[
https://issues.apache.org/jira/browse/PHOENIX-5055?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=16708715#comment-16708715
]
Jaanai commented on PHOENIX-5055:
---------------------------------
{quote}There's still a chance for two mutations to the same row to wind up in
different batches. Consider the case where there are, say, 3 mutations to Row
A, and mutations 1 and 2 combine to make up a batch size. I believe your patch
will cut a batch after mutation 2, and mutation 3 will have a different
timestamp
{quote}
As Thomas said that there would not see multiple rows with the same rowkey that
will be merged before splitting them into multiple batches by the batch size or
number or rows.
{quote}It would be possible to calculate all the sameRowMutationSizeBytes
values in one pass in a separate loop, and then refer back to it during the
existing allMutations loop. Doing this might also make fixing
{quote}
Thanks for your point out.
> Split mutations batches probably affects correctness of index data
> ------------------------------------------------------------------
>
> Key: PHOENIX-5055
> URL: https://issues.apache.org/jira/browse/PHOENIX-5055
> Project: Phoenix
> Issue Type: Bug
> Affects Versions: 5.0.0, 4.14.1
> Reporter: Jaanai
> Assignee: Jaanai
> Priority: Critical
> Fix For: 5.1.0
>
> Attachments: ConcurrentTest.java, PHOENIX-5055-v4.x-HBase-1.4.patch
>
>
> In order to get more performance, we split the list of mutations into
> multiple batches in MutationSate. For one upsert SQL with some null values
> that will produce two type KeyValues(Put and DeleteColumn), These KeyValues
> should have the same timestamp so that keep on an atomic operation for
> corresponding the row key.
> [^ConcurrentTest.java] produced some random upsert/delete SQL and
> concurrently executed, some SQL snippets as follows:
> {code:java}
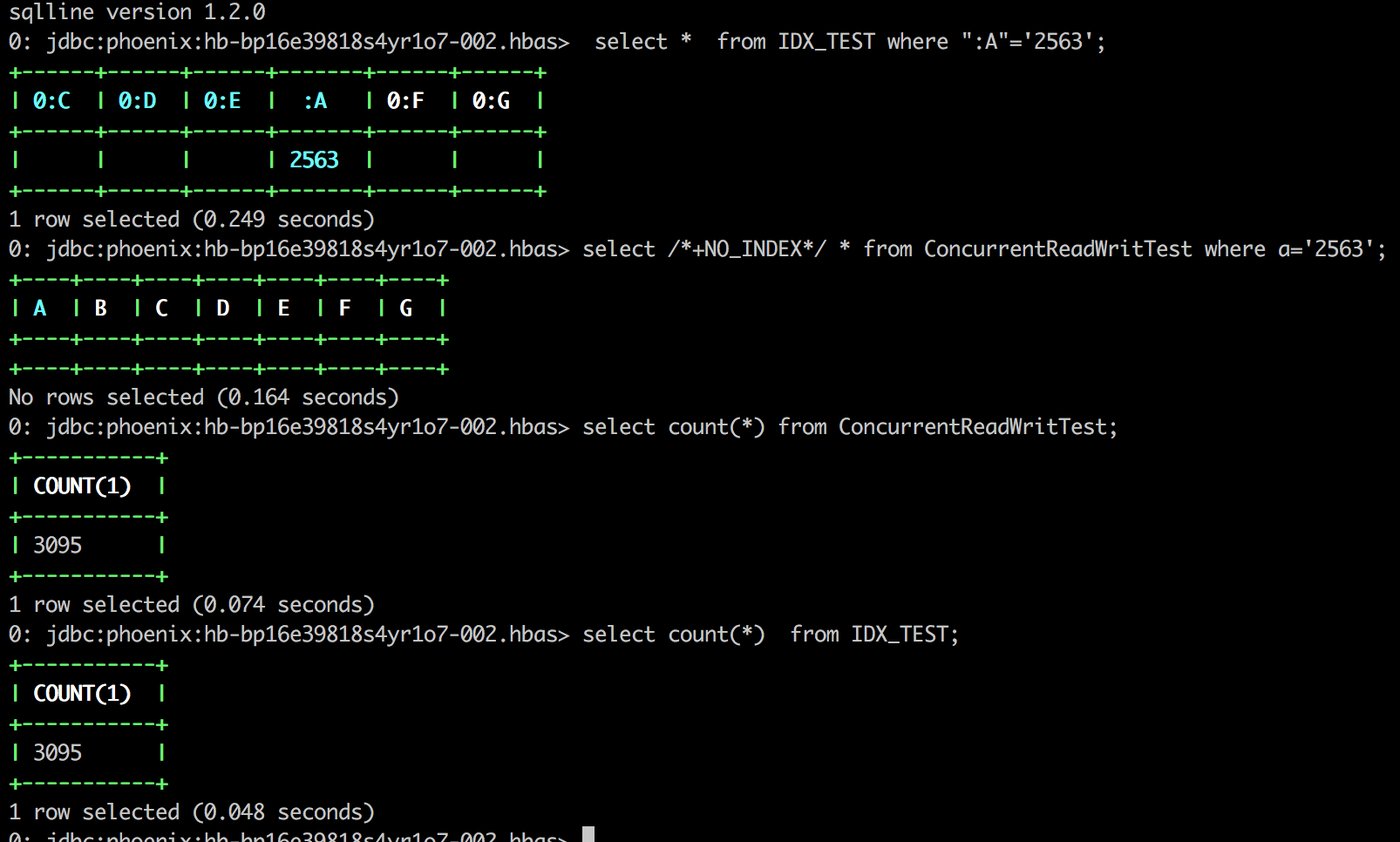
> 1149:UPSERT INTO ConcurrentReadWritTest(A,C,E,F,G) VALUES
> ('3826','2563','3052','3170','3767');
> 1864:UPSERT INTO ConcurrentReadWritTest(A,B,C,D,E,F,G) VALUES
> ('2563','4926','3526','678',null,null,'1617');
> 2332:UPSERT INTO ConcurrentReadWritTest(A,B,C,D,E,F,G) VALUES
> ('1052','2563','1120','2314','1456',null,null);
