[
https://issues.apache.org/jira/browse/SPARK-3523?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Larry Xiao updated SPARK-3523:
------------------------------
Description:
We implemented some algorithms for partitioning on GraphX, and evaluated. And
find the partitioning has space of improving. Seek opinion and advice.
h5. Motivation
* Graph in real world follow power law. Eg. On twitter 1% of the vertices are
adjacent to nearly half of the edges.
* For high-degree vertex, one vertex concentrates vast resources. So the
workload on few high-degree vertex should be decomposed by all machines
* For low-degree vertex, The computation on one vertex is quite small. Thus
should exploit the locality of the computation on low-degree vertex.
h5. Algorithm Description
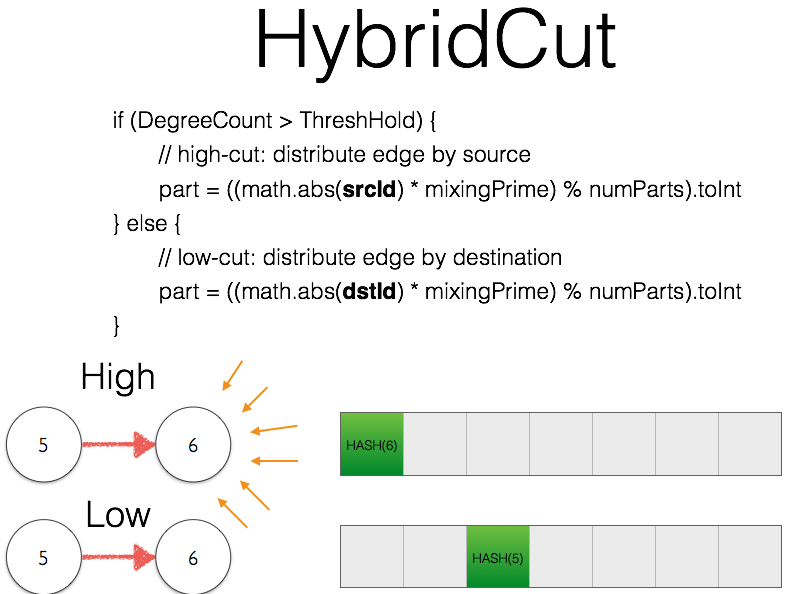
* HybridCut
*
!https://raw.githubusercontent.com/larryxiao/spark/GraphX/Arkansol.Analyse/HybridCut.png
