[
https://issues.apache.org/jira/browse/KUDU-613?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17247556#comment-17247556
]
Ben Manes commented on KUDU-613:
--------------------------------
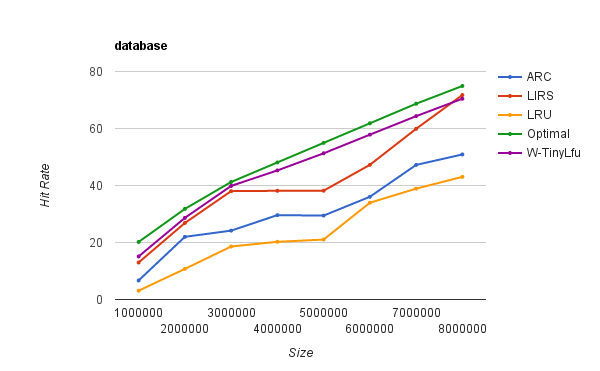
Note that LIRS has a quirky behavior in database & search workloads, which tend
to have scans. As shown below, the policy hits a plateau and only a much
greater cache size allows it to escape. This seems to be due to the IRR model
making incorrect promotions, as the MRU-biased workloads favor more aggressive
eviction of new arrivals. This is with 2x %NR which Impala is defaulted to.
A workaround is to decrease the %NR, as 0.2x matches TinyLFU in this workload.
That degrades in other workloads, of course. Therefore using hill climbing to
adaptively size the %NR can be employed, which in my experiments solves this
problem. You may want to enhance the Impala version with that technique, unless
a more LIRS-specific adaptive algorithm is discovered.
!https://raw.githubusercontent.com/ben-manes/caffeine/master/wiki/efficiency/database.png|width=446,height=276!
> Scan-resistant cache replacement algorithm for the block cache
> --------------------------------------------------------------
>
> Key: KUDU-613
> URL: https://issues.apache.org/jira/browse/KUDU-613
> Project: Kudu
> Issue Type: Improvement
> Components: perf
> Affects Versions: M4.5
> Reporter: Andrew Wang
> Priority: Major
> Labels: roadmap-candidate
>
> The block cache currently uses LRU, which is vulnerable to large scan
> workloads. It'd be good to implement something like 2Q.
> ARC (patent encumbered, but good for ideas):
> https://www.usenix.org/conference/fast-03/arc-self-tuning-low-overhead-replacement-cache
> HBase (2Q like):
> https://github.com/apache/hbase/blob/master/hbase-server/src/main/java/org/apache/hadoop/hbase/io/hfile/LruBlockCache.java
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
{kind=link}