rbalamohan opened a new issue, #5863: URL: https://github.com/apache/iceberg/issues/5863
### Feature Request / Improvement When "merge-on-read" is enabled on tables, it creates "positional delete" files. These files contain 2 fields. ``` file schema: table -------------------------------------------------------------------------------- file_path: REQUIRED BINARY O:UTF8 R:0 D:0 pos: REQUIRED INT64 R:0 D:0 ``` When reading data back from the table, these "positional delete" files are merged. E.g "select count(*) from store_sales where ss_ext_discount_amt=0.0" will merge the contents after the table has been updated/deleted. It spends a lot of time in reading positional delete files. Though file_path is dictionary encoded, it ends up reconstructing the same filename again and again during reading. https://github.com/apache/iceberg/blob/master/parquet/src/main/java/org/apache/iceberg/parquet/ParquetValueReaders.java#L240 ``` @Override public String read(String reuse) { return column.nextBinary().toStringUsingUTF8(); } ``` ``` row group 1: RC:211807 TS:1696744 OFFSET:4 -------------------------------------------------------------------------------- file_path: BINARY SNAPPY DO:4 FPO:401 SZ:1653/1969/1.19 VC:211807 ENC:BIT_PACKED,PLAIN_DICTIONARY pos: INT64 SNAPPY DO:0 FPO:1657 SZ:883089/1694775/1.92 VC:211807 ENC:PLAIN,BIT_PACKED ``` 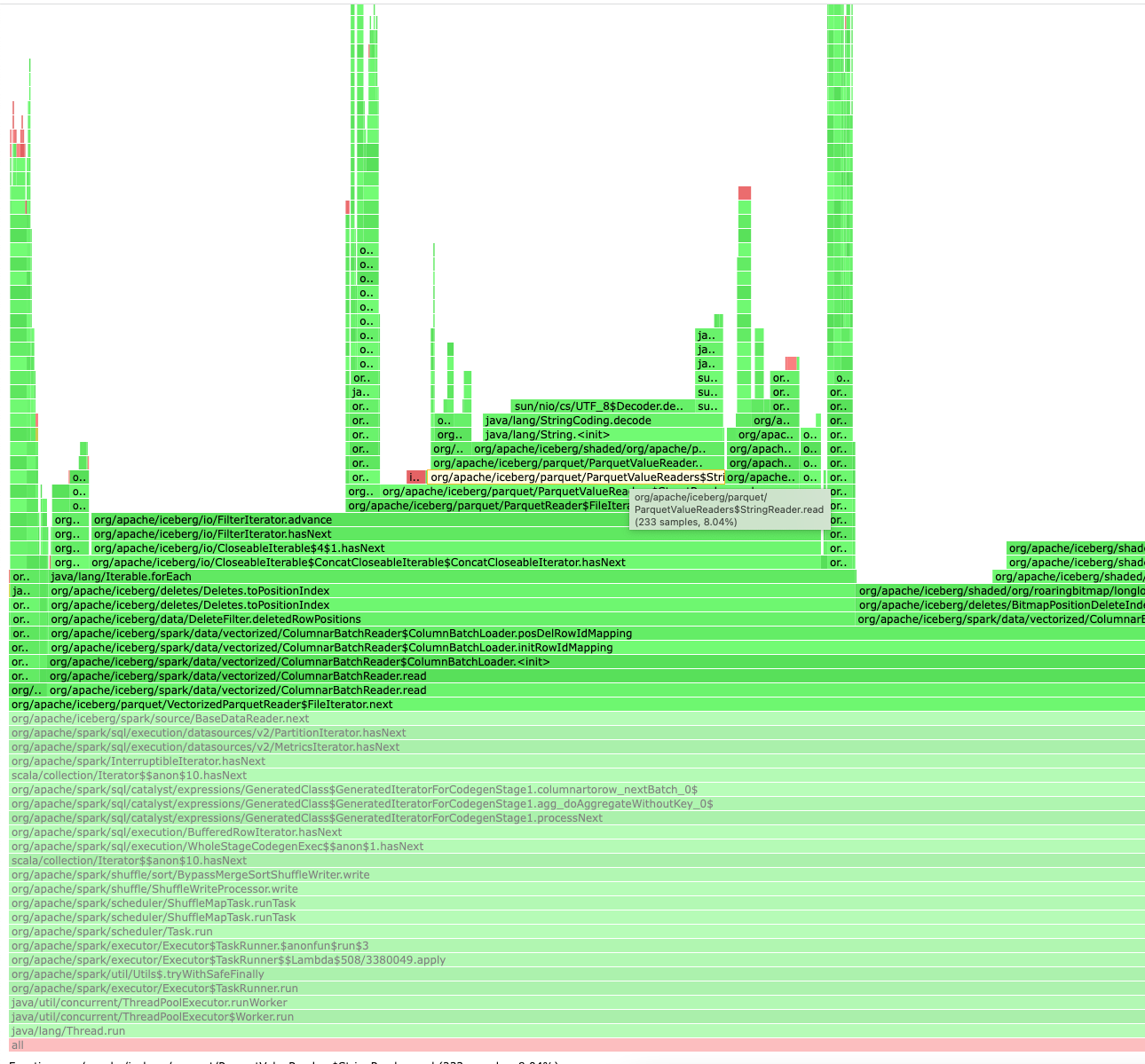 Given that there will be very few file_path compared to the number of records being updated/deleted, it will be nice to optimize the repeated string conversion. ### Query engine Spark -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: [email protected] For queries about this service, please contact Infrastructure at: [email protected] --------------------------------------------------------------------- To unsubscribe, e-mail: [email protected] For additional commands, e-mail: [email protected]
{kind=link}