* HybridCutPlus
*
!https://raw.githubusercontent.com/larryxiao/spark/GraphX/Arkansol.Analyse/HybridCutPlus.png
* Greedy BiCut
* a heuristic algorithm for bipartite
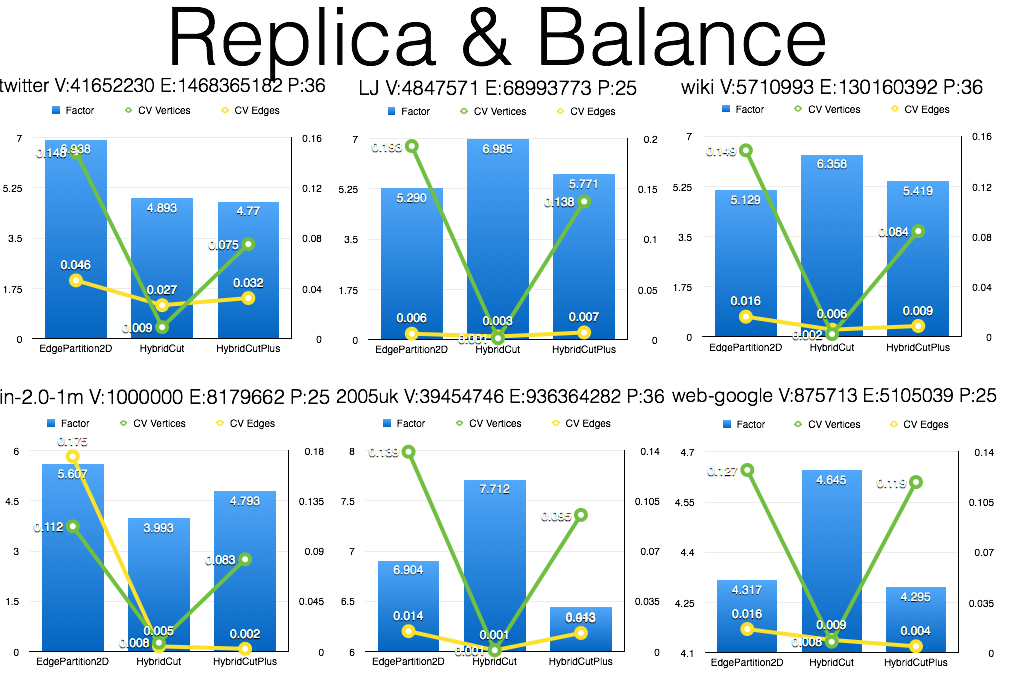
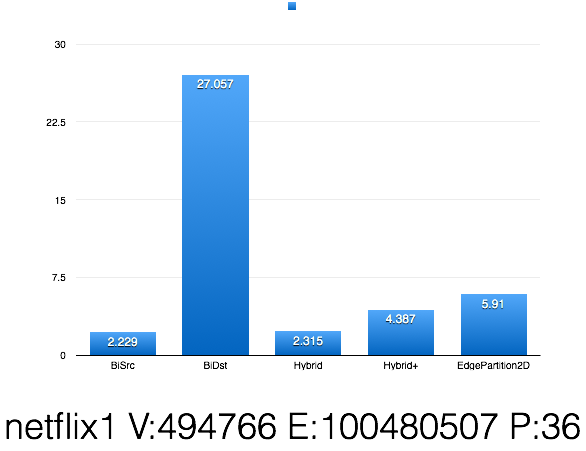
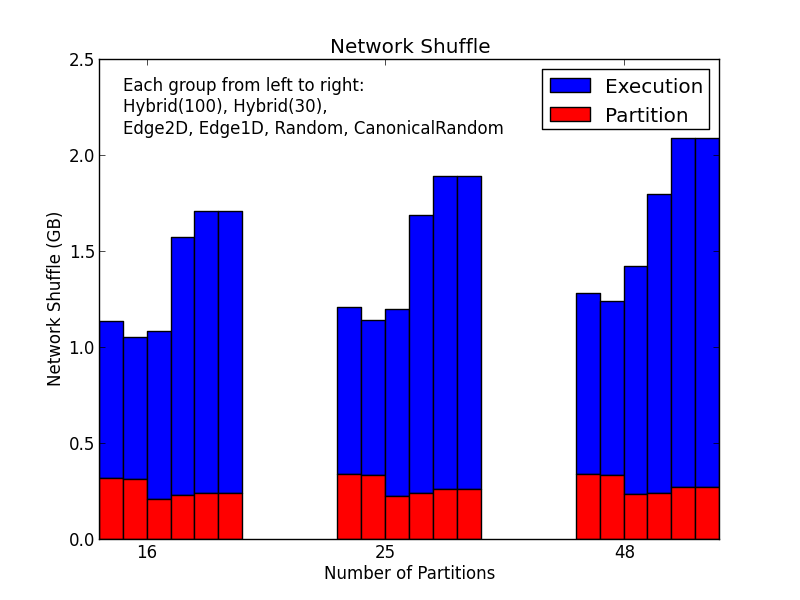
h5. Result
!https://raw.githubusercontent.com/larryxiao/spark/GraphX/Arkansol.Analyse/FactorBalance.png
!https://raw.githubusercontent.com/larryxiao/spark/GraphX/Arkansol.Analyse/Bipartite.png
!https://raw.githubusercontent.com/larryxiao/spark/GraphX/Arkansol.Analyse/Shuffle.png
h5. Code
*
https://github.com/larryxiao/spark/blob/GraphX/graphx/src/main/scala/org/apache/spark/graphx/impl/GraphImpl.scala#L173
* Because the implementation breaks the current separation using
PartitionStrategy.scala, so need to think of a way to support access to graph.
h5. Reference
- Bipartite-oriented Distributed Graph Partitioning for Big Learning.