> 2846:UPSERT INTO ConcurrentReadWritTest(A,B,C,D,G) VALUES
> ('1922','146',null,'469','2563');
> 2847:DELETE FROM ConcurrentReadWritTest WHERE A = '2563’;
> {code}
> Found incorrect indexed data for the index tables by sqlline.
> !https://gw.alicdn.com/tfscom/TB1nSDqpxTpK1RjSZFGXXcHqFXa.png|width=665,height=400!
> Debugged the mutations of batches on the server side. the DeleteColumns and
> Puts were splitted into the different batches for the once upsert, the
> DeleteFaimly also was executed by another thread. due to DeleteColumns's
> timestamp is larger than DeleteFaimly under multiple threads.
> !https://gw.alicdn.com/tfscom/TB1frHmpCrqK1RjSZK9XXXyypXa.png|width=901,height=120!
>
> Running the following:
> {code:java}
> conn.createStatement().executeUpdate( "CREATE TABLE " + tableName + " (" + "A
> VARCHAR NOT NULL PRIMARY KEY," + "B VARCHAR," + "C VARCHAR," + "D VARCHAR)
> COLUMN_ENCODED_BYTES = 0");
> conn.createStatement().executeUpdate("CREATE INDEX " + indexName + " on " +
> tableName + " (C) INCLUDE(D)");
> conn.createStatement().executeUpdate("UPSERT INTO " + tableName + "(A,B,C,D)
> VALUES ('A2','B2','C2','D2')");
> conn.createStatement().executeUpdate("UPSERT INTO " + tableName + "(A,B,C,D)
> VALUES ('A3','B3', 'C3', null)");
> {code}
> dump IndexMemStore:
> {code:java}
> hbase.index.covered.data.IndexMemStore(117):
> Inserting:\x01A3/0:D/1542190446218/DeleteColumn/vlen=0/seqid=0/value=
> phoenix.hbase.index.covered.data.IndexMemStore(133): Current kv state:
> phoenix.hbase.index.covered.data.IndexMemStore(135): KV:
> \x01A3/0:B/1542190446167/Put/vlen=2/seqid=5/value=B3
> phoenix.hbase.index.covered.data.IndexMemStore(135): KV:
> \x01A3/0:C/1542190446167/Put/vlen=2/seqid=5/value=C3
> phoenix.hbase.index.covered.data.IndexMemStore(135): KV:
> \x01A3/0:D/1542190446218/DeleteColumn/vlen=0/seqid=0/value=
> phoenix.hbase.index.covered.data.IndexMemStore(135): KV:
> \x01A3/0:_0/1542190446167/Put/vlen=1/seqid=5/value=x
> phoenix.hbase.index.covered.data.IndexMemStore(137): ========== END MemStore
> Dump ==================
> {code}
>
> The DeleteColumn's timestamp larger than other mutations.
>
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
{kind=link}
{kind=link}