working on a design to build EC into HDFS that
> gets rid of any external dependencies, makes it self-contained and
> independently maintained. This design lays the EC feature on the storage type
> support and considers compatible with existing HDFS features like caching,
> snapshot, encryption, high availability and etc. This design will also
> support different EC coding schemes, implementations and policies for
> different deployment scenarios. By utilizing advanced libraries (e.g. Intel
> ISA-L library), an implementation can greatly improve the performance of EC
> encoding/decoding and makes the EC solution even more attractive. We will
> post the design document soon.
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
---------------------------------------------------------------------
To unsubscribe, e-mail: hdfs-issues-unsubscr...@hadoop.apache.org
For additional commands, e-mail: hdfs-issues-h...@hadoop.apache.org
{kind=link}