Lijie Xu created SPARK-22713:
--------------------------------
Summary: OOM caused by the memory contention and memory leak in
TaskMemoryManager
Key: SPARK-22713
URL: https://issues.apache.org/jira/browse/SPARK-22713
Project: Spark
Issue Type: Bug
Components: Shuffle, Spark Core
Affects Versions: 2.1.2, 2.1.1
Reporter: Lijie Xu
Priority: Critical
*[Abstract]*
I recently encountered an OOM error in a PageRank application
(_org.apache.spark.examples.SparkPageRank_). After profiling the application, I
found the OOM error is related to the memory contention in shuffle spill phase.
Here, the memory contention means that a task tries to release some old memory
consumers from memory for keeping the new memory consumers. After analyzing the
OOM heap dump, I found the root cause is a memory leak in _TaskMemoryManager_.
Since memory contention is common in shuffle phase, this is a critical
bug/defect. In the following sections, I will use the application dataflow,
execution log, heap dump, and source code to identify the root cause.
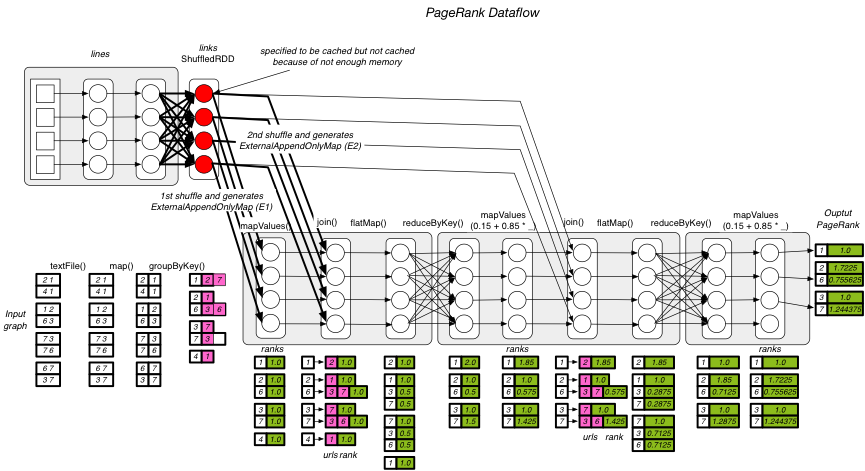
*[Application]*
This is a PageRank application from Spark’s example library. The following
figure shows the application dataflow. The source code is available at \[1\].
!
https://raw.githubusercontent.com/JerryLead/Misc/master/OOM-TasksMemoryManager/figures/PageRankDataflow.png|width=100%!
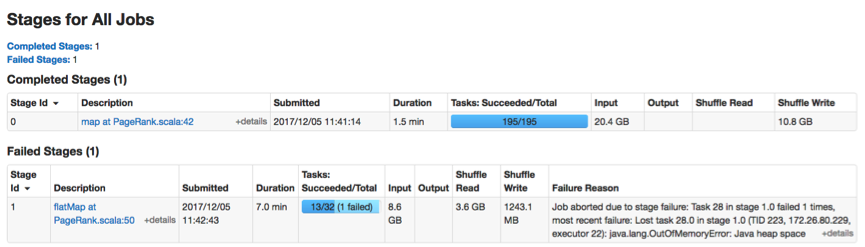
*[Failure symptoms]*
This application has a map stage and many iterative reduce stages. An OOM error
occurs in a reduce task (Task-28) as follows.
!
https://github.com/JerryLead/Misc/blob/master/OOM-TasksMemoryManager/figures/Stage.png?raw=true|width=100%!
!
https://github.com/JerryLead/Misc/blob/master/OOM-TasksMemoryManager/figures/task.png?raw=true|width=100%!
*[OOM root cause identification]*
Each executor has 1 CPU core and 6.5GB memory, so it only runs one task at a
time. After analyzing the application dataflow, error log, heap dump, and
source code, I found the following steps lead to the OOM error.
