[
https://issues.apache.org/jira/browse/NIFI-4639?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=16282299#comment-16282299
]
ASF GitHub Bot commented on NIFI-4639:
--------------------------------------
Github user markap14 commented on the issue:
https://github.com/apache/nifi/pull/2292
@joewitt I agree that this seems correct but have concerns about
performance as well. I built this PR and then copied in the kafka-0.11
processors from NiFi 1.4.0 in order to do a side-by-side comparison. The
results are shown below (left-hand-side being the new one):
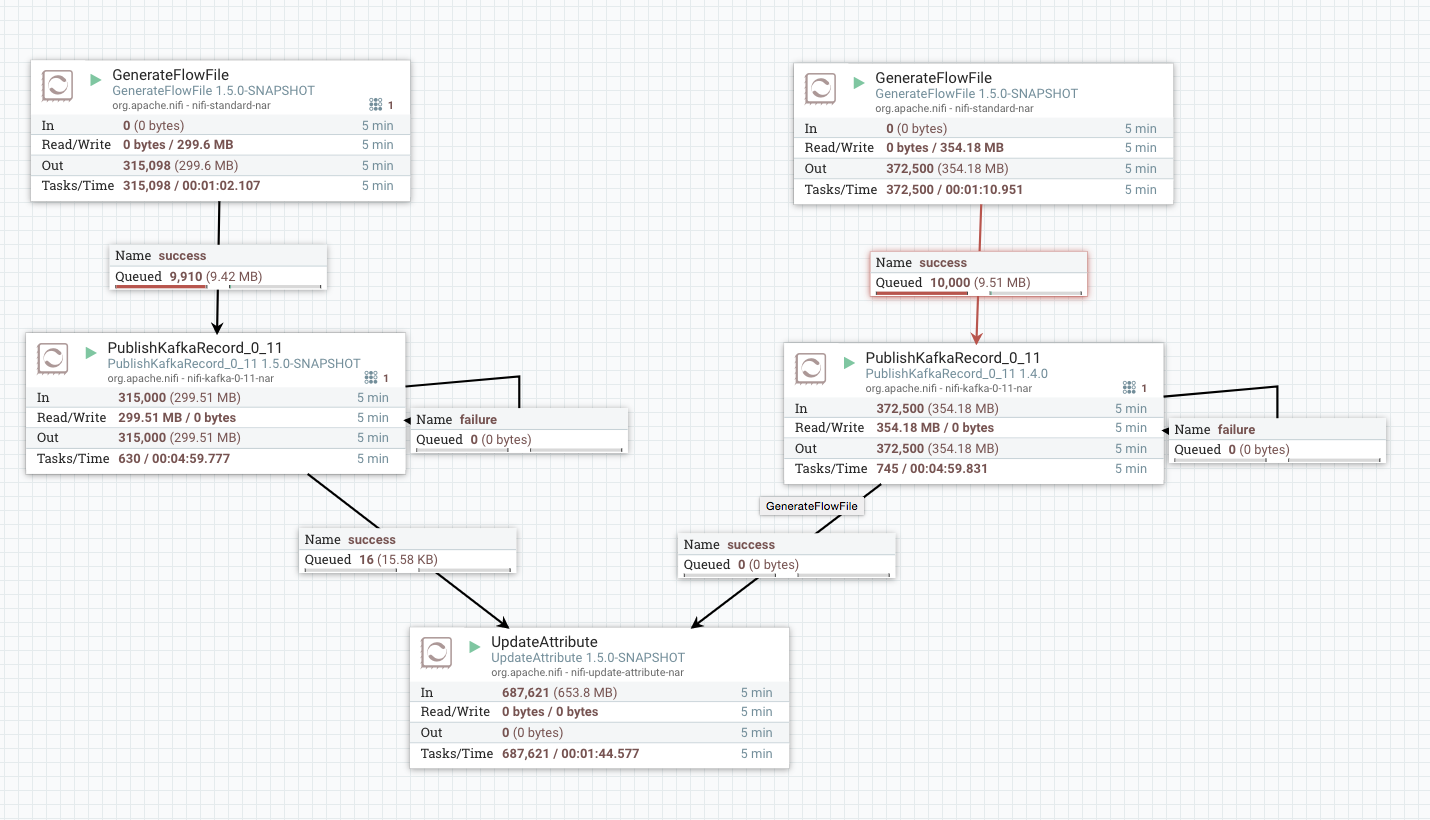
So we can see that the performance dropped by at 15%. This was the JSON
writer, specifically. Haven't tried with the Avro writer, but in any case we
need to ensure that this has high performance for all cases.
I wonder if a better option may be to add some sort of
`rebind(OuptutStream)` method to RecordWriter, so that it would reset itself to
write to a new Output Stream. This would avoid having to recreate potentially
expensive objects for every single record. Then, instead of creating a new
writer each time, we can just re-bind the existing writer to a new
OutputStream, write the record, flush, and repeat.
> PublishKafkaRecord with Avro writer: schema lost from output
> ------------------------------------------------------------
>
> Key: NIFI-4639
> URL: https://issues.apache.org/jira/browse/NIFI-4639
> Project: Apache NiFi
> Issue Type: Bug
> Components: Extensions
> Affects Versions: 1.4.0
> Reporter: Matthew Silverman
> Attachments: Demo_Names_NiFi_bug.xml
>
>
> I have a {{PublishKafkaRecord_0_10}} configured with an
> {{AvroRecordSetWriter}}, in turn configured to "Embed Avro Schema". However,
> when I consume data from the Kafka stream I recieve individual records that
> lack a schema header.
> As a workaround, I can send the flow files through a {{SplitRecord}}
> processor, which does embed the Avro schema into each resulting flow file.
> Comparing the code for {{SplitRecord}} and the {{PublishKafkaRecord}}
> processors, I believe the issue is that {{PublisherLease}} wipes the output
> stream after calling {{createWriter}}; however it is
> {{AvroRecordSetWriter#createWriter}} that writes the Avro header to the
> output stream. {{SplitRecord}}, on the other hand, creates a new writer for
> each output record.
> I've attached my flow.
--
This message was sent by Atlassian JIRA
(v6.4.14#64029)
{kind=link}