[
https://issues.apache.org/jira/browse/ARTEMIS-2399?focusedWorklogId=265708&page=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-265708
]
ASF GitHub Bot logged work on ARTEMIS-2399:
-------------------------------------------
Author: ASF GitHub Bot
Created on: 24/Jun/19 13:21
Start Date: 24/Jun/19 13:21
Worklog Time Spent: 10m
Work Description: wy96f commented on pull request #2730: ARTEMIS-2399 Fix
performance degradation when there are a lot of subscribers
URL: https://github.com/apache/activemq-artemis/pull/2730
We noticed that there was a significant drop in performance when entering
page mode in the case of multiple subscribers.
### **Environment**:
broker 2.9.0
cpu: 4 cores, memory: 8G, disk: ssd 500G
broker.xml:
<thread-pool-max-size>60</thread-pool-max-size>
<address-setting match="#">
<max-size-bytes>51Mb</max-size-bytes>
<page-size-bytes>50Mb</page-size-bytes>
<page-max-cache-size>1</page-max-cache-size>
<address-full-policy>PAGE</address-full-policy>
</address-setting>
<message-expiry-scan-period>-1</message-expiry-scan-period>
### **Test steps**:
We created a topic and 100 queues bound to it. We ran our GrinderRunner test
in our inner test infra cluster with 500 threads producing messages(200-500
bytes size) and 560 threads, each one picked a random queue to subscribe. The
test showed performance is bad: 13000 msg/s sent and 5000 msg/s received.
producer tps and latency:
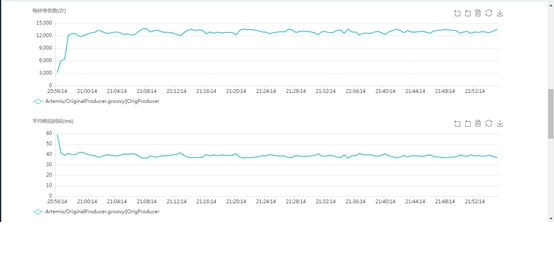
consumer tps and latency:
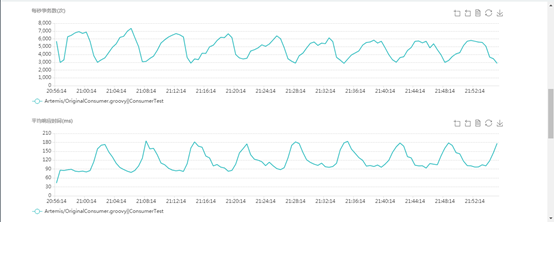
### **Analysis**:
There were two root causes:
1. Usually 1000 messages are delivered at once, sometimes less if consumers
are busy. Then depage() is called to fill the queue with number of messages
delivered in last step. To read these messages we need to read the whole page.
It's acceptable if the page is in the softValueCache. But in the case of
multiple subscribers with different cursor position, they read there own page
file, put it in the cache and evict other pages. At the later time, when they
need to read it again, they found it not in cache and have to read the whole
page from disk which spends much time and puts pressure on disk.
2. For multiple subscribers to the same address, just one executor is
responsible for delivering which means at the same moment only one queue is
delivering. Thus the queue maybe stalled for a long time. We get
queueMemorySize messages into memory, and when we deliver these after a long
time, we probably need to query message and read page file again.
### **Solution**:
1. We add a new cache called PageIndexCache which stores the message number
and file position. This cache is built when we first read the page and put it
into softValueCache. If the page is evicted from softValueCache later, we'll
use PageIndexCache to read message. In this way, we don't need to read the
whole page for just a few messages.
2. In most cases, one depage round is followed by at most
MAX_SCHEDULED_RUNNERS deliver round. Thus we just need to read
MAX_DELIVERIES_IN_LOOP * MAX_SCHEDULED_RUNNERS messages. This reduces the
possibility of requering the reference case the Garbage Collection removes it
and keeps enough messages to deliver each time.
The optimized performance in the pr:
producer tps and latency:
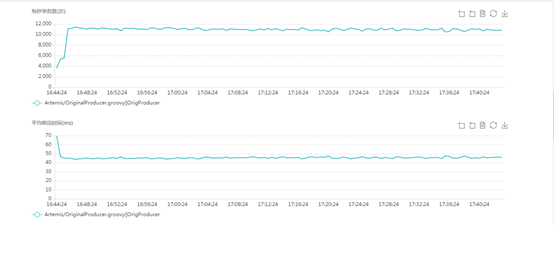
consumer tps and latency:
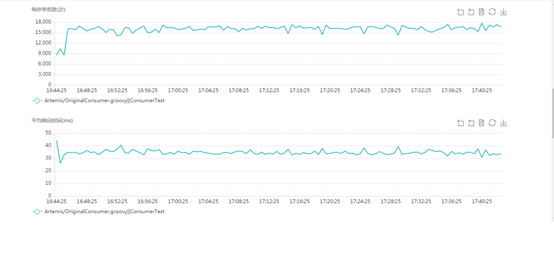
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
[email protected]
Issue Time Tracking
-------------------
Worklog Id: (was: 265708)
Time Spent: 10m
Remaining Estimate: 0h
> Fix performance degradation when there are a lot of subscribers
> ---------------------------------------------------------------
>
> Key: ARTEMIS-2399
> URL: https://issues.apache.org/jira/browse/ARTEMIS-2399
> Project: ActiveMQ Artemis
> Issue Type: Improvement
> Components: Broker
> Affects Versions: 2.9.0
> Environment: broker 2.9.0
> cpu: 4 cores, memory: 8G, disk: ssd 500G
> broker.xml:
> <thread-pool-max-size>60</thread-pool-max-size>
> <address-setting match="#">
> <max-size-bytes>51Mb</max-size-bytes>
> <page-size-bytes>50Mb</page-size-bytes>
> <page-max-cache-size>1</page-max-cache-size>
> <address-full-policy>PAGE</address-full-policy>
> </address-setting>
> <message-expiry-scan-period>-1</message-expiry-scan-period>
> Reporter: yangwei
> Priority: Major
> Time Spent: 10m
> Remaining Estimate: 0h
>
> We noticed that there was a significant drop in performance when entering
> page mode in the case of multiple subscribers.
> We created a topic and 100 queues bound to it. We ran our _GrinderRunner
> test_ in our inner test infra cluster with 500 threads producing message and
> 560 threads, each one picked a random queue to subscribe. The test showed
> performance is bad: 13000 msg/s sent and 5000 msg/s received.
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
{kind=link}
{kind=link}
{kind=link}
{kind=link}