[
https://issues.apache.org/jira/browse/HDFS-16476?focusedWorklogId=731319&page=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-731319
]
ASF GitHub Bot logged work on HDFS-16476:
-----------------------------------------
Author: ASF GitHub Bot
Created on: 23/Feb/22 02:39
Start Date: 23/Feb/22 02:39
Worklog Time Spent: 10m
Work Description: jianghuazhu commented on pull request #4010:
URL: https://github.com/apache/hadoop/pull/4010#issuecomment-1048400030
There are some ci/cd related failures here that don't seem to be related.
Here is an example with some online clusters, obtained by getting the
NameNode's jmx:
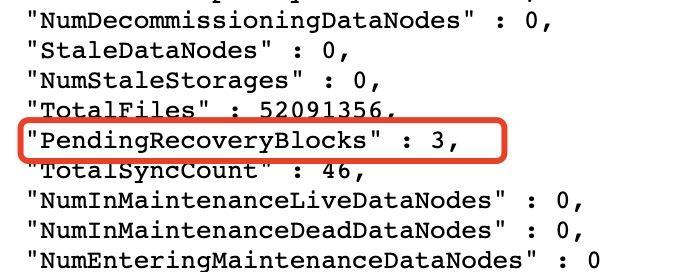
Regarding the display of logarithms, I think the block recovery work is
something between NameNode and DataNode, so in the RBF module, I implemented a
default value. E.g:
public int getPendingRecoveryBlocks() {
return 0;
}
If compatibility with RBF is required in the future, it can be achieved with
minimal code changes.
Would you guys help to review this PR, @ayushtkn @virajjasani .
Thank you very much.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: common-issues-unsubscr...@hadoop.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
Issue Time Tracking
-------------------
Worklog Id: (was: 731319)
Time Spent: 0.5h (was: 20m)
> Increase the number of metrics used to record PendingRecoveryBlocks
> -------------------------------------------------------------------
>
> Key: HDFS-16476
> URL: https://issues.apache.org/jira/browse/HDFS-16476
> Project: Hadoop HDFS
> Issue Type: Improvement
> Components: metrics, namenode
> Affects Versions: 2.9.2, 3.4.0
> Reporter: JiangHua Zhu
> Assignee: JiangHua Zhu
> Priority: Major
> Labels: pull-request-available
> Time Spent: 0.5h
> Remaining Estimate: 0h
>
> The complete process of block recovery is as follows:
> 1. NameNode collects which blocks need to be recovered.
> 2. The NameNode issues instructions to some DataNodes for execution.
> 3. DataNode tells NameNode after execution is complete.
> Now there is no way to know how many blocks are being recovered. The number
> of metrics used to record PendingRecoveryBlocks should be increased, which is
> good for increasing the robustness of the cluster.
> Here are some logs of DataNode execution:
> 2022-02-10 23:51:04,386 [12208592621] - INFO [IPC Server handler 38 on
> 8025:FsDatasetImpl@2687] - initReplicaRecovery: changing replica state for
> blk_xxxx from RBW to RUR
> 2022-02-10 23:51:04,395 [12208592630] - INFO [IPC Server handler 47 on
> 8025:FsDatasetImpl@2708] - updateReplica: BP-xxxx:blk_xxxx,
> recoveryId=18386356475, length=129869866, replica=ReplicaUnderRecovery,
> blk_xxxx, RUR
> Here are some logs that NameNdoe receives after completion:
> 2022-02-22 10:43:58,780 [8193058814] - INFO [IPC Server handler 15 on
> 8021:FSNamesystem@3647] - commitBlockSynchronization(oldBlock=BP-xxxx,
> newgenerationstamp=18551926574, newlength=16929, newtargets=[xxxx1:1004,
> xxxx2:1004, xxxx3:1004]) successful
--
This message was sent by Atlassian Jira
(v8.20.1#820001)
---------------------------------------------------------------------
To unsubscribe, e-mail: hdfs-issues-unsubscr...@hadoop.apache.org
For additional commands, e-mail: hdfs-issues-h...@hadoop.apache.org
{kind=link}