- PowerLyra : Differentiated Graph Computation and Partitioning on Skewed Graphs
was:
We implemented some algorithms for partitioning on GraphX, and evaluated. And
find the partitioning has space of improving. Seek opinion and advice.
H5. Motivation
* Graph in real world follow power law. Eg. On twitter 1% of the vertices are
adjacent to nearly half of the edges.
* For high-degree vertex, one vertex concentrates vast resources. So the
workload on few high-degree vertex should be decomposed by all machines
* For low-degree vertex, The computation on one vertex is quite small. Thus
should exploit the locality of the computation on low-degree vertex.
H5. Algorithm Description
* HybridCut
*
!https://raw.githubusercontent.com/larryxiao/spark/GraphX/Arkansol.Analyse/HybridCut.png
* HybridCutPlus
*
!https://raw.githubusercontent.com/larryxiao/spark/GraphX/Arkansol.Analyse/HybridCutPlus.png
* Greedy BiCut
* a heuristic algorithm for bipartite
H5. Result
!https://raw.githubusercontent.com/larryxiao/spark/GraphX/Arkansol.Analyse/FactorBalance.png
!https://raw.githubusercontent.com/larryxiao/spark/GraphX/Arkansol.Analyse/Bipartite.png
!https://raw.githubusercontent.com/larryxiao/spark/GraphX/Arkansol.Analyse/Shuffle.png
H5. Code
*
https://github.com/larryxiao/spark/blob/GraphX/graphx/src/main/scala/org/apache/spark/graphx/impl/GraphImpl.scala#L173
* Because the implementation breaks the current separation using
PartitionStrategy.scala, so need to think of a way to support access to graph.
H5. Reference
- Bipartite-oriented Distributed Graph Partitioning for Big Learning.
- PowerLyra : Differentiated Graph Computation and Partitioning on Skewed Graphs
> GraphX graph partitioning strategy
> ----------------------------------
>
> Key: SPARK-3523
> URL: https://issues.apache.org/jira/browse/SPARK-3523
> Project: Spark
> Issue Type: Improvement
> Components: GraphX
> Affects Versions: 1.0.2
> Reporter: Larry Xiao
>
> We implemented some algorithms for partitioning on GraphX, and evaluated. And
> find the partitioning has space of improving. Seek opinion and advice.
> h5. Motivation
> * Graph in real world follow power law. Eg. On twitter 1% of the vertices are
> adjacent to nearly half of the edges.
> * For high-degree vertex, one vertex concentrates vast resources. So the
> workload on few high-degree vertex should be decomposed by all machines
> * For low-degree vertex, The computation on one vertex is quite small. Thus
> should exploit the locality of the computation on low-degree vertex.
> h5. Algorithm Description
> * HybridCut
> *
> !https://raw.githubusercontent.com/larryxiao/spark/GraphX/Arkansol.Analyse/HybridCut.png
> * HybridCutPlus
> *
> !https://raw.githubusercontent.com/larryxiao/spark/GraphX/Arkansol.Analyse/HybridCutPlus.png
> * Greedy BiCut
> * a heuristic algorithm for bipartite
> h5. Result
> !https://raw.githubusercontent.com/larryxiao/spark/GraphX/Arkansol.Analyse/FactorBalance.png
> !https://raw.githubusercontent.com/larryxiao/spark/GraphX/Arkansol.Analyse/Bipartite.png
> !https://raw.githubusercontent.com/larryxiao/spark/GraphX/Arkansol.Analyse/Shuffle.png
> h5. Code
> *
> https://github.com/larryxiao/spark/blob/GraphX/graphx/src/main/scala/org/apache/spark/graphx/impl/GraphImpl.scala#L173
> * Because the implementation breaks the current separation using
> PartitionStrategy.scala, so need to think of a way to support access to graph.
> h5. Reference
> - Bipartite-oriented Distributed Graph Partitioning for Big Learning.
> - PowerLyra : Differentiated Graph Computation and Partitioning on Skewed
> Graphs
--
This message was sent by Atlassian JIRA
(v6.3.4#6332)
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscr...@spark.apache.org
For additional commands, e-mail: issues-h...@spark.apache.org
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}