[
https://issues.apache.org/jira/browse/DRILL-6879?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=16718120#comment-16718120
]
ASF GitHub Bot commented on DRILL-6879:
---------------------------------------
kkhatua commented on issue #1572: DRILL-6879: Show warnings for potential
performance issues
URL: https://github.com/apache/drill/pull/1572#issuecomment-446391795
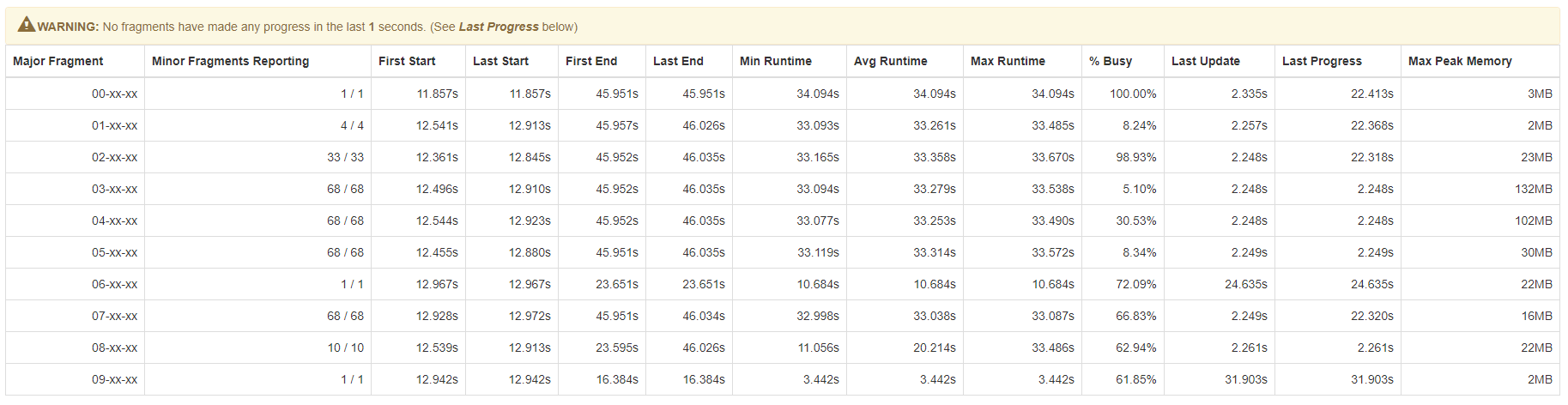
**Screenshot** for fragments making no progress (test setup has threshold
`drill.exec.http.profile.warning.progress.threshold` as **1 sec** ):
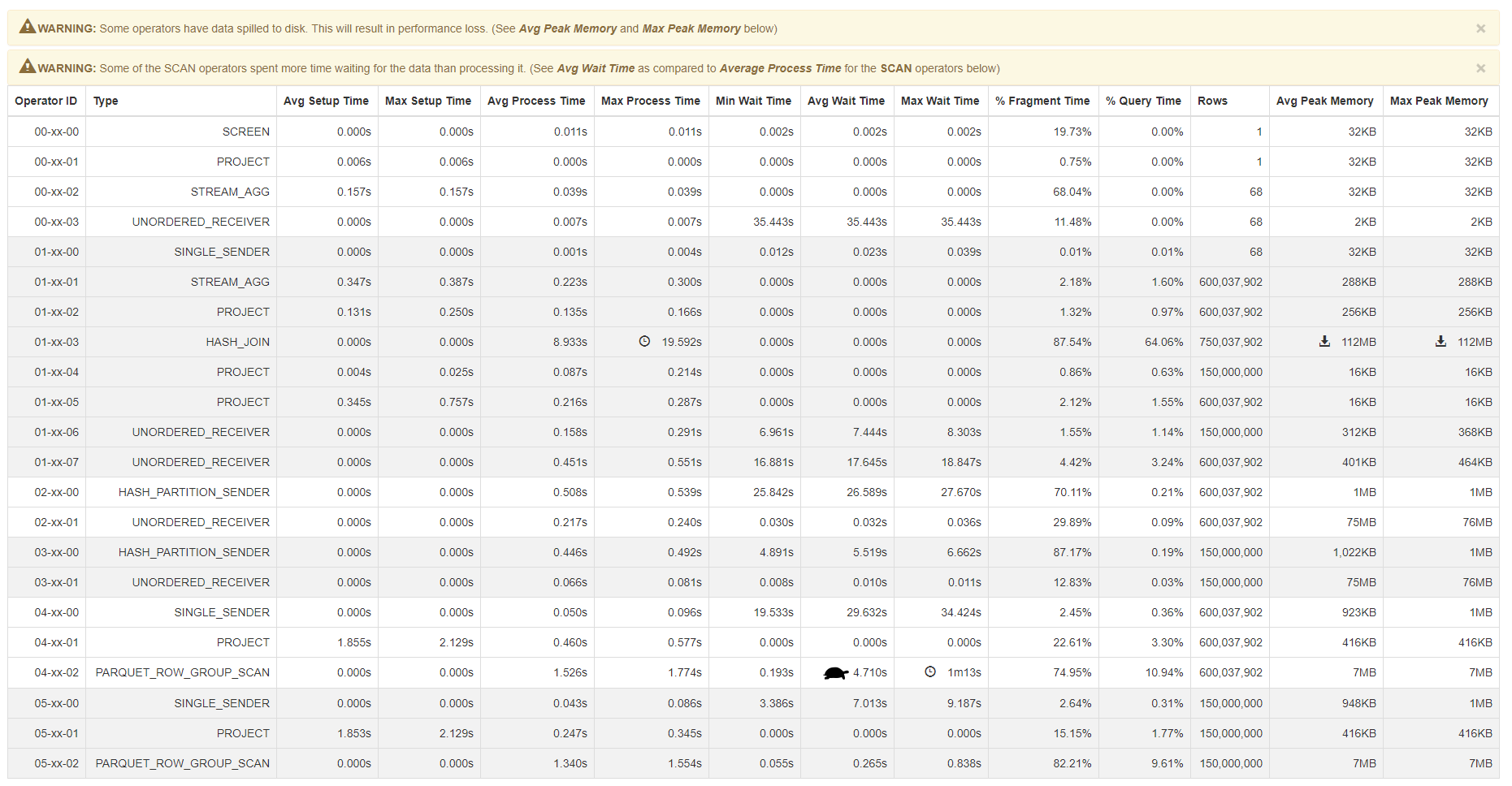
**Screenshot** for operators that have spilled to disk, or run with
unusually long wait times; or have the longest running fragments with an
extreme skew:
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
> Indicate a warning in the WebUI when a query makes little to no progress for
> a while
> ------------------------------------------------------------------------------------
>
> Key: DRILL-6879
> URL: https://issues.apache.org/jira/browse/DRILL-6879
> Project: Apache Drill
> Issue Type: Improvement
> Components: Execution - Monitoring, Web Server
> Affects Versions: 1.14.0
> Reporter: Kunal Khatua
> Assignee: Kunal Khatua
> Priority: Major
> Labels: user-experience
> Fix For: 1.16.0
>
> Attachments: image-2018-12-04-11-54-54-247.png,
> image-2018-12-06-11-19-00-339.png, image-2018-12-06-11-27-14-719.png
>
> Original Estimate: 168h
> Remaining Estimate: 168h
>
> When running a very large query on a cluster with limited resource, we
> noticed that one of the node's VM thread freezes the fragment threads as it
> tries to do some work (GC perhaps?). This is a clear indication that the
> query is stuck in a weird state where it might not recover from.
> Under such circumstances, it makes sense to cancel or atleast warn the user
> on that page of the query exceeding a certain threshold.
> For detecting this, the user will find that the {{Last Progress}} column in
> the Fragments Overview section will show large times.
> !image-2018-12-04-11-54-54-247.png|width=969,height=336!
> In addition, there are instances where a query might have buffered operators
> spilling to disk, which also hits performance (and, subsequently, longer run
> times). Calling out this skew can be very useful.
> !image-2018-12-06-11-27-14-719.png|width=969,height=256!
> Or there might be cases where a single fragment takes much longer than the
> average (indicated by an extreme skew in the Gantt chart).
> !image-2018-12-06-11-19-00-339.png|width=969,height=150!
>
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
{kind=link}
{kind=link}