[
https://issues.apache.org/jira/browse/HDFS-16333?focusedWorklogId=690836&page=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-690836
]
ASF GitHub Bot logged work on HDFS-16333:
-----------------------------------------
Author: ASF GitHub Bot
Created on: 06/Dec/21 08:59
Start Date: 06/Dec/21 08:59
Worklog Time Spent: 10m
Work Description: liubingxing edited a comment on pull request #3679:
URL: https://github.com/apache/hadoop/pull/3679#issuecomment-986568780
@tasanuma Thank you for your review and comments.
I run the UT `doTestBalancerWithStripedFile` in current trunk branch and
sometimes the errors occur .
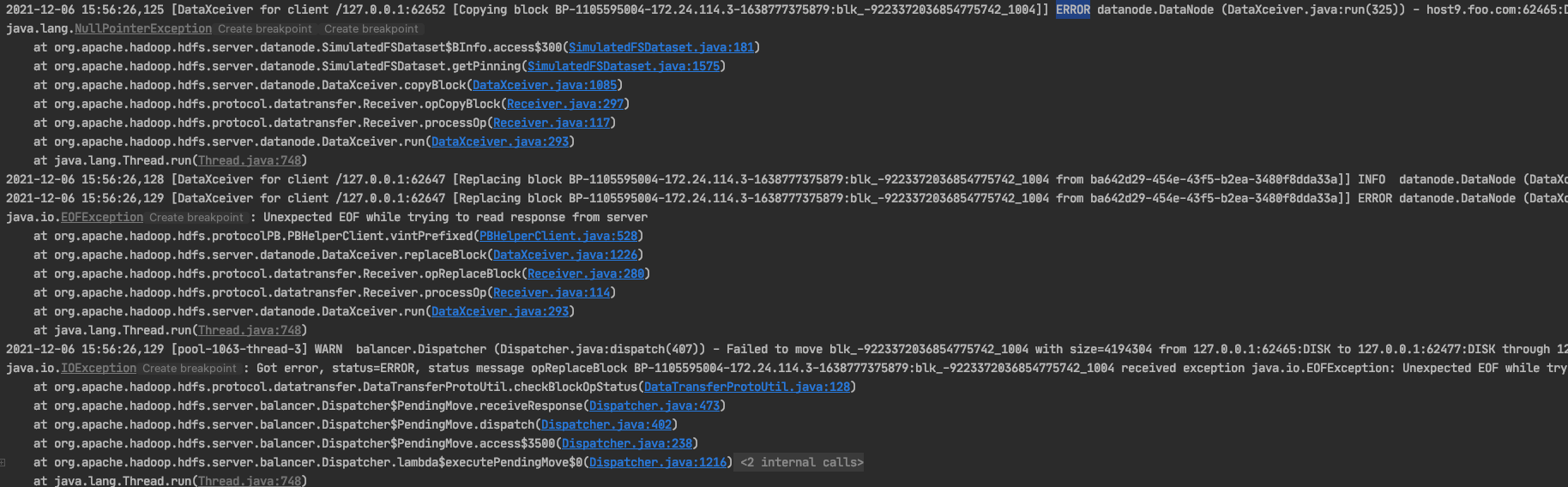
Therefore, it is not good to use `assertEquals(0,
nnc.getBlocksFailed().get())` to check the result in this new UT.
I will redesign a UT to test this scenario as soon as possible.
If you have any suggestions, please let me know, thank you.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: common-issues-unsubscr...@hadoop.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
Issue Time Tracking
-------------------
Worklog Id: (was: 690836)
Time Spent: 1h 50m (was: 1h 40m)
> fix balancer bug when transfer an EC block
> ------------------------------------------
>
> Key: HDFS-16333
> URL: https://issues.apache.org/jira/browse/HDFS-16333
> Project: Hadoop HDFS
> Issue Type: Bug
> Components: balancer & mover
> Reporter: qinyuren
> Assignee: qinyuren
> Priority: Major
> Labels: pull-request-available
> Attachments: image-2021-11-18-17-25-13-089.png,
> image-2021-11-18-17-25-50-556.png, image-2021-11-18-17-28-03-155.png
>
> Time Spent: 1h 50m
> Remaining Estimate: 0h
>
> We set the EC policy to (6+3) and we also have nodes that were
> decommissioning when we executed balancer.
> With the balancer running, we find many error logs as follow.
> !image-2021-11-18-17-25-13-089.png|width=858,height=135!
> Node A wants to transfer an EC block to node B, but we found that the block
> is not on node A. The FSCK command to show the block status as follow
> !image-2021-11-18-17-25-50-556.png|width=607,height=189!
> In the dispatcher. getBlockList function
> !image-2021-11-18-17-28-03-155.png!
>
> Assume that the location of the an EC block in storageGroupMap look like this
> indices:[0, 1, 2, 3, 4, 5, 6, 7, 8]
> node:[a, b, c, d, e, f, g, h, i]
> after decommission operation, the internal block on indices[1] were
> decommission to another node.
> indices:[0, 1, 2, 3, 4, 5, 6, 7, 8]
> node:[a, {color:#FF0000}j{color}, c, d, e, f, g, h, i]
> the location of indices[1] change from node {color:#FF0000}b{color} to node
> {color:#FF0000}j{color}.
>
> When the balancer get the block location and check it with the location in
> storageGroupMap.
> If a node is not found in storageGroupMap, it will not be add to block
> locations.
> In this case, node {color:#FF0000}j {color}will not be added to the block
> locations, while the indices is not updated.
> Finally, the block location may look like this,
> indices:[0, 1, 2, 3, 4, 5, 6, 7, 8]
> {color:#FF0000}block.location:[a, c, d, e, f, g, h, i]{color}
> the location of the nodes does not match their indices
>
> Solution:
> we should update the indices and match with the nodes
> {color:#FF0000}indices:[0, 2, 3, 4, 5, 6, 7, 8]{color}
> {color:#FF0000}block.location:[a, c, d, e, f, g, h, i]{color}
--
This message was sent by Atlassian Jira
(v8.20.1#820001)
---------------------------------------------------------------------
To unsubscribe, e-mail: hdfs-issues-unsubscr...@hadoop.apache.org
For additional commands, e-mail: hdfs-issues-h...@hadoop.apache.org
{kind=link}