=> The MemoryManager found that there is not enough memory to cache the
_links:ShuffledRDD_ (rdd-5-28, red circles in the dataflow figure).
!
https://github.com/JerryLead/Misc/blob/master/OOM-TasksMemoryManager/figures/ShuffledRDD.png?raw=true|width=100%!
=> The task needs to shuffle twice (1st shuffle and 2nd shuffle in the dataflow
figure).
=> The task needs to generate two _ExternalAppendOnlyMap_ (E1 for 1st shuffle
and E2 for 2nd shuffle) in sequence.
=> The 1st shuffle begins and ends. E1 aggregates all the shuffled data of 1st
shuffle and achieves 3.3 GB.
!
https://github.com/JerryLead/Misc/blob/master/OOM-TasksMemoryManager/figures/FirstShuffle.png?raw=true|width=100%!
=> The 2nd shuffle begins. E2 is aggregating the shuffled data of 2nd shuffle,
and finding that there is not enough memory left. This triggers the memory
contention.
!
https://github.com/JerryLead/Misc/blob/master/OOM-TasksMemoryManager/figures/SecondShuffle.png?raw=true|width=100%!
=> To handle the memory contention, the _TaskMemoryManager_ releases E1 (spills
it onto disk) and assumes that the 3.3GB space is free now.
!
https://github.com/JerryLead/Misc/blob/master/OOM-TasksMemoryManager/figures/MemoryContention.png?raw=true|width=100%!
=> E2 continues to aggregates the shuffled records of 2nd shuffle. However, E2
encounters an OOM error while shuffling.
!https://github.com/JerryLead/Misc/blob/master/OOM-TasksMemoryManager/figures/OOMbefore.png?raw=true|width=100%!
!https://github.com/JerryLead/Misc/blob/master/OOM-TasksMemoryManager/figures/OOMError.png?raw=true|width=100%!
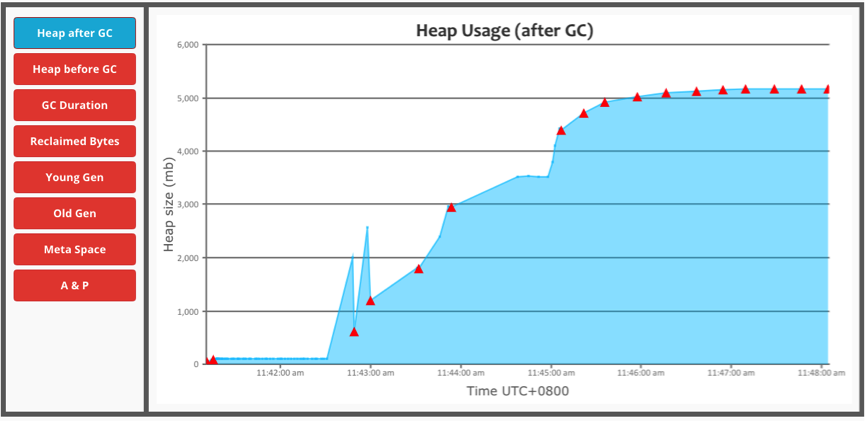
*[Guess]* The task memory usage below reveals that there is not memory drop
down. So, the cause may be that the 3.3GB _ExternalAppendOnlyMap_ (E1) is not
actually released by the _TaskMemoryManger_.
!https://github.com/JerryLead/Misc/blob/master/OOM-TasksMemoryManager/figures/GCFigure.png?raw=true|width=100%!
*[Root cause]* After analyzing the heap dump, I found the guess is right (the
3.3GB _ExternalAppendOnlyMap_ is actually not released). The 1.6GB object is
_ExternalAppendOnlyMap (E2)_.
!https://github.com/JerryLead/Misc/blob/master/OOM-TasksMemoryManager/figures/heapdump.png?raw=true|width=100%!
*[Question]* Why the released _ExternalAppendOnlyMap_ is still in memory?
The source code of _ExternalAppendOnlyMap_ shows that the _currentMap_
(_AppendOnlyMap_) has been set to _null_ when the spill action is finished.
!https://github.com/JerryLead/Misc/blob/master/OOM-TasksMemoryManager/figures/SourceCode.png?raw=true|width=100%!
*[Root cause in the source code]* I further analyze the reference chain of
unreleased _ExternalAppendOnlyMap_. The reference chain shows that the 3.3GB
_ExternalAppendOnlyMap_ is still referenced by the _upstream/readingIterator_
and further referenced by _TaskMemoryManager_ as follows. So, the root cause in
the source code is that the _ExternalAppendOnlyMap_ is still referenced by
other iterators (setting the _currentMap_ to _null_ is not enough).
!https://github.com/JerryLead/Misc/blob/master/OOM-TasksMemoryManager/figures/References.png?raw=true|width=100%!
*[Potential solution]*
Setting the _upstream/readingIterator_ to _null_ after the _forceSpill_()
action. I will try this solution in these days.
[References]
[1] PageRank source code.
https://github.com/JerryLead/SparkGC/blob/master/src/main/scala/applications/graph/PageRank.scala
[2] Task execution log.
https://github.com/JerryLead/Misc/blob/master/OOM-TasksMemoryManager/log/TaskExecutionLog.txt
*[Identified root causes]*
The above analysis reveals the root cause: the spilled records and in-memory
records are still kept in memory even they have been merged. The root causes
can be further summarized as follows.
*(1) Memory leak in _ExternalyAppendOnlyMap_:* The merged in-memory records in
AppendOnlyMap are not cleared after Memory-Disk-Merge.
*(2) Large serializer batch size:*
The _serializerBatchSize_ ("spark.shuffle.spill.batchSize", 10000) is too
arbitrary and too large for the application that have small aggregated record
number but large record size. For these applications, all the spilled records
(3.6GB in this case) will be serialized in a buffer and written as a whole file
segment at a time. In other words, the 3.6GB records will be read back to
memory at a time. Other applications that have large record number with small
record size may be OK, because the spilled records may be serialized and
written to many files. In other words, the 3.6GB records will be read back to
memory in several times with low memory consumption.
*(3) Memory leak in deserializer:* The spilled records are not cleared from the
_DeSerializeBuffer_ after Memory-Disk-Merge, which leads to both large buffer
and large object references.
*[Potential solutions]*
For each root cause, we can
*(1) Handle memory leak in ExternalyAppendOnlyMap:* Remove the records in both
in AppendOnlyMap and read-back-spilledMap once the in-memory records have been
merged. Current AppendOnlyMap (the following currentMap) does not delete the
merged records until all of the records in it have been merged.
{code}
private val sortedMap = CompletionIterator[(K, C), Iterator[(K,
C)]](destructiveIterator(
currentMap.destructiveSortedIterator(keyComparator)), freeCurrentMap()))
{code}
*(2) Adaptive serializer batch size instead of static spill threshold and
static serializerBatchSize:* Since we can dynamically obtain (estimate) the
record number and bytes in AppendOnlyMap, we can estimate the size of
serialize/deserialize buffer size when the spill threshold is achieved. Based
on this information, we can accordingly lower the batch size to write the
serialized records into multiple file segments.
*(3) Handle memory leak in the deserializer:* Try to remove the merged spilled
records in the deserializer or design a new deserializer.
The whole task OOM log can is available at \[3\].
*[References]*
\[1\] The GroupBy application code.
https://github.com/JerryLead/SparkGC/blob/master/src/main/scala/applications/sql/rdd/RDDGroupByTest.scala
\[2\] Data generator.
https://github.com/JerryLead/SparkGC/tree/master/datagen/sql/htmlgen
\[3\] Task-17 stderr log.
https://github.com/JerryLead/Misc/blob/master/SparkPRFigures/OOM/Task-17-log.txt
--
This message was sent by Atlassian JIRA
(v6.4.14#64029)
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscr...@spark.apache.org
For additional commands, e-mail: issues-h...@spark.apache.org
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}